 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying the lottery with rewards and multiple languages: lottery tickets in RL and NLP
Paper and Code

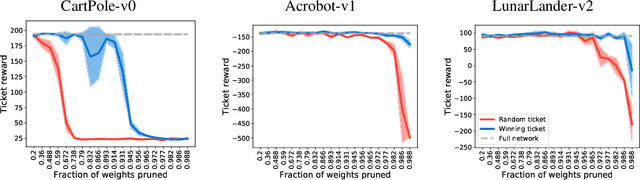
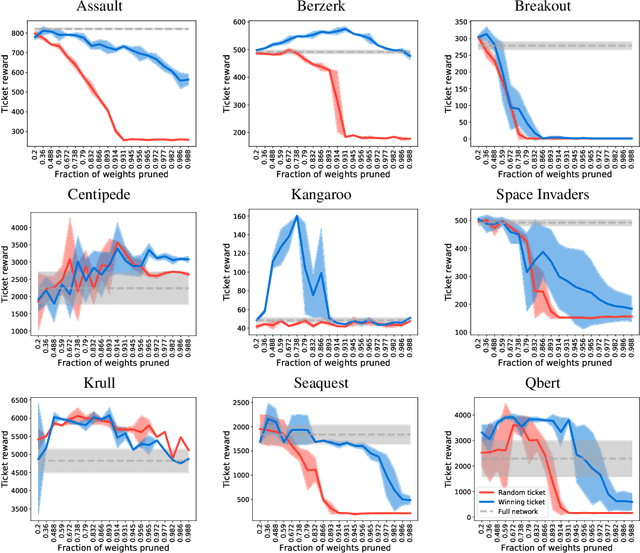
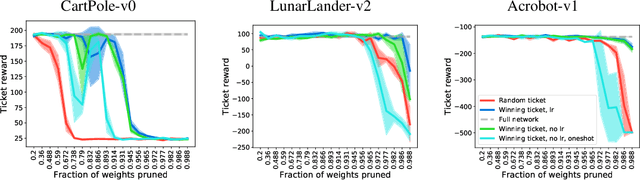
The lottery ticket hypothesis proposes that over-parameterization of deep neural networks (DNNs) aids training by increasing the probability of a "lucky" sub-network initialization being present rather than by helping the optimization process. This phenomenon is intriguing and suggests that initialization strategies for DNNs can be improved substantially, but the lottery ticket hypothesis has only previously been tested in the context of supervised learning for natural image tasks. Here, we evaluate whether "winning ticket" initializations exist in two different domains: reinforcement learning (RL) and in natural language processing (NLP). For RL, we analyzed a number of discrete-action space tasks, including both classic control and pixel control. For NLP, we examined both recurrent LSTM models and large-scale Transformer models. Consistent with work in supervised image classification, we confirm that winning ticket initializations generally outperform parameter-matched random initializations, even at extreme pruning rates. Together, these results suggest that the lottery ticket hypothesis is not restricted to supervised learning of natural images, but rather represents a broader phenomenon in DNNs.