 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint Face Hallucination and Deblurring via Structure Generation and Detail Enhancement
Nov 22, 2018

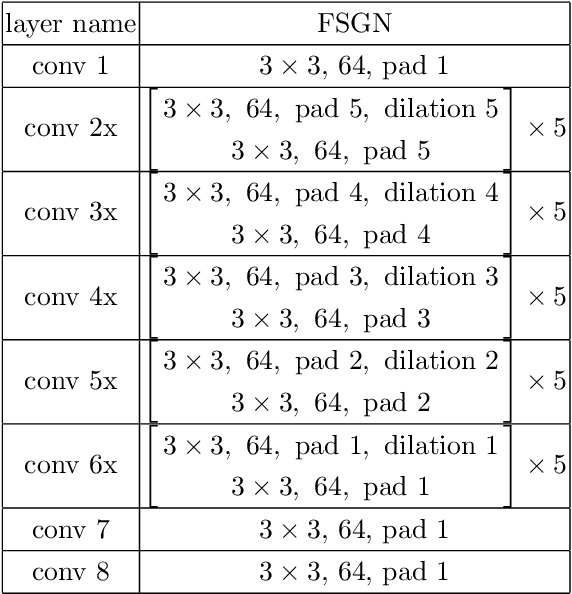
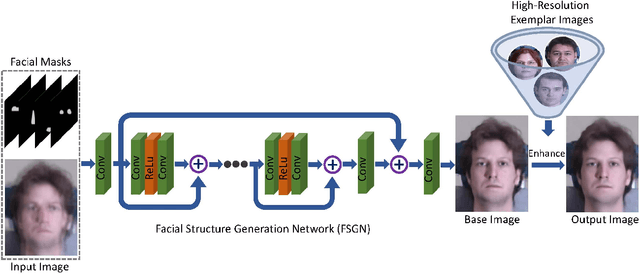
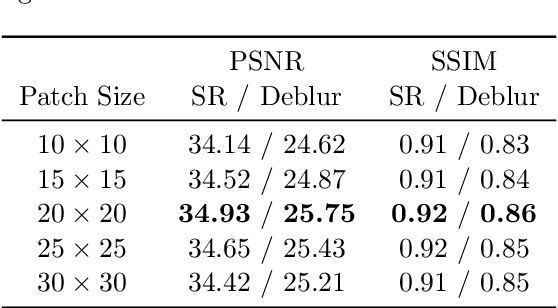
We address the problem of restoring a high-resolution face image from a blurry low-resolution input. This problem is difficult as super-resolution and deblurring need to be tackled simultaneously. Moreover, existing algorithms cannot handle face images well as low-resolution face images do not have much texture which is especially critical for deblurring. In this paper, we propose an effective algorithm by utilizing the domain-specific knowledge of human faces to recover high-quality faces. We first propose a facial component guided deep Convolutional Neural Network (CNN) to restore a coarse face image, which is denoted as the base image where the facial component is automatically generated from the input face image. However, the CNN based method cannot handle image details well. We further develop a novel exemplar-based detail enhancement algorithm via facial component matching. Extensive experiments show that the proposed method outperforms the state-of-the-art algorithms both quantitatively and qualitatively.
High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification
Mar 23, 2020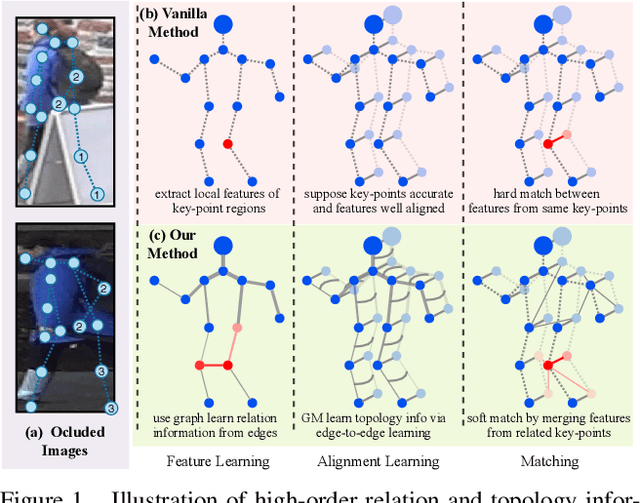
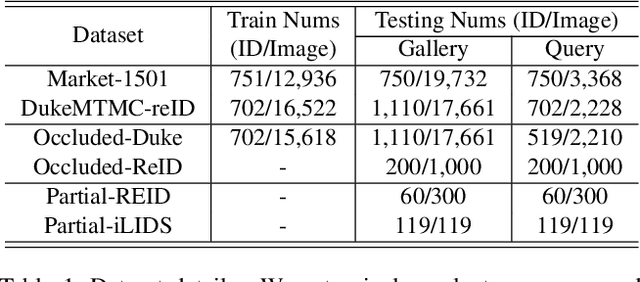
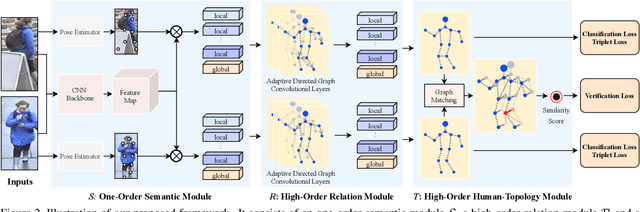
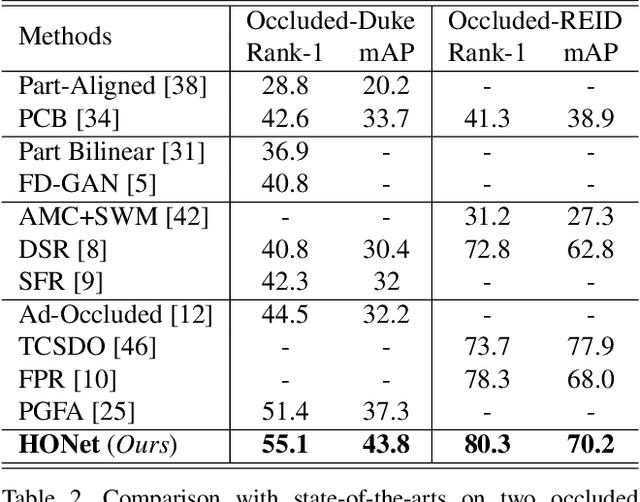
Occluded person re-identification (ReID) aims to match occluded person images to holistic ones across dis-joint cameras. In this paper, we propose a novel framework by learning high-order relation and topology information for discriminative features and robust alignment. At first, we use a CNN backbone and a key-points estimation model to extract semantic local features. Even so, occluded images still suffer from occlusion and outliers. Then, we view the local features of an image as nodes of a graph and propose an adaptive direction graph convolutional (ADGC)layer to pass relation information between nodes. The proposed ADGC layer can automatically suppress the message-passing of meaningless features by dynamically learning di-rection and degree of linkage. When aligning two groups of local features from two images, we view it as a graph matching problem and propose a cross-graph embedded-alignment (CGEA) layer to jointly learn and embed topology information to local features, and straightly predict similarity score. The proposed CGEA layer not only take full use of alignment learned by graph matching but also re-place sensitive one-to-one matching with a robust soft one. Finally, extensive experiments on occluded, partial, and holistic ReID tasks show the effectiveness of our proposed method. Specifically, our framework significantly outperforms state-of-the-art by6.5%mAP scores on Occluded-Duke dataset.
Adversarial Examples for Edge Detection: They Exist, and They Transfer
Jun 02, 2019

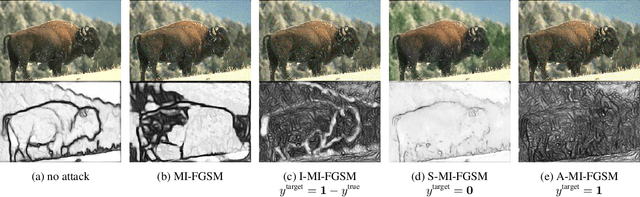
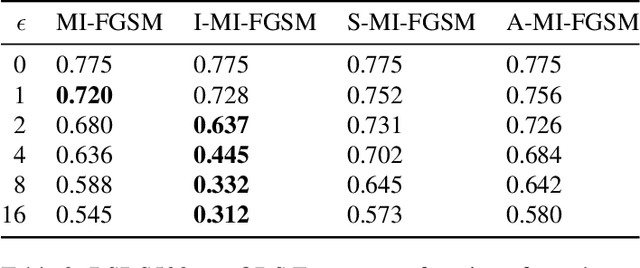
Convolutional neural networks have recently advanced the state of the art in many tasks including edge and object boundary detection. However, in this paper, we demonstrate that these edge detectors inherit a troubling property of neural networks: they can be fooled by adversarial examples. We show that adding small perturbations to an image causes HED, a CNN-based edge detection model, to fail to locate edges, to detect nonexistent edges, and even to hallucinate arbitrary configurations of edges. More surprisingly, we find that these adversarial examples transfer to other CNN-based vision models. In particular, attacks on edge detection result in significant drops in accuracy in models trained to perform unrelated, high-level tasks like image classification and semantic segmentation. Our code will be made public.
Kidney and Kidney Tumor Segmentation using a Logical Ensemble of U-nets with Volumetric Validation
Aug 07, 2019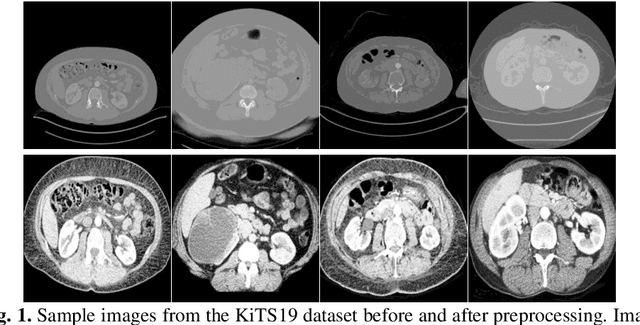
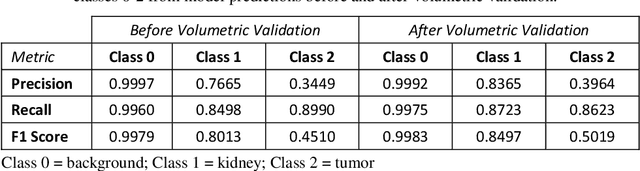
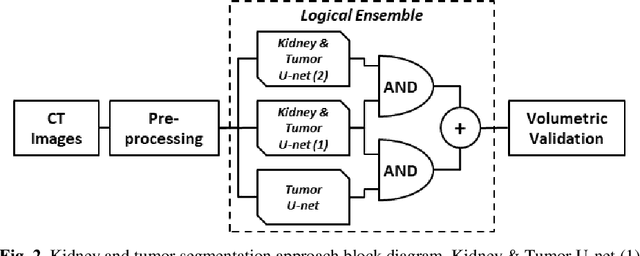
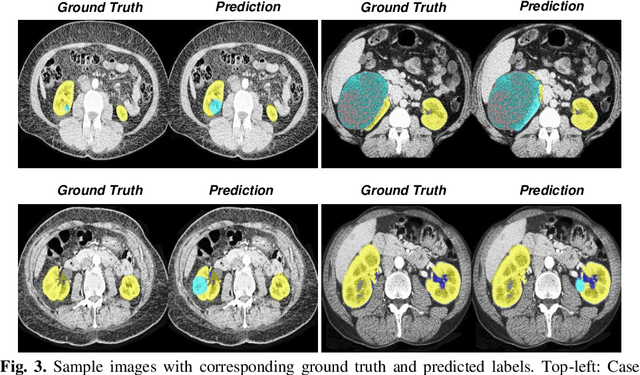
Automated medical image segmentation is a priority research area for computational methods. In particular, detection of cancerous tumors represents a current challenge in this area with potential for real-world impact. This paper describes a method developed in response to the 2019 Kidney Tumor Segmentation Challenge (KiTS19). Axial computed tomography (CT) scans from 210 kidney cancer patients were used to develop and evaluate this automatic segmentation method based on a logical ensemble of fully-convolutional network (FCN) architectures, followed by volumetric validation. Data was pre-processed using conventional computer vision techniques, thresholding, histogram equalization, morphological operations, centering, zooming and resizing. Three binary FCN segmentation models were trained to classify kidney and tumor (2), and only tumor (1), respectively. Model output images were stacked and volumetrically validated to produce the final segmentation for each patient scan. The average F1 score from kidney and tumor pixel classifications was calculated as 0.6758 using preprocessed images and annotations; although restoring to the original image format reduced this score. It remains to be seen how this compares to other solutions.
Learned Spectral Computed Tomography
Mar 09, 2020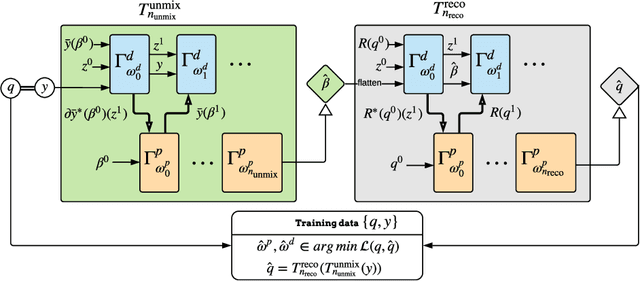
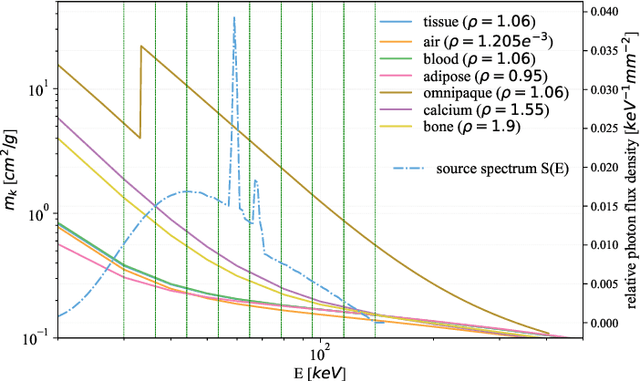

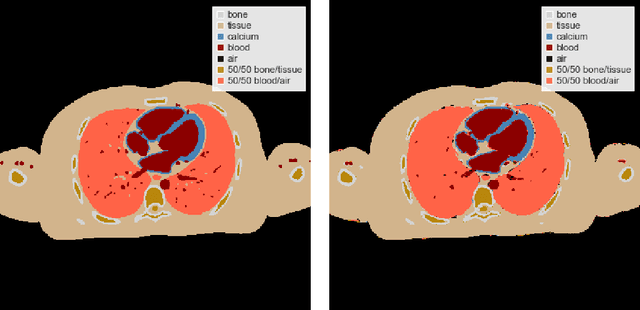
Spectral Photon-Counting Computed Tomography (SPCCT) is a promising technology that has shown a number of advantages over conventional X-ray Computed Tomography (CT) in the form of material separation, artefact removal and enhanced image quality. However, due to the increased complexity and non-linearity of the SPCCT governing equations, model-based reconstruction algorithms typically require handcrafted regularisation terms and meticulous tuning of hyperparameters making them impractical to calibrate in variable conditions. Additionally, they typically incur high computational costs and in cases of limited-angle data, their imaging capability deteriorates significantly. Recently, Deep Learning has proven to provide state-of-the-art reconstruction performance in medical imaging applications while circumventing most of these challenges. Inspired by these advances, we propose a Deep Learning imaging method for SPCCT that exploits the expressive power of Neural Networks while also incorporating model knowledge. The method takes the form of a two-step learned primal-dual algorithm that is trained using case-specific data. The proposed approach is characterised by fast reconstruction capability and high imaging performance, even in limited-data cases, while avoiding the hand-tuning that is required by other optimisation approaches. We demonstrate the performance of the method in terms of reconstructed images and quality metrics via numerical examples inspired by the application of cardiovascular imaging.
On the Texture Bias for Few-Shot CNN Segmentation
Mar 09, 2020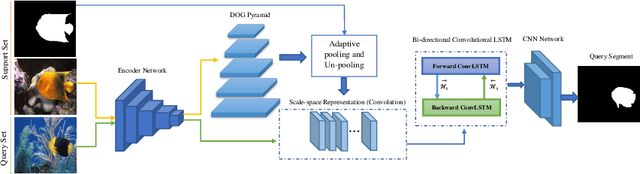


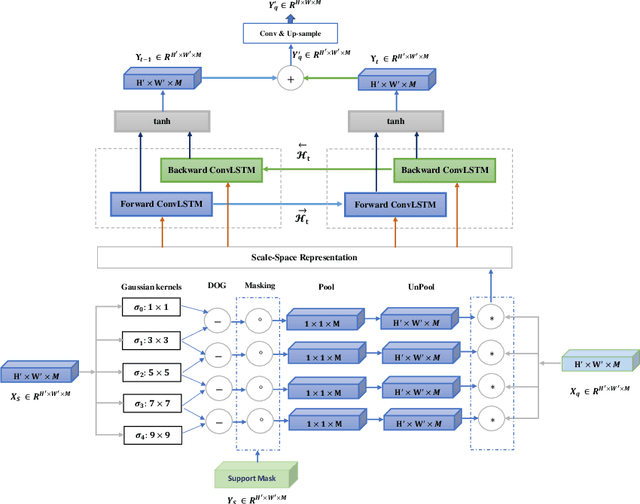
Despite the initial belief that Convolutional Neural Networks (CNNs) are driven by shapes to perform visual recognition tasks, recent evidence suggests that texture bias in CNNs provides higher performing and more robust models. This contrasts with the perceptual bias in the human visual cortex, which has a stronger preference towards shape components. Perceptual differences may explain why CNNs achieve human-level performance when large labeled datasets are available, but their performance significantly degrades in low-labeled data scenarios, such as few-shot semantic segmentation. To remove the texture bias in the context of few-shot learning, we propose a novel architecture that integrates a set of difference of Gaussians (DoG) to attenuate high-frequency local components in the feature space. This produces a set of modified feature maps, whose high-frequency components are diminished at different standard deviation values of the Gaussian distribution in the spatial domain. As this results in multiple feature maps for a single image, we employ a bi-directional convolutional long-short-term-memory to efficiently merge the multi scale-space representations. We perform extensive experiments on two well-known few-shot segmentation benchmarks -Pascal i5 and FSS-1000- and demonstrate that our method outperforms significantly state-of-the-art approaches. The code is available at: https://github.com/rezazad68/fewshot-segmentation
Equivariant neural networks and equivarification
Jun 16, 2019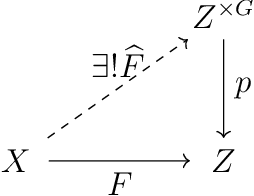
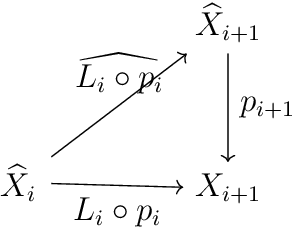
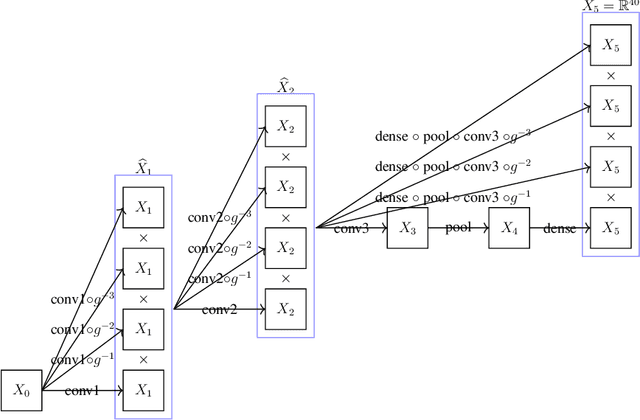

We provide a process to modify a neural network to an equivariant one, which we call {\em equivarification}. As an illustration, we build an equivariant neural network for image classification by equivarifying a convolutional neural network.
A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications
Jan 20, 2020
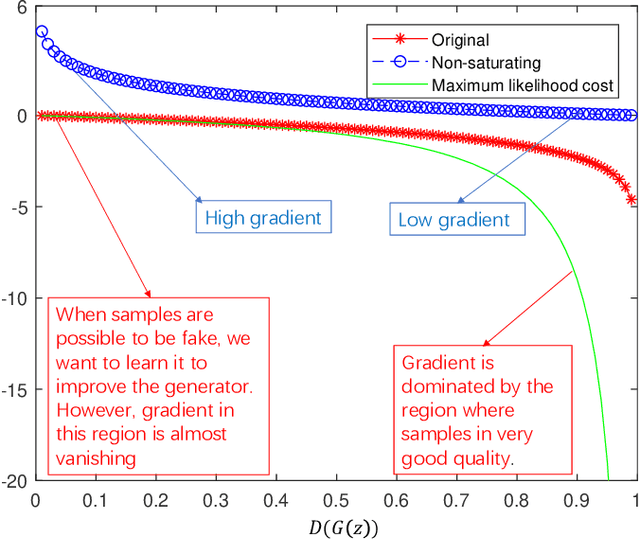

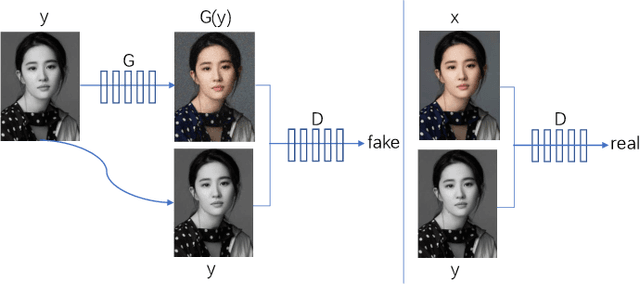
Generative adversarial networks (GANs) are a hot research topic recently. GANs have been widely studied since 2014, and a large number of algorithms have been proposed. However, there is few comprehensive study explaining the connections among different GANs variants, and how they have evolved. In this paper, we attempt to provide a review on various GANs methods from the perspectives of algorithms, theory, and applications. Firstly, the motivations, mathematical representations, and structure of most GANs algorithms are introduced in details. Furthermore, GANs have been combined with other machine learning algorithms for specific applications, such as semi-supervised learning, transfer learning, and reinforcement learning. This paper compares the commonalities and differences of these GANs methods. Secondly, theoretical issues related to GANs are investigated. Thirdly, typical applications of GANs in image processing and computer vision, natural language processing, music, speech and audio, medical field, and data science are illustrated. Finally, the future open research problems for GANs are pointed out.
IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis
Oct 27, 2018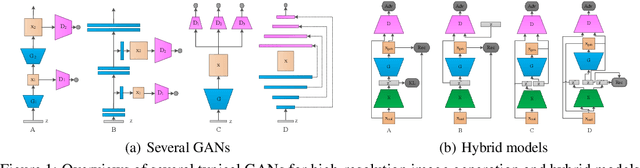
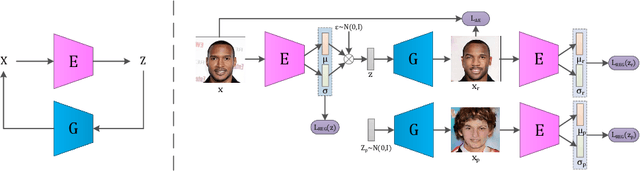
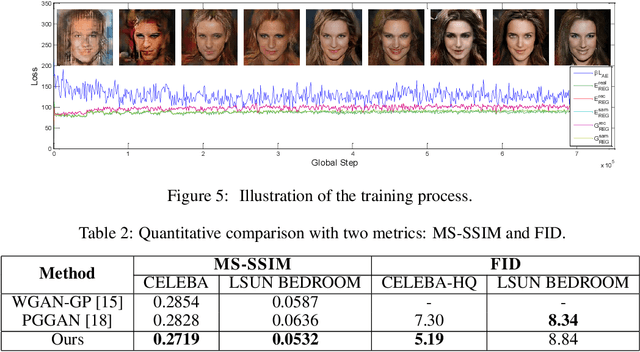

We present a novel introspective variational autoencoder (IntroVAE) model for synthesizing high-resolution photographic images. IntroVAE is capable of self-evaluating the quality of its generated samples and improving itself accordingly. Its inference and generator models are jointly trained in an introspective way. On one hand, the generator is required to reconstruct the input images from the noisy outputs of the inference model as normal VAEs. On the other hand, the inference model is encouraged to classify between the generated and real samples while the generator tries to fool it as GANs. These two famous generative frameworks are integrated in a simple yet efficient single-stream architecture that can be trained in a single stage. IntroVAE preserves the advantages of VAEs, such as stable training and nice latent manifold. Unlike most other hybrid models of VAEs and GANs, IntroVAE requires no extra discriminators, because the inference model itself serves as a discriminator to distinguish between the generated and real samples. Experiments demonstrate that our method produces high-resolution photo-realistic images (e.g., CELEBA images at \(1024^{2}\)), which are comparable to or better than the state-of-the-art GANs.
Multi-person Spatial Interaction in a Large Immersive Display Using Smartphones as Touchpads
Nov 26, 2019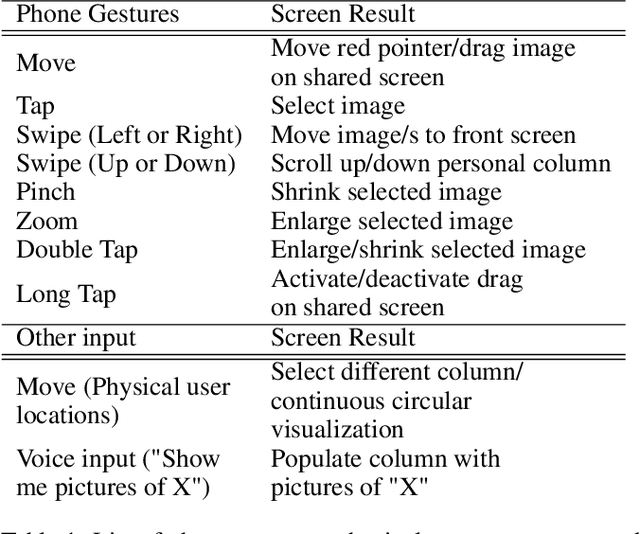
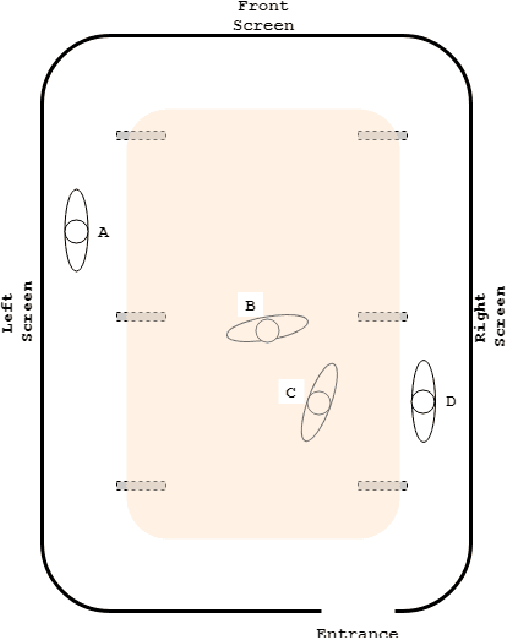
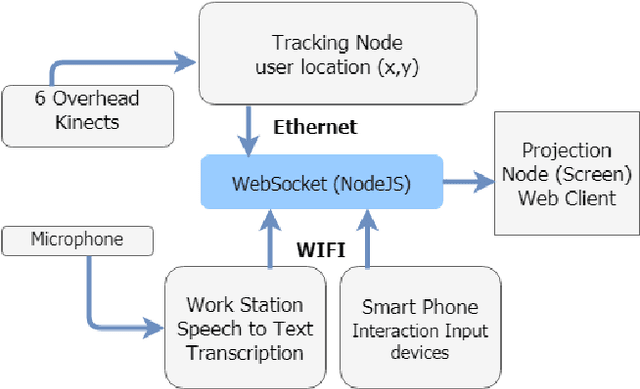

In this paper, we present a multi-user interaction interface for a large immersive space that supports simultaneous screen interactions by combining (1) user input via personal smartphones and Bluetooth microphones, (2) spatial tracking via an overhead array of Kinect sensors, and (3) WebSocket interfaces to a webpage running on the large screen. Users are automatically, dynamically assigned personal and shared screen sub-spaces based on their tracked location with respect to the screen, and use a webpage on their personal smartphone for touchpad-type input. We report user experiments using our interaction framework that involve image selection and placement tasks, with the ultimate goal of realizing display-wall environments as viable, interactive workspaces with natural multimodal interfaces.