 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Patch-based Selection and Refinement for Early Object Detection
Nov 03, 2023
Early object detection (OD) is a crucial task for the safety of many dynamic systems. Current OD algorithms have limited success for small objects at a long distance. To improve the accuracy and efficiency of such a task, we propose a novel set of algorithms that divide the image into patches, select patches with objects at various scales, elaborate the details of a small object, and detect it as early as possible. Our approach is built upon a transformer-based network and integrates the diffusion model to improve the detection accuracy. As demonstrated on BDD100K, our algorithms enhance the mAP for small objects from 1.03 to 8.93, and reduce the data volume in computation by more than 77\%. The source code is available at \href{https://github.com/destiny301/dpr}{https://github.com/destiny301/dpr}
GC-VTON: Predicting Globally Consistent and Occlusion Aware Local Flows with Neighborhood Integrity Preservation for Virtual Try-on
Nov 07, 2023Flow based garment warping is an integral part of image-based virtual try-on networks. However, optimizing a single flow predicting network for simultaneous global boundary alignment and local texture preservation results in sub-optimal flow fields. Moreover, dense flows are inherently not suited to handle intricate conditions like garment occlusion by body parts or by other garments. Forcing flows to handle the above issues results in various distortions like texture squeezing, and stretching. In this work, we propose a novel approach where we disentangle the global boundary alignment and local texture preserving tasks via our GlobalNet and LocalNet modules. A consistency loss is then employed between the two modules which harmonizes the local flows with the global boundary alignment. Additionally, we explicitly handle occlusions by predicting body-parts visibility mask, which is used to mask out the occluded regions in the warped garment. The masking prevents the LocalNet from predicting flows that distort texture to compensate for occlusions. We also introduce a novel regularization loss (NIPR), that defines a criteria to identify the regions in the warped garment where texture integrity is violated (squeezed or stretched). NIPR subsequently penalizes the flow in those regions to ensure regular and coherent warps that preserve the texture in local neighborhoods. Evaluation on a widely used virtual try-on dataset demonstrates strong performance of our network compared to the current SOTA methods.
CapST: An Enhanced and Lightweight Method for Deepfake Video Classification
Nov 07, 2023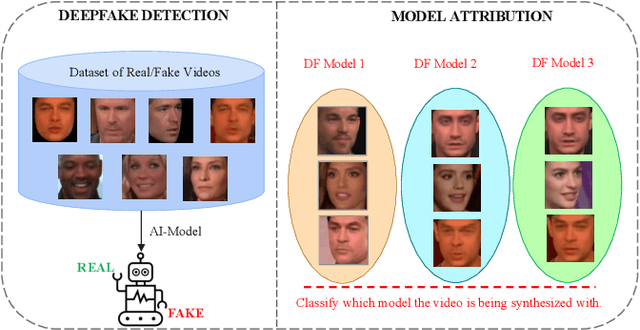
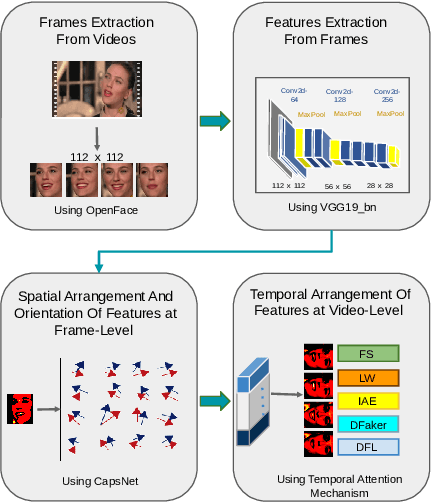
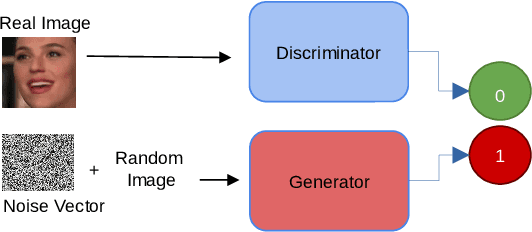
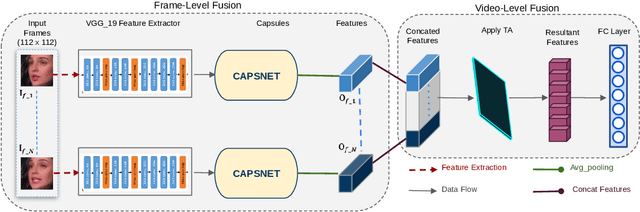
The proliferation of deepfake videos, synthetic media produced through advanced Artificial Intelligence techniques has raised significant concerns across various sectors, encompassing realms such as politics, entertainment, and security. In response, this research introduces an innovative and streamlined model designed to classify deepfake videos generated by five distinct encoders adeptly. Our approach not only achieves state of the art performance but also optimizes computational resources. At its core, our solution employs part of a VGG19bn as a backbone to efficiently extract features, a strategy proven effective in image-related tasks. We integrate a Capsule Network coupled with a Spatial Temporal attention mechanism to bolster the model's classification capabilities while conserving resources. This combination captures intricate hierarchies among features, facilitating robust identification of deepfake attributes. Delving into the intricacies of our innovation, we introduce an existing video level fusion technique that artfully capitalizes on temporal attention mechanisms. This mechanism serves to handle concatenated feature vectors, capitalizing on the intrinsic temporal dependencies embedded within deepfake videos. By aggregating insights across frames, our model gains a holistic comprehension of video content, resulting in more precise predictions. Experimental results on an extensive benchmark dataset of deepfake videos called DFDM showcase the efficacy of our proposed method. Notably, our approach achieves up to a 4 percent improvement in accurately categorizing deepfake videos compared to baseline models, all while demanding fewer computational resources.
Holistic Analysis of Hallucination in GPT-4V(ision): Bias and Interference Challenges
Nov 07, 2023While GPT-4V(ision) impressively models both visual and textual information simultaneously, it's hallucination behavior has not been systematically assessed. To bridge this gap, we introduce a new benchmark, namely, the Bias and Interference Challenges in Visual Language Models (Bingo). This benchmark is designed to evaluate and shed light on the two common types of hallucinations in visual language models: bias and interference. Here, bias refers to the model's tendency to hallucinate certain types of responses, possibly due to imbalance in its training data. Interference pertains to scenarios where the judgment of GPT-4V(ision) can be disrupted due to how the text prompt is phrased or how the input image is presented. We identify a notable regional bias, whereby GPT-4V(ision) is better at interpreting Western images or images with English writing compared to images from other countries or containing text in other languages. Moreover, GPT-4V(ision) is vulnerable to leading questions and is often confused when interpreting multiple images together. Popular mitigation approaches, such as self-correction and chain-of-thought reasoning, are not effective in resolving these challenges. We also identified similar biases and interference vulnerabilities with LLaVA and Bard. Our results characterize the hallucination challenges in GPT-4V(ision) and state-of-the-art visual-language models, and highlight the need for new solutions. The Bingo benchmark is available at https://github.com/gzcch/Bingo.
Deep Learning-based 3D Point Cloud Classification: A Systematic Survey and Outlook
Nov 05, 2023
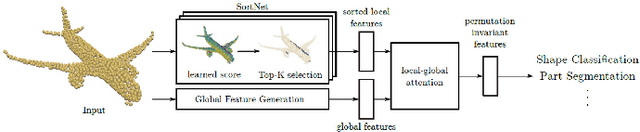
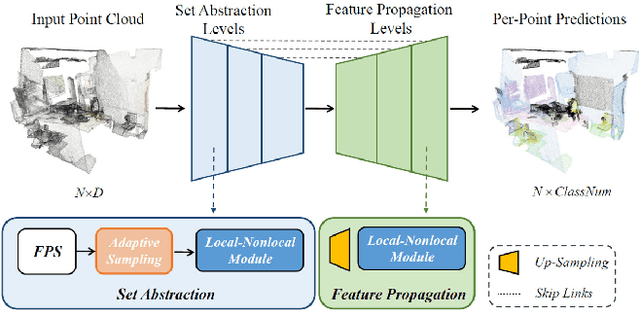
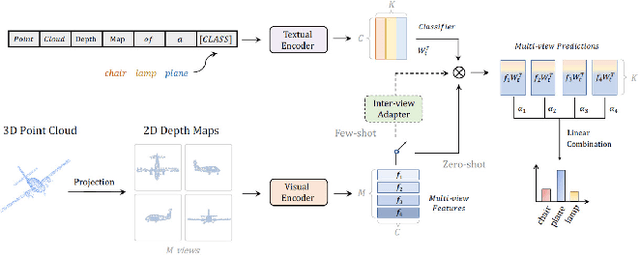
In recent years, point cloud representation has become one of the research hotspots in the field of computer vision, and has been widely used in many fields, such as autonomous driving, virtual reality, robotics, etc. Although deep learning techniques have achieved great success in processing regular structured 2D grid image data, there are still great challenges in processing irregular, unstructured point cloud data. Point cloud classification is the basis of point cloud analysis, and many deep learning-based methods have been widely used in this task. Therefore, the purpose of this paper is to provide researchers in this field with the latest research progress and future trends. First, we introduce point cloud acquisition, characteristics, and challenges. Second, we review 3D data representations, storage formats, and commonly used datasets for point cloud classification. We then summarize deep learning-based methods for point cloud classification and complement recent research work. Next, we compare and analyze the performance of the main methods. Finally, we discuss some challenges and future directions for point cloud classification.
SIRE: scale-invariant, rotation-equivariant estimation of artery orientations using graph neural networks
Nov 09, 2023Blood vessel orientation as visualized in 3D medical images is an important descriptor of its geometry that can be used for centerline extraction and subsequent segmentation and visualization. Arteries appear at many scales and levels of tortuosity, and determining their exact orientation is challenging. Recent works have used 3D convolutional neural networks (CNNs) for this purpose, but CNNs are sensitive to varying vessel sizes and orientations. We present SIRE: a scale-invariant, rotation-equivariant estimator for local vessel orientation. SIRE is modular and can generalise due to symmetry preservation. SIRE consists of a gauge equivariant mesh CNN (GEM-CNN) operating on multiple nested spherical meshes with different sizes in parallel. The features on each mesh are a projection of image intensities within the corresponding sphere. These features are intrinsic to the sphere and, in combination with the GEM-CNN, lead to SO(3)-equivariance. Approximate scale invariance is achieved by weight sharing and use of a symmetric maximum function to combine multi-scale predictions. Hence, SIRE can be trained with arbitrarily oriented vessels with varying radii to generalise to vessels with a wide range of calibres and tortuosity. We demonstrate the efficacy of SIRE using three datasets containing vessels of varying scales: the vascular model repository (VMR), the ASOCA coronary artery set, and a set of abdominal aortic aneurysms (AAAs). We embed SIRE in a centerline tracker which accurately tracks AAAs, regardless of the data SIRE is trained with. Moreover, SIRE can be used to track coronary arteries, even when trained only with AAAs. In conclusion, by incorporating SO(3) and scale symmetries, SIRE can determine the orientations of vessels outside of the training domain, forming a robust and data-efficient solution to geometric analysis of blood vessels in 3D medical images.
H-NeXt: The next step towards roto-translation invariant networks
Nov 02, 2023The widespread popularity of equivariant networks underscores the significance of parameter efficient models and effective use of training data. At a time when robustness to unseen deformations is becoming increasingly important, we present H-NeXt, which bridges the gap between equivariance and invariance. H-NeXt is a parameter-efficient roto-translation invariant network that is trained without a single augmented image in the training set. Our network comprises three components: an equivariant backbone for learning roto-translation independent features, an invariant pooling layer for discarding roto-translation information, and a classification layer. H-NeXt outperforms the state of the art in classification on unaugmented training sets and augmented test sets of MNIST and CIFAR-10.
Tracking and fast imaging of a translational object via Fourier modulation
Oct 28, 2023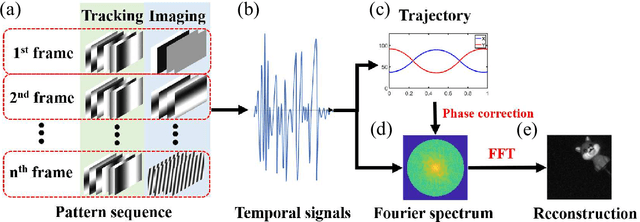
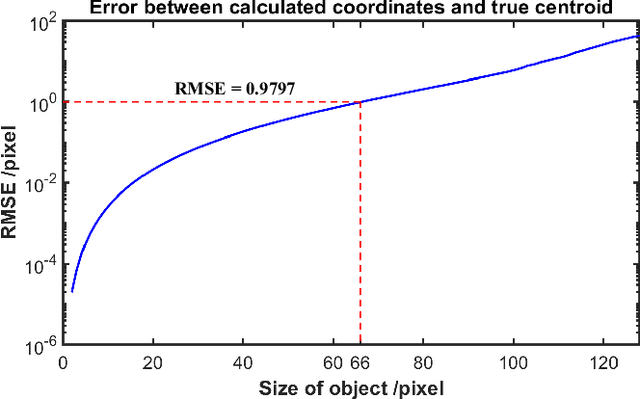
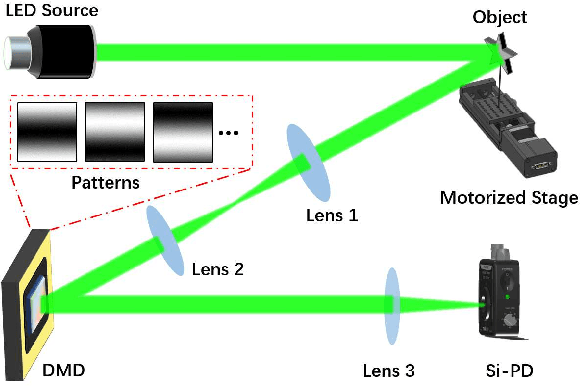

The tracking and imaging of high-speed moving objects hold significant promise for application in various fields. Single-pixel imaging enables the progressive capture of a fast-moving translational object through motion compensation. However, achieving a balance between a short reconstruction time and a good image quality is challenging. In this study, we present a approach that simultaneously incorporates position encoding and spatial information encoding through the Fourier patterns. The utilization of Fourier patterns with specific spatial frequencies ensures robust and accurate object localization. By exploiting the properties of the Fourier transform, our method achieves a remarkable reduction in time complexity and memory consumption while significantly enhancing image quality. Furthermore, we introduce an optimized sampling strategy specifically tailored for small moving objects, significantly reducing the required dwell time for imaging. The proposed method provides a practical solution for the real-time tracking, imaging and edge detection of translational objects, underscoring its considerable potential for diverse applications.
SDF4CHD: Generative Modeling of Cardiac Anatomies with Congenital Heart Defects
Nov 08, 2023Congenital heart disease (CHD) encompasses a spectrum of cardiovascular structural abnormalities, often requiring customized treatment plans for individual patients. Computational modeling and analysis of these unique cardiac anatomies can improve diagnosis and treatment planning and may ultimately lead to improved outcomes. Deep learning (DL) methods have demonstrated the potential to enable efficient treatment planning by automating cardiac segmentation and mesh construction for patients with normal cardiac anatomies. However, CHDs are often rare, making it challenging to acquire sufficiently large patient cohorts for training such DL models. Generative modeling of cardiac anatomies has the potential to fill this gap via the generation of virtual cohorts; however, prior approaches were largely designed for normal anatomies and cannot readily capture the significant topological variations seen in CHD patients. Therefore, we propose a type- and shape-disentangled generative approach suitable to capture the wide spectrum of cardiac anatomies observed in different CHD types and synthesize differently shaped cardiac anatomies that preserve the unique topology for specific CHD types. Our DL approach represents generic whole heart anatomies with CHD type-specific abnormalities implicitly using signed distance fields (SDF) based on CHD type diagnosis, which conveniently captures divergent anatomical variations across different types and represents meaningful intermediate CHD states. To capture the shape-specific variations, we then learn invertible deformations to morph the learned CHD type-specific anatomies and reconstruct patient-specific shapes. Our approach has the potential to augment the image-segmentation pairs for rarer CHD types for cardiac segmentation and generate cohorts of CHD cardiac meshes for computational simulation.
Enhancing Few-shot CLIP with Semantic-Aware Fine-Tuning
Nov 08, 2023Learning generalized representations from limited training samples is crucial for applying deep neural networks in low-resource scenarios. Recently, methods based on Contrastive Language-Image Pre-training (CLIP) have exhibited promising performance in few-shot adaptation tasks. To avoid catastrophic forgetting and overfitting caused by few-shot fine-tuning, existing works usually freeze the parameters of CLIP pre-trained on large-scale datasets, overlooking the possibility that some parameters might not be suitable for downstream tasks. To this end, we revisit CLIP's visual encoder with a specific focus on its distinctive attention pooling layer, which performs a spatial weighted-sum of the dense feature maps. Given that dense feature maps contain meaningful semantic information, and different semantics hold varying importance for diverse downstream tasks (such as prioritizing semantics like ears and eyes in pet classification tasks rather than side mirrors), using the same weighted-sum operation for dense features across different few-shot tasks might not be appropriate. Hence, we propose fine-tuning the parameters of the attention pooling layer during the training process to encourage the model to focus on task-specific semantics. In the inference process, we perform residual blending between the features pooled by the fine-tuned and the original attention pooling layers to incorporate both the few-shot knowledge and the pre-trained CLIP's prior knowledge. We term this method as Semantic-Aware FinE-tuning (SAFE). SAFE is effective in enhancing the conventional few-shot CLIP and is compatible with the existing adapter approach (termed SAFE-A).