 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Simultaneously sparse and low-rank abundance matrix estimation for hyperspectral image unmixing
Oct 14, 2015
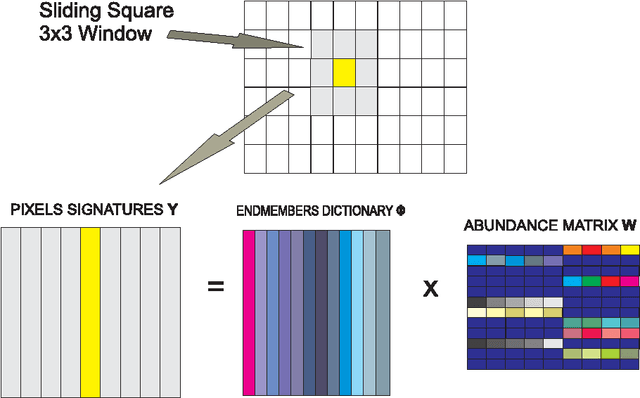
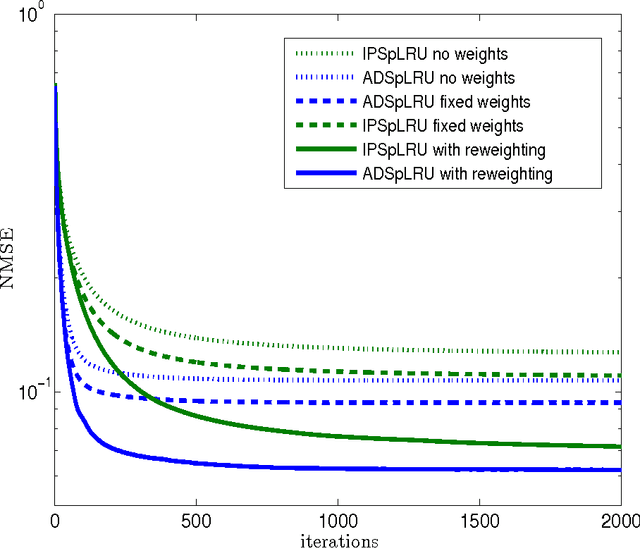
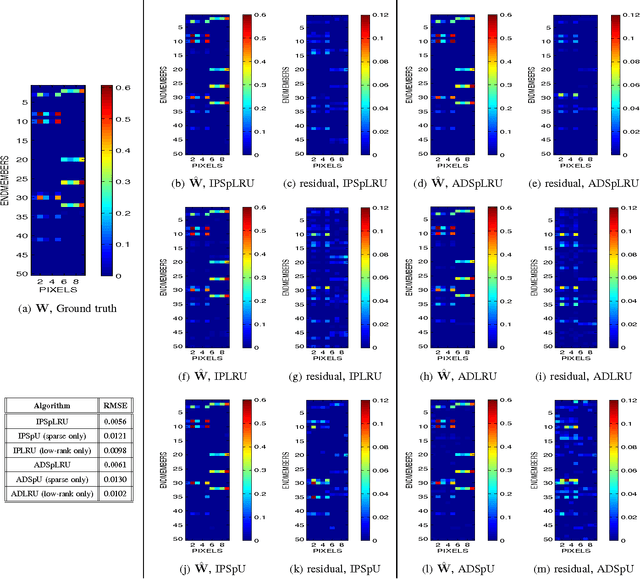
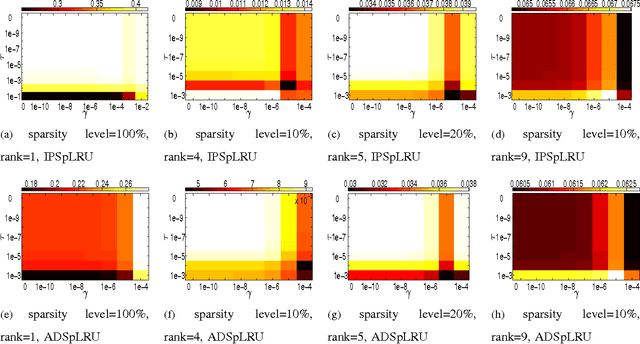
In a plethora of applications dealing with inverse problems, e.g. in image processing, social networks, compressive sensing, biological data processing etc., the signal of interest is known to be structured in several ways at the same time. This premise has recently guided the research to the innovative and meaningful idea of imposing multiple constraints on the parameters involved in the problem under study. For instance, when dealing with problems whose parameters form sparse and low-rank matrices, the adoption of suitably combined constraints imposing sparsity and low-rankness, is expected to yield substantially enhanced estimation results. In this paper, we address the spectral unmixing problem in hyperspectral images. Specifically, two novel unmixing algorithms are introduced, in an attempt to exploit both spatial correlation and sparse representation of pixels lying in homogeneous regions of hyperspectral images. To this end, a novel convex mixed penalty term is first defined consisting of the sum of the weighted $\ell_1$ and the weighted nuclear norm of the abundance matrix corresponding to a small area of the image determined by a sliding square window. This penalty term is then used to regularize a conventional quadratic cost function and impose simultaneously sparsity and row-rankness on the abundance matrix. The resulting regularized cost function is minimized by a) an incremental proximal sparse and low-rank unmixing algorithm and b) an algorithm based on the alternating minimization method of multipliers (ADMM). The effectiveness of the proposed algorithms is illustrated in experiments conducted both on simulated and real data.
Walking on the Edge: Fast, Low-Distortion Adversarial Examples
Dec 05, 2019
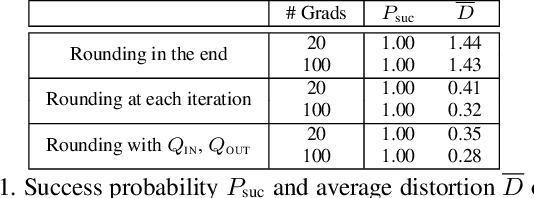
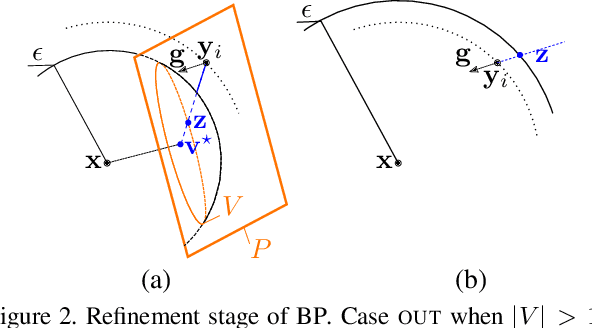
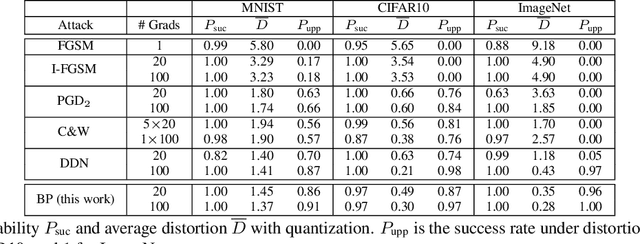
Adversarial examples of deep neural networks are receiving ever increasing attention because they help in understanding and reducing the sensitivity to their input. This is natural given the increasing applications of deep neural networks in our everyday lives. When white-box attacks are almost always successful, it is typically only the distortion of the perturbations that matters in their evaluation. In this work, we argue that speed is important as well, especially when considering that fast attacks are required by adversarial training. Given more time, iterative methods can always find better solutions. We investigate this speed-distortion trade-off in some depth and introduce a new attack called boundary projection (BP) that improves upon existing methods by a large margin. Our key idea is that the classification boundary is a manifold in the image space: we therefore quickly reach the boundary and then optimize distortion on this manifold.
Learn to Explain Efficiently via Neural Logic Inductive Learning
Oct 06, 2019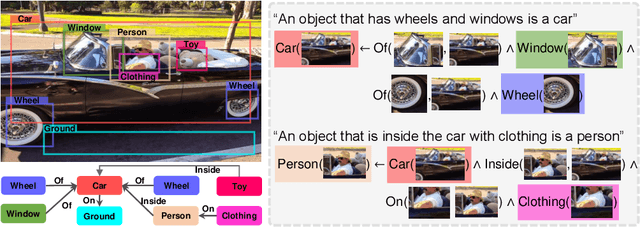
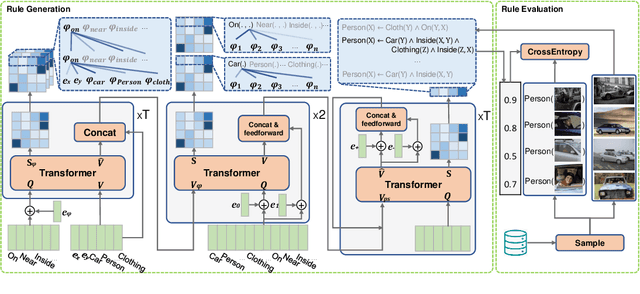
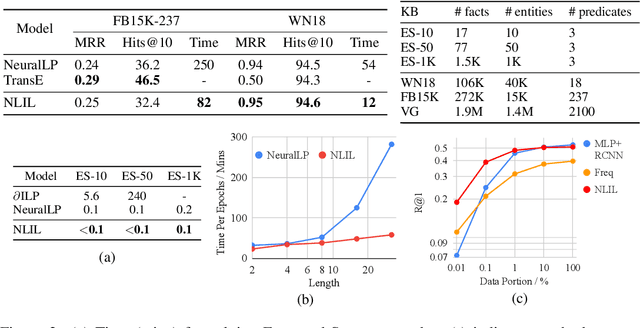
The capability of making interpretable and self-explanatory decisions is essential for developing responsible machine learning systems. In this work, we study the learning to explain problem in the scope of inductive logic programming (ILP). We propose Neural Logic Inductive Learning (NLIL), an efficient differentiable ILP framework that learns first-order logic rules that can explain the patterns in the data. In experiments, compared with the state-of-the-art methods, we find NLIL can search for rules that are x10 times longer while remaining x3 times faster. We also show that NLIL can scale to large image datasets, i.e. Visual Genome, with 1M entities.
Accuracy vs. Complexity: A Trade-off in Visual Question Answering Models
Jan 20, 2020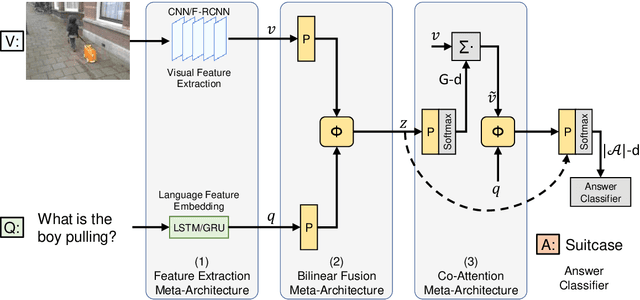
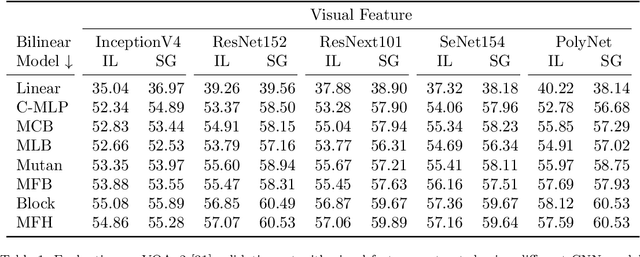
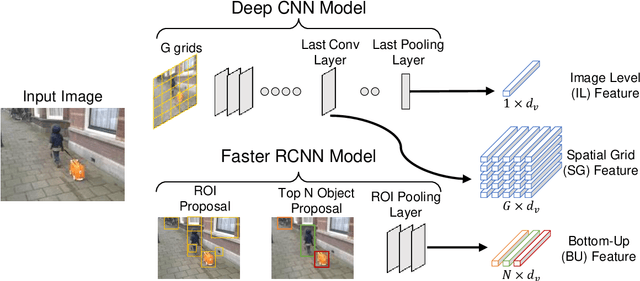
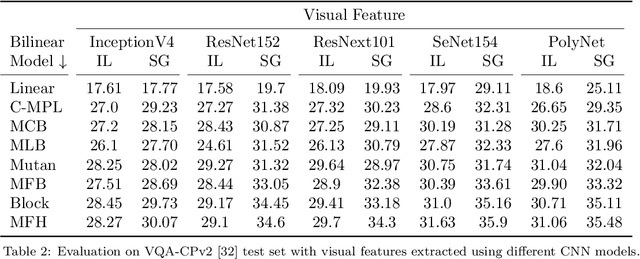
Visual Question Answering (VQA) has emerged as a Visual Turing Test to validate the reasoning ability of AI agents. The pivot to existing VQA models is the joint embedding that is learned by combining the visual features from an image and the semantic features from a given question. Consequently, a large body of literature has focused on developing complex joint embedding strategies coupled with visual attention mechanisms to effectively capture the interplay between these two modalities. However, modelling the visual and semantic features in a high dimensional (joint embedding) space is computationally expensive, and more complex models often result in trivial improvements in the VQA accuracy. In this work, we systematically study the trade-off between the model complexity and the performance on the VQA task. VQA models have a diverse architecture comprising of pre-processing, feature extraction, multimodal fusion, attention and final classification stages. We specifically focus on the effect of "multi-modal fusion" in VQA models that is typically the most expensive step in a VQA pipeline. Our thorough experimental evaluation leads us to two proposals, one optimized for minimal complexity and the other one optimized for state-of-the-art VQA performance.
Knowledge-guided Pairwise Reconstruction Network for Weakly Supervised Referring Expression Grounding
Sep 05, 2019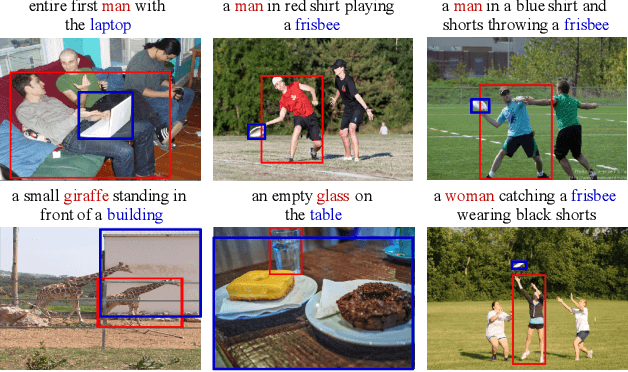
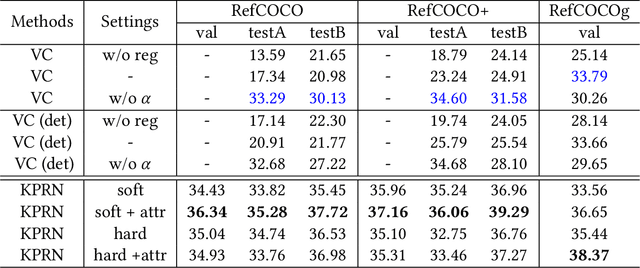
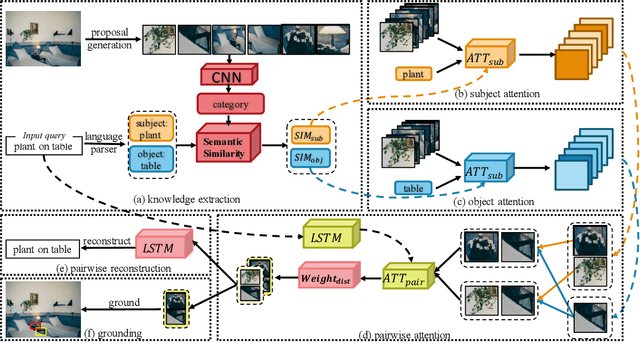
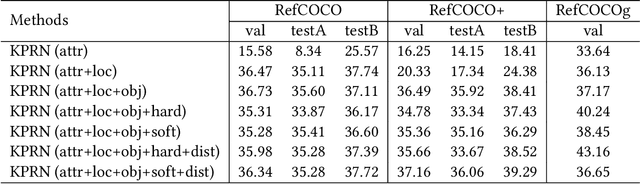
Weakly supervised referring expression grounding (REG) aims at localizing the referential entity in an image according to linguistic query, where the mapping between the image region (proposal) and the query is unknown in the training stage. In referring expressions, people usually describe a target entity in terms of its relationship with other contextual entities as well as visual attributes. However, previous weakly supervised REG methods rarely pay attention to the relationship between the entities. In this paper, we propose a knowledge-guided pairwise reconstruction network (KPRN), which models the relationship between the target entity (subject) and contextual entity (object) as well as grounds these two entities. Specifically, we first design a knowledge extraction module to guide the proposal selection of subject and object. The prior knowledge is obtained in a specific form of semantic similarities between each proposal and the subject/object. Second, guided by such knowledge, we design the subject and object attention module to construct the subject-object proposal pairs. The subject attention excludes the unrelated proposals from the candidate proposals. The object attention selects the most suitable proposal as the contextual proposal. Third, we introduce a pairwise attention and an adaptive weighting scheme to learn the correspondence between these proposal pairs and the query. Finally, a pairwise reconstruction module is used to measure the grounding for weakly supervised learning. Extensive experiments on four large-scale datasets show our method outperforms existing state-of-the-art methods by a large margin.
Efficient Neural Architecture Transformation Searchin Channel-Level for Object Detection
Sep 05, 2019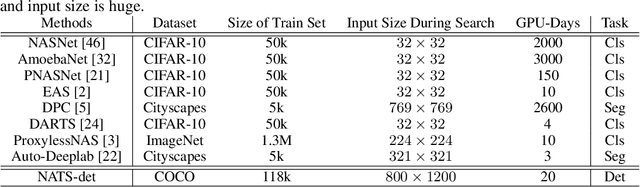

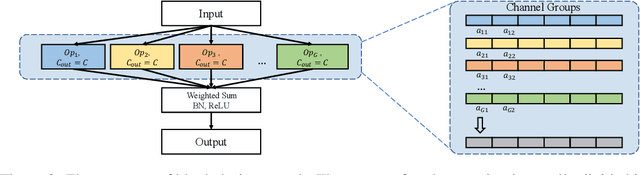
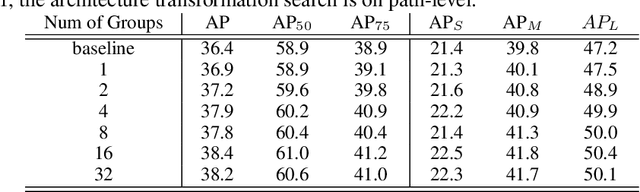
Recently, Neural Architecture Search has achieved great success in large-scale image classification. In contrast, there have been limited works focusing on architecture search for object detection, mainly because the costly ImageNet pre-training is always required for detectors. Training from scratch, as a substitute, demands more epochs to converge and brings no computation saving. To overcome this obstacle, we introduce a practical neural architecture transformation search(NATS)algorithm for object detection in this paper. Instead of searching and constructing an entire network, NATS explores the architecture space on the base of existing network and reusing its weights. We propose a novel neural architecture search strategy in channel-level instead of path-level and devise a search space specially targeting at object detection. With the combination of these two designs, an architecture transformation scheme could be discovered to adapt a network designed for image classification to task of object detection. Since our method is gradient-based and only searches for a transformation scheme, the weights of models pretrained inImageNet could be utilized in both searching and retraining stage, which makes the whole process very efficient. The transformed network requires no extra parameters and FLOPs, and is friendly to hardware optimization, which is practical to use in real-time application. In experiments, we demonstrate the effectiveness of NATSon networks like ResNet and ResNeXt. Our transformed networks, combined with various detection frameworks, achieve significant improvements on the COCO dataset while keeping fast.
Measuring the Utilization of Public Open Spaces by Deep Learning: a Benchmark Study at the Detroit Riverfront
Feb 04, 2020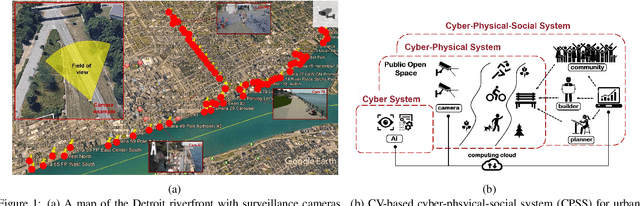
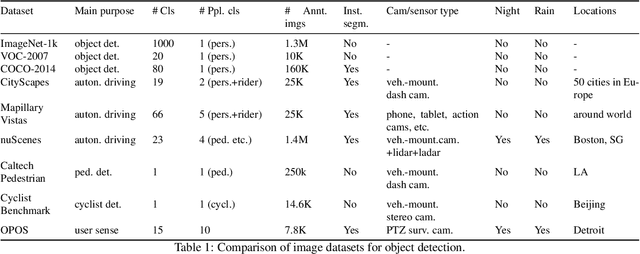

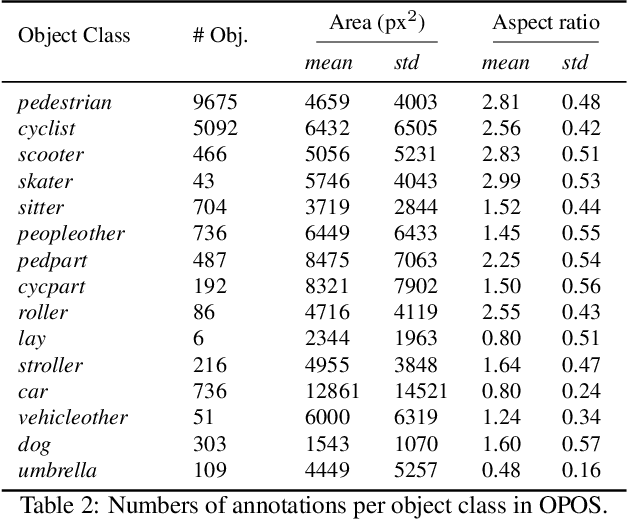
Physical activities and social interactions are essential activities that ensure a healthy lifestyle. Public open spaces (POS), such as parks, plazas and greenways, are key environments that encourage those activities. To evaluate a POS, there is a need to study how humans use the facilities within it. However, traditional approaches to studying use of POS are manual and therefore time and labor intensive. They also may only provide qualitative insights. It is appealing to make use of surveillance cameras and to extract user-related information through computer vision. This paper proposes a proof-of-concept deep learning computer vision framework for measuring human activities quantitatively in POS and demonstrates a case study of the proposed framework using the Detroit Riverfront Conservancy (DRFC) surveillance camera network. A custom image dataset is presented to train the framework; the dataset includes 7826 fully annotated images collected from 18 cameras across the DRFC park space under various illumination conditions. Dataset analysis is also provided as well as a baseline model for one-step user localization and activity recognition. The mAP results are 77.5\% for {\it pedestrian} detection and 81.6\% for {\it cyclist} detection. Behavioral maps are autonomously generated by the framework to locate different POS users and the average error for behavioral localization is within 10 cm.
Spatio-Temporal Deep Learning-Based Undersampling Artefact Reduction for 2D Radial Cine MRI with Limited Data
Apr 01, 2019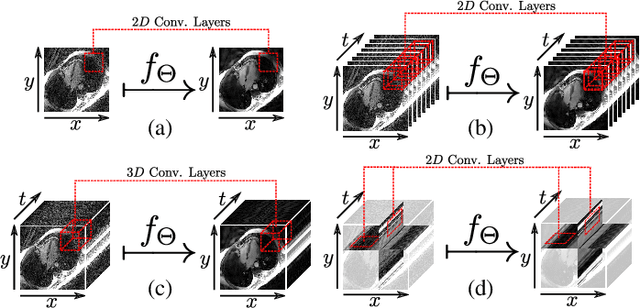
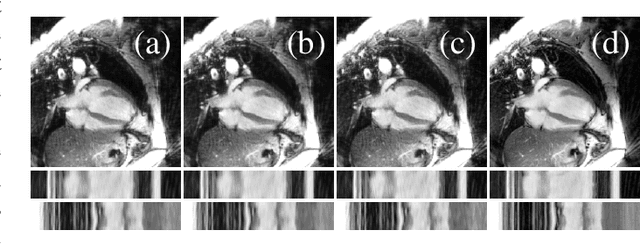

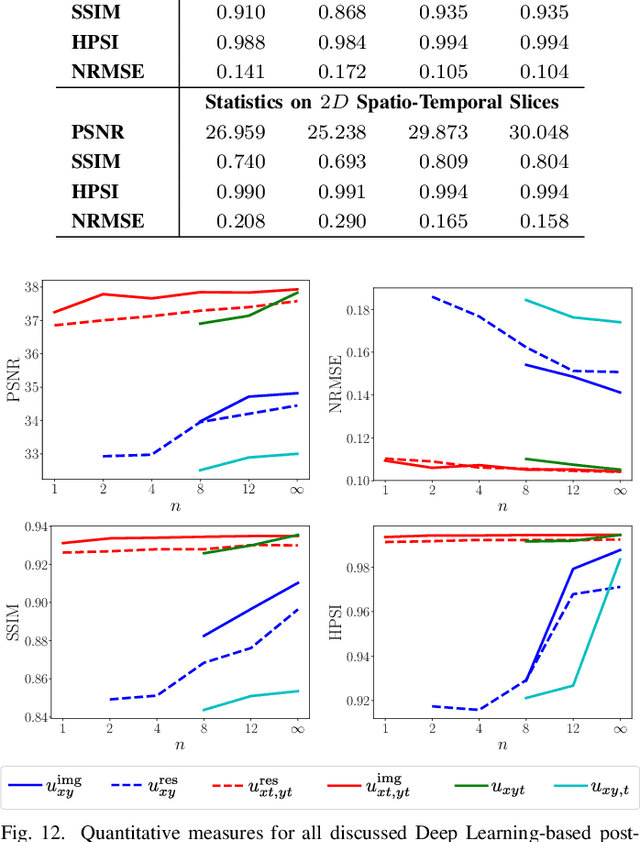
In this work we reduce undersampling artefacts in two-dimensional ($2D$) golden-angle radial cine cardiac MRI by applying a modified version of the U-net. We train the network on $2D$ spatio-temporal slices which are previously extracted from the image sequences. We compare our approach to two $2D$ and a $3D$ Deep Learning-based post processing methods and to three iterative reconstruction methods for dynamic cardiac MRI. Our method outperforms the $2D$ spatially trained U-net and the $2D$ spatio-temporal U-net. Compared to the $3D$ spatio-temporal U-net, our method delivers comparable results, but with shorter training times and less training data. Compared to the Compressed Sensing-based methods $kt$-FOCUSS and a total variation regularised reconstruction approach, our method improves image quality with respect to all reported metrics. Further, it achieves competitive results when compared to an iterative reconstruction method based on adaptive regularization with Dictionary Learning and total variation, while only requiring a small fraction of the computational time. A persistent homology analysis demonstrates that the data manifold of the spatio-temporal domain has a lower complexity than the spatial domain and therefore, the learning of a projection-like mapping is facilitated. Even when trained on only one single subject without data-augmentation, our approach yields results which are similar to the ones obtained on a large training dataset. This makes the method particularly suitable for training a network on limited training data. Finally, in contrast to the spatial $2D$ U-net, our proposed method is shown to be naturally robust with respect to image rotation in image space and almost achieves rotation-equivariance where neither data-augmentation nor a particular network design are required.
Self-Contained Stylization via Steganography for Reverse and Serial Style Transfer
Dec 10, 2018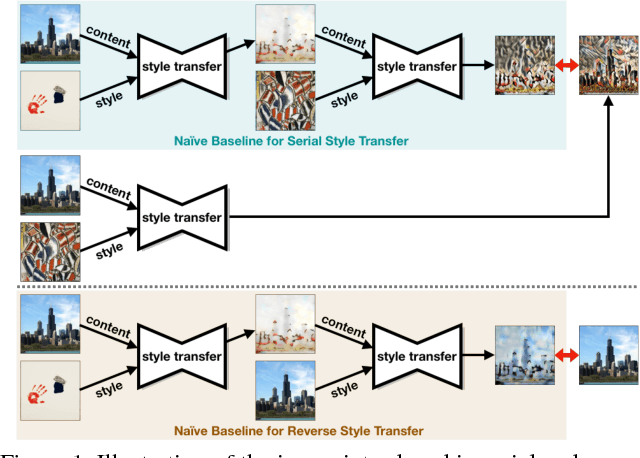

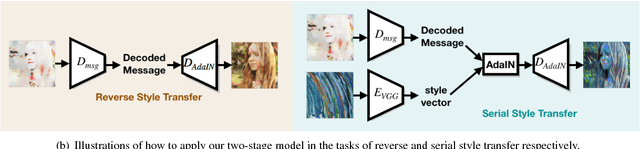
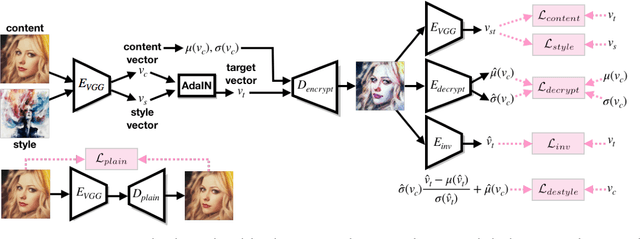
Style transfer has been widely applied to give real-world images a new artistic look. However, given a stylized image, the attempts to use typical style transfer methods for de-stylization or transferring it again into another style usually lead to artifacts or undesired results. We realize that these issues are originated from the content inconsistency between the original image and its stylized output. Therefore in this paper we advance to keep the content information of the input image during process of style transfer by the power of steganography, with two approaches proposed: a two-stage model and an end-to-end model. We conduct extensive experiments to successfully verify the capacity of our models, in which both of them are able to not only generate stylized images of quality comparable with the ones produced by state-of-the-art style transfer methods, but also effectively eliminate the artifacts introduced in reconstructing original input from a stylized image as well as performing multiple times of style transfer in series.
Lake Ice Monitoring with Webcams and Crowd-Sourced Images
Feb 18, 2020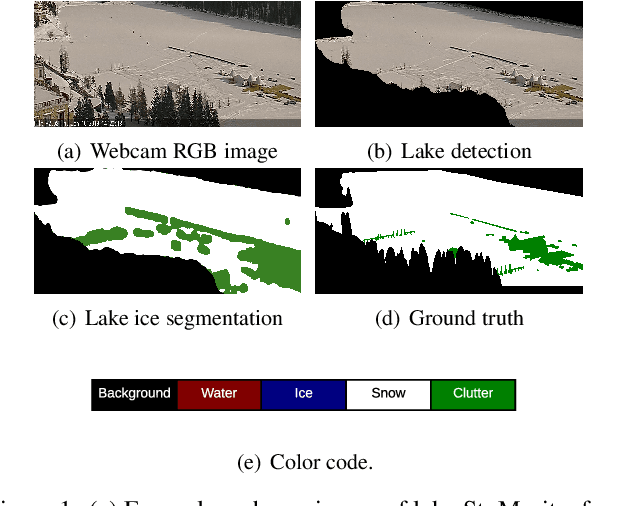
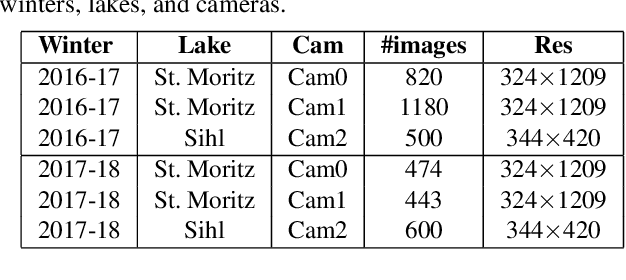

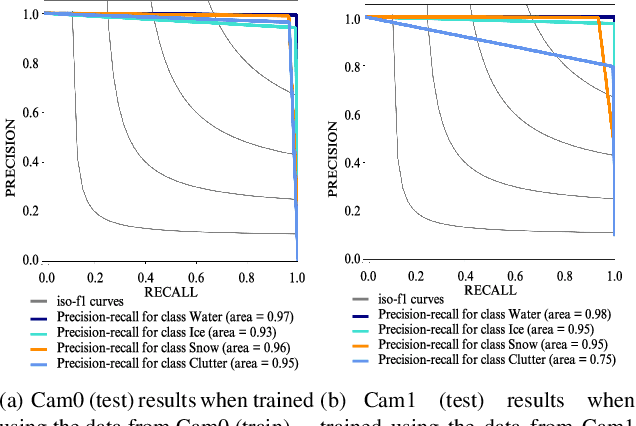
Lake ice is a strong climate indicator and has been recognised as part of the Essential Climate Variables (ECV) by the Global Climate Observing System (GCOS). The dynamics of freezing and thawing, and possible shifts of freezing patterns over time, can help in understanding the local and global climate systems. One way to acquire the spatio-temporal information about lake ice formation, independent of clouds, is to analyse webcam images. This paper intends to move towards a universal model for monitoring lake ice with freely available webcam data. We demonstrate good performance, including the ability to generalise across different winters and different lakes, with a state-of-the-art Convolutional Neural Network (CNN) model for semantic image segmentation, Deeplab v3+. Moreover, we design a variant of that model, termed Deep-U-Lab, which predicts sharper, more correct segmentation boundaries. We have tested the model's ability to generalise with data from multiple camera views and two different winters. On average, it achieves intersection-over-union (IoU) values of ~71% across different cameras and ~69% across different winters, greatly outperforming prior work. Going even further, we show that the model even achieves 60% IoU on arbitrary images scraped from photo-sharing web sites. As part of the work, we introduce a new benchmark dataset of webcam images, Photi-LakeIce, from multiple cameras and two different winters, along with pixel-wise ground truth annotations.