 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decentralized Learning over Wireless Networks with Broadcast-Based Subgraph Sampling
Oct 24, 2023
This work centers on the communication aspects of decentralized learning over wireless networks, using consensus-based decentralized stochastic gradient descent (D-SGD). Considering the actual communication cost or delay caused by in-network information exchange in an iterative process, our goal is to achieve fast convergence of the algorithm measured by improvement per transmission slot. We propose BASS, an efficient communication framework for D-SGD over wireless networks with broadcast transmission and probabilistic subgraph sampling. In each iteration, we activate multiple subsets of non-interfering nodes to broadcast model updates to their neighbors. These subsets are randomly activated over time, with probabilities reflecting their importance in network connectivity and subject to a communication cost constraint (e.g., the average number of transmission slots per iteration). During the consensus update step, only bi-directional links are effectively preserved to maintain communication symmetry. In comparison to existing link-based scheduling methods, the inherent broadcasting nature of wireless channels offers intrinsic advantages in speeding up convergence of decentralized learning by creating more communicated links with the same number of transmission slots.
Privacy-oriented manipulation of speaker representations
Oct 10, 2023Speaker embeddings are ubiquitous, with applications ranging from speaker recognition and diarization to speech synthesis and voice anonymisation. The amount of information held by these embeddings lends them versatility, but also raises privacy concerns. Speaker embeddings have been shown to contain information on age, sex, health and more, which speakers may want to keep private, especially when this information is not required for the target task. In this work, we propose a method for removing and manipulating private attributes from speaker embeddings that leverages a Vector-Quantized Variational Autoencoder architecture, combined with an adversarial classifier and a novel mutual information loss. We validate our model on two attributes, sex and age, and perform experiments with ignorant and fully-informed attackers, and with in-domain and out-of-domain data.
Learning Comprehensive Representations with Richer Self for Text-to-Image Person Re-Identification
Oct 17, 2023Text-to-image person re-identification (TIReID) retrieves pedestrian images of the same identity based on a query text. However, existing methods for TIReID typically treat it as a one-to-one image-text matching problem, only focusing on the relationship between image-text pairs within a view. The many-to-many matching between image-text pairs across views under the same identity is not taken into account, which is one of the main reasons for the poor performance of existing methods. To this end, we propose a simple yet effective framework, called LCR$^2$S, for modeling many-to-many correspondences of the same identity by learning comprehensive representations for both modalities from a novel perspective. We construct a support set for each image (text) by using other images (texts) under the same identity and design a multi-head attentional fusion module to fuse the image (text) and its support set. The resulting enriched image and text features fuse information from multiple views, which are aligned to train a "richer" TIReID model with many-to-many correspondences. Since the support set is unavailable during inference, we propose to distill the knowledge learned by the "richer" model into a lightweight model for inference with a single image/text as input. The lightweight model focuses on semantic association and reasoning of multi-view information, which can generate a comprehensive representation containing multi-view information with only a single-view input to perform accurate text-to-image retrieval during inference. In particular, we use the intra-modal features and inter-modal semantic relations of the "richer" model to supervise the lightweight model to inherit its powerful capability. Extensive experiments demonstrate the effectiveness of LCR$^2$S, and it also achieves new state-of-the-art performance on three popular TIReID datasets.
Optimal Spatial-Temporal Triangulation for Bearing-Only Cooperative Motion Estimation
Oct 25, 2023Vision-based cooperative motion estimation is an important problem for many multi-robot systems such as cooperative aerial target pursuit. This problem can be formulated as bearing-only cooperative motion estimation, where the visual measurement is modeled as a bearing vector pointing from the camera to the target. The conventional approaches for bearing-only cooperative estimation are mainly based on the framework distributed Kalman filtering (DKF). In this paper, we propose a new optimal bearing-only cooperative estimation algorithm, named spatial-temporal triangulation, based on the method of distributed recursive least squares, which provides a more flexible framework for designing distributed estimators than DKF. The design of the algorithm fully incorporates all the available information and the specific triangulation geometric constraint. As a result, the algorithm has superior estimation performance than the state-of-the-art DKF algorithms in terms of both accuracy and convergence speed as verified by numerical simulation. We rigorously prove the exponential convergence of the proposed algorithm. Moreover, to verify the effectiveness of the proposed algorithm under practical challenging conditions, we develop a vision-based cooperative aerial target pursuit system, which is the first of such fully autonomous systems so far to the best of our knowledge.
PROMINET: Prototype-based Multi-View Network for Interpretable Email Response Prediction
Oct 25, 2023Email is a widely used tool for business communication, and email marketing has emerged as a cost-effective strategy for enterprises. While previous studies have examined factors affecting email marketing performance, limited research has focused on understanding email response behavior by considering email content and metadata. This study proposes a Prototype-based Multi-view Network (PROMINET) that incorporates semantic and structural information from email data. By utilizing prototype learning, the PROMINET model generates latent exemplars, enabling interpretable email response prediction. The model maps learned semantic and structural exemplars to observed samples in the training data at different levels of granularity, such as document, sentence, or phrase. The approach is evaluated on two real-world email datasets: the Enron corpus and an in-house Email Marketing corpus. Experimental results demonstrate that the PROMINET model outperforms baseline models, achieving a ~3% improvement in F1 score on both datasets. Additionally, the model provides interpretability through prototypes at different granularity levels while maintaining comparable performance to non-interpretable models. The learned prototypes also show potential for generating suggestions to enhance email text editing and improve the likelihood of effective email responses. This research contributes to enhancing sender-receiver communication and customer engagement in email interactions.
WSDMS: Debunk Fake News via Weakly Supervised Detection of Misinforming Sentences with Contextualized Social Wisdom
Oct 25, 2023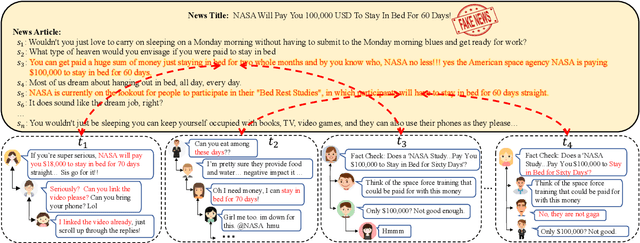
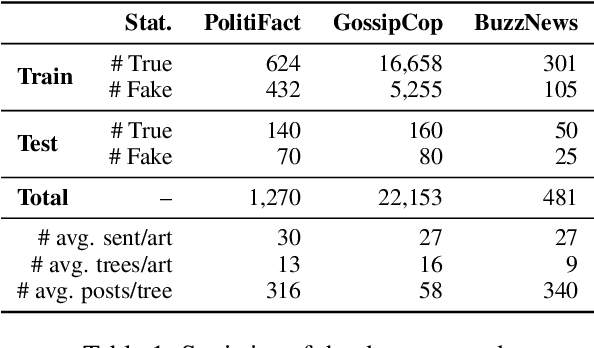
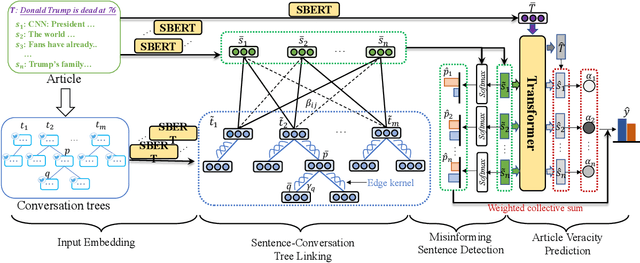
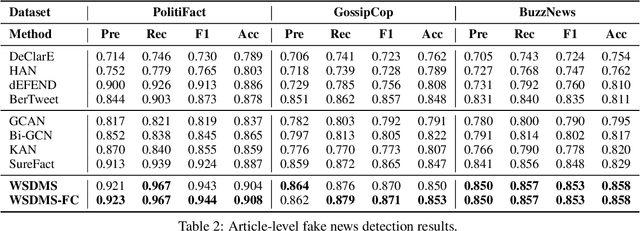
In recent years, we witness the explosion of false and unconfirmed information (i.e., rumors) that went viral on social media and shocked the public. Rumors can trigger versatile, mostly controversial stance expressions among social media users. Rumor verification and stance detection are different yet relevant tasks. Fake news debunking primarily focuses on determining the truthfulness of news articles, which oversimplifies the issue as fake news often combines elements of both truth and falsehood. Thus, it becomes crucial to identify specific instances of misinformation within the articles. In this research, we investigate a novel task in the field of fake news debunking, which involves detecting sentence-level misinformation. One of the major challenges in this task is the absence of a training dataset with sentence-level annotations regarding veracity. Inspired by the Multiple Instance Learning (MIL) approach, we propose a model called Weakly Supervised Detection of Misinforming Sentences (WSDMS). This model only requires bag-level labels for training but is capable of inferring both sentence-level misinformation and article-level veracity, aided by relevant social media conversations that are attentively contextualized with news sentences. We evaluate WSDMS on three real-world benchmarks and demonstrate that it outperforms existing state-of-the-art baselines in debunking fake news at both the sentence and article levels.
Open Knowledge Base Canonicalization with Multi-task Unlearning
Oct 25, 2023
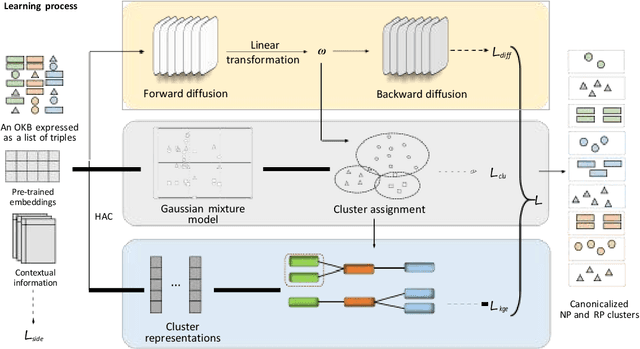
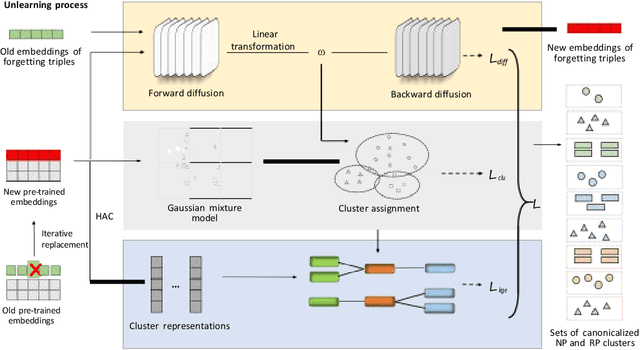

The construction of large open knowledge bases (OKBs) is integral to many applications in the field of mobile computing. Noun phrases and relational phrases in OKBs often suffer from redundancy and ambiguity, which calls for the investigation on OKB canonicalization. However, in order to meet the requirements of some privacy protection regulations and to ensure the timeliness of the data, the canonicalized OKB often needs to remove some sensitive information or outdated data. The machine unlearning in OKB canonicalization is an excellent solution to the above problem. Current solutions address OKB canonicalization by devising advanced clustering algorithms and using knowledge graph embedding (KGE) to further facilitate the canonicalization process. Effective schemes are urgently needed to fully synergise machine unlearning with clustering and KGE learning. To this end, we put forward a multi-task unlearning framework, namely MulCanon, to tackle machine unlearning problem in OKB canonicalization. Specifically, the noise characteristics in the diffusion model are utilized to achieve the effect of machine unlearning for data in OKB. MulCanon unifies the learning objectives of diffusion model, KGE and clustering algorithms, and adopts a two-step multi-task learning paradigm for training. A thorough experimental study on popular OKB canonicalization datasets validates that MulCanon achieves advanced machine unlearning effects.
Bayesian Domain Invariant Learning via Posterior Generalization of Parameter Distributions
Oct 25, 2023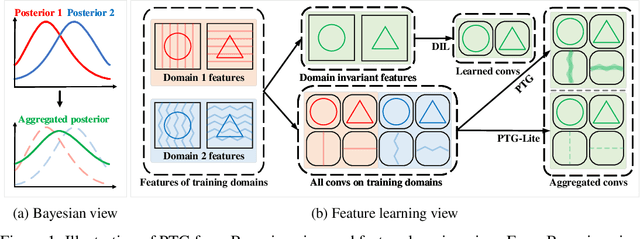
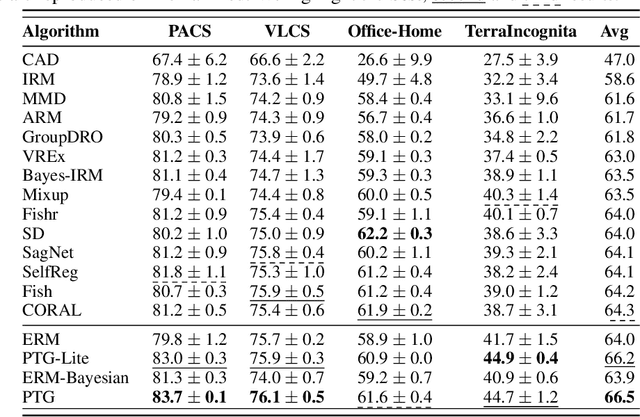

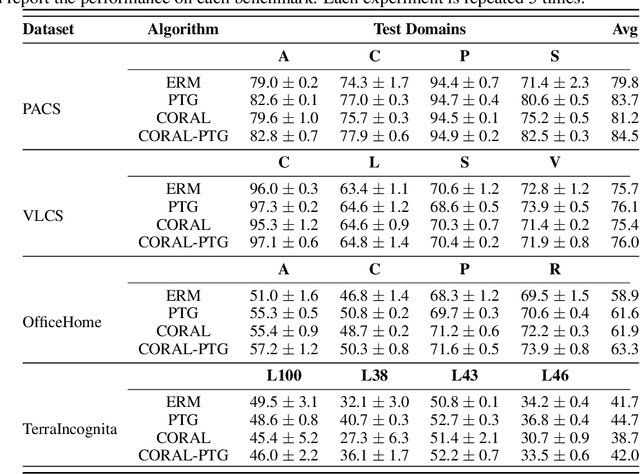
Domain invariant learning aims to learn models that extract invariant features over various training domains, resulting in better generalization to unseen target domains. Recently, Bayesian Neural Networks have achieved promising results in domain invariant learning, but most works concentrate on aligning features distributions rather than parameter distributions. Inspired by the principle of Bayesian Neural Network, we attempt to directly learn the domain invariant posterior distribution of network parameters. We first propose a theorem to show that the invariant posterior of parameters can be implicitly inferred by aggregating posteriors on different training domains. Our assumption is more relaxed and allows us to extract more domain invariant information. We also propose a simple yet effective method, named PosTerior Generalization (PTG), that can be used to estimate the invariant parameter distribution. PTG fully exploits variational inference to approximate parameter distributions, including the invariant posterior and the posteriors on training domains. Furthermore, we develop a lite version of PTG for widespread applications. PTG shows competitive performance on various domain generalization benchmarks on DomainBed. Additionally, PTG can use any existing domain generalization methods as its prior, and combined with previous state-of-the-art method the performance can be further improved. Code will be made public.
Causal Discovery with Generalized Linear Models through Peeling Algorithms
Oct 25, 2023This article presents a novel method for causal discovery with generalized structural equation models suited for analyzing diverse types of outcomes, including discrete, continuous, and mixed data. Causal discovery often faces challenges due to unmeasured confounders that hinder the identification of causal relationships. The proposed approach addresses this issue by developing two peeling algorithms (bottom-up and top-down) to ascertain causal relationships and valid instruments. This approach first reconstructs a super-graph to represent ancestral relationships between variables, using a peeling algorithm based on nodewise GLM regressions that exploit relationships between primary and instrumental variables. Then, it estimates parent-child effects from the ancestral relationships using another peeling algorithm while deconfounding a child's model with information borrowed from its parents' models. The article offers a theoretical analysis of the proposed approach, which establishes conditions for model identifiability and provides statistical guarantees for accurately discovering parent-child relationships via the peeling algorithms. Furthermore, the article presents numerical experiments showcasing the effectiveness of our approach in comparison to state-of-the-art structure learning methods without confounders. Lastly, it demonstrates an application to Alzheimer's disease (AD), highlighting the utility of the method in constructing gene-to-gene and gene-to-disease regulatory networks involving Single Nucleotide Polymorphisms (SNPs) for healthy and AD subjects.
Video Referring Expression Comprehension via Transformer with Content-conditioned Query
Oct 25, 2023
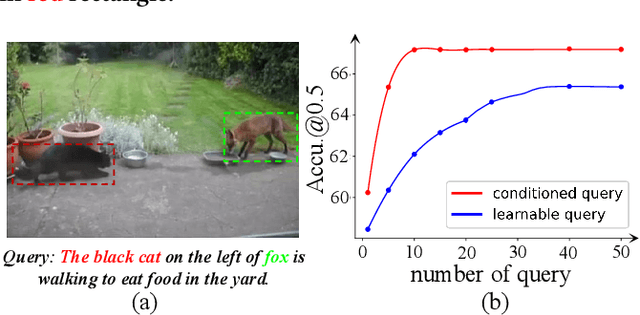
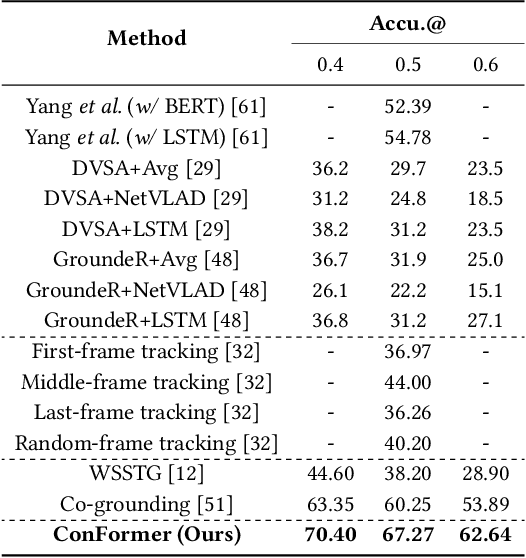
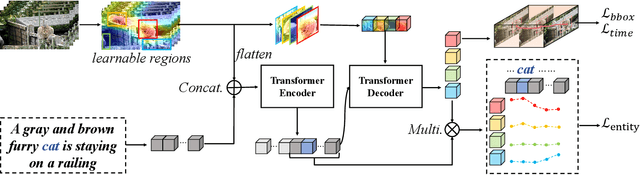
Video Referring Expression Comprehension (REC) aims to localize a target object in videos based on the queried natural language. Recent improvements in video REC have been made using Transformer-based methods with learnable queries. However, we contend that this naive query design is not ideal given the open-world nature of video REC brought by text supervision. With numerous potential semantic categories, relying on only a few slow-updated queries is insufficient to characterize them. Our solution to this problem is to create dynamic queries that are conditioned on both the input video and language to model the diverse objects referred to. Specifically, we place a fixed number of learnable bounding boxes throughout the frame and use corresponding region features to provide prior information. Also, we noticed that current query features overlook the importance of cross-modal alignment. To address this, we align specific phrases in the sentence with semantically relevant visual areas, annotating them in existing video datasets (VID-Sentence and VidSTG). By incorporating these two designs, our proposed model (called ConFormer) outperforms other models on widely benchmarked datasets. For example, in the testing split of VID-Sentence dataset, ConFormer achieves 8.75% absolute improvement on Accu.@0.6 compared to the previous state-of-the-art model.