 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-guided Pairwise Reconstruction Network for Weakly Supervised Referring Expression Grounding
Paper and Code
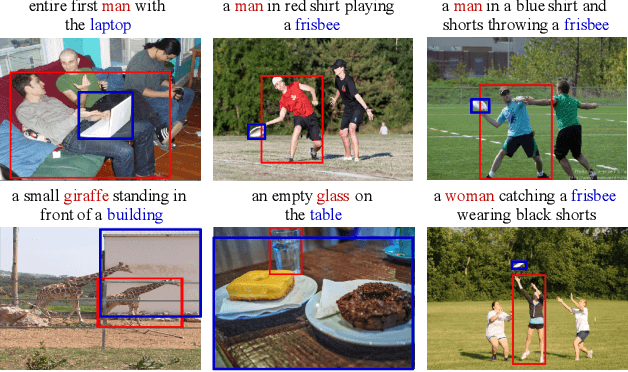
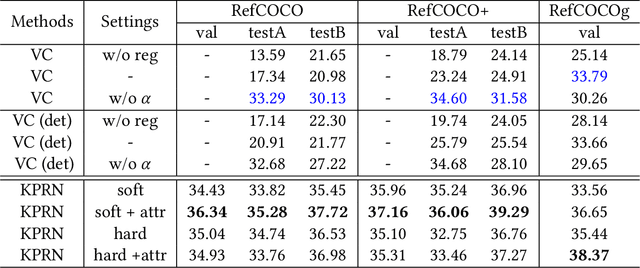
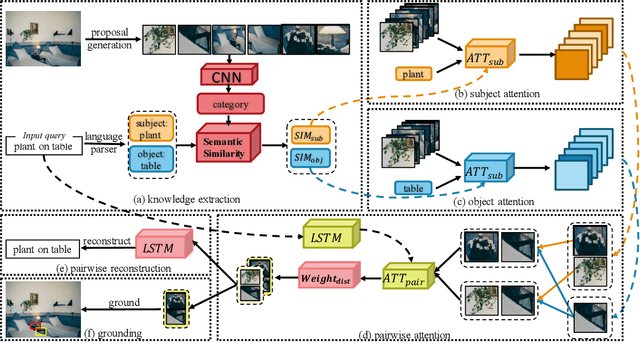
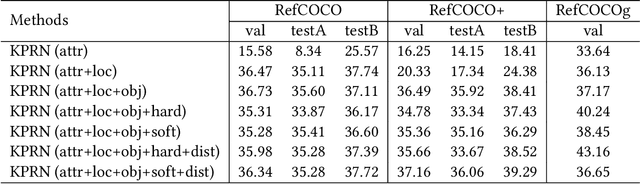
Weakly supervised referring expression grounding (REG) aims at localizing the referential entity in an image according to linguistic query, where the mapping between the image region (proposal) and the query is unknown in the training stage. In referring expressions, people usually describe a target entity in terms of its relationship with other contextual entities as well as visual attributes. However, previous weakly supervised REG methods rarely pay attention to the relationship between the entities. In this paper, we propose a knowledge-guided pairwise reconstruction network (KPRN), which models the relationship between the target entity (subject) and contextual entity (object) as well as grounds these two entities. Specifically, we first design a knowledge extraction module to guide the proposal selection of subject and object. The prior knowledge is obtained in a specific form of semantic similarities between each proposal and the subject/object. Second, guided by such knowledge, we design the subject and object attention module to construct the subject-object proposal pairs. The subject attention excludes the unrelated proposals from the candidate proposals. The object attention selects the most suitable proposal as the contextual proposal. Third, we introduce a pairwise attention and an adaptive weighting scheme to learn the correspondence between these proposal pairs and the query. Finally, a pairwise reconstruction module is used to measure the grounding for weakly supervised learning. Extensive experiments on four large-scale datasets show our method outperforms existing state-of-the-art methods by a large margin.