 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the notion of number in humans and machines
Jun 27, 2019
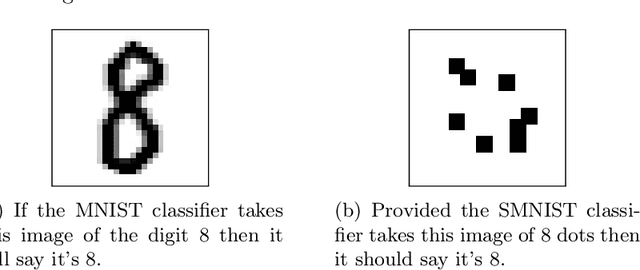
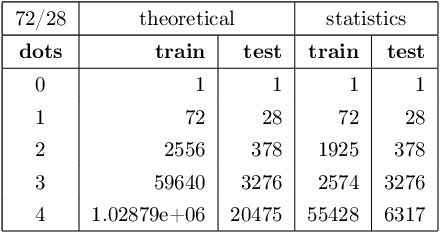

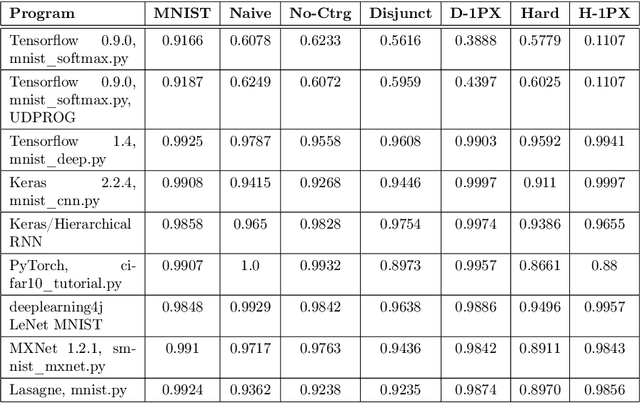
In this paper, we performed two types of software experiments to study the numerosity classification (subitizing) in humans and machines. Experiments focus on a particular kind of task is referred to as Semantic MNIST or simply SMNIST where the numerosity of objects placed in an image must be determined. The experiments called SMNIST for Humans are intended to measure the capacity of the Object File System in humans. In this type of experiment the measurement result is in well agreement with the value known from the cognitive psychology literature. The experiments called SMNIST for Machines serve similar purposes but they investigate existing, well known (but originally developed for other purpose) and under development deep learning computer programs. These measurement results can be interpreted similar to the results from SMNIST for Humans. The main thesis of this paper can be formulated as follows: in machines the image classification artificial neural networks can learn to distinguish numerosities with better accuracy when these numerosities are smaller than the capacity of OFS in humans. Finally, we outline a conceptual framework to investigate the notion of number in humans and machines.
EHSOD: CAM-Guided End-to-end Hybrid-Supervised Object Detection with Cascade Refinement
Feb 18, 2020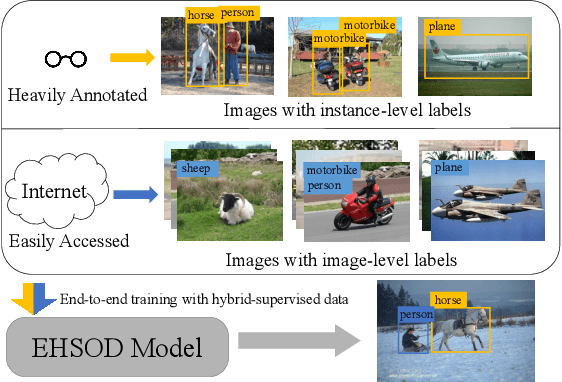
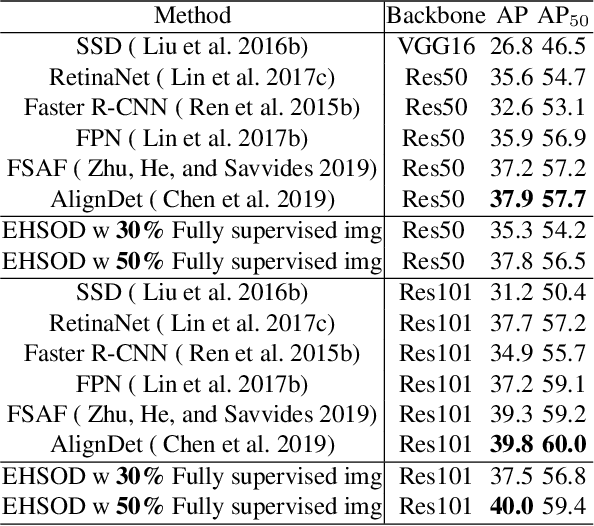
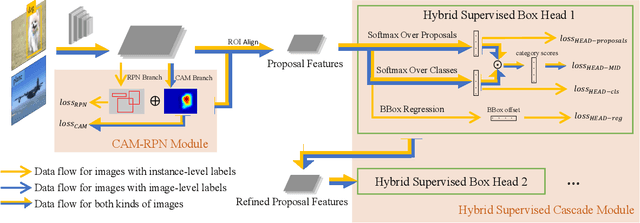
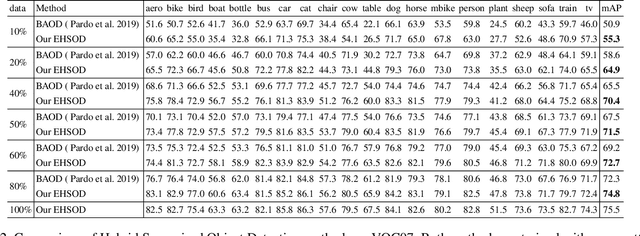
Object detectors trained on fully-annotated data currently yield state of the art performance but require expensive manual annotations. On the other hand, weakly-supervised detectors have much lower performance and cannot be used reliably in a realistic setting. In this paper, we study the hybrid-supervised object detection problem, aiming to train a high quality detector with only a limited amount of fullyannotated data and fully exploiting cheap data with imagelevel labels. State of the art methods typically propose an iterative approach, alternating between generating pseudo-labels and updating a detector. This paradigm requires careful manual hyper-parameter tuning for mining good pseudo labels at each round and is quite time-consuming. To address these issues, we present EHSOD, an end-to-end hybrid-supervised object detection system which can be trained in one shot on both fully and weakly-annotated data. Specifically, based on a two-stage detector, we proposed two modules to fully utilize the information from both kinds of labels: 1) CAMRPN module aims at finding foreground proposals guided by a class activation heat-map; 2) hybrid-supervised cascade module further refines the bounding-box position and classification with the help of an auxiliary head compatible with image-level data. Extensive experiments demonstrate the effectiveness of the proposed method and it achieves comparable results on multiple object detection benchmarks with only 30% fully-annotated data, e.g. 37.5% mAP on COCO. We will release the code and the trained models.
Deep inspection: an electrical distribution pole parts study via deep neural networks
Jul 16, 2019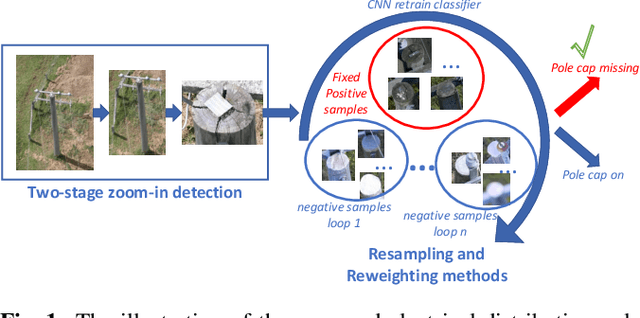

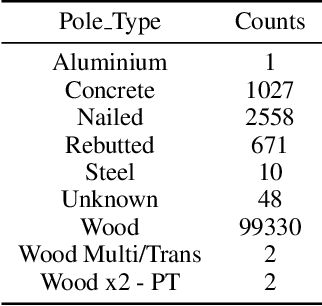

Electrical distribution poles are important assets in electricity supply. These poles need to be maintained in good condition to ensure they protect community safety, maintain reliability of supply, and meet legislative obligations. However, maintaining such a large volumes of assets is an expensive and challenging task. To address this, recent approaches utilise imagery data captured from helicopter and/or drone inspections. Whilst reducing the cost for manual inspection, manual analysis on each image is still required. As such, several image-based automated inspection systems have been proposed. In this paper, we target two major challenges: tiny object detection and extremely imbalanced datasets, which currently hinder the wide deployment of the automatic inspection. We propose a novel two-stage zoom-in detection method to gradually focus on the object of interest. To address the imbalanced dataset problem, we propose the resampling as well as reweighting schemes to iteratively adapt the model to the large intra-class variation of major class and balance the contributions to the loss from each class. Finally, we integrate these components together and devise a novel automatic inspection framework. Extensive experiments demonstrate that our proposed approaches are effective and can boost the performance compared to the baseline methods.
The troublesome kernel: why deep learning for inverse problems is typically unstable
Jan 05, 2020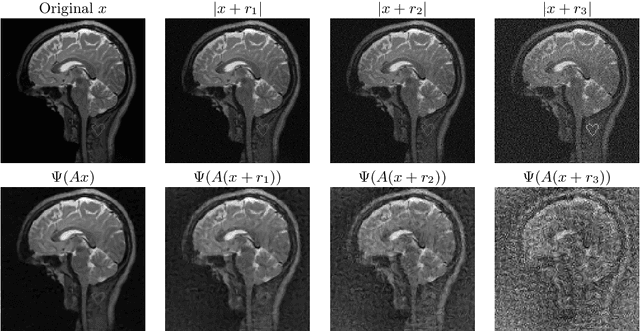

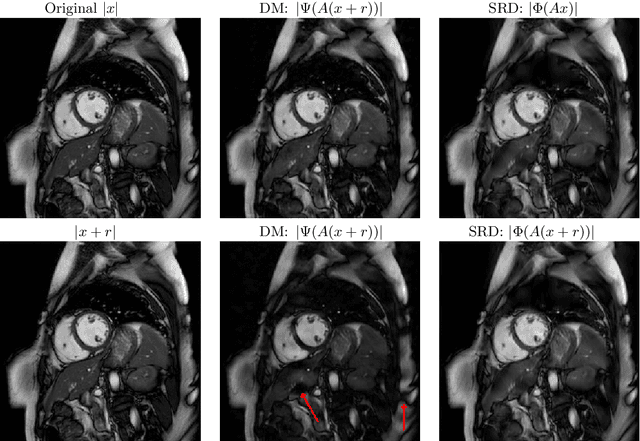
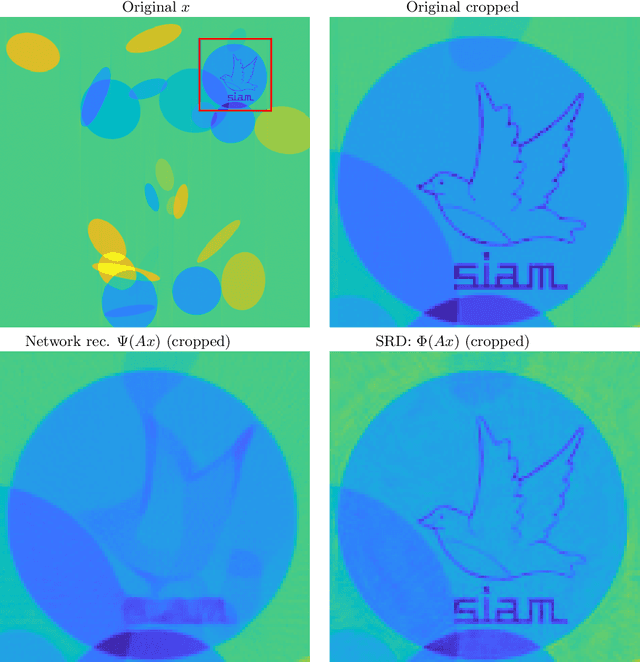
There is overwhelming empirical evidence that Deep Learning (DL) leads to unstable methods in applications ranging from image classification and computer vision to voice recognition and automated diagnosis in medicine. Recently, a similar instability phenomenon has been discovered when DL is used to solve certain problems in computational science, namely, inverse problems in imaging. In this paper we present a comprehensive mathematical analysis explaining the many facets of the instability phenomenon in DL for inverse problems. Our main results not only explain why this phenomenon occurs, they also shed light as to why finding a cure for instabilities is so difficult in practice. Additionally, these theorems show that instabilities are typically not rare events - rather, they can occur even when the measurements are subject to completely random noise - and consequently how easy it can be to destablise certain trained neural networks. We also examine the delicate balance between reconstruction performance and stability, and in particular, how DL methods may outperform state-of-the-art sparse regularization methods, but at the cost of instability. Finally, we demonstrate a counterintuitive phenomenon: training a neural network may generically not yield an optimal reconstruction method for an inverse problem.
Single Unit Status in Deep Convolutional Neural Network Codes for Face Identification: Sparseness Redefined
Mar 01, 2020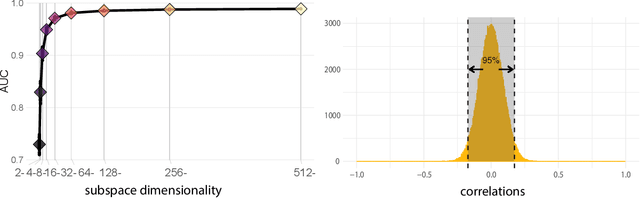
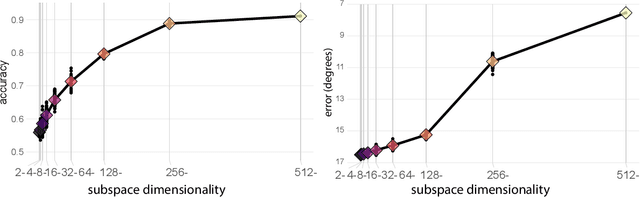
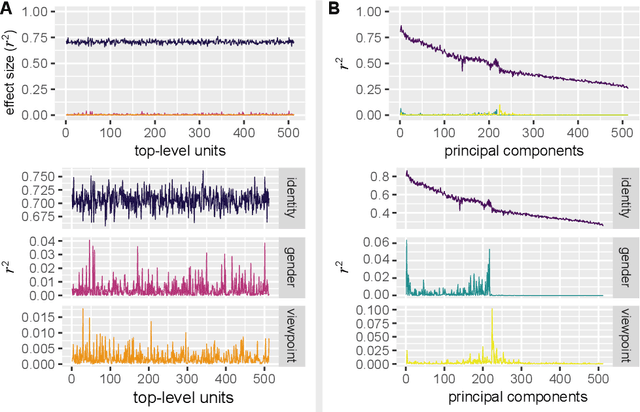
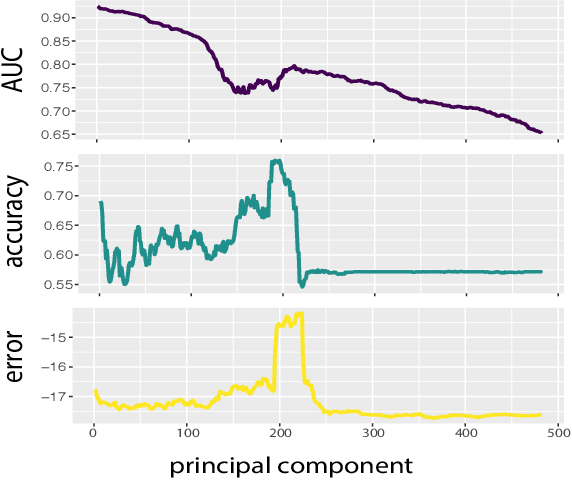
Deep convolutional neural networks (DCNNs) trained for face identification develop representations that generalize over variable images, while retaining subject (e.g., gender) and image (e.g., viewpoint) information. Identity, gender, and viewpoint codes were studied at the "neural unit" and ensemble levels of a face-identification network. At the unit level, identification, gender classification, and viewpoint estimation were measured by deleting units to create variably-sized, randomly-sampled subspaces at the top network layer. Identification of 3,531 identities remained high (area under the ROC approximately 1.0) as dimensionality decreased from 512 units to 16 (0.95), 4 (0.80), and 2 (0.72) units. Individual identities separated statistically on every top-layer unit. Cross-unit responses were minimally correlated, indicating that units code non-redundant identity cues. This "distributed" code requires only a sparse, random sample of units to identify faces accurately. Gender classification declined gradually and viewpoint estimation fell steeply as dimensionality decreased. Individual units were weakly predictive of gender and viewpoint, but ensembles proved effective predictors. Therefore, distributed and sparse codes co-exist in the network units to represent different face attributes. At the ensemble level, principal component analysis of face representations showed that identity, gender, and viewpoint information separated into high-dimensional subspaces, ordered by explained variance. Identity, gender, and viewpoint information contributed to all individual unit responses, undercutting a neural tuning analogy for face attributes. Interpretation of neural-like codes from DCNNs, and by analogy, high-level visual codes, cannot be inferred from single unit responses. Instead, "meaning" is encoded by directions in the high-dimensional space.
Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP
Jun 06, 2019
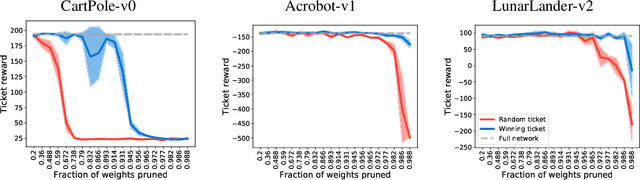
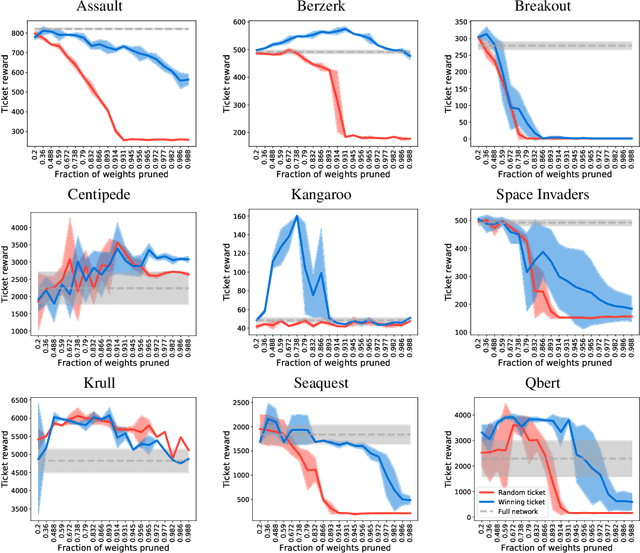
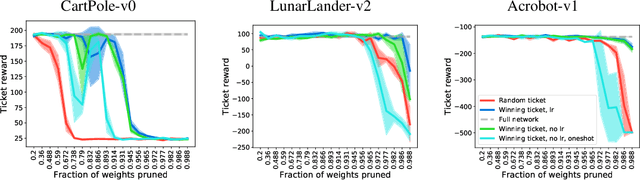
The lottery ticket hypothesis proposes that over-parameterization of deep neural networks (DNNs) aids training by increasing the probability of a "lucky" sub-network initialization being present rather than by helping the optimization process. This phenomenon is intriguing and suggests that initialization strategies for DNNs can be improved substantially, but the lottery ticket hypothesis has only previously been tested in the context of supervised learning for natural image tasks. Here, we evaluate whether "winning ticket" initializations exist in two different domains: reinforcement learning (RL) and in natural language processing (NLP). For RL, we analyzed a number of discrete-action space tasks, including both classic control and pixel control. For NLP, we examined both recurrent LSTM models and large-scale Transformer models. Consistent with work in supervised image classification, we confirm that winning ticket initializations generally outperform parameter-matched random initializations, even at extreme pruning rates. Together, these results suggest that the lottery ticket hypothesis is not restricted to supervised learning of natural images, but rather represents a broader phenomenon in DNNs.
Automated Pavement Crack Segmentation Using Fully Convolutional U-Net with a Pretrained ResNet-34 Encoder
Jan 21, 2020
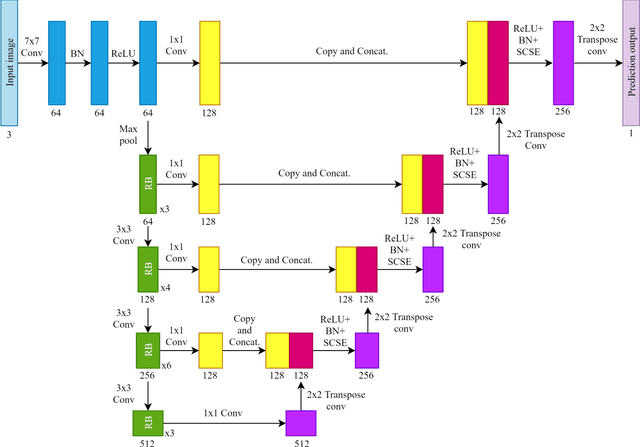
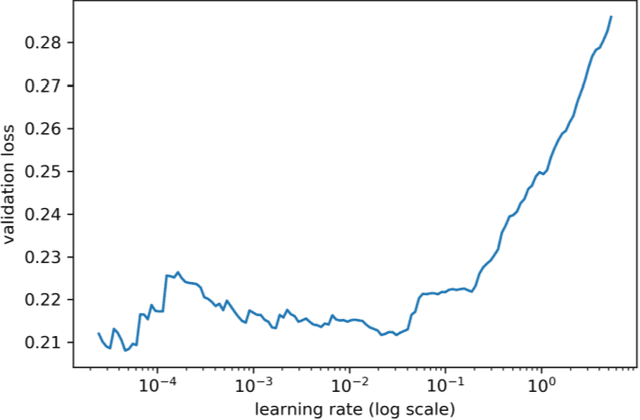
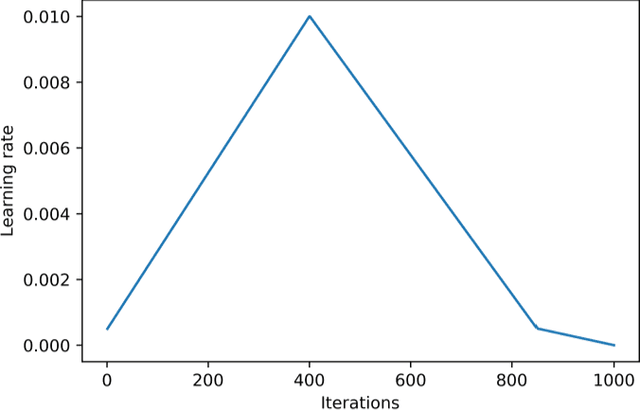
Automated pavement crack segmentation is a challenging task because of inherent irregular patterns and lighting conditions, in addition to the presence of noise in images. Conventional approaches require a substantial amount of feature engineering to differentiate crack regions from non-affected regions. In this paper, we propose a deep learning technique based on a convolutional neural network to perform segmentation tasks on pavement crack images. Our approach requires minimal feature engineering compared to other machine learning techniques. The proposed neural network architecture is a modified U-Net in which the encoder is replaced with a pretrained ResNet-34 network. To minimize the dice coefficient loss function, we optimize the parameters in the neural network by using an adaptive moment optimizer called AdamW. Additionally, we use a systematic method to find the optimum learning rate instead of doing parametric sweeps. We used a "one-cycle" training schedule based on cyclical learning rates to speed up the convergence. We evaluated the performance of our convolutional neural network on CFD, a pavement crack image dataset. Our method achieved an F1 score of about 96%. This is the best performance among all other algorithms tested on this dataset, outperforming the previous best method by a 1.7% margin.
End-to-End Learning-Based Ultrasound Reconstruction
Apr 09, 2019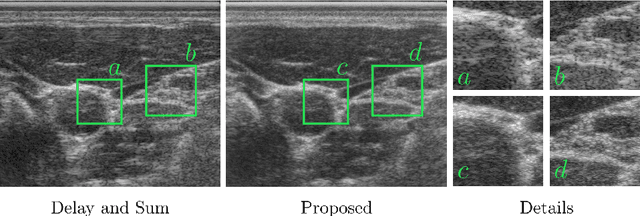
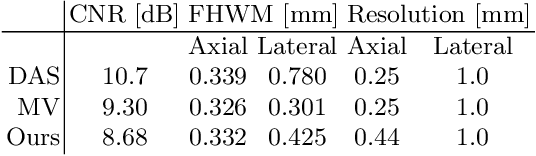
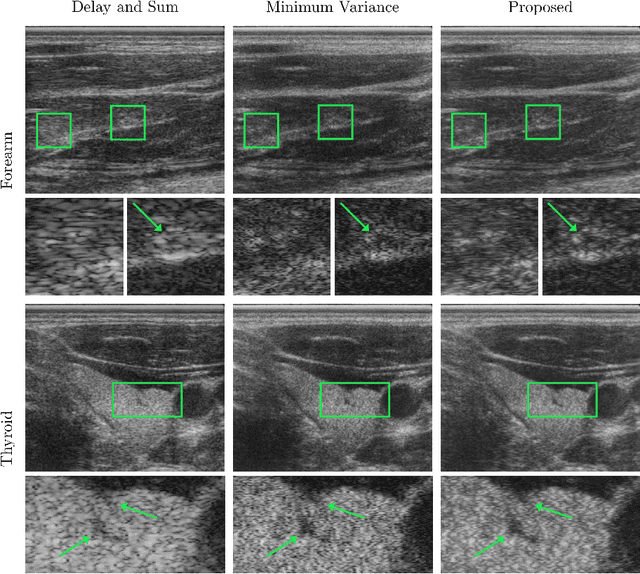
Ultrasound imaging is caught between the quest for the highest image quality, and the necessity for clinical usability. Our contribution is two-fold: First, we propose a novel fully convolutional neural network for ultrasound reconstruction. Second, a custom loss function tailored to the modality is employed for end-to-end training of the network. We demonstrate that training a network to map time-delayed raw data to a minimum variance ground truth offers performance increases in a clinical environment. In doing so, a path is explored towards improved clinically viable ultrasound reconstruction. The proposed method displays both promising image reconstruction quality and acquisition frequency when integrated for live ultrasound scanning. A clinical evaluation is conducted to verify the diagnostic usefulness of the proposed method in a clinical setting.
FaceQnet: Quality Assessment for Face Recognition based on Deep Learning
Apr 04, 2019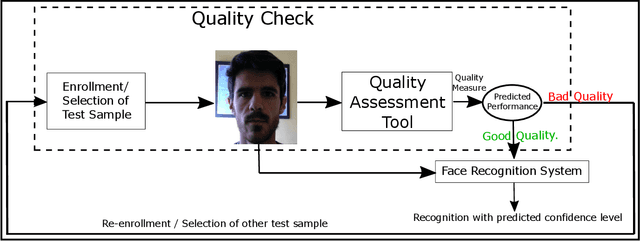


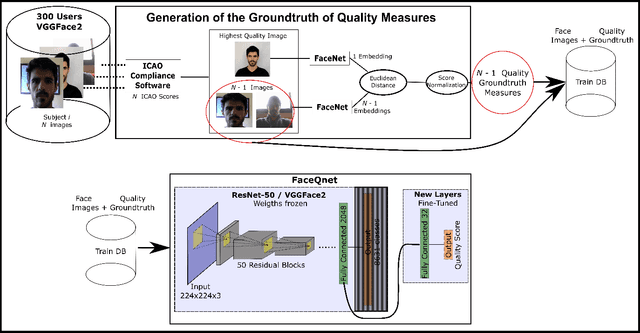
In this paper we develop a Quality Assessment approach for face recognition based on deep learning. The method consists of a Convolutional Neural Network, FaceQnet, that is used to predict the suitability of a specific input image for face recognition purposes. The training of FaceQnet is done using the VGGFace2 database. We employ the BioLab-ICAO framework for labeling the VGGFace2 images with quality information related to their ICAO compliance level. The groundtruth quality labels are obtained using FaceNet to generate comparison scores. We employ the groundtruth data to fine-tune a ResNet-based CNN, making it capable of returning a numerical quality measure for each input image. Finally, we verify if the FaceQnet scores are suitable to predict the expected performance when employing a specific image for face recognition with a COTS face recognition system. Several conclusions can be drawn from this work, most notably: 1) we managed to employ an existing ICAO compliance framework and a pretrained CNN to automatically label data with quality information, 2) we trained FaceQnet for quality estimation by fine-tuning a pre-trained face recognition network (ResNet-50), and 3) we have shown that the predictions from FaceQnet are highly correlated with the face recognition accuracy of a state-of-the-art commercial system not used during development. FaceQnet is publicly available in GitHub.
Image patch analysis and clustering of sunspots: a dimensionality reduction approach
Jun 24, 2014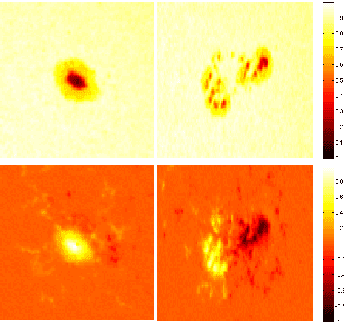
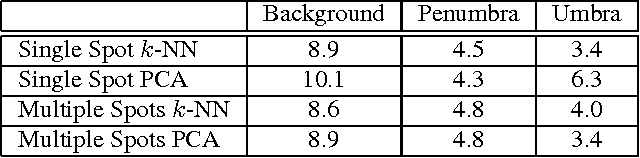
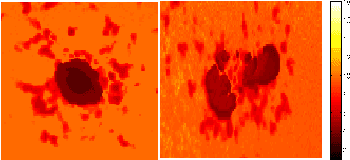
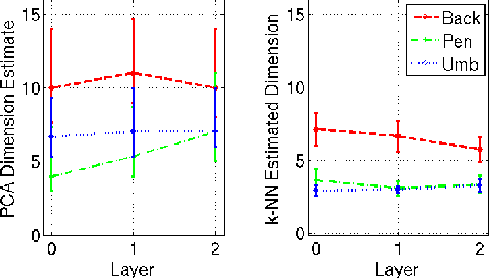
Sunspots, as seen in white light or continuum images, are associated with regions of high magnetic activity on the Sun, visible on magnetogram images. Their complexity is correlated with explosive solar activity and so classifying these active regions is useful for predicting future solar activity. Current classification of sunspot groups is visually based and suffers from bias. Supervised learning methods can reduce human bias but fail to optimally capitalize on the information present in sunspot images. This paper uses two image modalities (continuum and magnetogram) to characterize the spatial and modal interactions of sunspot and magnetic active region images and presents a new approach to cluster the images. Specifically, in the framework of image patch analysis, we estimate the number of intrinsic parameters required to describe the spatial and modal dependencies, the correlation between the two modalities and the corresponding spatial patterns, and examine the phenomena at different scales within the images. To do this, we use linear and nonlinear intrinsic dimension estimators, canonical correlation analysis, and multiresolution analysis of intrinsic dimension.
* 5 pages, 7 figures, accepted to ICIP 2014