 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scene Graph Generation via Conditional Random Fields
Nov 20, 2018
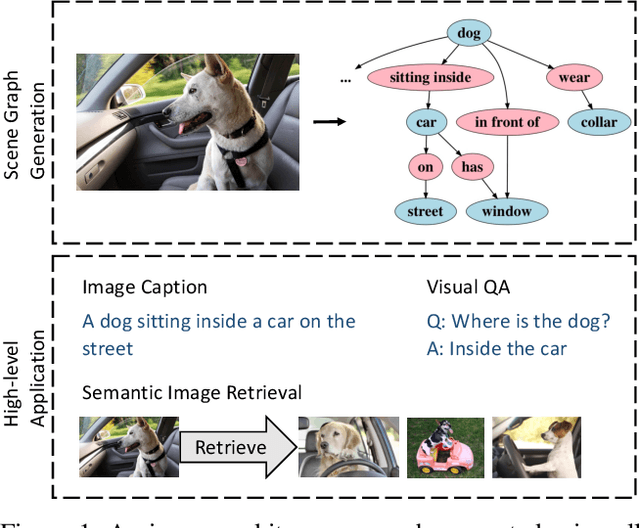
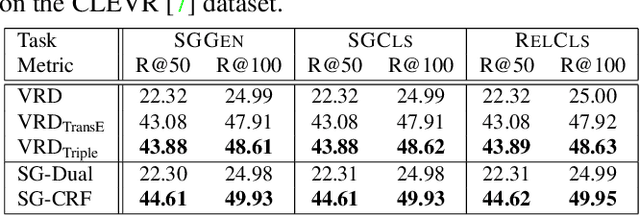
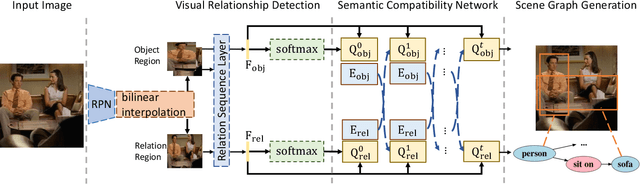
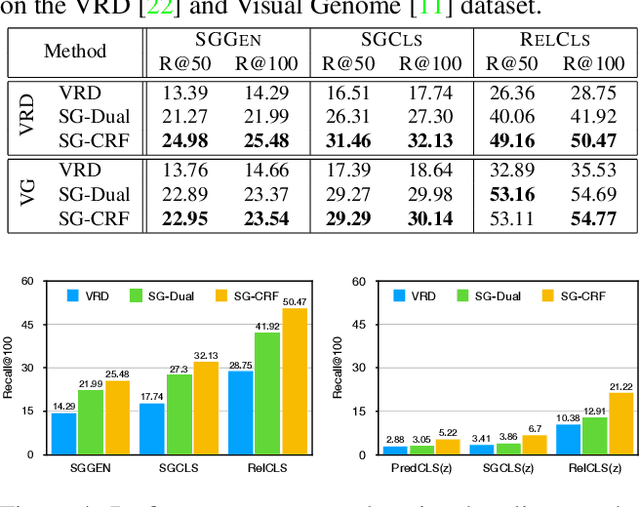
Despite the great success object detection and segmentation models have achieved in recognizing individual objects in images, performance on cognitive tasks such as image caption, semantic image retrieval, and visual QA is far from satisfactory. To achieve better performance on these cognitive tasks, merely recognizing individual object instances is insufficient. Instead, the interactions between object instances need to be captured in order to facilitate reasoning and understanding of the visual scenes in an image. Scene graph, a graph representation of images that captures object instances and their relationships, offers a comprehensive understanding of an image. However, existing techniques on scene graph generation fail to distinguish subjects and objects in the visual scenes of images and thus do not perform well with real-world datasets where exist ambiguous object instances. In this work, we propose a novel scene graph generation model for predicting object instances and its corresponding relationships in an image. Our model, SG-CRF, learns the sequential order of subject and object in a relationship triplet, and the semantic compatibility of object instance nodes and relationship nodes in a scene graph efficiently. Experiments empirically show that SG-CRF outperforms the state-of-the-art methods, on three different datasets, i.e., CLEVR, VRD, and Visual Genome, raising the Recall@100 from 24.99% to 49.95%, from 41.92% to 50.47%, and from 54.69% to 54.77%, respectively.
Local Fourier Slice Photography
Feb 16, 2019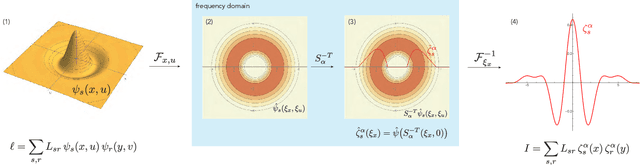
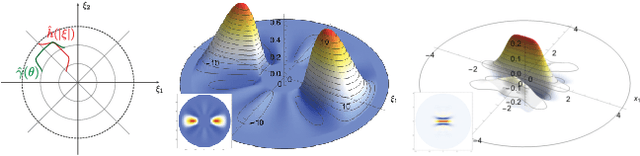
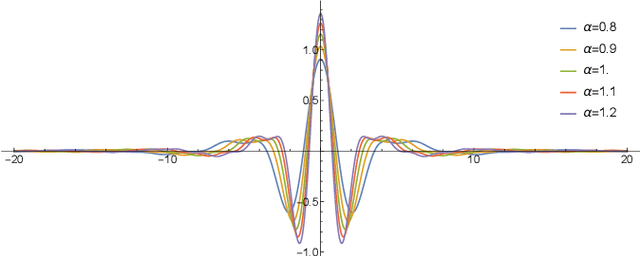
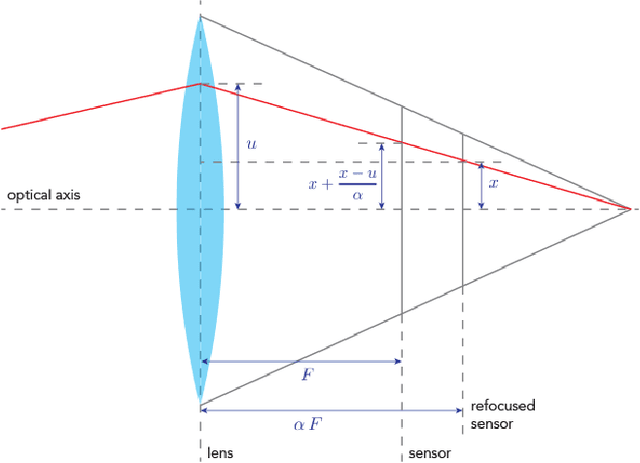
Light field cameras provide intriguing possibilities, such as post-capture refocus or the ability to look behind an object. This comes, however, at the price of significant storage requirements. Compression techniques can be used to reduce these but refocusing and reconstruction require so far again a dense representation. To avoid this, we introduce a sheared local Fourier slice equation that allows for refocusing directly from a compressed light field, either to obtain an image or a compressed representation of it. The result is made possible by wavelets that respect the "slicing's" intrinsic structure and enable us to derive exact reconstruction filters for the refocused image in closed form. Image reconstruction then amounts to applying these filters to the light field's wavelet coefficients, and hence no decompression is necessary. We demonstrate that this substantially reduces storage requirements and also computation times. We furthermore analyze the computational complexity of our algorithm and show that it scales linearly with the size of the reconstructed region and the non-negligible wavelet coefficients, i.e. with the visual complexity.
Efficient Neural Network Approaches for Leather Defect Classification
Jun 15, 2019
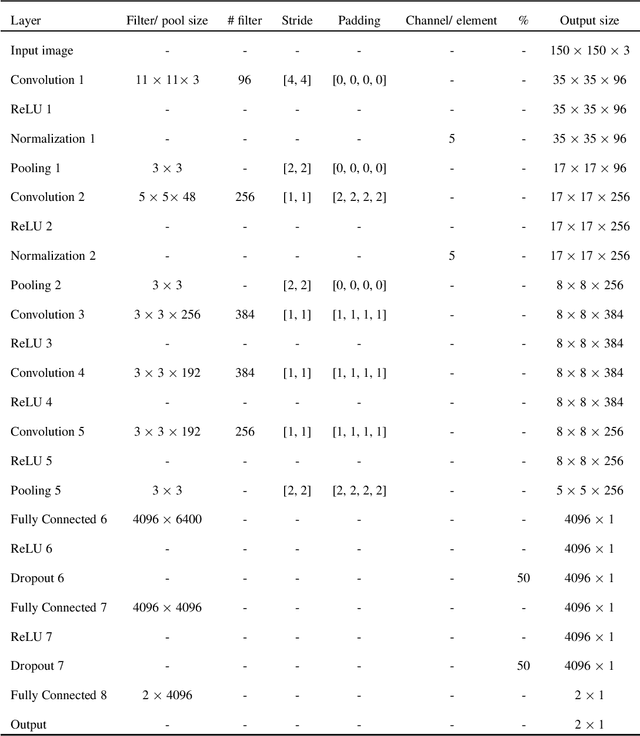

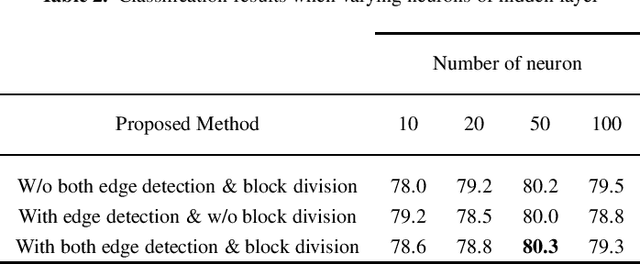
Genuine leather, such as the hides of cows, crocodiles, lizards and goats usually contain natural and artificial defects, like holes, fly bites, tick marks, veining, cuts, wrinkles and others. A traditional solution to identify the defects is by manual defect inspection, which involves skilled experts. It is time consuming and may incur a high error rate and results in low productivity. This paper presents a series of automatic image processing processes to perform the classification of leather defects by adopting deep learning approaches. Particularly, the leather images are first partitioned into small patches,then it undergoes a pre-processing technique, namely the Canny edge detection to enhance defect visualization. Next, artificial neural network (ANN) and convolutional neural network (CNN) are employed to extract the rich image features. The best classification result achieved is 80.3 %, evaluated on a data set that consists of 2000 samples. In addition, the performance metrics such as confusion matrix and Receiver Operating Characteristic (ROC) are reported to demonstrate the efficiency of the method proposed.
Learning in Confusion: Batch Active Learning with Noisy Oracle
Sep 27, 2019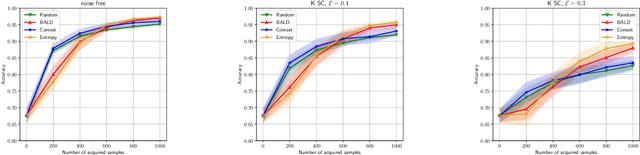
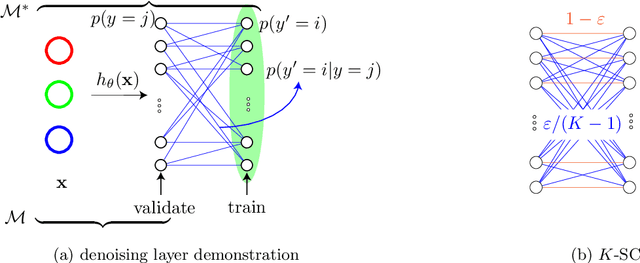
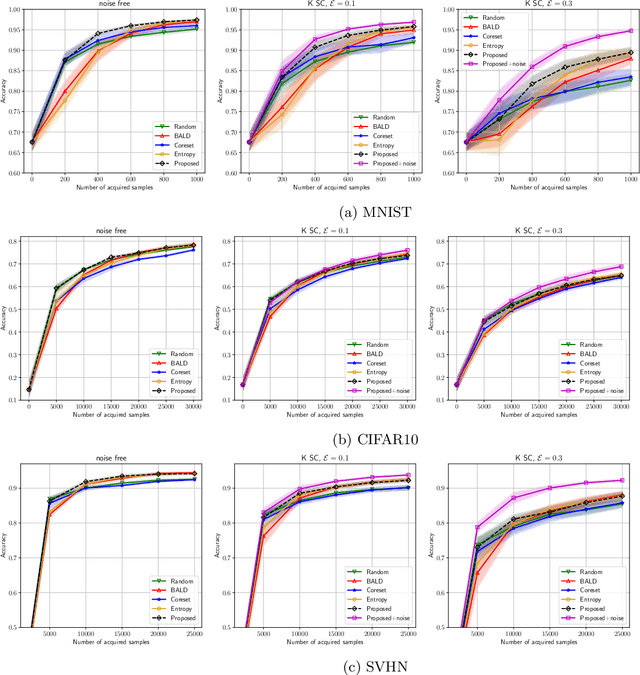
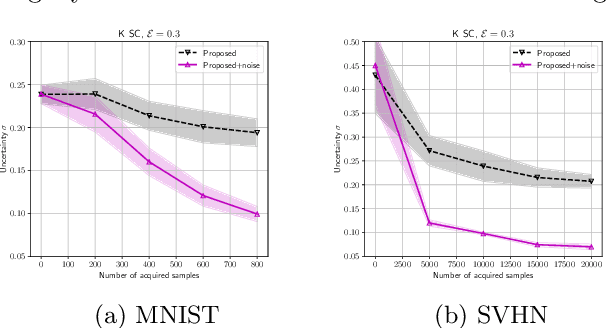
We study the problem of training machine learning models incrementally using active learning with access to imperfect or noisy oracles. We specifically consider the setting of batch active learning, in which multiple samples are selected as opposed to a single sample as in classical settings so as to reduce the training overhead. Our approach bridges between uniform randomness and score based importance sampling of clusters when selecting a batch of new samples. Experiments on benchmark image classification datasets (MNIST, SVHN, and CIFAR10) shows improvement over existing active learning strategies. We introduce an extra denoising layer to deep networks to make active learning robust to label noises and show significant improvements.
Patch Correspondences for Interpreting Pixel-level CNNs
Sep 04, 2018
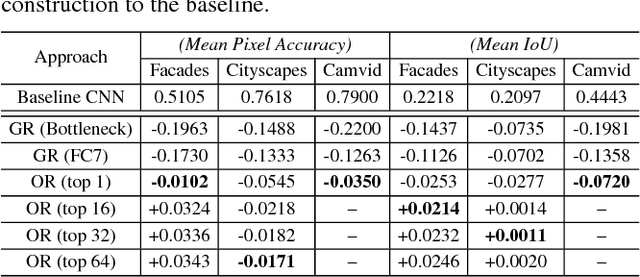
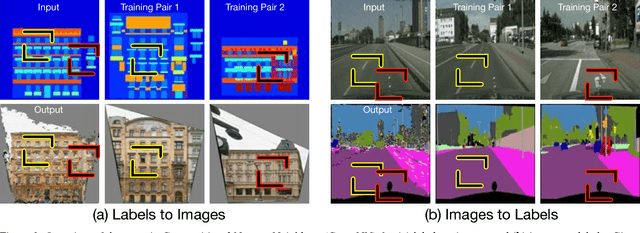
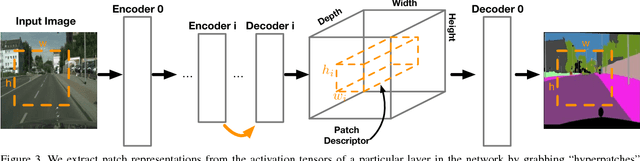
We present compositional nearest neighbors (CompNN), a simple approach to visually interpreting distributed representations learned by a convolutional neural network (CNN) for pixel-level tasks (e.g., image synthesis and segmentation). It does so by reconstructing both a CNN's input and output image by copy-pasting corresponding patches from the training set with similar feature embeddings. To do so efficiently, it makes of a patch-match-based algorithm that exploits the fact that the patch representations learned by a CNN for pixel level tasks vary smoothly. Finally, we show that CompNN can be used to establish semantic correspondences between two images and control properties of the output image by modifying the images contained in the training set. We present qualitative and quantitative experiments for semantic segmentation and image-to-image translation that demonstrate that CompNN is a good tool for interpreting the embeddings learned by pixel-level CNNs.
Convolutional Recurrent Neural Networks for Dynamic MR Image Reconstruction
Oct 14, 2018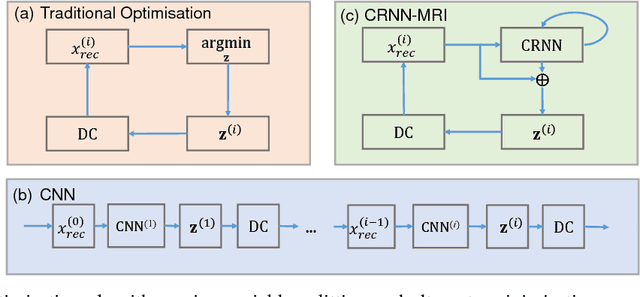
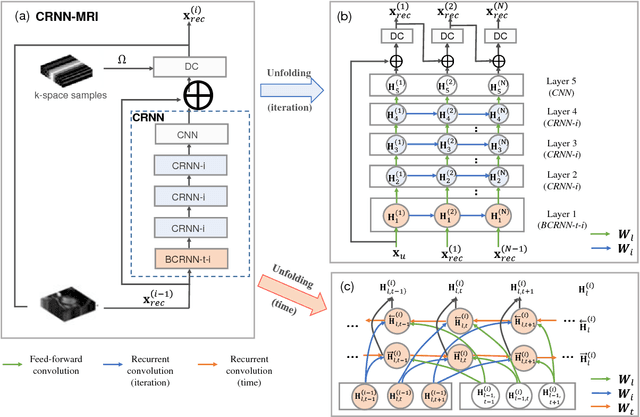
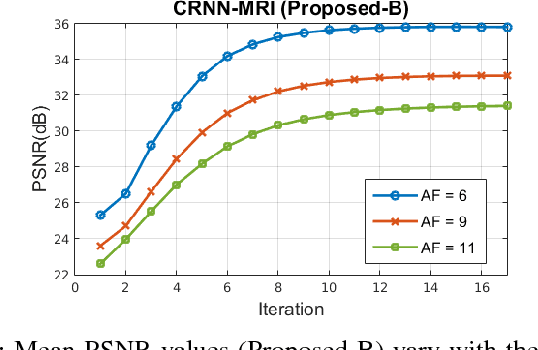
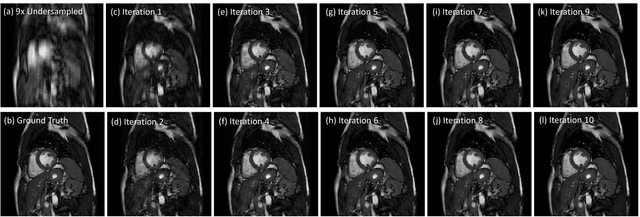
Accelerating the data acquisition of dynamic magnetic resonance imaging (MRI) leads to a challenging ill-posed inverse problem, which has received great interest from both the signal processing and machine learning community over the last decades. The key ingredient to the problem is how to exploit the temporal correlation of the MR sequence to resolve the aliasing artefact. Traditionally, such observation led to a formulation of a non-convex optimisation problem, which were solved using iterative algorithms. Recently, however, deep learning based-approaches have gained significant popularity due to its ability to solve general inversion problems. In this work, we propose a unique, novel convolutional recurrent neural network (CRNN) architecture which reconstructs high quality cardiac MR images from highly undersampled k-space data by jointly exploiting the dependencies of the temporal sequences as well as the iterative nature of the traditional optimisation algorithms. In particular, the proposed architecture embeds the structure of the traditional iterative algorithms, efficiently modelling the recurrence of the iterative reconstruction stages by using recurrent hidden connections over such iterations. In addition, spatiotemporal dependencies are simultaneously learnt by exploiting bidirectional recurrent hidden connections across time sequences. The proposed algorithm is able to learn both the temporal dependency and the iterative reconstruction process effectively with only a very small number of parameters, while outperforming current MR reconstruction methods in terms of computational complexity, reconstruction accuracy and speed.
Superresolution of Noisy Remotely Sensed Images Through Directional Representations
Sep 04, 2018
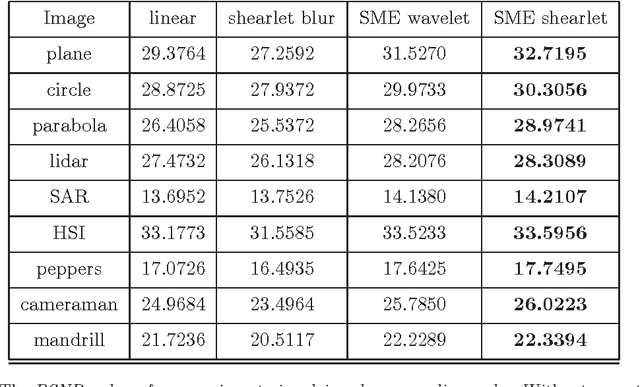

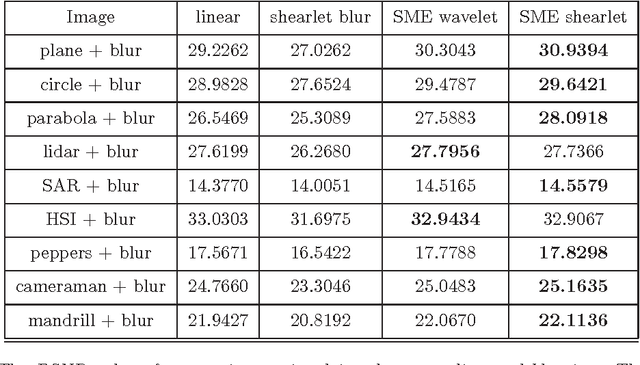
We develop an algorithm for single-image superresolution of remotely sensed data, based on the discrete shearlet transform. The shearlet transform extracts directional features of signals, and is known to provide near-optimally sparse representations for a broad class of images. This often leads to superior performance in edge detection and image representation when compared to isotropic frames. We justify the use of shearlets mathematically, before presenting a denoising single-image superresolution algorithm that combines the shearlet transform with sparse mixing estimators (SME). Our algorithm is compared with a variety of single-image superresolution methods, including wavelet SME superresolution. Our numerical results demonstrate competitive performance in terms of PSNR and SSIM.
Road Crack Detection Using Deep Convolutional Neural Network and Adaptive Thresholding
Apr 18, 2019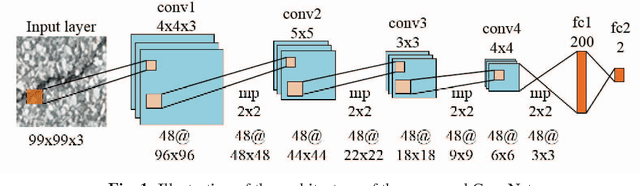
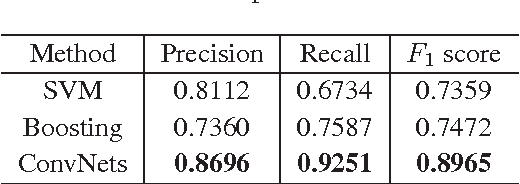
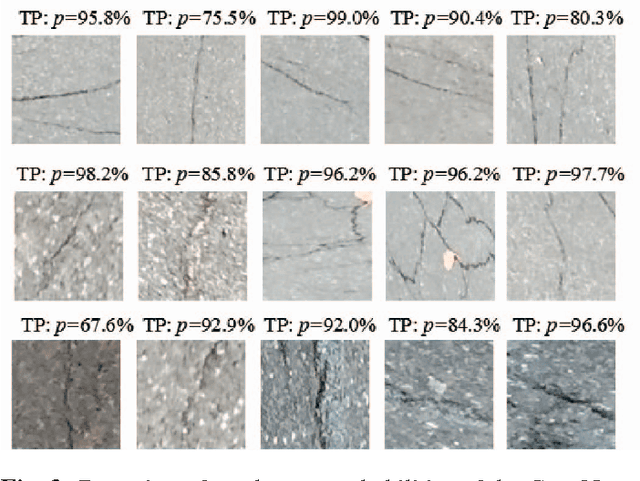
Crack is one of the most common road distresses which may pose road safety hazards. Generally, crack detection is performed by either certified inspectors or structural engineers. This task is, however, time-consuming, subjective and labor-intensive. In this paper, we propose a novel road crack detection algorithm based on deep learning and adaptive image segmentation. Firstly, a deep convolutional neural network is trained to determine whether an image contains cracks or not. The images containing cracks are then smoothed using bilateral filtering, which greatly minimizes the number of noisy pixels. Finally, we utilize an adaptive thresholding method to extract the cracks from road surface. The experimental results illustrate that our network can classify images with an accuracy of 99.92%, and the cracks can be successfully extracted from the images using our proposed thresholding algorithm.
Budget-aware Semi-Supervised Semantic and Instance Segmentation
May 23, 2019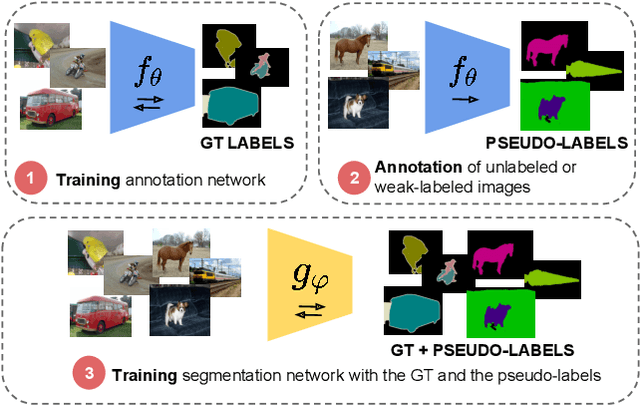


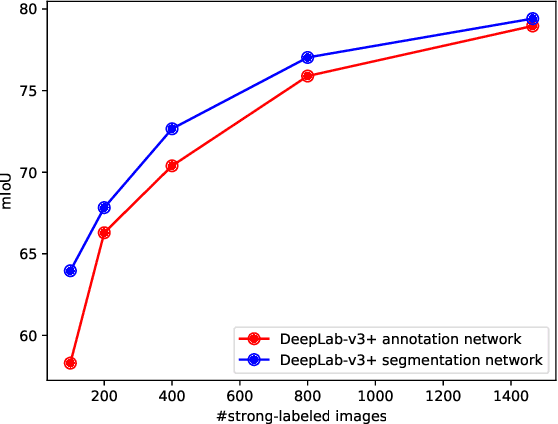
Methods that move towards less supervised scenarios are key for image segmentation, as dense labels demand significant human intervention. Generally, the annotation burden is mitigated by labeling datasets with weaker forms of supervision, e.g. image-level labels or bounding boxes. Another option are semi-supervised settings, that commonly leverage a few strong annotations and a huge number of unlabeled/weakly-labeled data. In this paper, we revisit semi-supervised segmentation schemes and narrow down significantly the annotation budget (in terms of total labeling time of the training set) compared to previous approaches. With a very simple pipeline, we demonstrate that at low annotation budgets, semi-supervised methods outperform by a wide margin weakly-supervised ones for both semantic and instance segmentation. Our approach also outperforms previous semi-supervised works at a much reduced labeling cost. We present results for the Pascal VOC benchmark and unify weakly and semi-supervised approaches by considering the total annotation budget, thus allowing a fairer comparison between methods.
Noise2Void - Learning Denoising from Single Noisy Images
Nov 27, 2018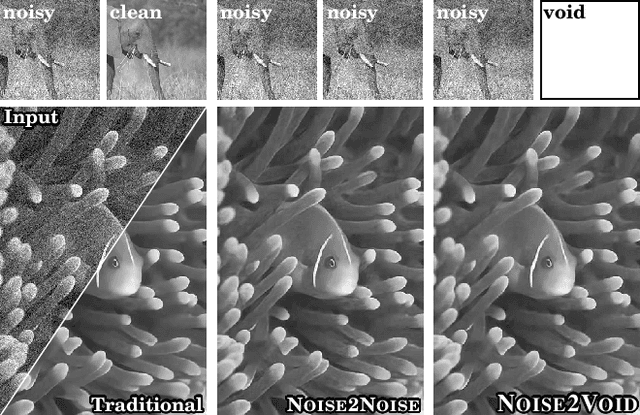
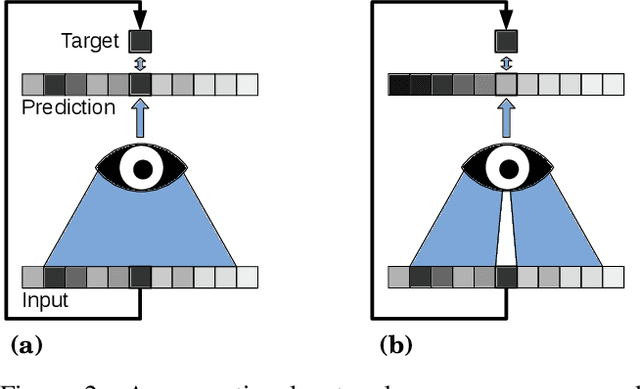

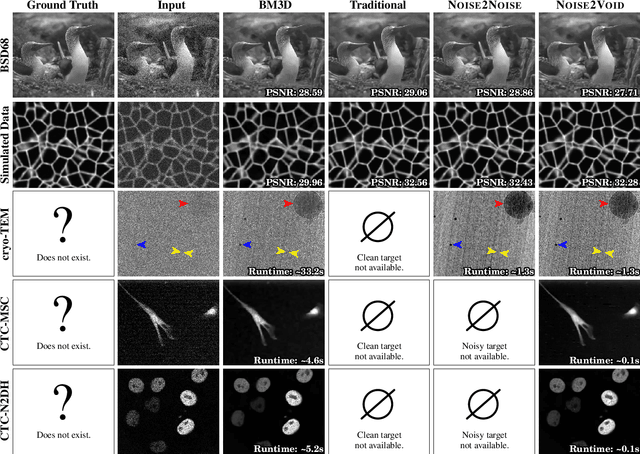
The field of image denoising is currently dominated by discriminative deep learning methods that are trained on pairs of noisy input and clean target images. Recently it has been shown that such methods can also be trained without clean targets. Instead, independent pairs of noisy images can be used, in an approach known as Noise2Noise (N2N). Here, we introduce Noise2Void (N2V), a training scheme that takes this idea one step further. It does not require noisy image pairs, nor clean target images. Consequently, N2V allows us to train directly on the body of data to be denoised and can therefore be applied when other methods cannot. Especially interesting is the application to biomedical image data, where the acquisition of training targets, clean or noisy, is frequently not possible. We compare the performance of N2V to approaches that have either clean target images and/or noisy image pairs available. Intuitively, N2V cannot be expected to outperform methods that have more information available during training. Still, we observe that the denoising performance of Noise2Void drops in moderation and compares favorably to training-free denoising methods.