 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYMDIREC: A Neuro-Symbolic Divide-Retrieve-Conquer Framework for Enhanced RTL Synthesis and Summarization
Mar 17, 2026Register-Transfer Level (RTL) synthesis and summarization are central to hardware design automation but remain challenging for Large Language Models (LLMs) due to rigid HDL syntax, limited supervision, and weak alignment with natural language. Existing prompting and retrieval-augmented generation (RAG) methods have not incorporated symbolic planning, limiting their structural precision. We introduce SYMDIREC, a neuro-symbolic framework that decomposes RTL tasks into symbolic subgoals, retrieves relevant code via a fine-tuned retriever, and assembles verified outputs through LLM reasoning. Supporting both Verilog and VHDL without LLM fine-tuning, SYMDIREC achieves ~20% higher Pass@1 rates for synthesis and 15-20% ROUGE-L improvements for summarization over prompting and RAG baselines, demonstrating the benefits of symbolic guidance in RTL tasks.
CODMAS: A Dialectic Multi-Agent Collaborative Framework for Structured RTL Optimization
Mar 17, 2026Optimizing Register Transfer Level (RTL) code is a critical step in Electronic Design Automation (EDA) for improving power, performance, and area (PPA). We present CODMAS (Collaborative Optimization via a Dialectic Multi-Agent System), a framework that combines structured dialectic reasoning with domain-aware code generation and deterministic evaluation to automate RTL optimization. At the core of CODMAS are two dialectic agents: the Articulator, inspired by rubber-duck debugging, which articulates stepwise transformation plans and exposes latent assumptions; and the Hypothesis Partner, which predicts outcomes and reconciles deviations between expected and actual behavior to guide targeted refinements. These agents direct a Domain-Specific Coding Agent (DCA) to generate architecture-aware Verilog edits and a Code Evaluation Agent (CEA) to verify syntax, functionality, and PPA metrics. We introduce RTLOPT, a benchmark of 120 Verilog triples (unoptimized, optimized, testbench) for pipelining and clock-gating transformations. Across proprietary and open LLMs, CODMAS achieves ~25% reduction in critical path delay for pipelining and ~22% power reduction for clock gating, while reducing functional and compilation failures compared to strong prompting and agentic baselines. These results demonstrate that structured multi-agent reasoning can significantly enhance automated RTL optimization and scale to more complex designs and broader optimization tasks.
Chain-of-Descriptions: Improving Code LLMs for VHDL Code Generation and Summarization
Jul 16, 2025Large Language Models (LLMs) have become widely used across diverse NLP tasks and domains, demonstrating their adaptability and effectiveness. In the realm of Electronic Design Automation (EDA), LLMs show promise for tasks like Register-Transfer Level (RTL) code generation and summarization. However, despite the proliferation of LLMs for general code-related tasks, there's a dearth of research focused on evaluating and refining these models for hardware description languages (HDLs), notably VHDL. In this study, we evaluate the performance of existing code LLMs for VHDL code generation and summarization using various metrics and two datasets -- VHDL-Eval and VHDL-Xform. The latter, an in-house dataset, aims to gauge LLMs' understanding of functionally equivalent code. Our findings reveal consistent underperformance of these models across different metrics, underscoring a significant gap in their suitability for this domain. To address this challenge, we propose Chain-of-Descriptions (CoDes), a novel approach to enhance the performance of LLMs for VHDL code generation and summarization tasks. CoDes involves generating a series of intermediate descriptive steps based on: (i) the problem statement for code generation, and (ii) the VHDL code for summarization. These steps are then integrated with the original input prompt (problem statement or code) and provided as input to the LLMs to generate the final output. Our experiments demonstrate that the CoDes approach significantly surpasses the standard prompting strategy across various metrics on both datasets. This method not only improves the quality of VHDL code generation and summarization but also serves as a framework for future research aimed at enhancing code LLMs for VHDL.
DECASTE: Unveiling Caste Stereotypes in Large Language Models through Multi-Dimensional Bias Analysis
May 20, 2025Recent advancements in large language models (LLMs) have revolutionized natural language processing (NLP) and expanded their applications across diverse domains. However, despite their impressive capabilities, LLMs have been shown to reflect and perpetuate harmful societal biases, including those based on ethnicity, gender, and religion. A critical and underexplored issue is the reinforcement of caste-based biases, particularly towards India's marginalized caste groups such as Dalits and Shudras. In this paper, we address this gap by proposing DECASTE, a novel, multi-dimensional framework designed to detect and assess both implicit and explicit caste biases in LLMs. Our approach evaluates caste fairness across four dimensions: socio-cultural, economic, educational, and political, using a range of customized prompting strategies. By benchmarking several state-of-the-art LLMs, we reveal that these models systematically reinforce caste biases, with significant disparities observed in the treatment of oppressed versus dominant caste groups. For example, bias scores are notably elevated when comparing Dalits and Shudras with dominant caste groups, reflecting societal prejudices that persist in model outputs. These results expose the subtle yet pervasive caste biases in LLMs and emphasize the need for more comprehensive and inclusive bias evaluation methodologies that assess the potential risks of deploying such models in real-world contexts.
Self-Regulated Data-Free Knowledge Amalgamation for Text Classification
Jun 16, 2024



Recently, there has been a growing availability of pre-trained text models on various model repositories. These models greatly reduce the cost of training new models from scratch as they can be fine-tuned for specific tasks or trained on large datasets. However, these datasets may not be publicly accessible due to the privacy, security, or intellectual property issues. In this paper, we aim to develop a lightweight student network that can learn from multiple teacher models without accessing their original training data. Hence, we investigate Data-Free Knowledge Amalgamation (DFKA), a knowledge-transfer task that combines insights from multiple pre-trained teacher models and transfers them effectively to a compact student network. To accomplish this, we propose STRATANET, a modeling framework comprising: (a) a steerable data generator that produces text data tailored to each teacher and (b) an amalgamation module that implements a self-regulative strategy using confidence estimates from the teachers' different layers to selectively integrate their knowledge and train a versatile student. We evaluate our method on three benchmark text classification datasets with varying labels or domains. Empirically, we demonstrate that the student model learned using our STRATANET outperforms several baselines significantly under data-driven and data-free constraints.
VHDL-Eval: A Framework for Evaluating Large Language Models in VHDL Code Generation
Jun 06, 2024



With the unprecedented advancements in Large Language Models (LLMs), their application domains have expanded to include code generation tasks across various programming languages. While significant progress has been made in enhancing LLMs for popular programming languages, there exists a notable gap in comprehensive evaluation frameworks tailored for Hardware Description Languages (HDLs), particularly VHDL. This paper addresses this gap by introducing a comprehensive evaluation framework designed specifically for assessing LLM performance in VHDL code generation task. We construct a dataset for evaluating LLMs on VHDL code generation task. This dataset is constructed by translating a collection of Verilog evaluation problems to VHDL and aggregating publicly available VHDL problems, resulting in a total of 202 problems. To assess the functional correctness of the generated VHDL code, we utilize a curated set of self-verifying testbenches specifically designed for those aggregated VHDL problem set. We conduct an initial evaluation of different LLMs and their variants, including zero-shot code generation, in-context learning (ICL), and Parameter-efficient fine-tuning (PEFT) methods. Our findings underscore the considerable challenges faced by existing LLMs in VHDL code generation, revealing significant scope for improvement. This study emphasizes the necessity of supervised fine-tuning code generation models specifically for VHDL, offering potential benefits to VHDL designers seeking efficient code generation solutions.
PROMINET: Prototype-based Multi-View Network for Interpretable Email Response Prediction
Oct 25, 2023



Email is a widely used tool for business communication, and email marketing has emerged as a cost-effective strategy for enterprises. While previous studies have examined factors affecting email marketing performance, limited research has focused on understanding email response behavior by considering email content and metadata. This study proposes a Prototype-based Multi-view Network (PROMINET) that incorporates semantic and structural information from email data. By utilizing prototype learning, the PROMINET model generates latent exemplars, enabling interpretable email response prediction. The model maps learned semantic and structural exemplars to observed samples in the training data at different levels of granularity, such as document, sentence, or phrase. The approach is evaluated on two real-world email datasets: the Enron corpus and an in-house Email Marketing corpus. Experimental results demonstrate that the PROMINET model outperforms baseline models, achieving a ~3% improvement in F1 score on both datasets. Additionally, the model provides interpretability through prototypes at different granularity levels while maintaining comparable performance to non-interpretable models. The learned prototypes also show potential for generating suggestions to enhance email text editing and improve the likelihood of effective email responses. This research contributes to enhancing sender-receiver communication and customer engagement in email interactions.
M-SENSE: Modeling Narrative Structure in Short Personal Narratives Using Protagonist's Mental Representations
Feb 18, 2023Narrative is a ubiquitous component of human communication. Understanding its structure plays a critical role in a wide variety of applications, ranging from simple comparative analyses to enhanced narrative retrieval, comprehension, or reasoning capabilities. Prior research in narratology has highlighted the importance of studying the links between cognitive and linguistic aspects of narratives for effective comprehension. This interdependence is related to the textual semantics and mental language in narratives, referring to characters' motivations, feelings or emotions, and beliefs. However, this interdependence is hardly explored for modeling narratives. In this work, we propose the task of automatically detecting prominent elements of the narrative structure by analyzing the role of characters' inferred mental state along with linguistic information at the syntactic and semantic levels. We introduce a STORIES dataset of short personal narratives containing manual annotations of key elements of narrative structure, specifically climax and resolution. To this end, we implement a computational model that leverages the protagonist's mental state information obtained from a pre-trained model trained on social commonsense knowledge and integrates their representations with contextual semantic embed-dings using a multi-feature fusion approach. Evaluating against prior zero-shot and supervised baselines, we find that our model is able to achieve significant improvements in the task of identifying climax and resolution.
Interpretable Multi-Modal Hate Speech Detection
Mar 02, 2021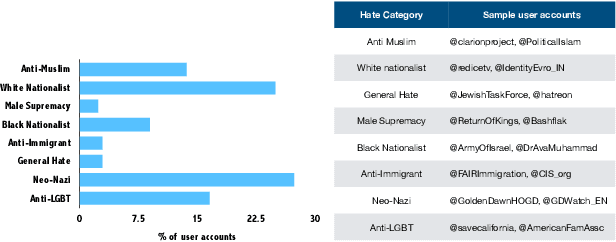

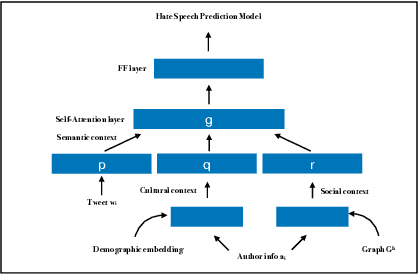
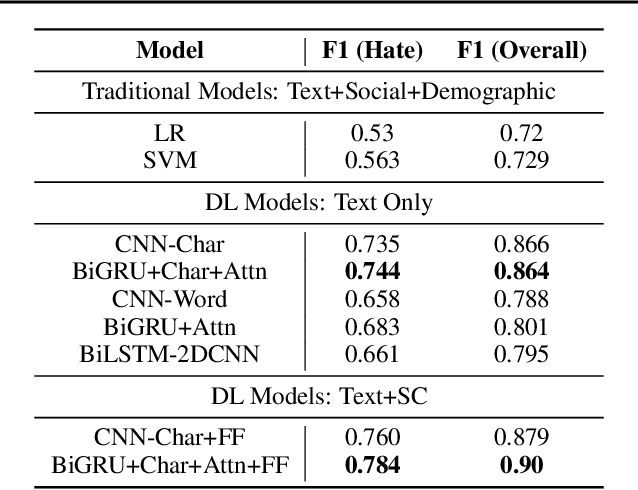
With growing role of social media in shaping public opinions and beliefs across the world, there has been an increased attention to identify and counter the problem of hate speech on social media. Hate speech on online spaces has serious manifestations, including social polarization and hate crimes. While prior works have proposed automated techniques to detect hate speech online, these techniques primarily fail to look beyond the textual content. Moreover, few attempts have been made to focus on the aspects of interpretability of such models given the social and legal implications of incorrect predictions. In this work, we propose a deep neural multi-modal model that can: (a) detect hate speech by effectively capturing the semantics of the text along with socio-cultural context in which a particular hate expression is made, and (b) provide interpretable insights into decisions of our model. By performing a thorough evaluation of different modeling techniques, we demonstrate that our model is able to outperform the existing state-of-the-art hate speech classification approaches. Finally, we show the importance of social and cultural context features towards unearthing clusters associated with different categories of hate.
* 5 pages, Accepted at the International Conference on Machine Learning AI for Social Good Workshop, Long Beach, United States, 2019
Video SemNet: Memory-Augmented Video Semantic Network
Nov 22, 2020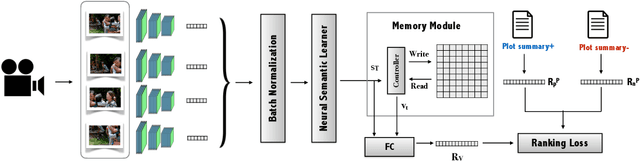
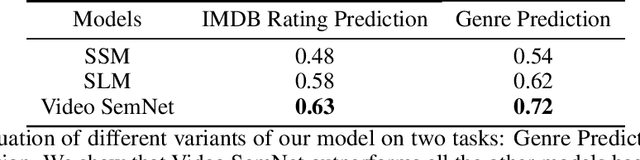
Stories are a very compelling medium to convey ideas, experiences, social and cultural values. Narrative is a specific manifestation of the story that turns it into knowledge for the audience. In this paper, we propose a machine learning approach to capture the narrative elements in movies by bridging the gap between the low-level data representations and semantic aspects of the visual medium. We present a Memory-Augmented Video Semantic Network, called Video SemNet, to encode the semantic descriptors and learn an embedding for the video. The model employs two main components: (i) a neural semantic learner that learns latent embeddings of semantic descriptors and (ii) a memory module that retains and memorizes specific semantic patterns from the video. We evaluate the video representations obtained from variants of our model on two tasks: (a) genre prediction and (b) IMDB Rating prediction. We demonstrate that our model is able to predict genres and IMDB ratings with a weighted F-1 score of 0.72 and 0.63 respectively. The results are indicative of the representational power of our model and the ability of such representations to measure audience engagement.