 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Depth Estimation and 3D Geometry Reconstruction using Bayesian Helmholtz Stereopsis with Belief Propagation
Jul 26, 2024Helmholtz stereopsis is one the versatile techniques for 3D geometry reconstruction from 2D images of objects with unknown and arbitrary reflectance surfaces. HS eliminates the need for surface reflectance, a challenging parameter to measure, based on the Helmholtz reciprocity principle. Its Bayesian formulation using maximum a posteriori (MAP) probability approach has significantly improved reconstruction accuracy of HS method. This framework enables the inclusion of smoothness priors which enforces observations and neighborhood information in the formulation. We used Markov Random Fields (MRF) which is a powerful tool to integrate diverse prior contextual information and solved the MAP-MRF using belief propagation algorithm. We propose a new smoothness function utilizing the normal field integration method for refined depth estimation within the Bayesian framework. Utilizing three pairs of images with different viewpoints, our approach demonstrates superior depth label accuracy compared to conventional Bayesian methods. Experimental results indicate that our proposed method yields a better depth map with reduced RMS error, showcasing its efficacy in improving depth estimation within Helmholtz stereopsis.
Swin-Tempo: Temporal-Aware Lung Nodule Detection in CT Scans as Video Sequences Using Swin Transformer-Enhanced UNet
Oct 14, 2023Lung cancer is highly lethal, emphasizing the critical need for early detection. However, identifying lung nodules poses significant challenges for radiologists, who rely heavily on their expertise for accurate diagnosis. To address this issue, computer-aided diagnosis (CAD) systems based on machine learning techniques have emerged to assist doctors in identifying lung nodules from computed tomography (CT) scans. Unfortunately, existing networks in this domain often suffer from computational complexity, leading to high rates of false negatives and false positives, limiting their effectiveness. To address these challenges, we present an innovative model that harnesses the strengths of both convolutional neural networks and vision transformers. Inspired by object detection in videos, we treat each 3D CT image as a video, individual slices as frames, and lung nodules as objects, enabling a time-series application. The primary objective of our work is to overcome hardware limitations during model training, allowing for efficient processing of 2D data while utilizing inter-slice information for accurate identification based on 3D image context. We validated the proposed network by applying a 10-fold cross-validation technique to the publicly available Lung Nodule Analysis 2016 dataset. Our proposed architecture achieves an average sensitivity criterion of 97.84% and a competition performance metrics (CPM) of 96.0% with few parameters. Comparative analysis with state-of-the-art advancements in lung nodule identification demonstrates the significant accuracy achieved by our proposed model.
Deep Bayesian Active Learning, A Brief Survey on Recent Advances
Dec 15, 2020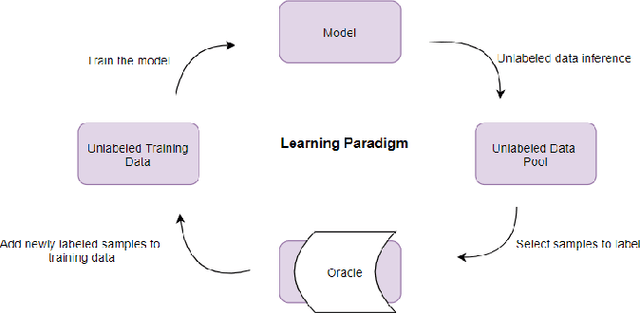
Active learning frameworks offer efficient data annotation without remarkable accuracy degradation. In other words, active learning starts training the model with a small size of labeled data while exploring the space of unlabeled data in order to select most informative samples to be labeled. Generally speaking, representing the uncertainty is crucial in any active learning framework, however, deep learning methods are not capable of either representing or manipulating model uncertainty. On the other hand, from the real world application perspective, uncertainty representation is getting more and more attention in the machine learning community. Deep Bayesian active learning frameworks and generally any Bayesian active learning settings, provide practical consideration in the model which allows training with small data while representing the model uncertainty for further efficient training. In this paper, we briefly survey recent advances in Bayesian active learning and in particular deep Bayesian active learning frameworks.
Graph-Based Method for Anomaly Prediction in Functional Brain Network
May 24, 2019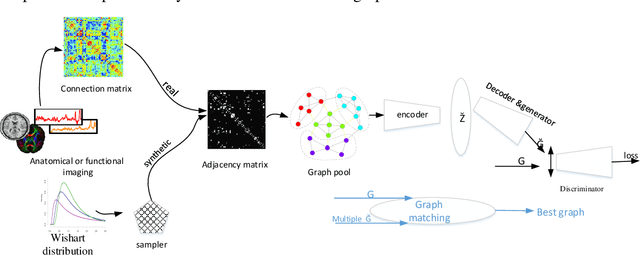
Resting-state functional MRI (rs-fMRI) in functional neuroimaging techniques have accelerated progress in brain disorders and dysfunction studies. Since, there are the slight differences between healthy and disorder brain, investigation in the complex topology of functional brain networks in human is difficult and complicated task with the growth of evaluation criteria. Recently, graph theory and deep learning applications have spread widely to understanding human cognitive functions that are linked to gene expression and related distributed spatial patterns. Irregular graph analysis has been widely applied in many brain recognition domains, these applications might involve both node-centric and graph-centric tasks. In this paper, we discuss about individual Variational Autoencoder (VAE) and Graph Convolutional Network (GCN) for the region of interest recognition areas of brain which not have normal connection when apply certain tasks. Here in, we identified a framework of Graph Auto-Encoder (GAE) with hypersphere distributer for functional data analysis in brain imaging studies that is underlying non-Euclidean structure, in learning of strong rigid graphs among large scale data. In addition, we distinguish the possible mode correlations in abnormal brain connections.
Semi-Supervised Hierarchical Semantic Object Parsing
Oct 29, 2017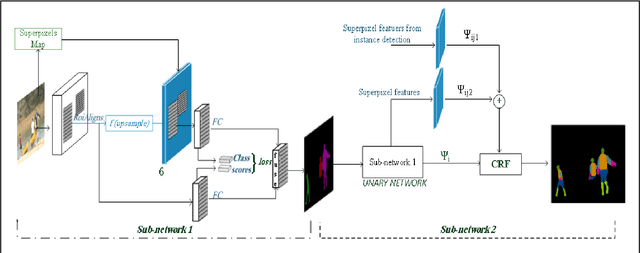
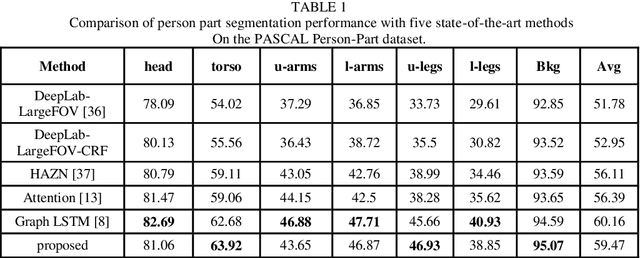
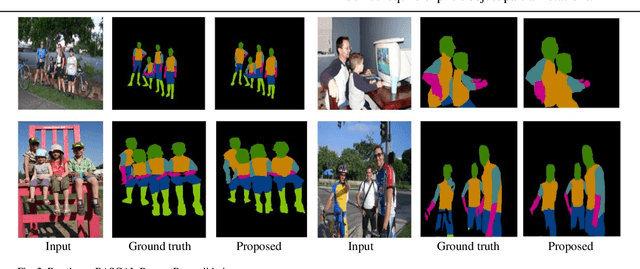
Models based on Convolutional Neural Networks (CNNs) have been proven very successful for semantic segmentation and object parsing that yield hierarchies of features. Our key insight is to build convolutional networks that take input of arbitrary size and produce object parsing output with efficient inference and learning. In this work, we focus on the task of instance segmentation and parsing which recognizes and localizes objects down to a pixel level base on deep CNN. Therefore, unlike some related work, a pixel cannot belong to multiple instances and parsing. Our model is based on a deep neural network trained for object masking that supervised with input image and follow incorporates a Conditional Random Field (CRF) with end-to-end trainable piecewise order potentials based on object parsing outputs. In each CRF unit we designed terms to capture the short range and long range dependencies from various neighbors. The accurate instance-level segmentation that our network produce is reflected by the considerable improvements obtained over previous work at high APr thresholds. We demonstrate the effectiveness of our model with extensive experiments on challenging dataset subset of PASCAL VOC2012.
Sparse Estimation with Generalized Beta Mixture and the Horseshoe Prior
Nov 10, 2014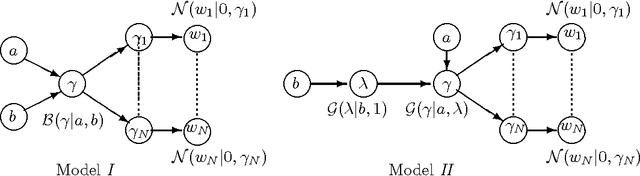
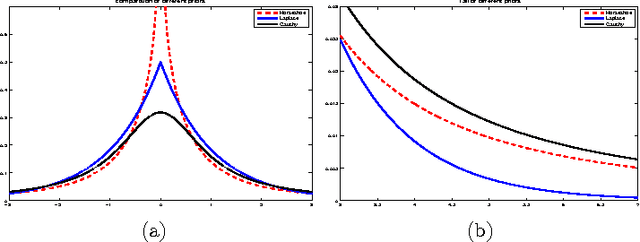
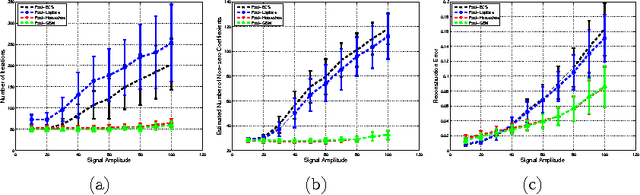
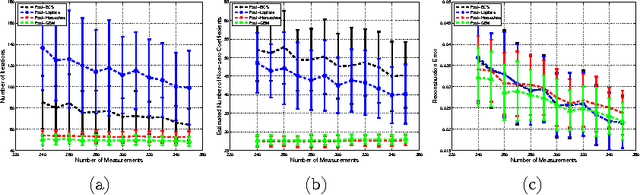
In this paper, the use of the Generalized Beta Mixture (GBM) and Horseshoe distributions as priors in the Bayesian Compressive Sensing framework is proposed. The distributions are considered in a two-layer hierarchical model, making the corresponding inference problem amenable to Expectation Maximization (EM). We present an explicit, algebraic EM-update rule for the models, yielding two fast and experimentally validated algorithms for signal recovery. Experimental results show that our algorithms outperform state-of-the-art methods on a wide range of sparsity levels and amplitudes in terms of reconstruction accuracy, convergence rate and sparsity. The largest improvement can be observed for sparse signals with high amplitudes.