 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Nest-DGIL: Nesterov-optimized Deep Geometric Incremental Learning for CS Image Reconstruction
Aug 06, 2023
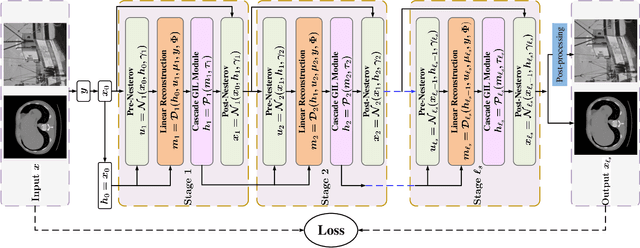
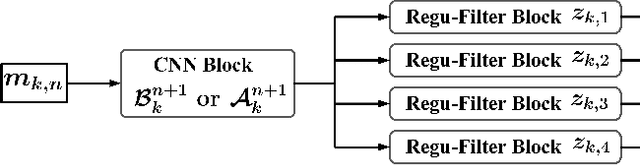
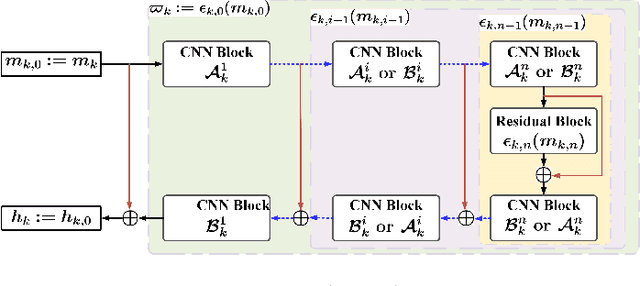
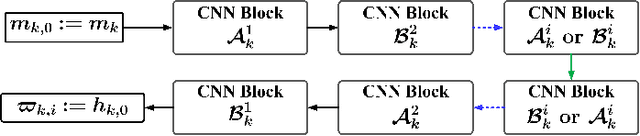
Proximal gradient-based optimization is one of the most common strategies for solving image inverse problems as well as easy to implement. However, these techniques often generate heavy artifacts in image reconstruction. One of the most popular refinement methods is to fine-tune the regularization parameter to alleviate such artifacts, but it may not always be sufficient or applicable due to increased computational costs. In this work, we propose a deep geometric incremental learning framework based on second Nesterov proximal gradient optimization. The proposed end-to-end network not only has the powerful learning ability for high/low frequency image features,but also can theoretically guarantee that geometric texture details will be reconstructed from preliminary linear reconstruction.Furthermore, it can avoid the risk of intermediate reconstruction results falling outside the geometric decomposition domains and achieve fast convergence. Our reconstruction framework is decomposed into four modules including general linear reconstruction, cascade geometric incremental restoration, Nesterov acceleration and post-processing. In the image restoration step,a cascade geometric incremental learning module is designed to compensate for the missing texture information from different geometric spectral decomposition domains. Inspired by overlap-tile strategy, we also develop a post-processing module to remove the block-effect in patch-wise-based natural image reconstruction. All parameters in the proposed model are learnable,an adaptive initialization technique of physical-parameters is also employed to make model flexibility and ensure converging smoothly. We compare the reconstruction performance of the proposed method with existing state-of-the-art methods to demonstrate its superiority. Our source codes are available at https://github.com/fanxiaohong/Nest-DGIL.
Frequency Disentangled Features in Neural Image Compression
Aug 04, 2023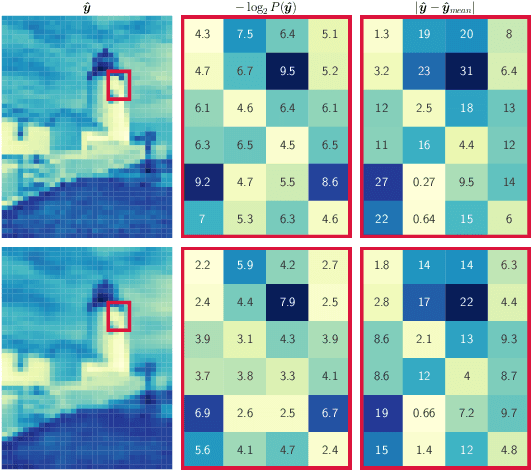

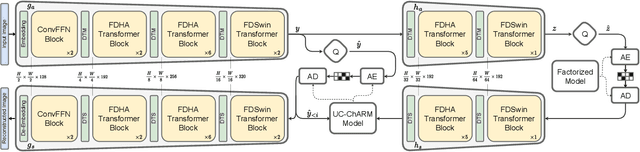
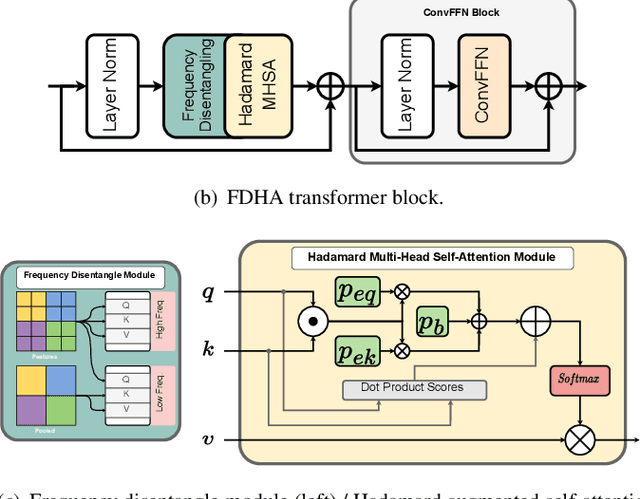
The design of a neural image compression network is governed by how well the entropy model matches the true distribution of the latent code. Apart from the model capacity, this ability is indirectly under the effect of how close the relaxed quantization is to the actual hard quantization. Optimizing the parameters of a rate-distortion variational autoencoder (R-D VAE) is ruled by this approximated quantization scheme. In this paper, we propose a feature-level frequency disentanglement to help the relaxed scalar quantization achieve lower bit rates by guiding the high entropy latent features to include most of the low-frequency texture of the image. In addition, to strengthen the de-correlating power of the transformer-based analysis/synthesis transform, an augmented self-attention score calculation based on the Hadamard product is utilized during both encoding and decoding. Channel-wise autoregressive entropy modeling takes advantage of the proposed frequency separation as it inherently directs high-informational low-frequency channels to the first chunks and conditions the future chunks on it. The proposed network not only outperforms hand-engineered codecs, but also neural network-based codecs built on computation-heavy spatially autoregressive entropy models.
You Do Not Need Additional Priors in Camouflage Object Detection
Oct 01, 2023
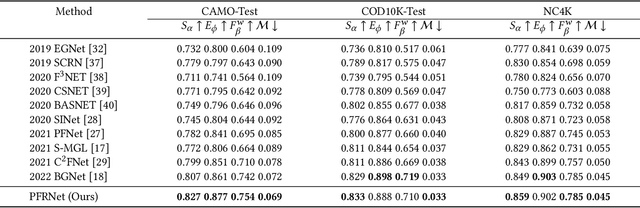
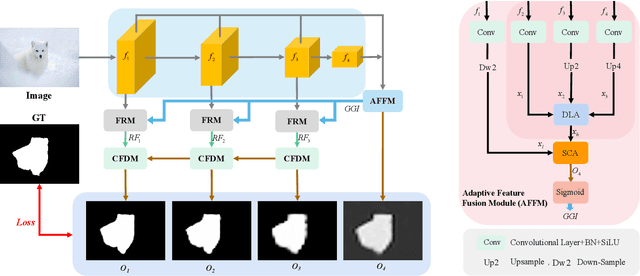
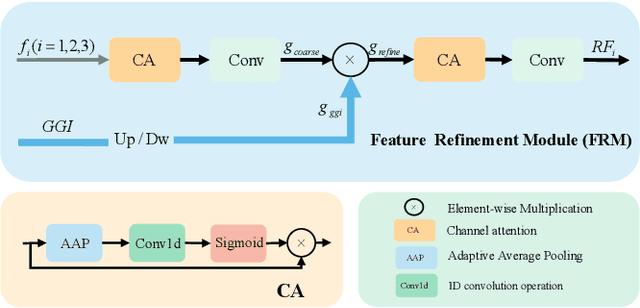
Camouflage object detection (COD) poses a significant challenge due to the high resemblance between camouflaged objects and their surroundings. Although current deep learning methods have made significant progress in detecting camouflaged objects, many of them heavily rely on additional prior information. However, acquiring such additional prior information is both expensive and impractical in real-world scenarios. Therefore, there is a need to develop a network for camouflage object detection that does not depend on additional priors. In this paper, we propose a novel adaptive feature aggregation method that effectively combines multi-layer feature information to generate guidance information. In contrast to previous approaches that rely on edge or ranking priors, our method directly leverages information extracted from image features to guide model training. Through extensive experimental results, we demonstrate that our proposed method achieves comparable or superior performance when compared to state-of-the-art approaches.
Multi-spectral Entropy Constrained Neural Compression of Solar Imagery
Sep 19, 2023Missions studying the dynamic behaviour of the Sun are defined to capture multi-spectral images of the sun and transmit them to the ground station in a daily basis. To make transmission efficient and feasible, image compression systems need to be exploited. Recently successful end-to-end optimized neural network-based image compression systems have shown great potential to be used in an ad-hoc manner. In this work we have proposed a transformer-based multi-spectral neural image compressor to efficiently capture redundancies both intra/inter-wavelength. To unleash the locality of window-based self attention mechanism, we propose an inter-window aggregated token multi head self attention. Additionally to make the neural compressor autoencoder shift invariant, a randomly shifted window attention mechanism is used which makes the transformer blocks insensitive to translations in their input domain. We demonstrate that the proposed approach not only outperforms the conventional compression algorithms but also it is able to better decorrelates images along the multiple wavelengths compared to single spectral compression.
Exploiting Causality Signals in Medical Images: A Pilot Study with Empirical Results
Sep 19, 2023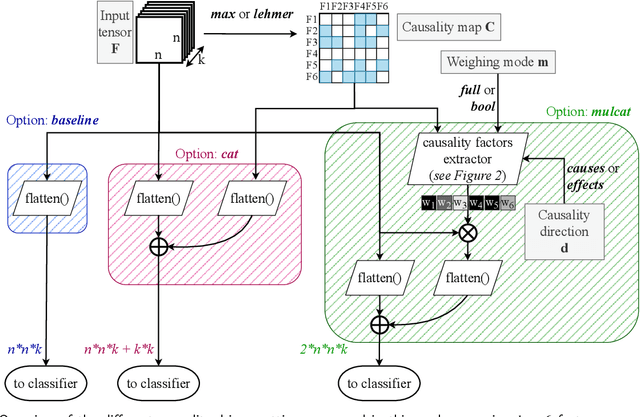
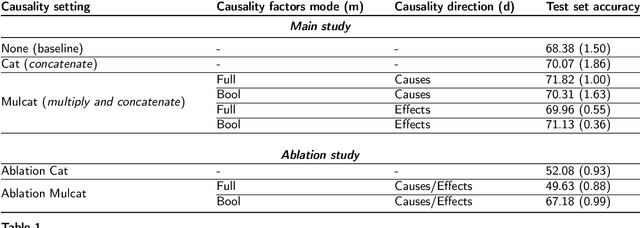
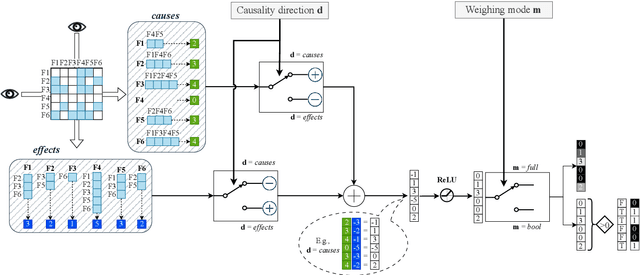
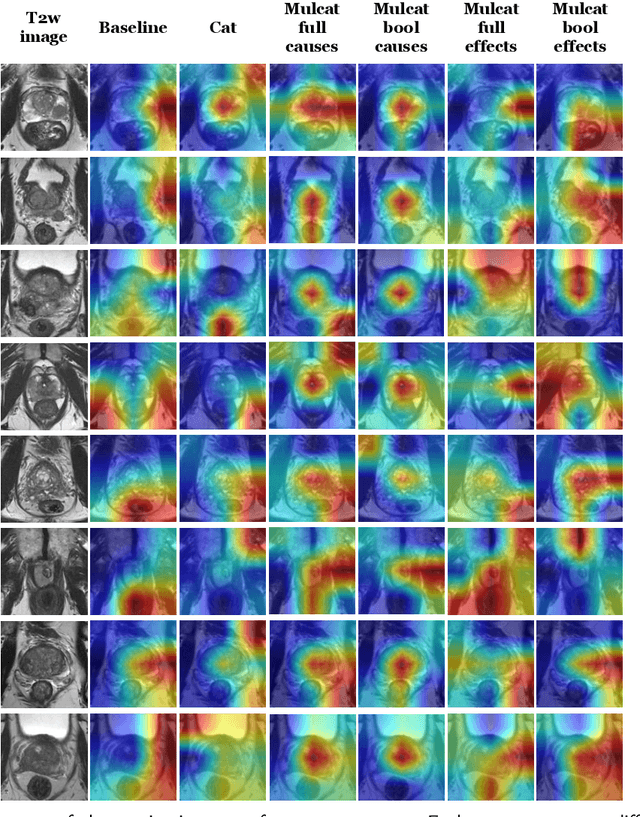
We present a new method for automatically classifying medical images that uses weak causal signals in the scene to model how the presence of a feature in one part of the image affects the appearance of another feature in a different part of the image. Our method consists of two components: a convolutional neural network backbone and a causality-factors extractor module. The latter computes weights for the feature maps to enhance each feature map according to its causal influence in the image's scene. We can modify the functioning of the causality module by using two external signals, thus obtaining different variants of our method. We evaluate our method on a public dataset of prostate MRI images for prostate cancer diagnosis, using quantitative experiments, qualitative assessment, and ablation studies. Our results show that our method improves classification performance and produces more robust predictions, focusing on relevant parts of the image. That is especially important in medical imaging, where accurate and reliable classifications are essential for effective diagnosis and treatment planning.
GETAvatar: Generative Textured Meshes for Animatable Human Avatars
Oct 04, 2023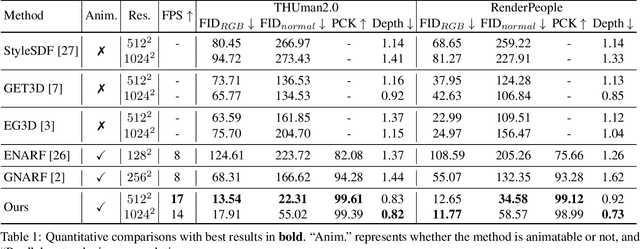
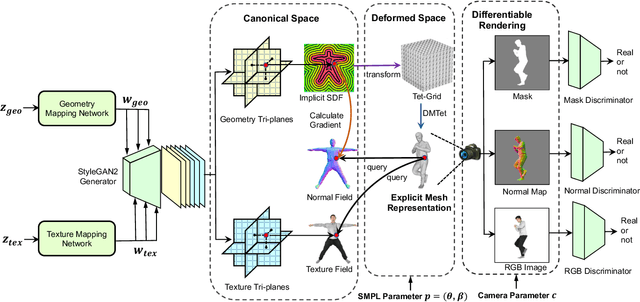
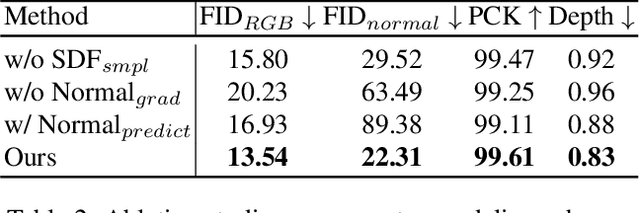

We study the problem of 3D-aware full-body human generation, aiming at creating animatable human avatars with high-quality textures and geometries. Generally, two challenges remain in this field: i) existing methods struggle to generate geometries with rich realistic details such as the wrinkles of garments; ii) they typically utilize volumetric radiance fields and neural renderers in the synthesis process, making high-resolution rendering non-trivial. To overcome these problems, we propose GETAvatar, a Generative model that directly generates Explicit Textured 3D meshes for animatable human Avatar, with photo-realistic appearance and fine geometric details. Specifically, we first design an articulated 3D human representation with explicit surface modeling, and enrich the generated humans with realistic surface details by learning from the 2D normal maps of 3D scan data. Second, with the explicit mesh representation, we can use a rasterization-based renderer to perform surface rendering, allowing us to achieve high-resolution image generation efficiently. Extensive experiments demonstrate that GETAvatar achieves state-of-the-art performance on 3D-aware human generation both in appearance and geometry quality. Notably, GETAvatar can generate images at 512x512 resolution with 17FPS and 1024x1024 resolution with 14FPS, improving upon previous methods by 2x. Our code and models will be available.
Task-driven Compression for Collision Encoding based on Depth Images
Sep 11, 2023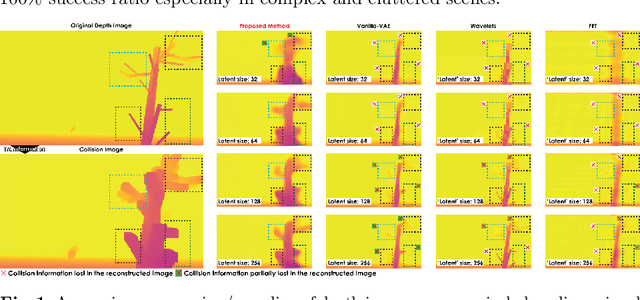

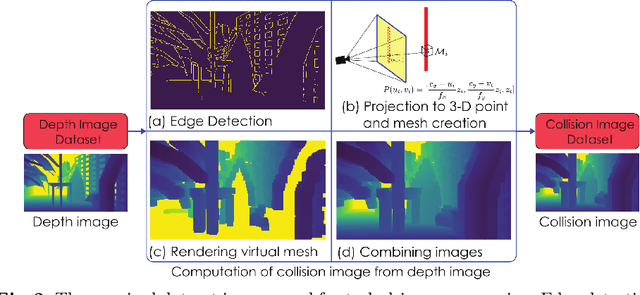

This paper contributes a novel learning-based method for aggressive task-driven compression of depth images and their encoding as images tailored to collision prediction for robotic systems. A novel 3D image processing methodology is proposed that accounts for the robot's size in order to appropriately "inflate" the obstacles represented in the depth image and thus obtain the distance that can be traversed by the robot in a collision-free manner along any given ray within the camera frustum. Such depth-and-collision image pairs are used to train a neural network that follows the architecture of Variational Autoencoders to compress-and-transform the information in the original depth image to derive a latent representation that encodes the collision information for the given depth image. We compare our proposed task-driven encoding method with classical task-agnostic methods and demonstrate superior performance for the task of collision image prediction from extremely low-dimensional latent spaces. A set of comparative studies show that the proposed approach is capable of encoding depth image-and-collision image tuples from complex scenes with thin obstacles at long distances better than the classical methods at compression ratios as high as 4050:1.
Design of Novel Loss Functions for Deep Learning in X-ray CT
Sep 23, 2023Deep learning (DL) shows promise of advantages over conventional signal processing techniques in a variety of imaging applications. The networks' being trained from examples of data rather than explicitly designed allows them to learn signal and noise characteristics to most effectively construct a mapping from corrupted data to higher quality representations. In inverse problems, one has options of applying DL in the domain of the originally captured data, in the transformed domain of the desired final representation, or both. X-ray computed tomography (CT), one of the most valuable tools in medical diagnostics, is already being improved by DL methods. Whether for removal of common quantum noise resulting from the Poisson-distributed photon counts, or for reduction of the ill effects of metal implants on image quality, researchers have begun employing DL widely in CT. The selection of training data is driven quite directly by the corruption on which the focus lies. However, the way in which differences between the target signal and measured data is penalized in training generally follows conventional, pointwise loss functions. This work introduces a creative technique for favoring reconstruction characteristics that are not well described by norms such as mean-squared or mean-absolute error. Particularly in a field such as X-ray CT, where radiologists' subjective preferences in image characteristics are key to acceptance, it may be desirable to penalize differences in DL more creatively. This penalty may be applied in the data domain, here the CT sinogram, or in the reconstructed image. We design loss functions for both shaping and selectively preserving frequency content of the signal.
Randomize to Generalize: Domain Randomization for Runway FOD Detection
Sep 23, 2023Tiny Object Detection is challenging due to small size, low resolution, occlusion, background clutter, lighting conditions and small object-to-image ratio. Further, object detection methodologies often make underlying assumption that both training and testing data remain congruent. However, this presumption often leads to decline in performance when model is applied to out-of-domain(unseen) data. Techniques like synthetic image generation are employed to improve model performance by leveraging variations in input data. Such an approach typically presumes access to 3D-rendered datasets. In contrast, we propose a novel two-stage methodology Synthetic Randomized Image Augmentation (SRIA), carefully devised to enhance generalization capabilities of models encountering 2D datasets, particularly with lower resolution which is more practical in real-world scenarios. The first stage employs a weakly supervised technique to generate pixel-level segmentation masks. Subsequently, the second stage generates a batch-wise synthesis of artificial images, carefully designed with an array of diverse augmentations. The efficacy of proposed technique is illustrated on challenging foreign object debris (FOD) detection. We compare our results with several SOTA models including CenterNet, SSD, YOLOv3, YOLOv4, YOLOv5, and Outer Vit on a publicly available FOD-A dataset. We also construct an out-of-distribution test set encompassing 800 annotated images featuring a corpus of ten common categories. Notably, by harnessing merely 1.81% of objects from source training data and amalgamating with 29 runway background images, we generate 2227 synthetic images. Subsequent model retraining via transfer learning, utilizing enriched dataset generated by domain randomization, demonstrates significant improvement in detection accuracy. We report that detection accuracy improved from an initial 41% to 92% for OOD test set.
MedSyn: Text-guided Anatomy-aware Synthesis of High-Fidelity 3D CT Images
Oct 06, 2023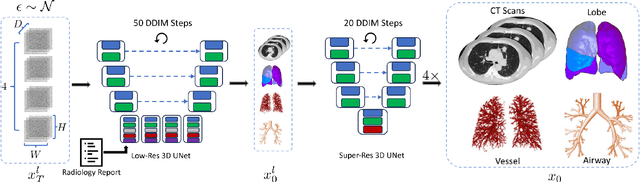
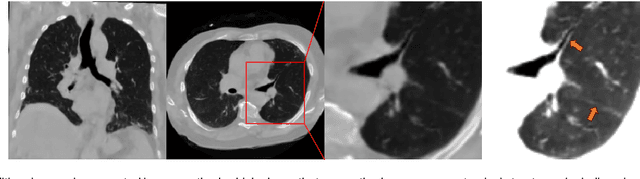
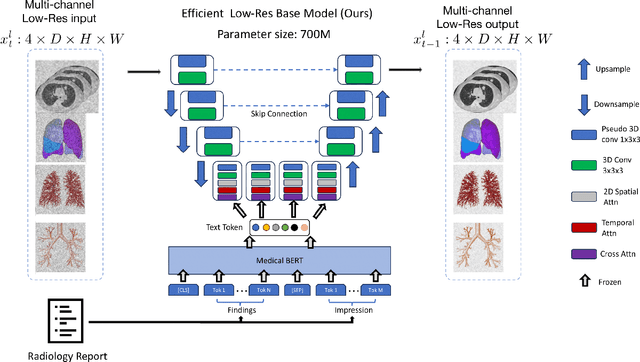
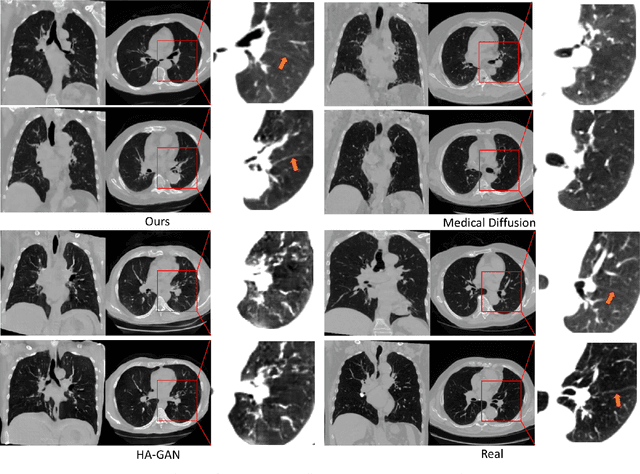
This paper introduces an innovative methodology for producing high-quality 3D lung CT images guided by textual information. While diffusion-based generative models are increasingly used in medical imaging, current state-of-the-art approaches are limited to low-resolution outputs and underutilize radiology reports' abundant information. The radiology reports can enhance the generation process by providing additional guidance and offering fine-grained control over the synthesis of images. Nevertheless, expanding text-guided generation to high-resolution 3D images poses significant memory and anatomical detail-preserving challenges. Addressing the memory issue, we introduce a hierarchical scheme that uses a modified UNet architecture. We start by synthesizing low-resolution images conditioned on the text, serving as a foundation for subsequent generators for complete volumetric data. To ensure the anatomical plausibility of the generated samples, we provide further guidance by generating vascular, airway, and lobular segmentation masks in conjunction with the CT images. The model demonstrates the capability to use textual input and segmentation tasks to generate synthesized images. The results of comparative assessments indicate that our approach exhibits superior performance compared to the most advanced models based on GAN and diffusion techniques, especially in accurately retaining crucial anatomical features such as fissure lines, airways, and vascular structures. This innovation introduces novel possibilities. This study focuses on two main objectives: (1) the development of a method for creating images based on textual prompts and anatomical components, and (2) the capability to generate new images conditioning on anatomical elements. The advancements in image generation can be applied to enhance numerous downstream tasks.