 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEHSOD: CAM-Guided End-to-end Hybrid-Supervised Object Detection with Cascade Refinement
Paper and Code
Feb 18, 2020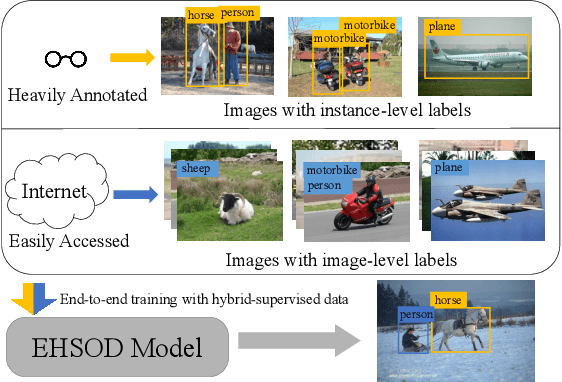
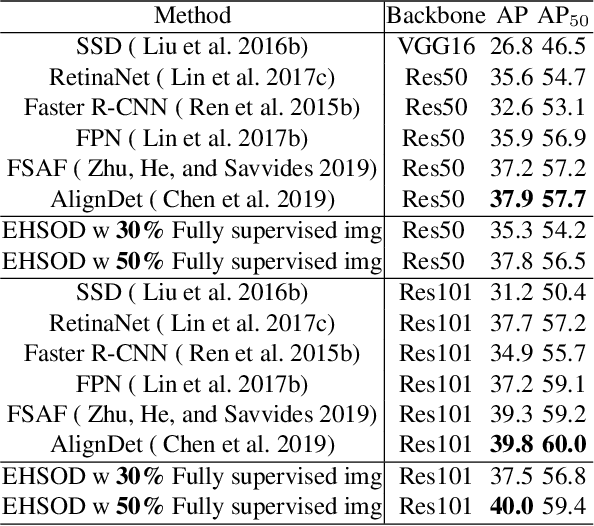
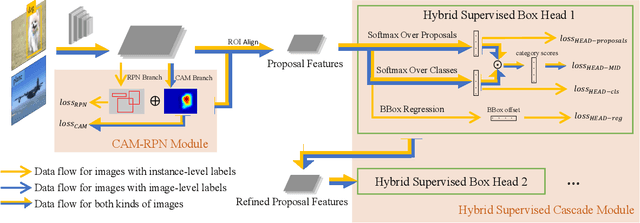
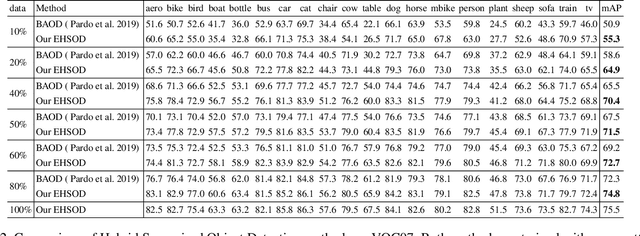
Object detectors trained on fully-annotated data currently yield state of the art performance but require expensive manual annotations. On the other hand, weakly-supervised detectors have much lower performance and cannot be used reliably in a realistic setting. In this paper, we study the hybrid-supervised object detection problem, aiming to train a high quality detector with only a limited amount of fullyannotated data and fully exploiting cheap data with imagelevel labels. State of the art methods typically propose an iterative approach, alternating between generating pseudo-labels and updating a detector. This paradigm requires careful manual hyper-parameter tuning for mining good pseudo labels at each round and is quite time-consuming. To address these issues, we present EHSOD, an end-to-end hybrid-supervised object detection system which can be trained in one shot on both fully and weakly-annotated data. Specifically, based on a two-stage detector, we proposed two modules to fully utilize the information from both kinds of labels: 1) CAMRPN module aims at finding foreground proposals guided by a class activation heat-map; 2) hybrid-supervised cascade module further refines the bounding-box position and classification with the help of an auxiliary head compatible with image-level data. Extensive experiments demonstrate the effectiveness of the proposed method and it achieves comparable results on multiple object detection benchmarks with only 30% fully-annotated data, e.g. 37.5% mAP on COCO. We will release the code and the trained models.