 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagenWorld: Stress-Testing Image Generation Models with Explainable Human Evaluation on Open-ended Real-World Tasks
Mar 29, 2026Advances in diffusion, autoregressive, and hybrid models have enabled high-quality image synthesis for tasks such as text-to-image, editing, and reference-guided composition. Yet, existing benchmarks remain limited, either focus on isolated tasks, cover only narrow domains, or provide opaque scores without explaining failure modes. We introduce \textbf{ImagenWorld}, a benchmark of 3.6K condition sets spanning six core tasks (generation and editing, with single or multiple references) and six topical domains (artworks, photorealistic images, information graphics, textual graphics, computer graphics, and screenshots). The benchmark is supported by 20K fine-grained human annotations and an explainable evaluation schema that tags localized object-level and segment-level errors, complementing automated VLM-based metrics. Our large-scale evaluation of 14 models yields several insights: (1) models typically struggle more in editing tasks than in generation tasks, especially in local edits. (2) models excel in artistic and photorealistic settings but struggle with symbolic and text-heavy domains such as screenshots and information graphics. (3) closed-source systems lead overall, while targeted data curation (e.g., Qwen-Image) narrows the gap in text-heavy cases. (4) modern VLM-based metrics achieve Kendall accuracies up to 0.79, approximating human ranking, but fall short of fine-grained, explainable error attribution. ImagenWorld provides both a rigorous benchmark and a diagnostic tool to advance robust image generation.
Gen-n-Val: Agentic Image Data Generation and Validation
Jun 05, 2025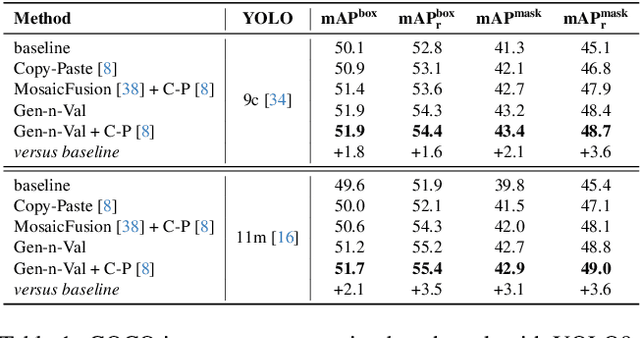



Recently, Large Language Models (LLMs) and Vision Large Language Models (VLLMs) have demonstrated impressive performance as agents across various tasks while data scarcity and label noise remain significant challenges in computer vision tasks, such as object detection and instance segmentation. A common solution for resolving these issues is to generate synthetic data. However, current synthetic data generation methods struggle with issues, such as multiple objects per mask, inaccurate segmentation, and incorrect category labels, limiting their effectiveness. To address these issues, we introduce Gen-n-Val, a novel agentic data generation framework that leverages Layer Diffusion (LD), LLMs, and VLLMs to produce high-quality, single-object masks and diverse backgrounds. Gen-n-Val consists of two agents: (1) The LD prompt agent, an LLM, optimizes prompts for LD to generate high-quality foreground instance images and segmentation masks. These optimized prompts ensure the generation of single-object synthetic data with precise instance masks and clean backgrounds. (2) The data validation agent, a VLLM, which filters out low-quality synthetic instance images. The system prompts for both agents are refined through TextGrad. Additionally, we use image harmonization to combine multiple instances within scenes. Compared to state-of-the-art synthetic data approaches like MosaicFusion, our approach reduces invalid synthetic data from 50% to 7% and improves performance by 1% mAP on rare classes in COCO instance segmentation with YOLOv9c and YOLO11m. Furthermore, Gen-n-Val shows significant improvements (7. 1% mAP) over YOLO-Worldv2-M in open-vocabulary object detection benchmarks with YOLO11m. Moreover, Gen-n-Val improves the performance of YOLOv9 and YOLO11 families in instance segmentation and object detection.
CameraBench: Benchmarking Visual Reasoning in MLLMs via Photography
Apr 14, 2025Large language models (LLMs) and multimodal large language models (MLLMs) have significantly advanced artificial intelligence. However, visual reasoning, reasoning involving both visual and textual inputs, remains underexplored. Recent advancements, including the reasoning models like OpenAI o1 and Gemini 2.0 Flash Thinking, which incorporate image inputs, have opened this capability. In this ongoing work, we focus specifically on photography-related tasks because a photo is a visual snapshot of the physical world where the underlying physics (i.e., illumination, blur extent, etc.) interplay with the camera parameters. Successfully reasoning from the visual information of a photo to identify these numerical camera settings requires the MLLMs to have a deeper understanding of the underlying physics for precise visual comprehension, representing a challenging and intelligent capability essential for practical applications like photography assistant agents. We aim to evaluate MLLMs on their ability to distinguish visual differences related to numerical camera settings, extending a methodology previously proposed for vision-language models (VLMs). Our preliminary results demonstrate the importance of visual reasoning in photography-related tasks. Moreover, these results show that no single MLLM consistently dominates across all evaluation tasks, demonstrating ongoing challenges and opportunities in developing MLLMs with better visual reasoning.
Self-Contained Stylization via Steganography for Reverse and Serial Style Transfer
Dec 10, 2018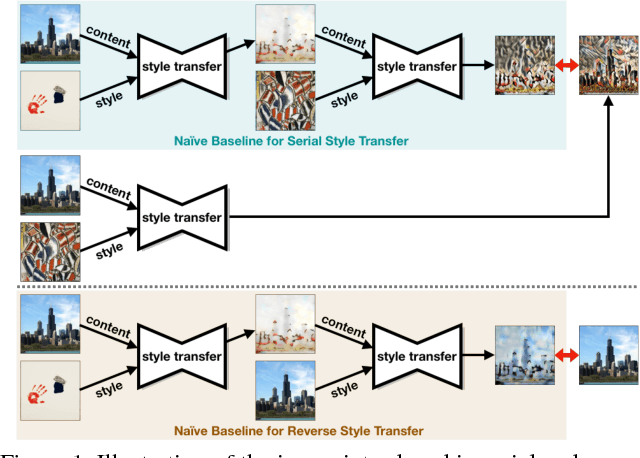

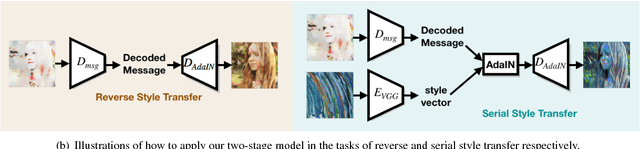
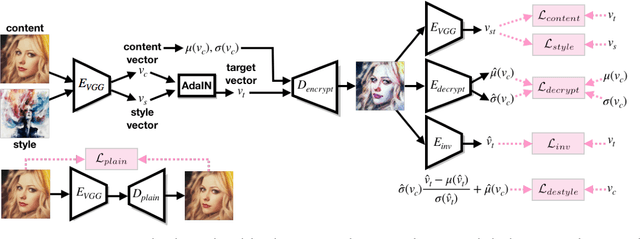
Style transfer has been widely applied to give real-world images a new artistic look. However, given a stylized image, the attempts to use typical style transfer methods for de-stylization or transferring it again into another style usually lead to artifacts or undesired results. We realize that these issues are originated from the content inconsistency between the original image and its stylized output. Therefore in this paper we advance to keep the content information of the input image during process of style transfer by the power of steganography, with two approaches proposed: a two-stage model and an end-to-end model. We conduct extensive experiments to successfully verify the capacity of our models, in which both of them are able to not only generate stylized images of quality comparable with the ones produced by state-of-the-art style transfer methods, but also effectively eliminate the artifacts introduced in reconstructing original input from a stylized image as well as performing multiple times of style transfer in series.