 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self Attention Grid for Person Re-Identification
Sep 23, 2018

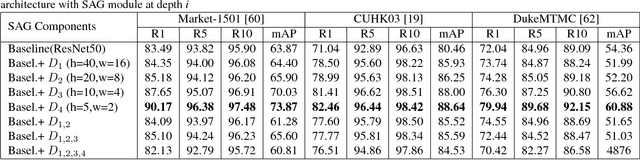
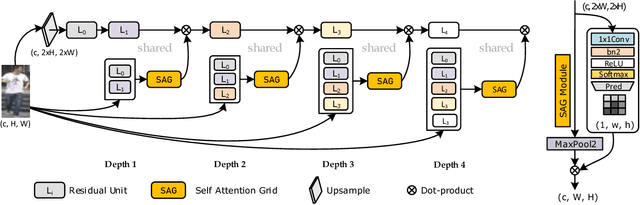
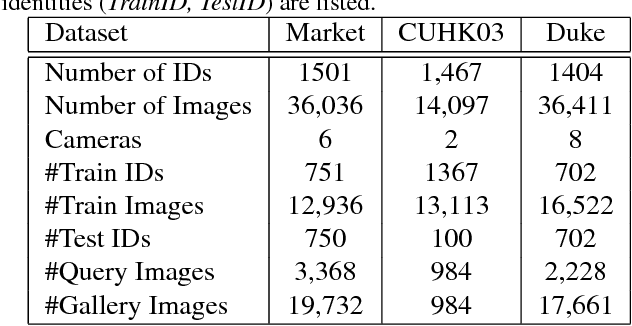
In this paper, we present an attention mechanism scheme to improve person re-identification task. Inspired by biology, we propose Self Attention Grid (SAG) to discover the most informative parts from a high-resolution image using its internal representation. In particular, given an input image, the proposed model is fed with two copies of the same image and consists of two branches. The upper branch processes the high-resolution image and learns high dimensional feature representation while the lower branch processes the low-resolution image and learn a filtering attention grid. We apply a max filter operation to non-overlapping sub-regions on the high feature representation before element-wise multiplied with the output of the second branch. The feature maps of the second branch are subsequently weighted to reflect the importance of each patch of the grid using a softmax operation. Our attention module helps the network learn the most discriminative visual features of multiple image regions and is specifically optimized to attend feature representation at different levels. Extensive experiments on three large-scale datasets show that our self-attention mechanism significantly improves the baseline model and outperforms various state-of-art models by a large margin.
Deep Snake for Real-Time Instance Segmentation
Jan 06, 2020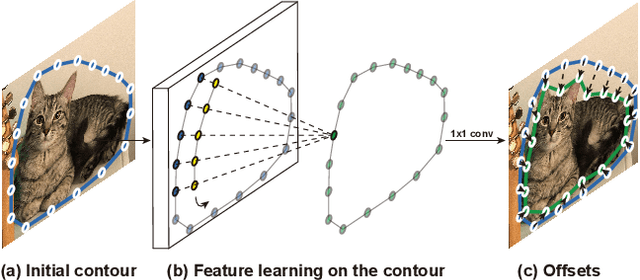

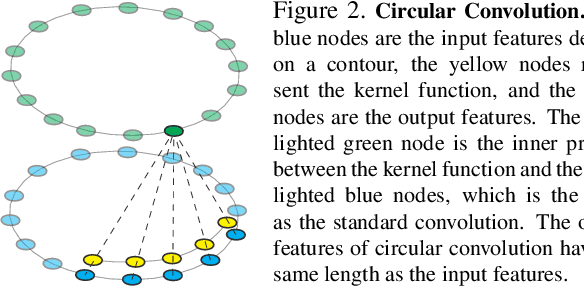

This paper introduces a novel contour-based approach named deep snake for real-time instance segmentation. Unlike some recent methods that directly regress the coordinates of the object boundary points from an image, deep snake uses a neural network to iteratively deform an initial contour to the object boundary, which implements the classic idea of snake algorithms with a learning-based approach. For structured feature learning on the contour, we propose to use circular convolution in deep snake, which better exploits the cycle-graph structure of a contour compared against generic graph convolution. Based on deep snake, we develop a two-stage pipeline for instance segmentation: initial contour proposal and contour deformation, which can handle errors in initial object localization. Experiments show that the proposed approach achieves state-of-the-art performances on the Cityscapes, Kins and Sbd datasets while being efficient for real-time instance segmentation, 32.3 fps for 512$\times$512 images on a 1080Ti GPU. The code will be available at https://github.com/zju3dv/snake/.
On measuring the iconicity of a face
Mar 04, 2019

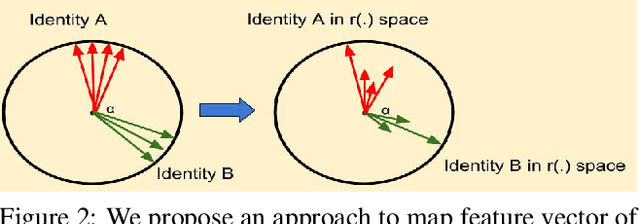
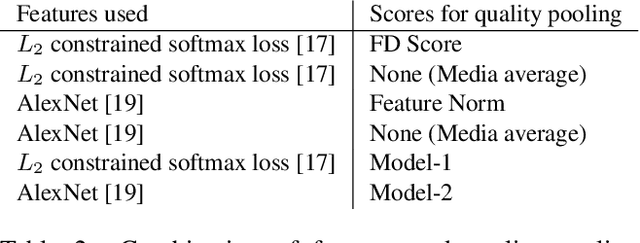
For a given identity in a face dataset, there are certain iconic images which are more representative of the subject than others. In this paper, we explore the problem of computing the iconicity of a face. The premise of the proposed approach is as follows: For an identity containing a mixture of iconic and non iconic images, if a given face cannot be successfully matched with any other face of the same identity, then the iconicity of the face image is low. Using this information, we train a Siamese Multi-Layer Perceptron network, such that each of its twins predict iconicity scores of the image feature pair, fed in as input. We observe the variation of the obtained scores with respect to covariates such as blur, yaw, pitch, roll and occlusion to demonstrate that they effectively predict the quality of the image and compare it with other existing metrics. Furthermore, we use these scores to weight features for template-based face verification and compare it with media averaging of features.
Adaptive Loss-aware Quantization for Multi-bit Networks
Dec 18, 2019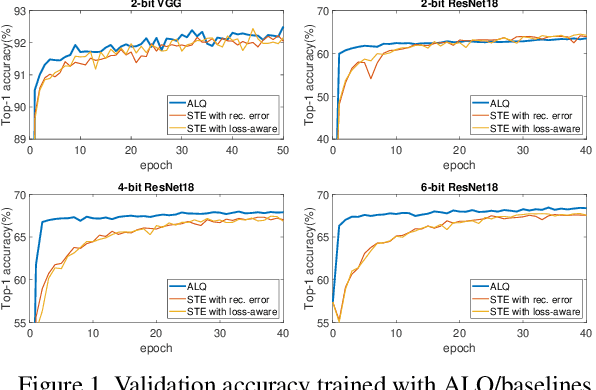
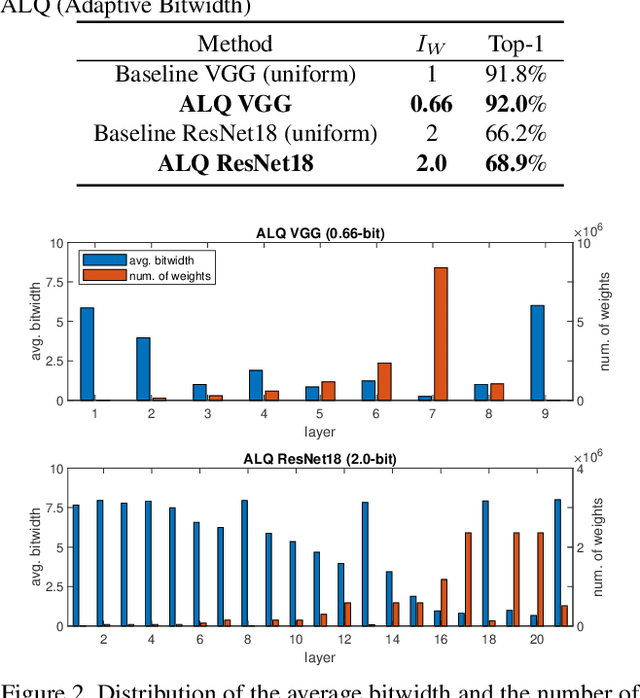
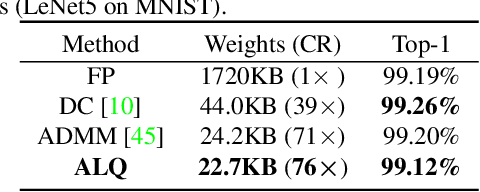
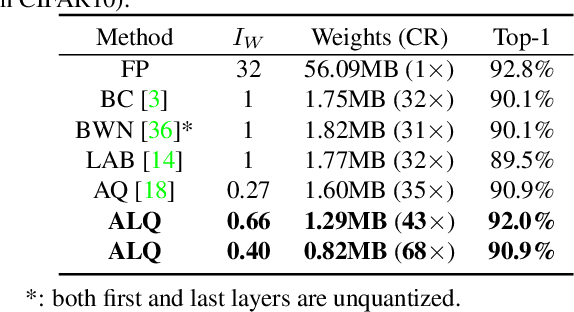
We investigate the compression of deep neural networks by quantizing their weights and activations into multiple binary bases, known as multi-bit networks (MBNs), which accelerates the inference and reduces the storage for deployment on low-resource mobile and embedded platforms. We propose Adaptive Loss-aware Quantization (ALQ), a new MBN quantization pipeline that is able to achieve an average bitwidth below one bit without notable loss in inference accuracy. Unlike previous MBN quantization solutions that train a quantizer by minimizing the error to reconstruct full precision weights, ALQ directly minimizes the quantization-induced error on the loss function involving neither gradient approximation nor full precision calculations. ALQ also exploits strategies including adaptive bitwidth, smooth bitwidth reduction, and iterative trained quantization to allow a smaller network size without loss in accuracy. Experiment results on popular image datasets show that ALQ outperforms state-of-the-art compressed networks in terms of both storage and accuracy.
Continuous Meta-Learning without Tasks
Dec 18, 2019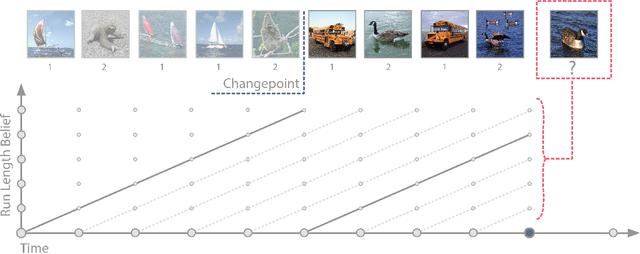
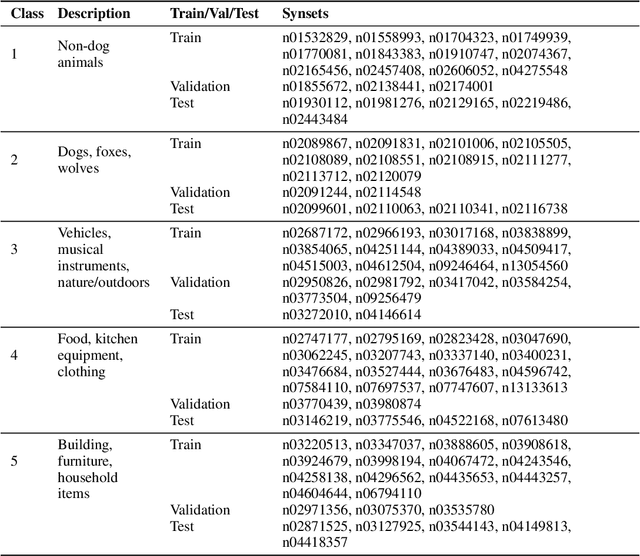
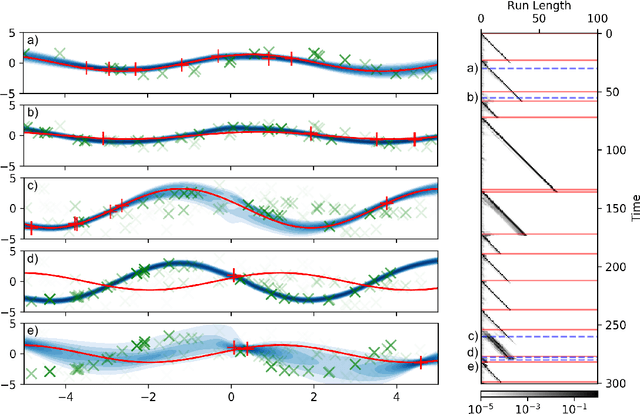

Meta-learning is a promising strategy for learning to efficiently learn within new tasks, using data gathered from a distribution of tasks. However, the meta-learning literature thus far has focused on the task segmented setting, where at train-time, offline data is assumed to be split according to the underlying task, and at test-time, the algorithms are optimized to learn in a single task. In this work, we enable the application of generic meta-learning algorithms to settings where this task segmentation is unavailable, such as continual online learning with a time-varying task. We present meta-learning via online changepoint analysis (MOCA), an approach which augments a meta-learning algorithm with a differentiable Bayesian changepoint detection scheme. The framework allows both training and testing directly on time series data without segmenting it into discrete tasks. We demonstrate the utility of this approach on a nonlinear meta-regression benchmark as well as two meta-image-classification benchmarks.
Motion Corrected Multishot MRI Reconstruction Using Generative Networks with Sensitivity Encoding
Mar 24, 2019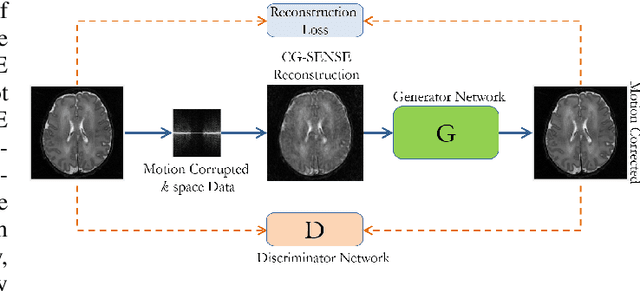
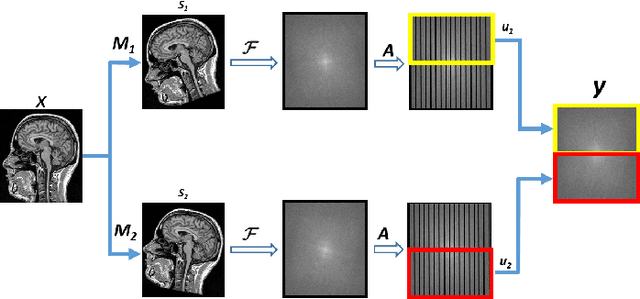

Multishot Magnetic Resonance Imaging (MRI) is a promising imaging modality that can produce a high-resolution image with relatively less data acquisition time. The downside of multishot MRI is that it is very sensitive to subject motion and even small amounts of motion during the scan can produce artifacts in the final MR image that may cause misdiagnosis. Numerous efforts have been made to address this issue; however, all of these proposals are limited in terms of how much motion they can correct and the required computational time. In this paper, we propose a novel generative networks based conjugate gradient SENSE (CG-SENSE) reconstruction framework for motion correction in multishot MRI. The proposed framework first employs CG-SENSE reconstruction to produce the motion-corrupted image and then a generative adversarial network (GAN) is used to correct the motion artifacts. The proposed method has been rigorously evaluated on synthetically corrupted data on varying degrees of motion, numbers of shots, and encoding trajectories. Our analyses (both quantitative as well as qualitative/visual analysis) establishes that the proposed method significantly robust and outperforms state-of-the-art motion correction techniques and also reduces severalfold of computational times.
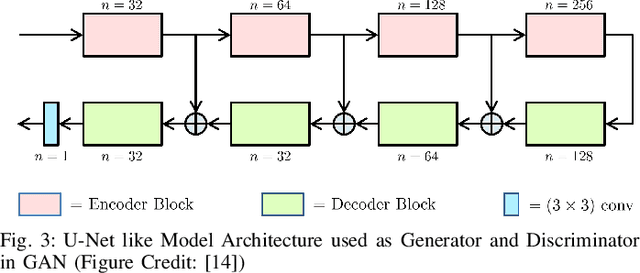
BinGAN: Learning Compact Binary Descriptors with a Regularized GAN
Nov 06, 2018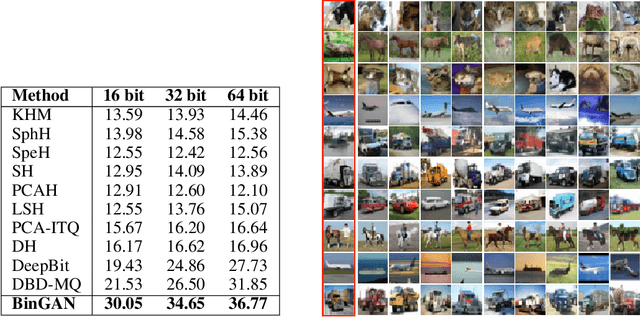
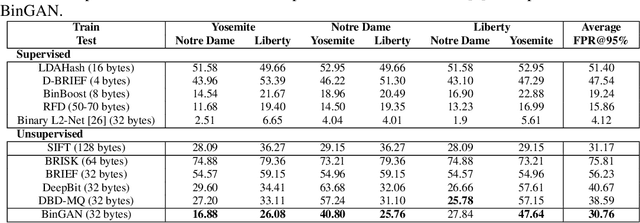


In this paper, we propose a novel regularization method for Generative Adversarial Networks, which allows the model to learn discriminative yet compact binary representations of image patches (image descriptors). We employ the dimensionality reduction that takes place in the intermediate layers of the discriminator network and train binarized low-dimensional representation of the penultimate layer to mimic the distribution of the higher-dimensional preceding layers. To achieve this, we introduce two loss terms that aim at: (i) reducing the correlation between the dimensions of the binarized low-dimensional representation of the penultimate layer i. e. maximizing joint entropy) and (ii) propagating the relations between the dimensions in the high-dimensional space to the low-dimensional space. We evaluate the resulting binary image descriptors on two challenging applications, image matching and retrieval, and achieve state-of-the-art results.
Fast and robust detection of solar modules in electroluminescence images
Jul 19, 2019



Fast, non-destructive and on-site quality control tools, mainly high sensitive imaging techniques, are important to assess the reliability of photovoltaic plants. To minimize the risk of further damages and electrical yield losses, electroluminescence (EL) imaging is used to detect local defects in an early stage, which might cause future electric losses. For an automated defect recognition on EL measurements, a robust detection and rectification of modules, as well as an optional segmentation into cells is required. This paper introduces a method to detect solar modules and crossing points between solar cells in EL images. We only require 1-D image statistics for the detection, resulting in an approach that is computationally efficient. In addition, the method is able to detect the modules under perspective distortion and in scenarios, where multiple modules are visible in the image. We compare our method to the state of the art and show that it is superior in presence of perspective distortion while the performance on images, where the module is roughly coplanar to the detector, is similar to the reference method. Finally, we show that we greatly improve in terms of computational time in comparison to the reference method.
Capsule GAN Using Capsule Network for Generator Architecture
Mar 18, 2020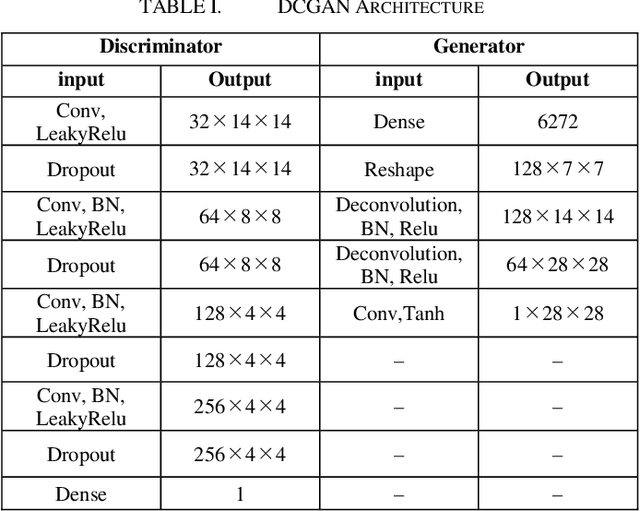
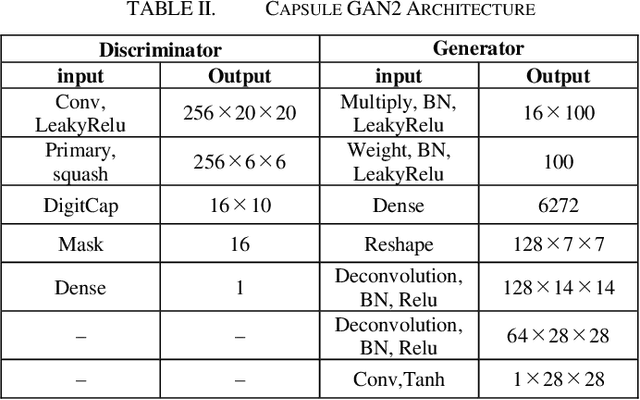
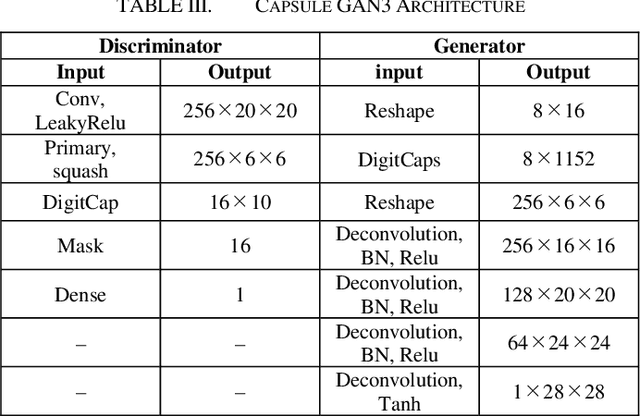

This paper presents Capsule GAN, a Generative adversarial network using Capsule Network not only in the discriminator but also in the generator. Recently, Generative adversarial networks (GANs) has been intensively studied. However, generating images by GANs is difficult. Therefore, GANs sometimes generate poor quality images. These GANs use convolutional neural networks (CNNs). However, CNNs have the defect that the relational information between features of the image may be lost. Capsule Network, proposed by Hinton in 2017, overcomes the defect of CNNs. Capsule GAN reported previously uses Capsule Network in the discriminator. However, instead of using Capsule Network, Capsule GAN reported in previous studies uses CNNs in generator architecture like DCGAN. This paper introduces two approaches to use Capsule Network in the generator. One is to use DigitCaps layer from the discriminator as the input to the generator. DigitCaps layer is the output layer of Capsule Network. It has the features of the input images of the discriminator. The other is to use the reverse operation of recognition process in Capsule Network in the generator. We compare Capsule GAN proposed in this paper with conventional GAN using CNN and Capsule GAN which uses Capsule Network in the discriminator only. The datasets are MNIST, Fashion-MNIST and color images. We show that Capsule GAN outperforms the GAN using CNN and the GAN using Capsule Network in the discriminator only. The architecture of Capsule GAN proposed in this paper is a basic architecture using Capsule Network. Therefore, we can apply the existing improvement techniques for GANs to Capsule GAN.
Joint Learning of Neural Networks via Iterative Reweighted Least Squares
May 16, 2019
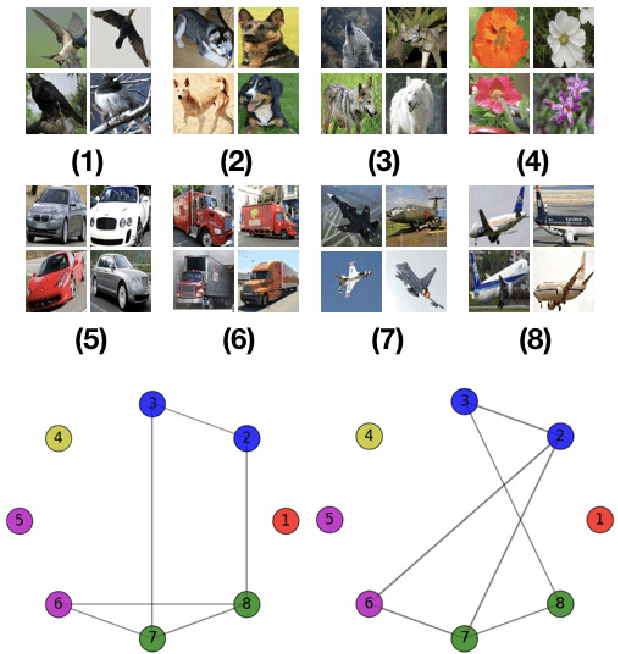
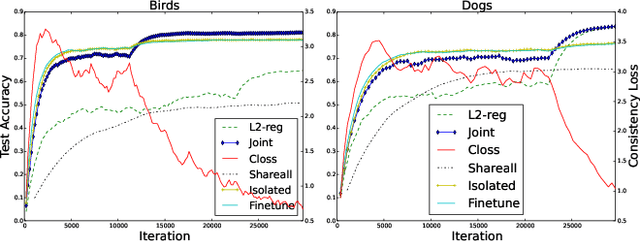
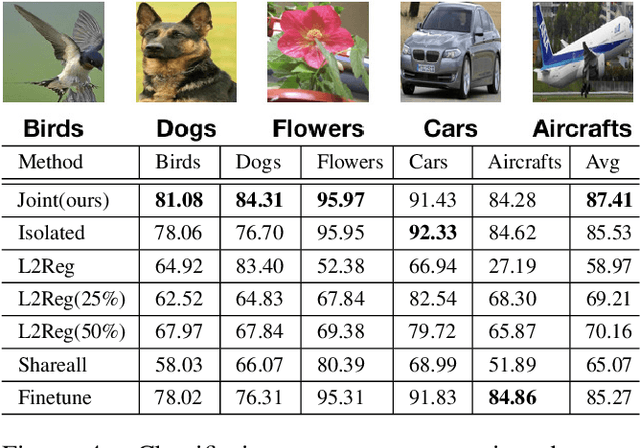
In this paper, we introduce the problem of jointly learning feed-forward neural networks across a set of relevant but diverse datasets. Compared to learning a separate network from each dataset in isolation, joint learning enables us to extract correlated information across multiple datasets to significantly improve the quality of learned networks. We formulate this problem as joint learning of multiple copies of the same network architecture and enforce the network weights to be shared across these networks. Instead of hand-encoding the shared network layers, we solve an optimization problem to automatically determine how layers should be shared between each pair of datasets. Experimental results show that our approach outperforms baselines without joint learning and those using pretraining-and-fine-tuning. We show the effectiveness of our approach on three tasks: image classification, learning auto-encoders, and image generation.