 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MotionDirector: Motion Customization of Text-to-Video Diffusion Models
Oct 12, 2023
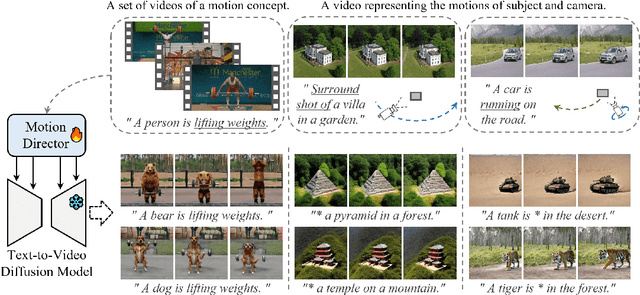
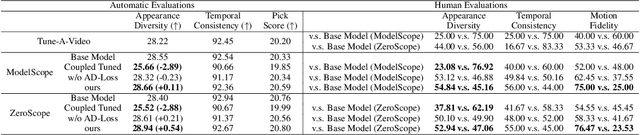


Large-scale pre-trained diffusion models have exhibited remarkable capabilities in diverse video generations. Given a set of video clips of the same motion concept, the task of Motion Customization is to adapt existing text-to-video diffusion models to generate videos with this motion. For example, generating a video with a car moving in a prescribed manner under specific camera movements to make a movie, or a video illustrating how a bear would lift weights to inspire creators. Adaptation methods have been developed for customizing appearance like subject or style, yet unexplored for motion. It is straightforward to extend mainstream adaption methods for motion customization, including full model tuning, parameter-efficient tuning of additional layers, and Low-Rank Adaptions (LoRAs). However, the motion concept learned by these methods is often coupled with the limited appearances in the training videos, making it difficult to generalize the customized motion to other appearances. To overcome this challenge, we propose MotionDirector, with a dual-path LoRAs architecture to decouple the learning of appearance and motion. Further, we design a novel appearance-debiased temporal loss to mitigate the influence of appearance on the temporal training objective. Experimental results show the proposed method can generate videos of diverse appearances for the customized motions. Our method also supports various downstream applications, such as the mixing of different videos with their appearance and motion respectively, and animating a single image with customized motions. Our code and model weights will be released.
Wasserstein Distortion: Unifying Fidelity and Realism
Oct 05, 2023We introduce a distortion measure for images, Wasserstein distortion, that simultaneously generalizes pixel-level fidelity on the one hand and realism on the other. We show how Wasserstein distortion reduces mathematically to a pure fidelity constraint or a pure realism constraint under different parameter choices. Pairs of images that are close under Wasserstein distortion illustrate its utility. In particular, we generate random textures that have high fidelity to a reference texture in one location of the image and smoothly transition to an independent realization of the texture as one moves away from this point. Connections between Wasserstein distortion and models of the human visual system are noted.
Integrating Audio-Visual Features for Multimodal Deepfake Detection
Oct 05, 2023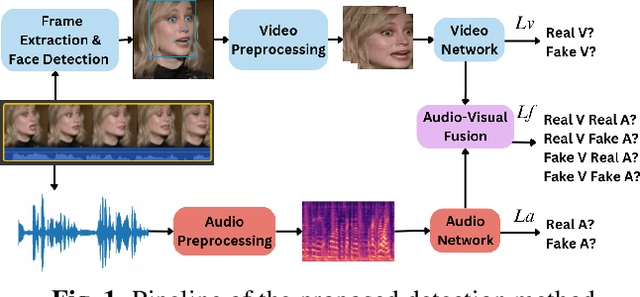
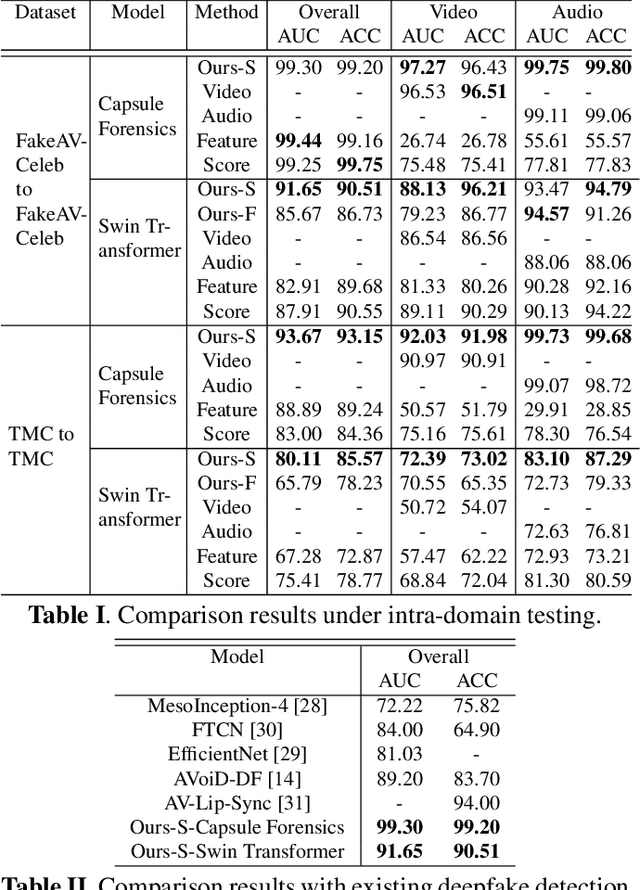
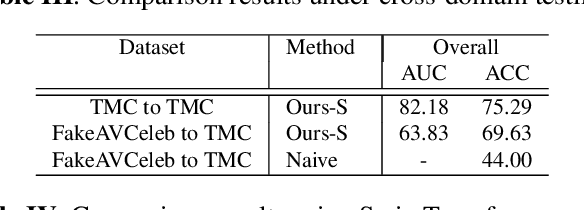
Deepfakes are AI-generated media in which an image or video has been digitally modified. The advancements made in deepfake technology have led to privacy and security issues. Most deepfake detection techniques rely on the detection of a single modality. Existing methods for audio-visual detection do not always surpass that of the analysis based on single modalities. Therefore, this paper proposes an audio-visual-based method for deepfake detection, which integrates fine-grained deepfake identification with binary classification. We categorize the samples into four types by combining labels specific to each single modality. This method enhances the detection under intra-domain and cross-domain testing.
PriViT: Vision Transformers for Fast Private Inference
Oct 06, 2023The Vision Transformer (ViT) architecture has emerged as the backbone of choice for state-of-the-art deep models for computer vision applications. However, ViTs are ill-suited for private inference using secure multi-party computation (MPC) protocols, due to the large number of non-polynomial operations (self-attention, feed-forward rectifiers, layer normalization). We propose PriViT, a gradient based algorithm to selectively "Taylorize" nonlinearities in ViTs while maintaining their prediction accuracy. Our algorithm is conceptually simple, easy to implement, and achieves improved performance over existing approaches for designing MPC-friendly transformer architectures in terms of achieving the Pareto frontier in latency-accuracy. We confirm these improvements via experiments on several standard image classification tasks. Public code is available at https://github.com/NYU-DICE-Lab/privit.
Large Language Model (LLM) as a System of Multiple Expert Agents: An Approach to solve the Abstraction and Reasoning Corpus (ARC) Challenge
Oct 08, 2023We attempt to solve the Abstraction and Reasoning Corpus (ARC) Challenge using Large Language Models (LLMs) as a system of multiple expert agents. Using the flexibility of LLMs to be prompted to do various novel tasks using zero-shot, few-shot, context-grounded prompting, we explore the feasibility of using LLMs to solve the ARC Challenge. We firstly convert the input image into multiple suitable text-based abstraction spaces. We then utilise the associative power of LLMs to derive the input-output relationship and map this to actions in the form of a working program, similar to Voyager / Ghost in the MineCraft. In addition, we use iterative environmental feedback in order to guide LLMs to solve the task. Our proposed approach achieves 50 solves out of 111 training set problems (45%) with just three abstraction spaces - grid, object and pixel - and we believe that with more abstraction spaces and learnable actions, we will be able to solve more.
Intelligent DRL-Based Adaptive Region of Interest for Delay-sensitive Telemedicine Applications
Oct 08, 2023Telemedicine applications have recently received substantial potential and interest, especially after the COVID-19 pandemic. Remote experience will help people get their complex surgery done or transfer knowledge to local surgeons, without the need to travel abroad. Even with breakthrough improvements in internet speeds, the delay in video streaming is still a hurdle in telemedicine applications. This imposes using image compression and region of interest (ROI) techniques to reduce the data size and transmission needs. This paper proposes a Deep Reinforcement Learning (DRL) model that intelligently adapts the ROI size and non-ROI quality depending on the estimated throughput. The delay and structural similarity index measure (SSIM) comparison are used to assess the DRL model. The comparison findings and the practical application reveal that DRL is capable of reducing the delay by 13% and keeping the overall quality in an acceptable range. Since the latency has been significantly reduced, these findings are a valuable enhancement to telemedicine applications.
Information-Theoretic Bounds on The Removal of Attribute-Specific Bias From Neural Networks
Oct 08, 2023Ensuring a neural network is not relying on protected attributes (e.g., race, sex, age) for predictions is crucial in advancing fair and trustworthy AI. While several promising methods for removing attribute bias in neural networks have been proposed, their limitations remain under-explored. In this work, we mathematically and empirically reveal an important limitation of attribute bias removal methods in presence of strong bias. Specifically, we derive a general non-vacuous information-theoretical upper bound on the performance of any attribute bias removal method in terms of the bias strength. We provide extensive experiments on synthetic, image, and census datasets to verify the theoretical bound and its consequences in practice. Our findings show that existing attribute bias removal methods are effective only when the inherent bias in the dataset is relatively weak, thus cautioning against the use of these methods in smaller datasets where strong attribute bias can occur, and advocating the need for methods that can overcome this limitation.
Attention-Guided Lidar Segmentation and Odometry Using Image-to-Point Cloud Saliency Transfer
Aug 28, 2023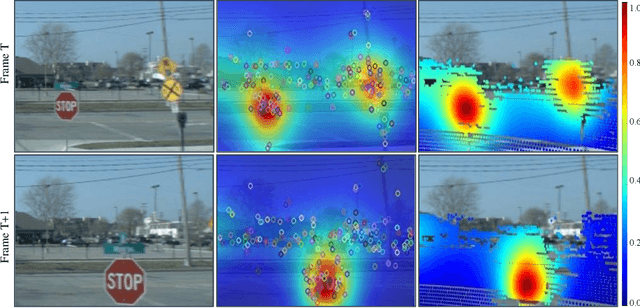

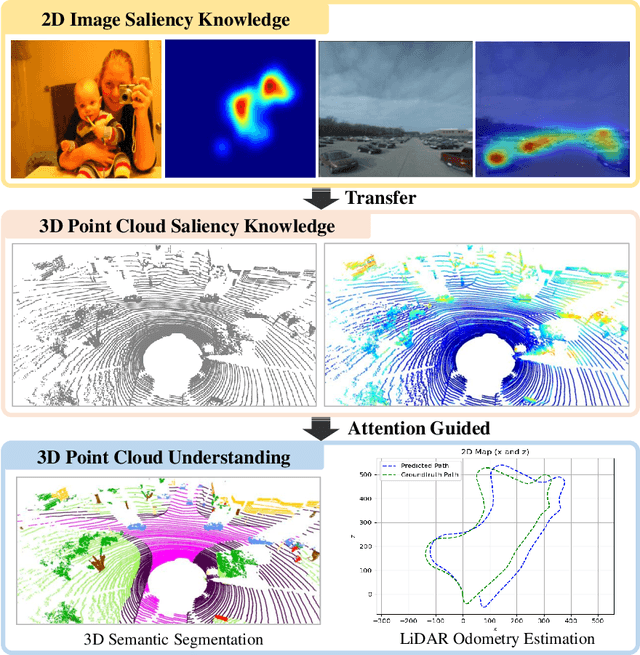
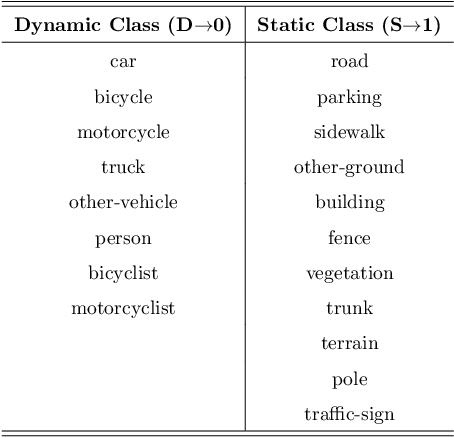
LiDAR odometry estimation and 3D semantic segmentation are crucial for autonomous driving, which has achieved remarkable advances recently. However, these tasks are challenging due to the imbalance of points in different semantic categories for 3D semantic segmentation and the influence of dynamic objects for LiDAR odometry estimation, which increases the importance of using representative/salient landmarks as reference points for robust feature learning. To address these challenges, we propose a saliency-guided approach that leverages attention information to improve the performance of LiDAR odometry estimation and semantic segmentation models. Unlike in the image domain, only a few studies have addressed point cloud saliency information due to the lack of annotated training data. To alleviate this, we first present a universal framework to transfer saliency distribution knowledge from color images to point clouds, and use this to construct a pseudo-saliency dataset (i.e. FordSaliency) for point clouds. Then, we adopt point cloud-based backbones to learn saliency distribution from pseudo-saliency labels, which is followed by our proposed SalLiDAR module. SalLiDAR is a saliency-guided 3D semantic segmentation model that integrates saliency information to improve segmentation performance. Finally, we introduce SalLONet, a self-supervised saliency-guided LiDAR odometry network that uses the semantic and saliency predictions of SalLiDAR to achieve better odometry estimation. Our extensive experiments on benchmark datasets demonstrate that the proposed SalLiDAR and SalLONet models achieve state-of-the-art performance against existing methods, highlighting the effectiveness of image-to-LiDAR saliency knowledge transfer. Source code will be available at https://github.com/nevrez/SalLONet.
Open Image Content Disarm And Reconstruction
Jul 26, 2023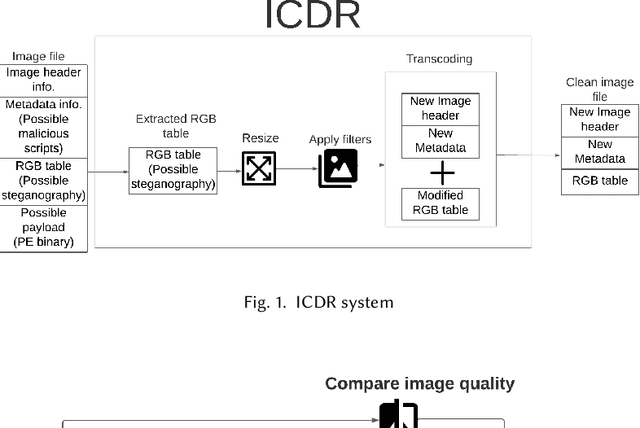
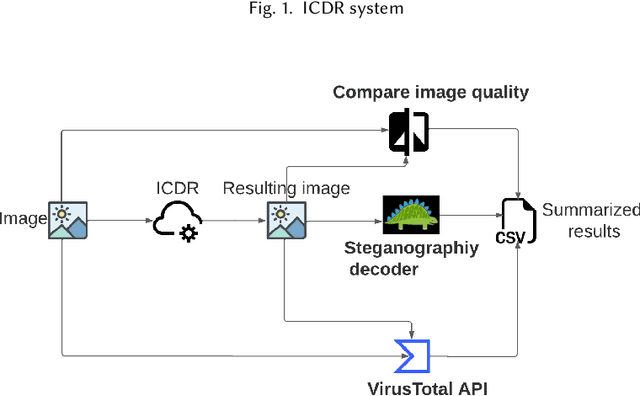
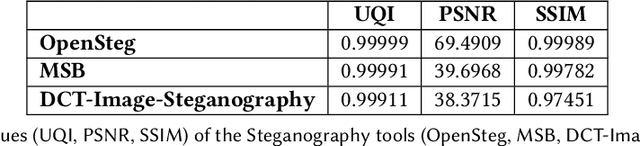
With the advance in malware technology, attackers create new ways to hide their malicious code from antivirus services. One way to obfuscate an attack is to use common files as cover to hide the malicious scripts, so the malware will look like a legitimate file. Although cutting-edge Artificial Intelligence and content signature exist, evasive malware successfully bypasses next-generation malware detection using advanced methods like steganography. Some of the files commonly used to hide malware are image files (e.g., JPEG). In addition, some malware use steganography to hide malicious scripts or sensitive data in images. Steganography in images is difficult to detect even with specialized tools. Image-based attacks try to attack the user's device using malicious payloads or utilize image steganography to hide sensitive data inside legitimate images and leak it outside the user's device. Therefore in this paper, we present a novel Image Content Disarm and Reconstruction (ICDR). Our ICDR system removes potential malware, with a zero trust approach, while maintaining high image quality and file usability. By extracting the image data, removing it from the rest of the file, and manipulating the image pixels, it is possible to disable or remove the hidden malware inside the file.
Diffeomorphic Multi-Resolution Deep Learning Registration for Applications in Breast MRI
Sep 24, 2023In breast surgical planning, accurate registration of MR images across patient positions has the potential to improve the localisation of tumours during breast cancer treatment. While learning-based registration methods have recently become the state-of-the-art approach for most medical image registration tasks, these methods have yet to make inroads into breast image registration due to certain difficulties-the lack of rich texture information in breast MR images and the need for the deformations to be diffeomophic. In this work, we propose learning strategies for breast MR image registration that are amenable to diffeomorphic constraints, together with early experimental results from in-silico and in-vivo experiments. One key contribution of this work is a registration network which produces superior registration outcomes for breast images in addition to providing diffeomorphic guarantees.