 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Refine and Distill: Exploiting Cycle-Inconsistency and Knowledge Distillation for Unsupervised Monocular Depth Estimation
Mar 11, 2019
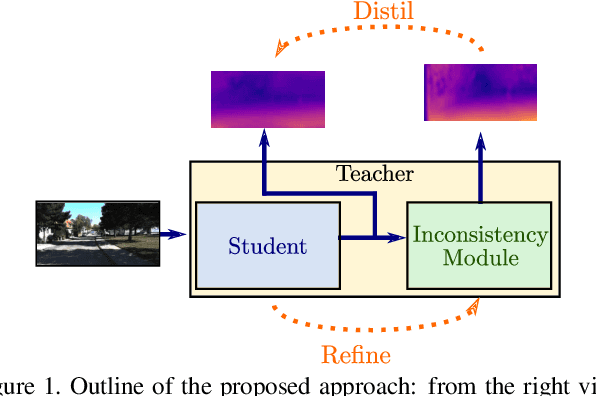
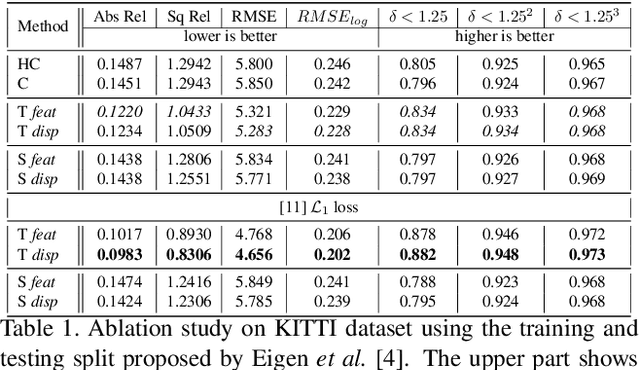
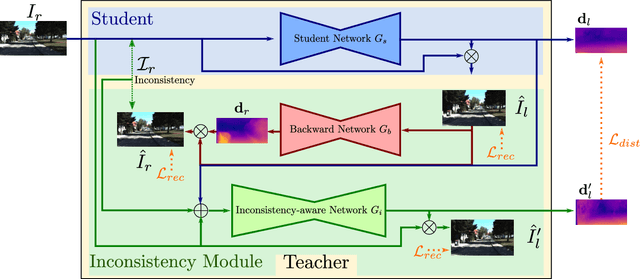
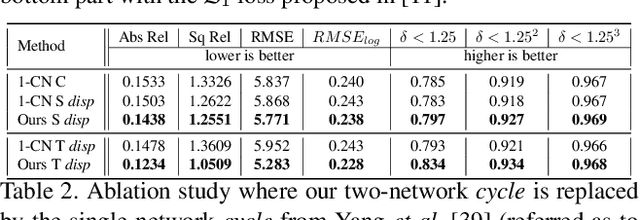
Nowadays, the majority of state of the art monocular depth estimation techniques are based on supervised deep learning models. However, collecting RGB images with associated depth maps is a very time consuming procedure. Therefore, recent works have proposed deep architectures for addressing the monocular depth prediction task as a reconstruction problem, thus avoiding the need of collecting ground-truth depth. Following these works, we propose a novel self-supervised deep model for estimating depth maps. Our framework exploits two main strategies: refinement via cycle-inconsistency and distillation. Specifically, first a \emph{student} network is trained to predict a disparity map such as to recover from a frame in a camera view the associated image in the opposite view. Then, a backward cycle network is applied to the generated image to re-synthesize back the input image, estimating the opposite disparity. A third network exploits the inconsistency between the original and the reconstructed input frame in order to output a refined depth map. Finally, knowledge distillation is exploited, such as to transfer information from the refinement network to the student. Our extensive experimental evaluation demonstrate the effectiveness of the proposed framework which outperforms state of the art unsupervised methods on the KITTI benchmark.
Deep weakly-supervised learning methods for classification and localization in histology images: a survey
Sep 26, 2019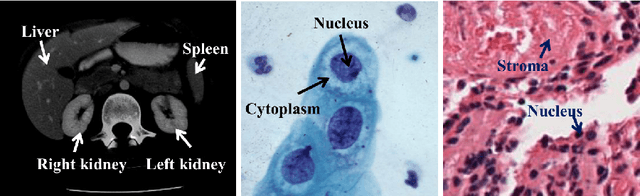

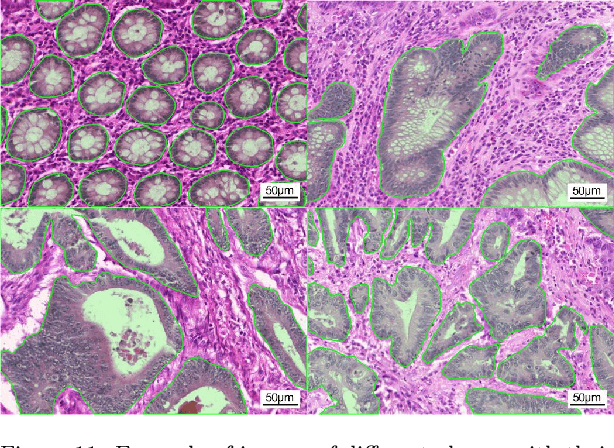
Using state-of-the-art deep learning models for the computer-assisted diagnosis of diseases like cancer raises several challenges related to the nature and availability of labeled histology images. In particular, cancer grading and localization in these images normally relies on both image- and pixel-level labels, the latter requiring a costly annotation process. In this survey, deep weakly-supervised learning (WSL) architectures are investigated to identify and locate diseases in histology image, without the need for pixel-level annotations. Given a training dataset with globally-annotated images, these models allow to simultaneously classify histology images, while localizing the corresponding regions of interest. These models are organized into two main approaches -- (1) bottom-up approaches (based on forward-pass information through a network, either by spatial pooling of representations/scores, or by detecting class regions), and (2) top-down approaches (based on backward-pass information within a network, inspired by human visual attention). Since relevant WSL models have mainly been developed in the computer vision community, and validated on natural scene images, we assess the extent to which they apply to histology images which have challenging properties, e.g., large size, non-salient and highly unstructured regions, stain heterogeneity, and coarse/ambiguous labels. The most relevant deep WSL models (e.g., CAM, WILDCAT and Deep MIL) are compared experimentally in terms of accuracy (classification and pixel-level localization) on several public benchmark histology datasets for breast and colon cancer (BACH ICIAR 2018, BreakHis, CAMELYON16, and GlaS). Results indicate that several deep learning models, and in particular WILDCAT and deep MIL can provide a high level of classification accuracy, although pixel-wise localization of cancer regions remains an issue for such images.
OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge
May 31, 2019


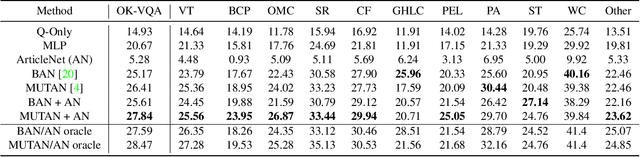
Visual Question Answering (VQA) in its ideal form lets us study reasoning in the joint space of vision and language and serves as a proxy for the AI task of scene understanding. However, most VQA benchmarks to date are focused on questions such as simple counting, visual attributes, and object detection that do not require reasoning or knowledge beyond what is in the image. In this paper, we address the task of knowledge-based visual question answering and provide a benchmark, called OK-VQA, where the image content is not sufficient to answer the questions, encouraging methods that rely on external knowledge resources. Our new dataset includes more than 14,000 questions that require external knowledge to answer. We show that the performance of the state-of-the-art VQA models degrades drastically in this new setting. Our analysis shows that our knowledge-based VQA task is diverse, difficult, and large compared to previous knowledge-based VQA datasets. We hope that this dataset enables researchers to open up new avenues for research in this domain. See http://okvqa.allenai.org to download and browse the dataset.
Revisiting Landscape Analysis in Deep Neural Networks: Eliminating Decreasing Paths to Infinity
Dec 31, 2019Traditional landscape analysis of deep neural networks aims to show that no sub-optimal local minima exist in some appropriate sense. From this, one may be tempted to conclude that descent algorithms which escape saddle points will reach a good local minimum. However, basic optimization theory tell us that it is also possible for a descent algorithm to diverge to infinity if there are paths leading to infinity, along which the loss function decreases. It is not clear whether for non-linear neural networks there exists one setting that no bad local-min and no decreasing paths to infinity can be simultaneously achieved. In this paper, we give the first positive answer to this question. More specifically, for a large class of over-parameterized deep neural networks with appropriate regularizers, the loss function has no bad local minima and no decreasing paths to infinity. The key mathematical trick is to show that the set of regularizers which may be undesirable can be viewed as the image of a Lipschitz continuous mapping from a lower-dimensional Euclidean space to a higher-dimensional Euclidean space, and thus has zero measure.
Analysis Dictionary Learning: An Efficient and Discriminative Solution
Mar 07, 2019
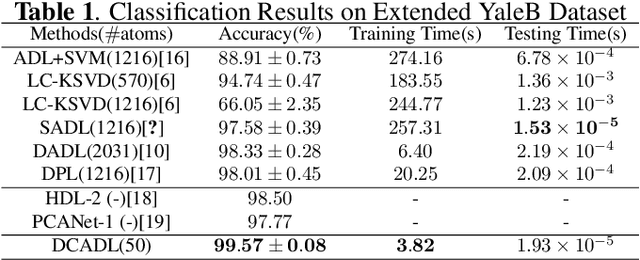
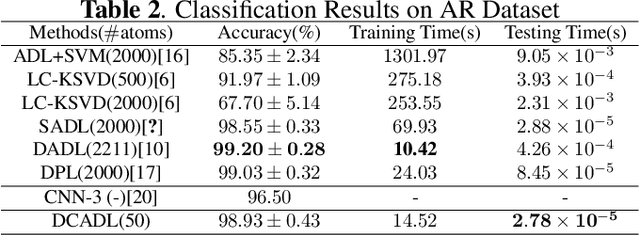

Discriminative Dictionary Learning (DL) methods have been widely advocated for image classification problems. To further sharpen their discriminative capabilities, most state-of-the-art DL methods have additional constraints included in the learning stages. These various constraints, however, lead to additional computational complexity. We hence propose an efficient Discriminative Convolutional Analysis Dictionary Learning (DCADL) method, as a lower cost Discriminative DL framework, to both characterize the image structures and refine the interclass structure representations. The proposed DCADL jointly learns a convolutional analysis dictionary and a universal classifier, while greatly reducing the time complexity in both training and testing phases, and achieving a competitive accuracy, thus demonstrating great performance in many experiments with standard databases.
Motion Corrected Multishot MRI Reconstruction Using Generative Networks with Sensitivity Encoding
Feb 20, 2019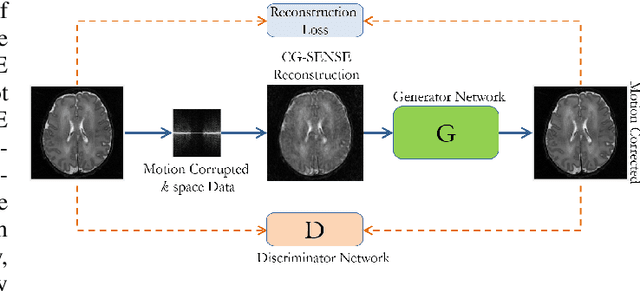
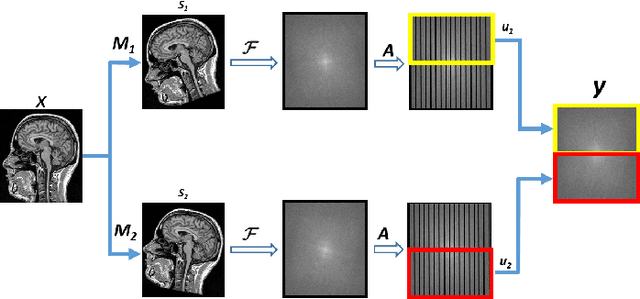
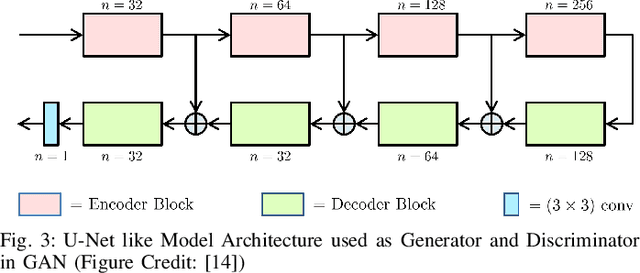

Multishot Magnetic Resonance Imaging (MRI) is a promising imaging modality that can produce a high-resolution image with relatively less data acquisition time. The downside of multishot MRI is that it is very sensitive to subject motion and even small amounts of motion during the scan can produce artifacts in the final MR image that may cause misdiagnosis. Numerous efforts have been made to address this issue; however, all of these proposals are limited in terms of how much motion they can correct and the required computational time. In this paper, we propose a novel generative networks based conjugate gradient SENSE (CG-SENSE) reconstruction framework for motion correction in multishot MRI. The proposed framework first employs CG-SENSE reconstruction to produce the motion-corrupted image and then a generative adversarial network (GAN) is used to correct the motion artifacts. The proposed method has been rigorously evaluated on synthetically corrupted data on varying degrees of motion, numbers of shots, and encoding trajectories. Our analyses (both quantitative as well as qualitative/visual analysis) establishes that the proposed method significantly robust and outperforms state-of-the-art motion correction techniques and also reduces severalfold of computational times.
Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders
Dec 17, 2018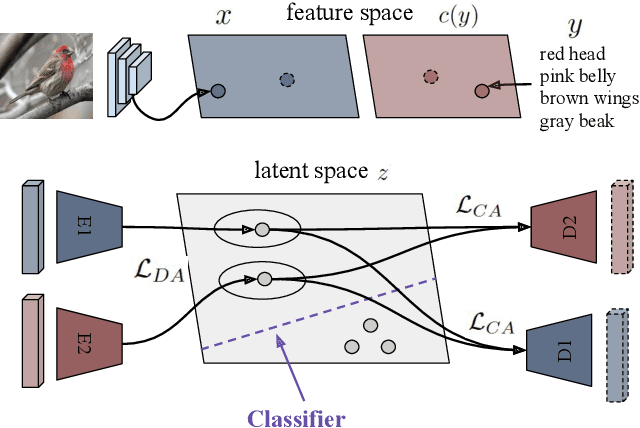

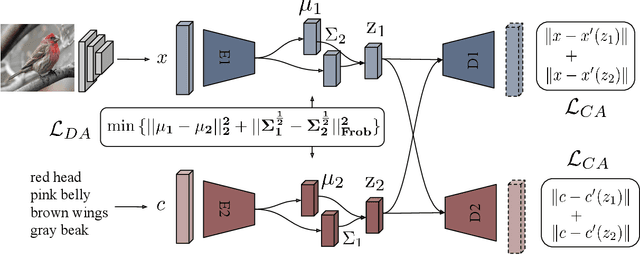
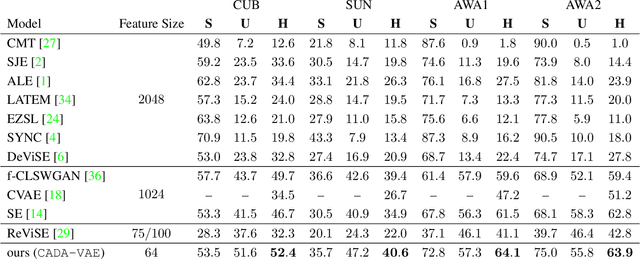
Many approaches in generalized zero-shot learning rely on cross-modal mapping between the image feature space and the class embedding space. As labeled images are rare, one direction is to augment the dataset by generating either images or image features. However, the former misses fine-grained details and the latter requires learning a mapping associated with class embeddings. In this work, we take feature generation one step further and propose a model where a shared latent space of image features and class embeddings is learned by modality-specific aligned variational autoencoders. This leaves us with the required discriminative information about the image and classes in the latent features, on which we train a softmax classifier. The key to our approach is that we align the distributions learned from images and from side-information to construct latent features that contain the essential multi-modal information associated with unseen classes. We evaluate our learned latent features on several benchmark datasets, i.e. CUB, SUN, AWA1 and AWA2, and establish a new state-of-the-art on generalized zero-shot as well as on few-shot learning. Moreover, our results on ImageNet with various zero-shot splits show that our latent features generalize well in large-scale settings.
Challenges ahead Electron Microscopy for Structural Biology from the Image Processing point of view
Jan 02, 2017Since the introduction of Direct Electron Detectors (DEDs), the resolution and range of macromolecules amenable to this technique has significantly widened, generating a broad interest that explains the well over a dozen reviews in top journal in the last two years. Similarly, the number of job offers to lead EM groups and/or coordinate EM facilities has exploded, and FEI (the main microscope manufacturer for Life Sciences) has received more than 100 orders of high-end electron microscopes by summer 2016. Strategic corporate movements are also happening, with very big players entering the market through key acquisitions (Thermo Fisher has recently bought FEI for \$4.2B), partly attracted by new Pharma interest in the field, now perceived to be in a position to impact structure-based drug design. The scientific perspectives are indeed extremely positive but, in these moments of well-founded generalized optimists, we want to make a reflection on some of the hurdles ahead us, since they certainly exist and they indeed limit the informational content of cryoEM projects. Here we focus on image processing aspects, particularly in the so-called area of Single Particle Analysis, discussing some of the current resolution and high-throughput limiting factors.
Training Deep Learning models with small datasets
Dec 14, 2019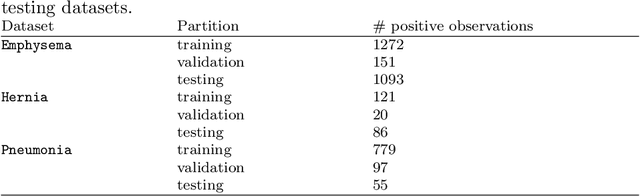
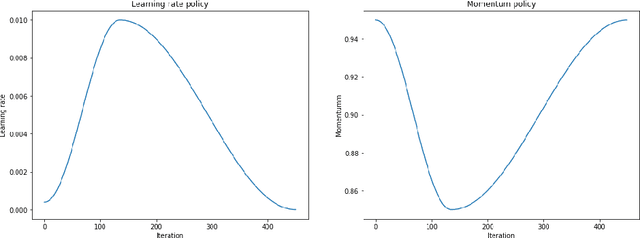
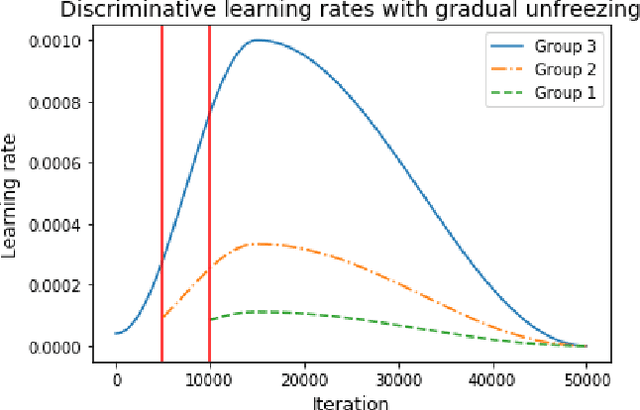
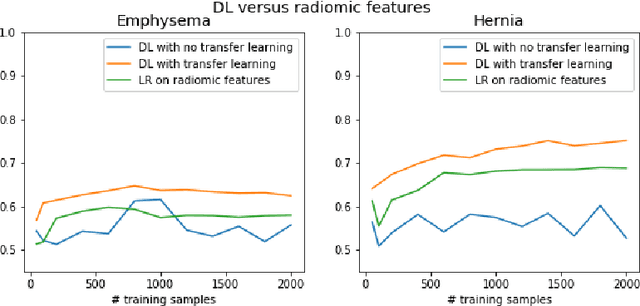
The growing use of Machine Learning has produced significant advances in many fields. For image-based tasks, however, the use of deep learning remains challenging in small datasets. In this article, we review, evaluate and compare the current state of the art techniques in training neural networks to elucidate which techniques work best for small datasets. We further propose a path forward for the improvement of model accuracy in medical imaging applications. We observed best results from one cycle training, discriminative learning rates with gradual freezing and parameter modification after transfer learning. We also established that when datasets are small, transfer learning plays an important role beyond parameter initialization by reusing previously learned features. Surprisingly we observed that there is little advantage in using pre-trained networks in images from another part of the body compared to Imagenet. On the contrary, if images from the same part of the body are available then transfer learning can produce a significant improvement in performance with as little as 50 images in the training data.
Image decomposition with anisotropic diffusion applied to leaf-texture analysis
Jan 19, 2012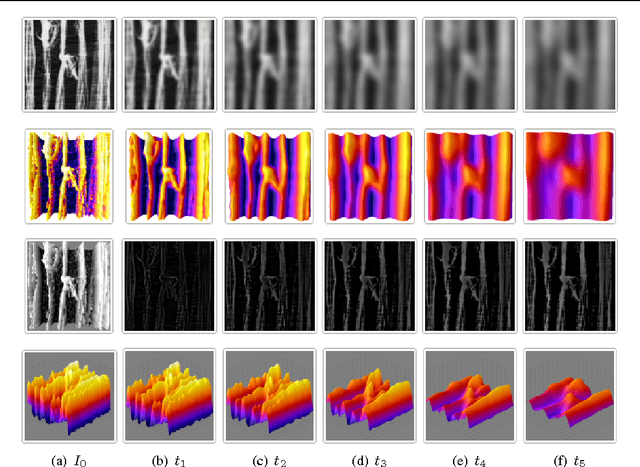
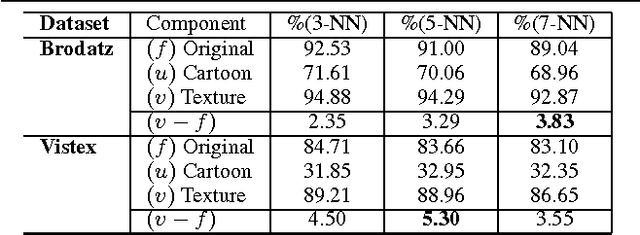

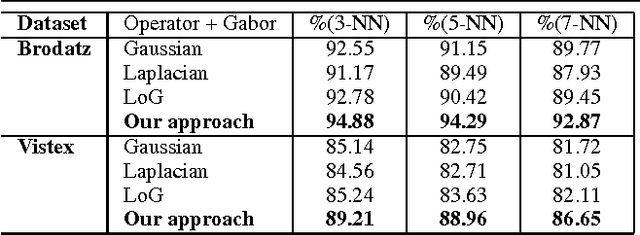
Texture analysis is an important field of investigation that has received a great deal of interest from computer vision community. In this paper, we propose a novel approach for texture modeling based on partial differential equation (PDE). Each image $f$ is decomposed into a family of derived sub-images. $f$ is split into the $u$ component, obtained with anisotropic diffusion, and the $v$ component which is calculated by the difference between the original image and the $u$ component. After enhancing the texture attribute $v$ of the image, Gabor features are computed as descriptors. We validate the proposed approach on two texture datasets with high variability. We also evaluate our approach on an important real-world application: leaf-texture analysis. Experimental results indicate that our approach can be used to produce higher classification rates and can be successfully employed for different texture applications.