 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Deep Learning on Medical Images: A Review
Apr 01, 2020
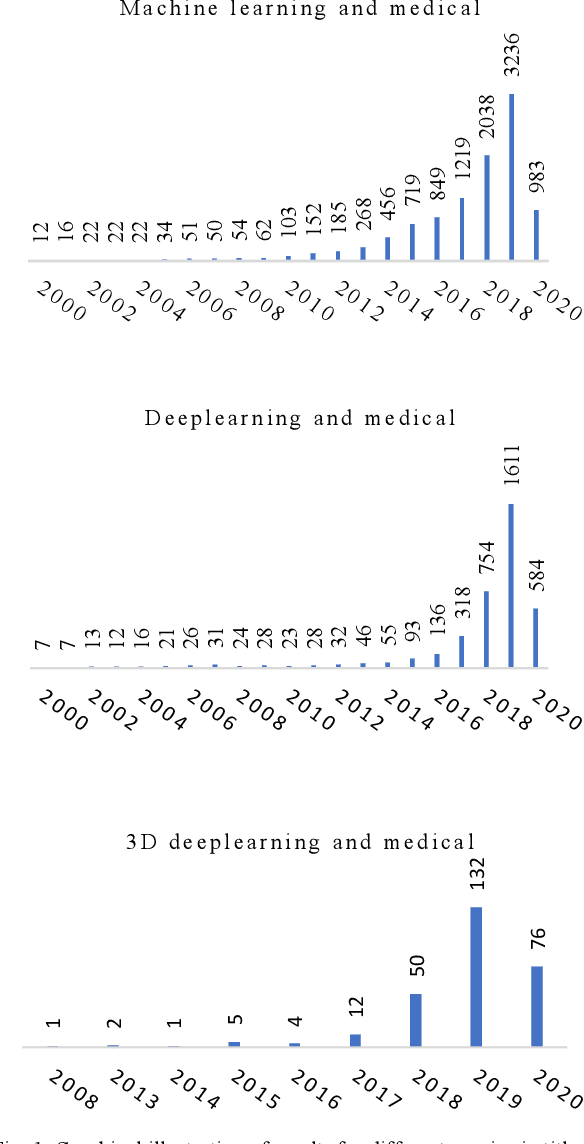
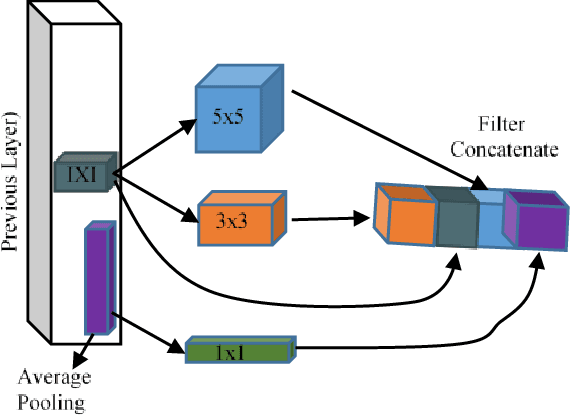
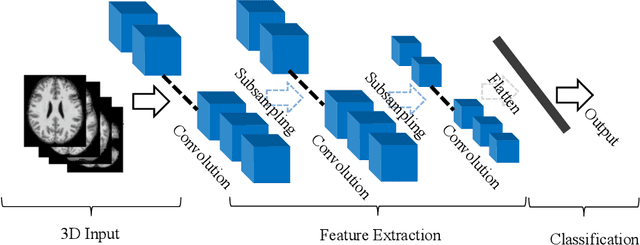
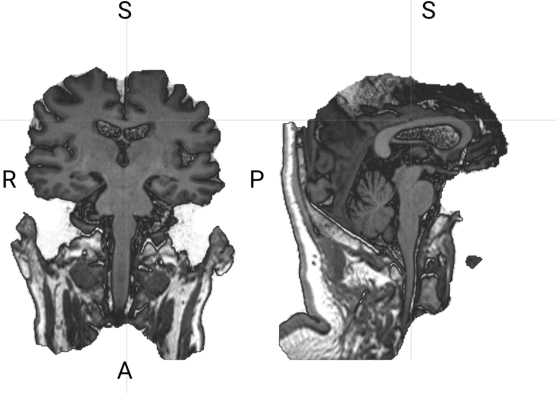
The rapid advancements in machine learning, graphics processing technologies and availability of medical imaging data has led to a rapid increase in use of machine learning models in the medical domain. This was exacerbated by the rapid advancements in convolutional neural network (CNN) based architectures, which were adopted by the medical imaging community to assist clinicians in disease diagnosis. Since the grand success of AlexNet in 2012, CNNs have been increasingly used in medical image analysis to improve the efficiency of human clinicians. In recent years, three-dimensional (3D) CNNs have been employed for analysis of medical images. In this paper, we trace the history of how the 3D CNN was developed from its machine learning roots, brief mathematical description of 3D CNN and the preprocessing steps required for medical images before feeding them to 3D CNNs. We review the significant research in the field of 3D medical imaging analysis using 3D CNNs (and its variants) in different medical areas such as classification, segmentation, detection, and localization. We conclude by discussing the challenges associated with the use of 3D CNNs in the medical imaging domain (and the use of deep learning models, in general) and possible future trends in the field.
Improved low-count quantitative PET reconstruction with a variational neural network
Jun 05, 2019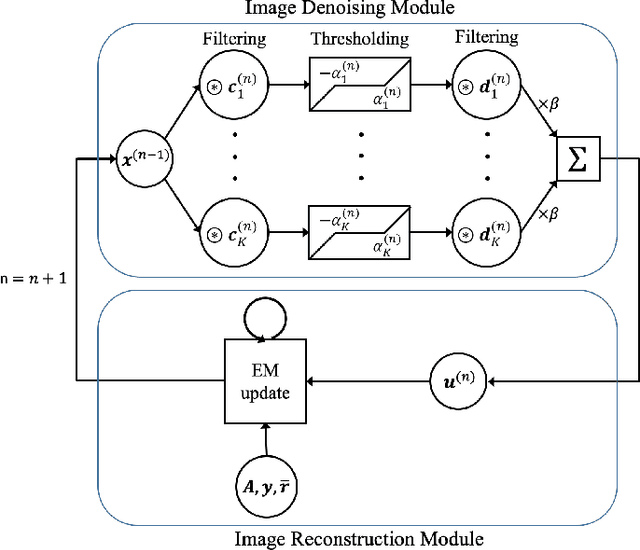
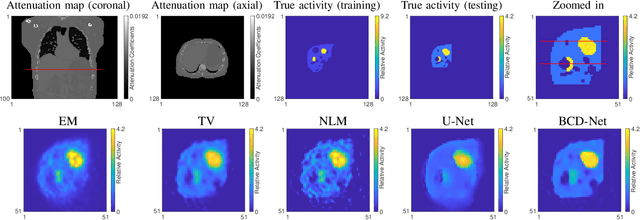
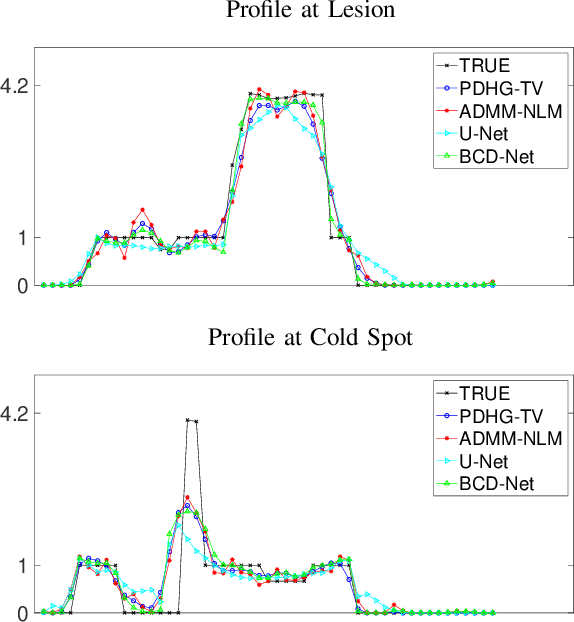

Image reconstruction in low-count PET is particularly challenging because gammas from natural radioactivity in Lu-based crystals cause high random fractions that lower the measurement signal-to-noise-ratio (SNR). In model-based image reconstruction (MBIR), using more iterations of an unregularized method may increase the noise, so incorporating regularization into the image reconstruction is desirable to control the noise. New regularization methods based on learned convolutional operators are emerging in MBIR. We modify the architecture of a variational neural network, BCD-Net, for PET MBIR, and demonstrate the efficacy of the trained BCD-Net using XCAT phantom data that simulates the low true coincidence count-rates with high random fractions typical for Y-90 PET patient imaging after Y-90 microsphere radioembolization. Numerical results show that the proposed BCD-Net significantly improves PET reconstruction performance compared to MBIR methods using non-trained regularizers, total variation (TV) and non-local means (NLM), and a non-MBIR method using a single forward pass deep neural network, U-Net. BCD-Net improved activity recovery for a hot sphere significantly and reduced noise, whereas non-trained regularizers had a trade-off between noise and quantification. BCD-Net improved CNR and RMSE by 43.4% (85.7%) and 12.9% (29.1%) compared to TV (NLM) regularized MBIR. Moreover, whereas the image reconstruction results show that the non-MBIR U-Net over-fits the training data, BCD-Net successfully generalizes to data that differs from training data. Improvements were also demonstrated for the clinically relevant phantom measurement data where we used training and testing datasets having very different activity distribution and count-level.
Multimodal Intelligence: Representation Learning, Information Fusion, and Applications
Nov 10, 2019Deep learning has revolutionized speech recognition, image recognition, and natural language processing since 2010, each involving a single modality in the input signal. However, many applications in artificial intelligence involve more than one modality. It is therefore of broad interest to study the more difficult and complex problem of modeling and learning across multiple modalities. In this paper, a technical review of the models and learning methods for multimodal intelligence is provided. The main focus is the combination of vision and natural language, which has become an important area in both computer vision and natural language processing research communities. This review provides a comprehensive analysis of recent work on multimodal deep learning from three new angles - learning multimodal representations, the fusion of multimodal signals at various levels, and multimodal applications. On multimodal representation learning, we review the key concept of embedding, which unifies the multimodal signals into the same vector space and thus enables cross-modality signal processing. We also review the properties of the many types of embedding constructed and learned for general downstream tasks. On multimodal fusion, this review focuses on special architectures for the integration of the representation of unimodal signals for a particular task. On applications, selected areas of a broad interest in current literature are covered, including caption generation, text-to-image generation, and visual question answering. We believe this review can facilitate future studies in the emerging field of multimodal intelligence for the community.
A Formal Evaluation of PSNR as Quality Measurement Parameter for Image Segmentation Algorithms
May 23, 2016
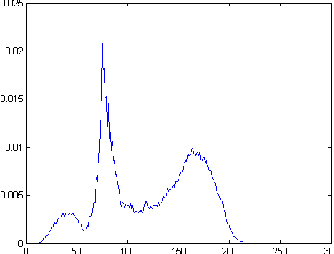

Quality evaluation of image segmentation algorithms are still subject of debate and research. Currently, there is no generic metric that could be applied to any algorithm reliably. This article contains an evaluation for the PSRN (Peak Signal-To-Noise Ratio) as a metric which has been used to evaluate threshold level selection as well as the number of thresholds in the case of multi-level segmentation. The results obtained in this study suggest that the PSNR is not an adequate quality measurement for segmentation algorithms.
Lossless Compression of Deep Neural Networks
Jan 24, 2020

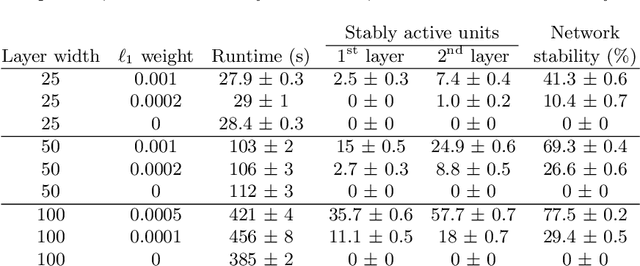
Deep neural networks have been successful in many predictive modeling tasks, such as image and language recognition, where large neural networks are often used to obtain good accuracy. Consequently, it is challenging to deploy these networks under limited computational resources, such as in mobile devices. In this work, we introduce an algorithm that removes units and layers of a neural network while not changing the output that is produced, which thus implies a lossless compression. This algorithm, which we denote as LEO (Lossless Expressiveness Optimization), relies on Mixed-Integer Linear Programming (MILP) to identify Rectifier Linear Units (ReLUs) with linear behavior over the input domain. By using L1 regularization to induce such behavior, we can benefit from training over a larger architecture than we would later use in the environment where the trained neural network is deployed.
Propagated Perturbation of Adversarial Attack for well-known CNNs: Empirical Study and its Explanation
Sep 23, 2019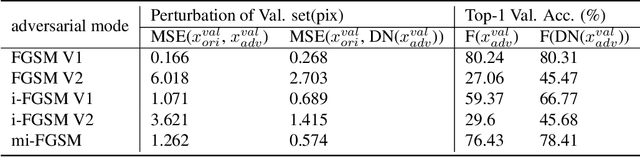
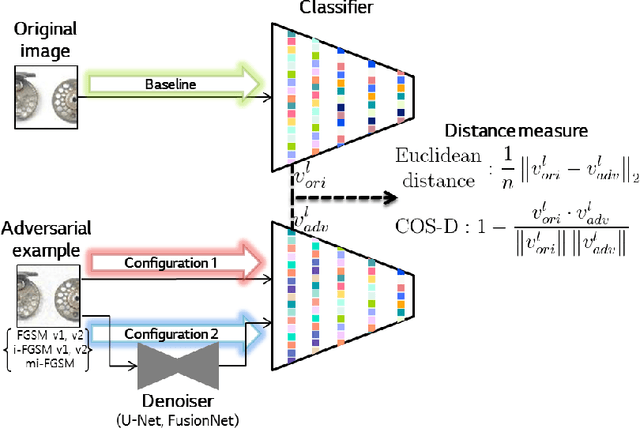
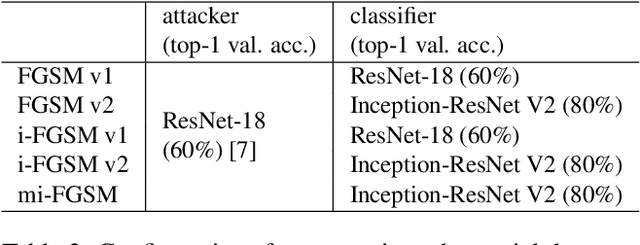
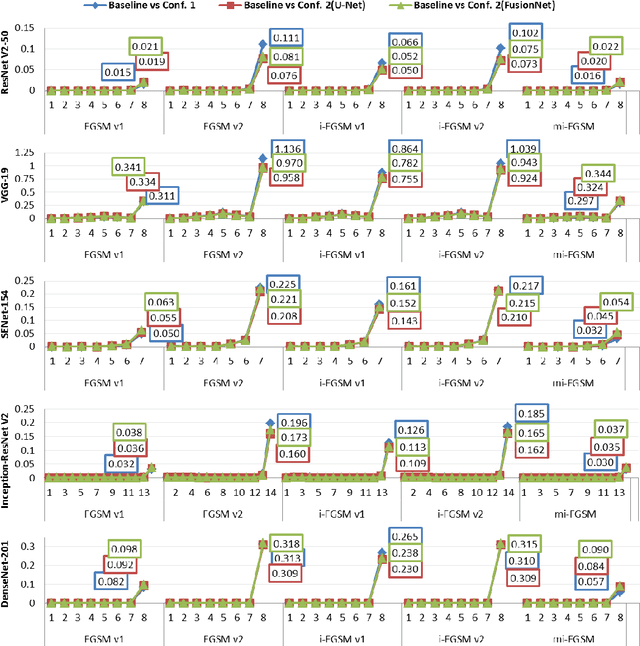
Deep Neural Network based classifiers are known to be vulnerable to perturbations of inputs constructed by an adversarial attack to force misclassification. Most studies have focused on how to make vulnerable noise by gradient based attack methods or to defense model from adversarial attack. The use of the denoiser model is one of a well-known solution to reduce the adversarial noise although classification performance had not significantly improved. In this study, we aim to analyze the propagation of adversarial attack as an explainable AI(XAI) point of view. Specifically, we examine the trend of adversarial perturbations through the CNN architectures. To analyze the propagated perturbation, we measured normalized Euclidean Distance and cosine distance in each CNN layer between the feature map of the perturbed image passed through denoiser and the non-perturbed original image. We used five well-known CNN based classifiers and three gradient-based adversarial attacks. From the experimental results, we observed that in most cases, Euclidean Distance explosively increases in the final fully connected layer while cosine distance fluctuated and disappeared at the last layer. This means that the use of denoiser can decrease the amount of noise. However, it failed to defense accuracy degradation.
Smart Inference for Multidigit Convolutional Neural Network based Barcode Decoding
Apr 14, 2020
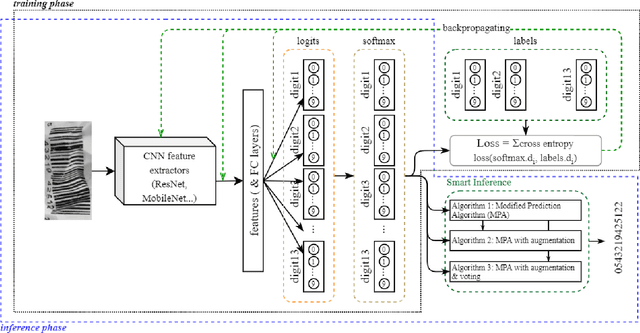
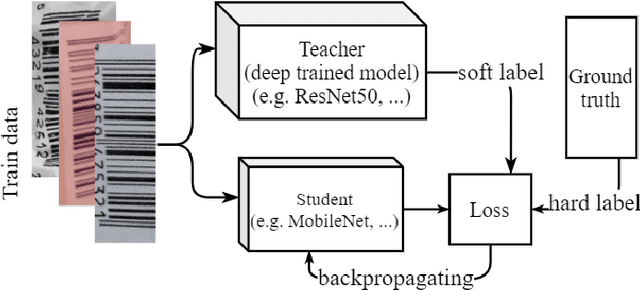
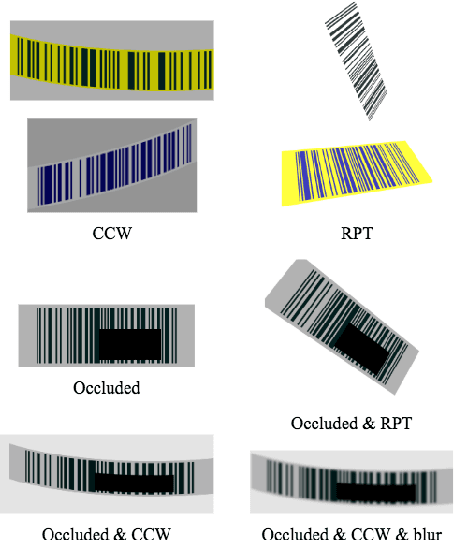
Barcodes are ubiquitous and have been used in most of critical daily activities for decades. However, most of traditional decoders require well-founded barcode under a relatively standard condition. While wilder conditioned barcodes such as underexposed, occluded, blurry, wrinkled and rotated are commonly captured in reality, those traditional decoders show weakness of recognizing. Several works attempted to solve those challenging barcodes, but many limitations still exist. This work aims to solve the decoding problem using deep convolutional neural network with the possibility of running on portable devices. Firstly, we proposed a special modification of inference based on the feature of having checksum and test-time augmentation, named as Smart Inference (SI) in prediction phase of a trained model. SI considerably boosts accuracy and reduces the false prediction for trained models. Secondly, we have created a large practical evaluation dataset of real captured 1D barcode under various challenging conditions to test our methods vigorously, which is publicly available for other researchers. The experiments' results demonstrated the SI effectiveness with the highest accuracy of 95.85% which outperformed many existing decoders on the evaluation set. Finally, we successfully minimized the best model by knowledge distillation to a shallow model which is shown to have high accuracy (90.85%) with good inference speed of 34.2 ms per image on a real edge device.
A Unified View of Label Shift Estimation
Mar 17, 2020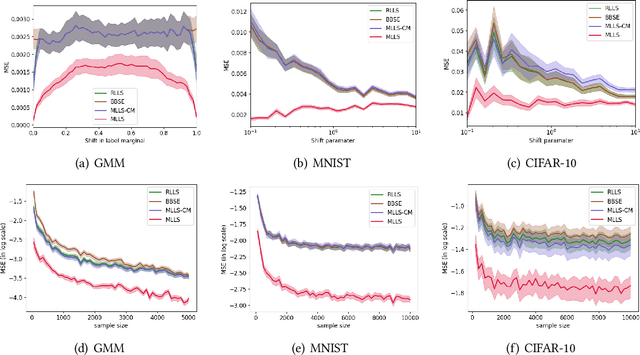
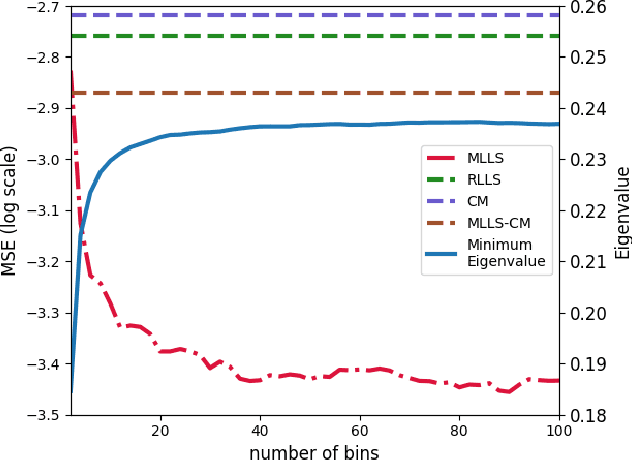
Label shift describes the setting where although the label distribution might change between the source and target domains, the class-conditional probabilities (of data given a label) do not. There are two dominant approaches for estimating the label marginal. BBSE, a moment-matching approach based on confusion matrices, is provably consistent and provides interpretable error bounds. However, a maximum likelihood estimation approach, which we call MLLS, dominates empirically. In this paper, we present a unified view of the two methods and the first theoretical characterization of the likelihood-based estimator. Our contributions include (i) conditions for consistency of MLLS, which include calibration of the classifier and a confusion matrix invertibility condition that BBSE also requires; (ii) a unified view of the methods, casting the confusion matrix as roughly equivalent to MLLS for a particular choice of calibration method; and (iii) a decomposition of MLLS's finite-sample error into terms reflecting the impacts of miscalibration and estimation error. Our analysis attributes BBSE's statistical inefficiency to a loss of information due to coarse calibration. We support our findings with experiments on both synthetic data and the MNIST and CIFAR10 image recognition datasets.
Forecasting Mobile Traffic with Spatiotemporal correlation using Deep Regression
Jul 25, 2019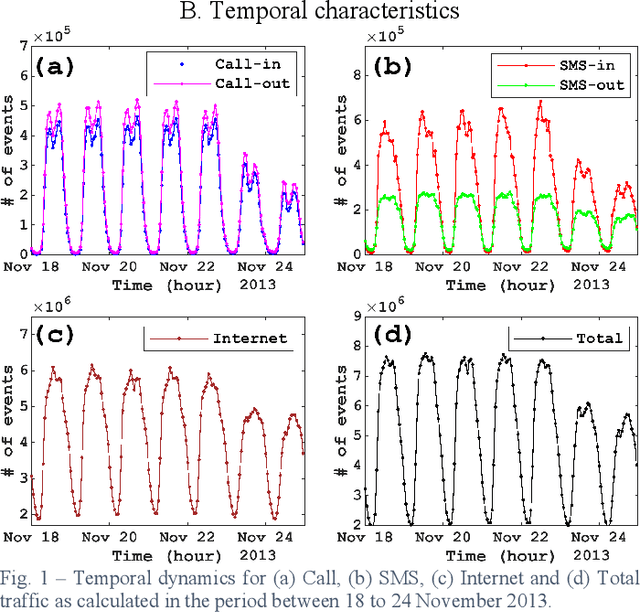
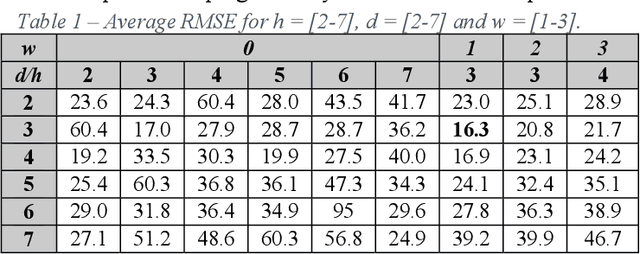
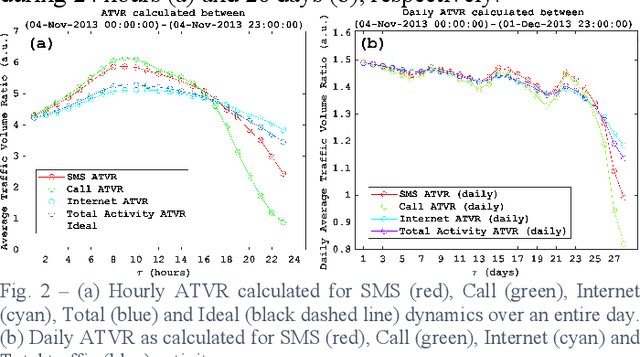
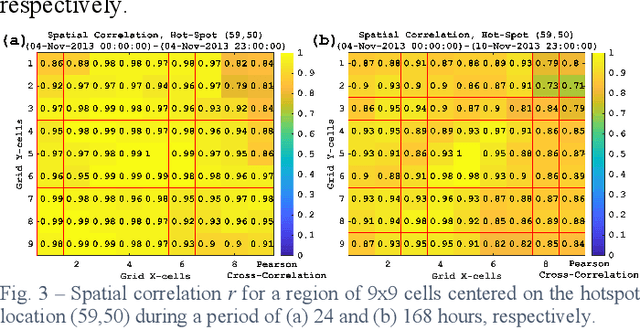
The concept of mobility prediction represents one of the key enablers for an efficient management of future cellular networks, which tend to be progressively more elaborate and dense due to the aggregation of multiple technologies. In this letter we aim to investigate the problem of cellular traffic prediction over a metropolitan area and propose a deep regression (DR) approach to model its complex spatio-temporal dynamics. DR is instrumental in capturing multi-scale and multi-domain dependences of mobile data by solving an image-to-image regression problem. A parametric relationship between input and expected output is defined and grid search is put in place to isolate and optimize performance. Experimental results confirm that the proposed method achieves a lower prediction error against stateof-the-art algorithms. We validate forecasting performance and stability by using a large public dataset of a European Provider.
KPNet: Towards Minimal Face Detector
Mar 17, 2020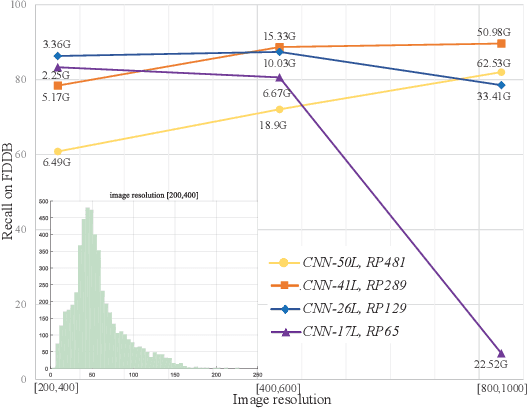

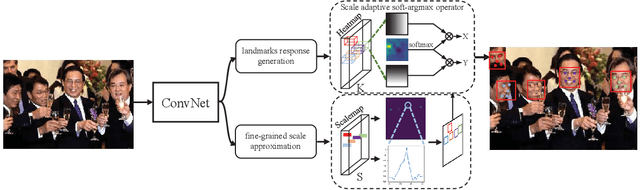
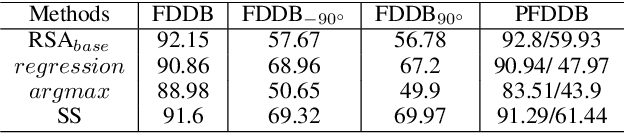
The small receptive field and capacity of minimal neural networks limit their performance when using them to be the backbone of detectors. In this work, we find that the appearance feature of a generic face is discriminative enough for a tiny and shallow neural network to verify from the background. And the essential barriers behind us are 1) the vague definition of the face bounding box and 2) tricky design of anchor-boxes or receptive field. Unlike most top-down methods for joint face detection and alignment, the proposed KPNet detects small facial keypoints instead of the whole face by in a bottom-up manner. It first predicts the facial landmarks from a low-resolution image via the well-designed fine-grained scale approximation and scale adaptive soft-argmax operator. Finally, the precise face bounding boxes, no matter how we define it, can be inferred from the keypoints. Without any complex head architecture or meticulous network designing, the KPNet achieves state-of-the-art accuracy on generic face detection and alignment benchmarks with only $\sim1M$ parameters, which runs at 1000fps on GPU and is easy to perform real-time on most modern front-end chips.