 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Jointly-Learned Exit and Inference for a Dynamic Neural Network : JEI-DNN
Oct 13, 2023
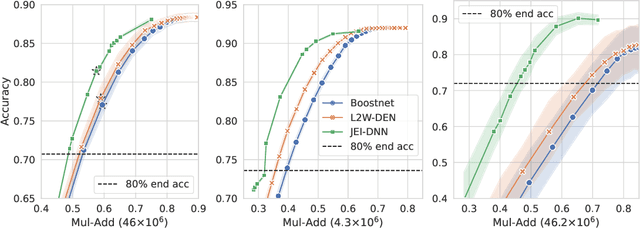
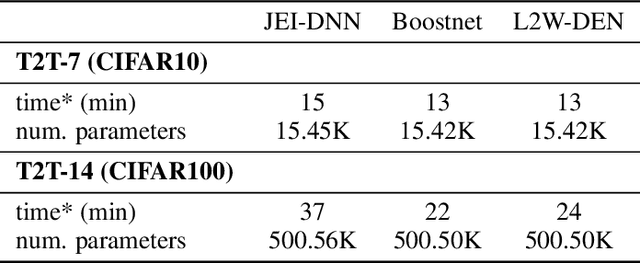
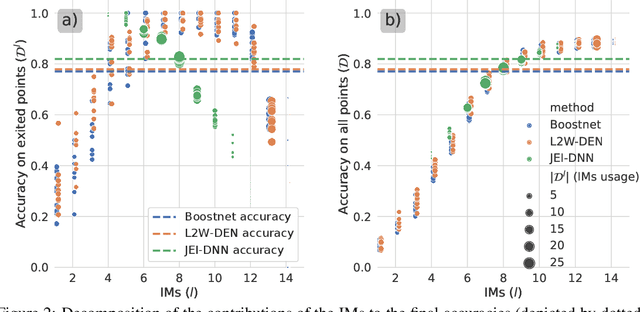

Large pretrained models, coupled with fine-tuning, are slowly becoming established as the dominant architecture in machine learning. Even though these models offer impressive performance, their practical application is often limited by the prohibitive amount of resources required for every inference. Early-exiting dynamic neural networks (EDNN) circumvent this issue by allowing a model to make some of its predictions from intermediate layers (i.e., early-exit). Training an EDNN architecture is challenging as it consists of two intertwined components: the gating mechanism (GM) that controls early-exiting decisions and the intermediate inference modules (IMs) that perform inference from intermediate representations. As a result, most existing approaches rely on thresholding confidence metrics for the gating mechanism and strive to improve the underlying backbone network and the inference modules. Although successful, this approach has two fundamental shortcomings: 1) the GMs and the IMs are decoupled during training, leading to a train-test mismatch; and 2) the thresholding gating mechanism introduces a positive bias into the predictive probabilities, making it difficult to readily extract uncertainty information. We propose a novel architecture that connects these two modules. This leads to significant performance improvements on classification datasets and enables better uncertainty characterization capabilities.
Towards an Interpretable Representation of Speaker Identity via Perceptual Voice Qualities
Oct 04, 2023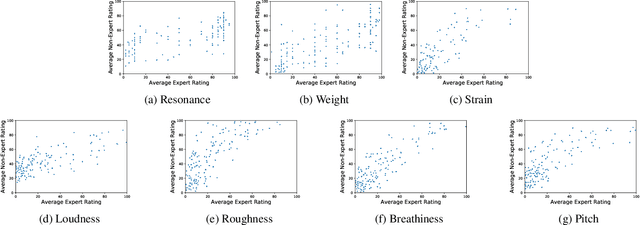

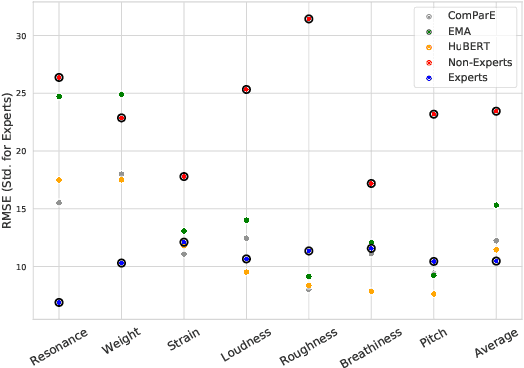
Unlike other data modalities such as text and vision, speech does not lend itself to easy interpretation. While lay people can understand how to describe an image or sentence via perception, non-expert descriptions of speech often end at high-level demographic information, such as gender or age. In this paper, we propose a possible interpretable representation of speaker identity based on perceptual voice qualities (PQs). By adding gendered PQs to the pathology-focused Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) protocol, our PQ-based approach provides a perceptual latent space of the character of adult voices that is an intermediary of abstraction between high-level demographics and low-level acoustic, physical, or learned representations. Contrary to prior belief, we demonstrate that these PQs are hearable by ensembles of non-experts, and further demonstrate that the information encoded in a PQ-based representation is predictable by various speech representations.
Fine-tuned vs. Prompt-tuned Supervised Representations: Which Better Account for Brain Language Representations?
Oct 03, 2023To decipher the algorithm underlying the human brain's language representation, previous work probed brain responses to language input with pre-trained artificial neural network (ANN) models fine-tuned on NLU tasks. However, full fine-tuning generally updates the entire parametric space and distorts pre-trained features, cognitively inconsistent with the brain's robust multi-task learning ability. Prompt-tuning, in contrast, protects pre-trained weights and learns task-specific embeddings to fit a task. Could prompt-tuning generate representations that better account for the brain's language representations than fine-tuning? If so, what kind of NLU task leads a pre-trained model to better decode the information represented in the human brain? We investigate these questions by comparing prompt-tuned and fine-tuned representations in neural decoding, that is predicting the linguistic stimulus from the brain activities evoked by the stimulus. We find that on none of the 10 NLU tasks, full fine-tuning significantly outperforms prompt-tuning in neural decoding, implicating that a more brain-consistent tuning method yields representations that better correlate with brain data. Moreover, we identify that tasks dealing with fine-grained concept meaning yield representations that better decode brain activation patterns than other tasks, especially the syntactic chunking task. This indicates that our brain encodes more fine-grained concept information than shallow syntactic information when representing languages.
Resilient Legged Local Navigation: Learning to Traverse with Compromised Perception End-to-End
Oct 05, 2023

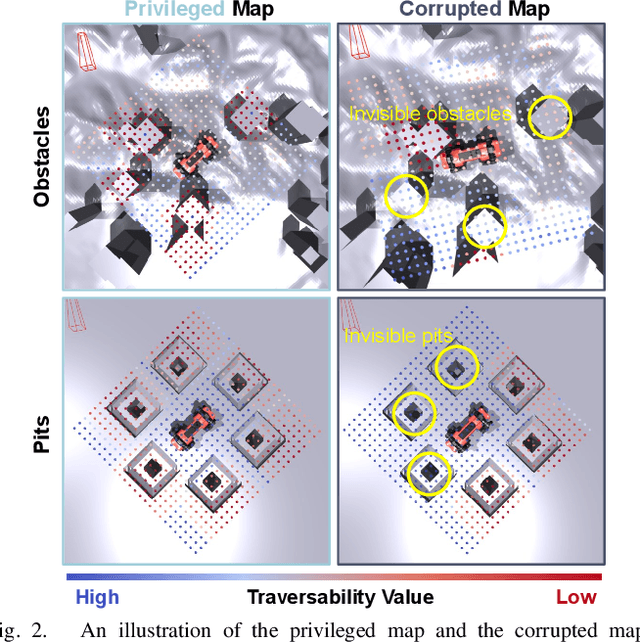
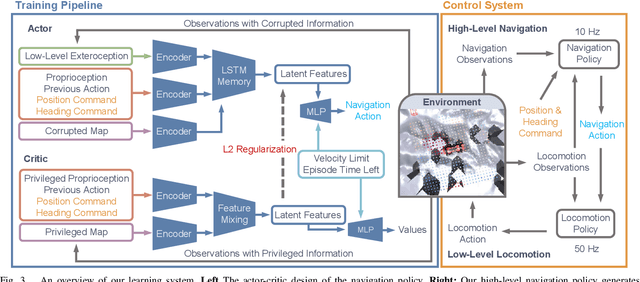
Autonomous robots must navigate reliably in unknown environments even under compromised exteroceptive perception, or perception failures. Such failures often occur when harsh environments lead to degraded sensing, or when the perception algorithm misinterprets the scene due to limited generalization. In this paper, we model perception failures as invisible obstacles and pits, and train a reinforcement learning (RL) based local navigation policy to guide our legged robot. Unlike previous works relying on heuristics and anomaly detection to update navigational information, we train our navigation policy to reconstruct the environment information in the latent space from corrupted perception and react to perception failures end-to-end. To this end, we incorporate both proprioception and exteroception into our policy inputs, thereby enabling the policy to sense collisions on different body parts and pits, prompting corresponding reactions. We validate our approach in simulation and on the real quadruped robot ANYmal running in real-time (<10 ms CPU inference). In a quantitative comparison with existing heuristic-based locally reactive planners, our policy increases the success rate over 30% when facing perception failures. Project Page: https://bit.ly/45NBTuh.
Alzheimer's Disease Prediction via Brain Structural-Functional Deep Fusing Network
Oct 05, 2023Fusing structural-functional images of the brain has shown great potential to analyze the deterioration of Alzheimer's disease (AD). However, it is a big challenge to effectively fuse the correlated and complementary information from multimodal neuroimages. In this paper, a novel model termed cross-modal transformer generative adversarial network (CT-GAN) is proposed to effectively fuse the functional and structural information contained in functional magnetic resonance imaging (fMRI) and diffusion tensor imaging (DTI). The CT-GAN can learn topological features and generate multimodal connectivity from multimodal imaging data in an efficient end-to-end manner. Moreover, the swapping bi-attention mechanism is designed to gradually align common features and effectively enhance the complementary features between modalities. By analyzing the generated connectivity features, the proposed model can identify AD-related brain connections. Evaluations on the public ADNI dataset show that the proposed CT-GAN can dramatically improve prediction performance and detect AD-related brain regions effectively. The proposed model also provides new insights for detecting AD-related abnormal neural circuits.
Swin-Tempo: Temporal-Aware Lung Nodule Detection in CT Scans as Video Sequences Using Swin Transformer-Enhanced UNet
Oct 14, 2023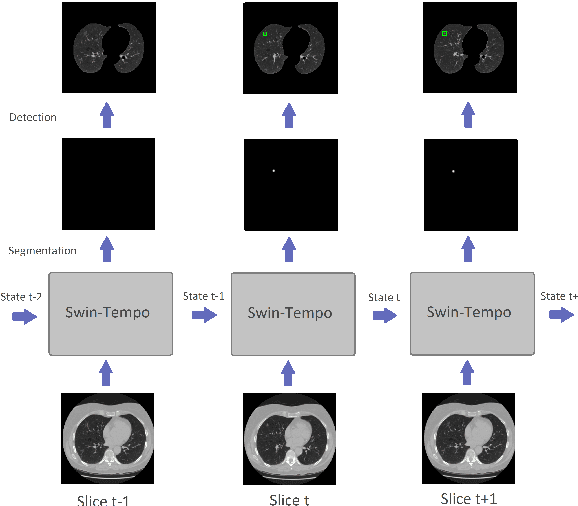

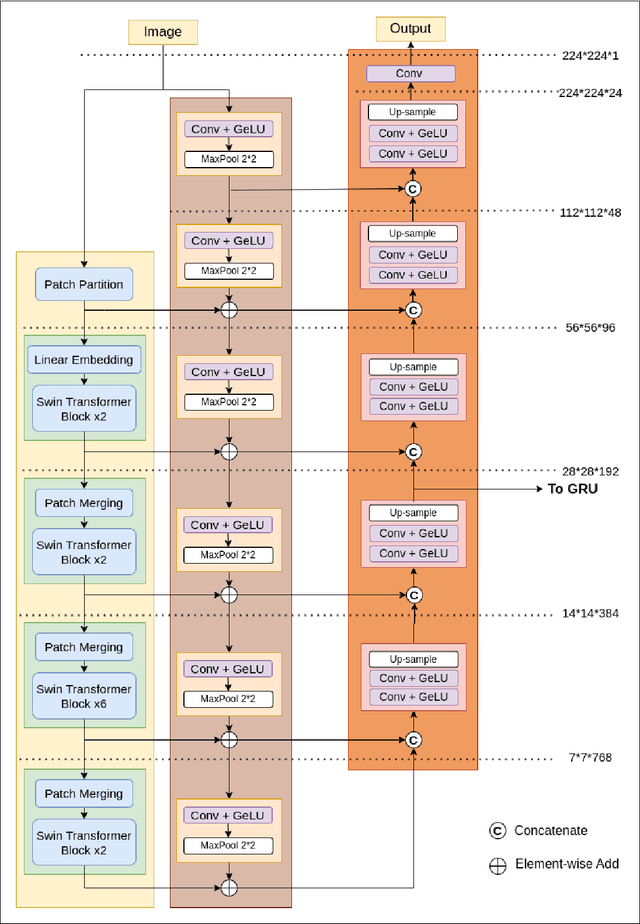
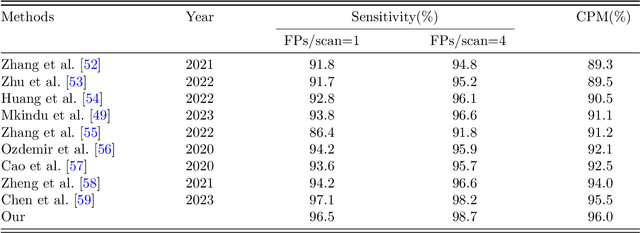
Lung cancer is highly lethal, emphasizing the critical need for early detection. However, identifying lung nodules poses significant challenges for radiologists, who rely heavily on their expertise for accurate diagnosis. To address this issue, computer-aided diagnosis (CAD) systems based on machine learning techniques have emerged to assist doctors in identifying lung nodules from computed tomography (CT) scans. Unfortunately, existing networks in this domain often suffer from computational complexity, leading to high rates of false negatives and false positives, limiting their effectiveness. To address these challenges, we present an innovative model that harnesses the strengths of both convolutional neural networks and vision transformers. Inspired by object detection in videos, we treat each 3D CT image as a video, individual slices as frames, and lung nodules as objects, enabling a time-series application. The primary objective of our work is to overcome hardware limitations during model training, allowing for efficient processing of 2D data while utilizing inter-slice information for accurate identification based on 3D image context. We validated the proposed network by applying a 10-fold cross-validation technique to the publicly available Lung Nodule Analysis 2016 dataset. Our proposed architecture achieves an average sensitivity criterion of 97.84% and a competition performance metrics (CPM) of 96.0% with few parameters. Comparative analysis with state-of-the-art advancements in lung nodule identification demonstrates the significant accuracy achieved by our proposed model.
Context-aware Session-based Recommendation with Graph Neural Networks
Oct 14, 2023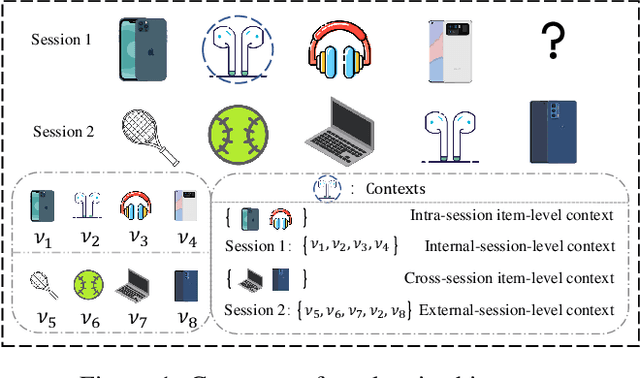
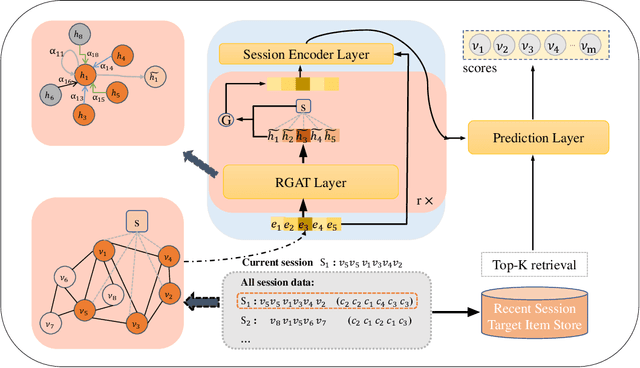
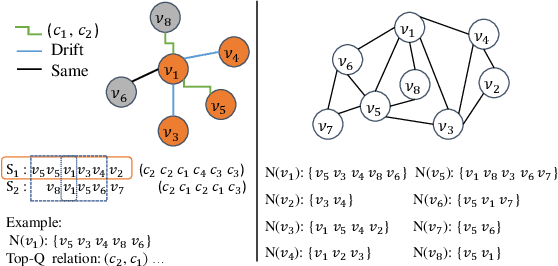
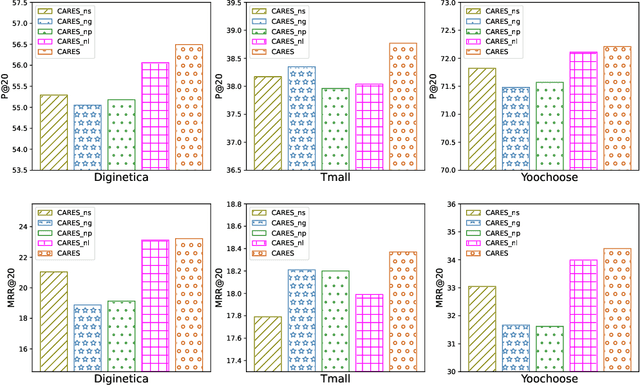
Session-based recommendation (SBR) is a task that aims to predict items based on anonymous sequences of user behaviors in a session. While there are methods that leverage rich context information in sessions for SBR, most of them have the following limitations: 1) they fail to distinguish the item-item edge types when constructing the global graph for exploiting cross-session contexts; 2) they learn a fixed embedding vector for each item, which lacks the flexibility to reflect the variation of user interests across sessions; 3) they generally use the one-hot encoded vector of the target item as the hard label to predict, thus failing to capture the true user preference. To solve these issues, we propose CARES, a novel context-aware session-based recommendation model with graph neural networks, which utilizes different types of contexts in sessions to capture user interests. Specifically, we first construct a multi-relation cross-session graph to connect items according to intra- and cross-session item-level contexts. Further, to encode the variation of user interests, we design personalized item representations. Finally, we employ a label collaboration strategy for generating soft user preference distribution as labels. Experiments on three benchmark datasets demonstrate that CARES consistently outperforms state-of-the-art models in terms of P@20 and MRR@20. Our data and codes are publicly available at https://github.com/brilliantZhang/CARES.
OBSUM: An object-based spatial unmixing model for spatiotemporal fusion of remote sensing images
Oct 14, 2023Spatiotemporal fusion aims to improve both the spatial and temporal resolution of remote sensing images, thus facilitating time-series analysis at a fine spatial scale. However, there are several important issues that limit the application of current spatiotemporal fusion methods. First, most spatiotemporal fusion methods are based on pixel-level computation, which neglects the valuable object-level information of the land surface. Moreover, many existing methods cannot accurately retrieve strong temporal changes between the available high-resolution image at base date and the predicted one. This study proposes an Object-Based Spatial Unmixing Model (OBSUM), which incorporates object-based image analysis and spatial unmixing, to overcome the two abovementioned problems. OBSUM consists of one preprocessing step and three fusion steps, i.e., object-level unmixing, object-level residual compensation, and pixel-level residual compensation. OBSUM can be applied using only one fine image at the base date and one coarse image at the prediction date, without the need of a coarse image at the base date. The performance of OBSUM was compared with five representative spatiotemporal fusion methods. The experimental results demonstrated that OBSUM outperformed other methods in terms of both accuracy indices and visual effects over time-series. Furthermore, OBSUM also achieved satisfactory results in two typical remote sensing applications. Therefore, it has great potential to generate accurate and high-resolution time-series observations for supporting various remote sensing applications.
Quantum image edge detection based on eight-direction Sobel operator for NEQR
Oct 01, 2023Quantum Sobel edge detection (QSED) is a kind of algorithm for image edge detection using quantum mechanism, which can solve the real-time problem encountered by classical algorithms. However, the existing QSED algorithms only consider two- or four-direction Sobel operator, which leads to a certain loss of edge detail information in some high-definition images. In this paper, a novel QSED algorithm based on eight-direction Sobel operator is proposed, which not only reduces the loss of edge information, but also simultaneously calculates eight directions' gradient values of all pixel in a quantum image. In addition, the concrete quantum circuits, which consist of gradient calculation, non-maximum suppression, double threshold detection and edge tracking units, are designed in details. For a 2^n x 2^n image with q gray scale, the complexity of our algorithm can be reduced to O(n^2 + q^2), which is lower than other existing classical or quantum algorithms. And the simulation experiment demonstrates that our algorithm can detect more edge information, especially diagonal edges, than the two- and four-direction QSED algorithms.
* 27 pages, 20 figures
Towards Lossless Dataset Distillation via Difficulty-Aligned Trajectory Matching
Oct 09, 2023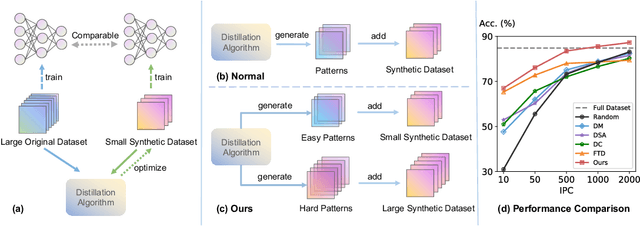
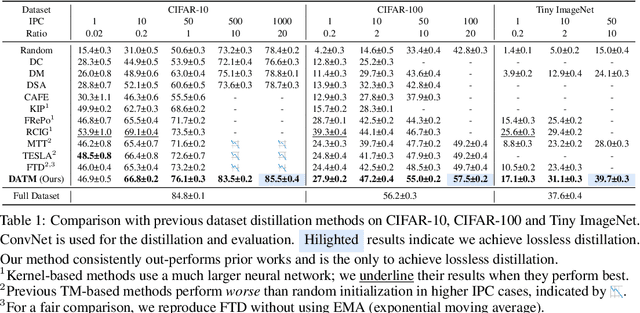
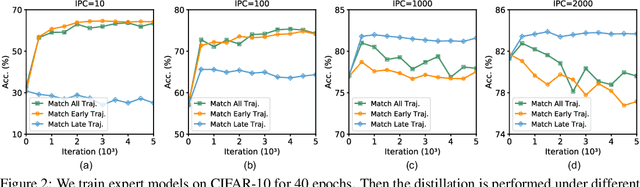

The ultimate goal of Dataset Distillation is to synthesize a small synthetic dataset such that a model trained on this synthetic set will perform equally well as a model trained on the full, real dataset. Until now, no method of Dataset Distillation has reached this completely lossless goal, in part due to the fact that previous methods only remain effective when the total number of synthetic samples is extremely small. Since only so much information can be contained in such a small number of samples, it seems that to achieve truly loss dataset distillation, we must develop a distillation method that remains effective as the size of the synthetic dataset grows. In this work, we present such an algorithm and elucidate why existing methods fail to generate larger, high-quality synthetic sets. Current state-of-the-art methods rely on trajectory-matching, or optimizing the synthetic data to induce similar long-term training dynamics as the real data. We empirically find that the training stage of the trajectories we choose to match (i.e., early or late) greatly affects the effectiveness of the distilled dataset. Specifically, early trajectories (where the teacher network learns easy patterns) work well for a low-cardinality synthetic set since there are fewer examples wherein to distribute the necessary information. Conversely, late trajectories (where the teacher network learns hard patterns) provide better signals for larger synthetic sets since there are now enough samples to represent the necessary complex patterns. Based on our findings, we propose to align the difficulty of the generated patterns with the size of the synthetic dataset. In doing so, we successfully scale trajectory matching-based methods to larger synthetic datasets, achieving lossless dataset distillation for the very first time. Code and distilled datasets are available at https://gzyaftermath.github.io/DATM.