 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShorter SPECT Scans Using Self-supervised Coordinate Learning to Synthesize Skipped Projection Views
Jun 27, 2024



Purpose: This study addresses the challenge of extended SPECT imaging duration under low-count conditions, as encountered in Lu-177 SPECT imaging, by developing a self-supervised learning approach to synthesize skipped SPECT projection views, thus shortening scan times in clinical settings. Methods: We employed a self-supervised coordinate-based learning technique, adapting the neural radiance field (NeRF) concept in computer vision to synthesize under-sampled SPECT projection views. For each single scan, we used self-supervised coordinate learning to estimate skipped SPECT projection views. The method was tested with various down-sampling factors (DFs=2, 4, 8) on both Lu-177 phantom SPECT/CT measurements and clinical SPECT/CT datasets, from 11 patients undergoing Lu-177 DOTATATE and 6 patients undergoing Lu-177 PSMA-617 radiopharmaceutical therapy. Results: For SPECT reconstructions, our method outperformed the use of linearly interpolated projections and partial projection views in relative contrast-to-noise-ratios (RCNR) averaged across different downsampling factors: 1) DOTATATE: 83% vs. 65% vs. 67% for lesions and 86% vs. 70% vs. 67% for kidney, 2) PSMA: 76% vs. 69% vs. 68% for lesions and 75% vs. 55% vs. 66% for organs, including kidneys, lacrimal glands, parotid glands, and submandibular glands. Conclusion: The proposed method enables reduction in acquisition time (by factors of 2, 4, or 8) while maintaining quantitative accuracy in clinical SPECT protocols by allowing for the collection of fewer projections. Importantly, the self-supervised nature of this NeRF-based approach eliminates the need for extensive training data, instead learning from each patient's projection data alone. The reduction in acquisition time is particularly relevant for imaging under low-count conditions and for protocols that require multiple-bed positions such as whole-body imaging.
Training End-to-End Unrolled Iterative Neural Networks for SPECT Image Reconstruction
Jan 23, 2023



Training end-to-end unrolled iterative neural networks for SPECT image reconstruction requires a memory-efficient forward-backward projector for efficient backpropagation. This paper describes an open-source, high performance Julia implementation of a SPECT forward-backward projector that supports memory-efficient backpropagation with an exact adjoint. Our Julia projector uses only ~5% of the memory of an existing Matlab-based projector. We compare unrolling a CNN-regularized expectation-maximization (EM) algorithm with end-to-end training using our Julia projector with other training methods such as gradient truncation (ignoring gradients involving the projector) and sequential training, using XCAT phantoms and virtual patient (VP) phantoms generated from SIMIND Monte Carlo (MC) simulations. Simulation results with two different radionuclides (90Y and 177Lu) show that: 1) For 177Lu XCAT phantoms and 90Y VP phantoms, training unrolled EM algorithm in end-to-end fashion with our Julia projector yields the best reconstruction quality compared to other training methods and OSEM, both qualitatively and quantitatively. For VP phantoms with 177Lu radionuclide, the reconstructed images using end-to-end training are in higher quality than using sequential training and OSEM, but are comparable with using gradient truncation. We also find there exists a trade-off between computational cost and reconstruction accuracy for different training methods. End-to-end training has the highest accuracy because the correct gradient is used in backpropagation; sequential training yields worse reconstruction accuracy, but is significantly faster and uses much less memory.
Improved low-count quantitative PET reconstruction with a variational neural network
Jun 05, 2019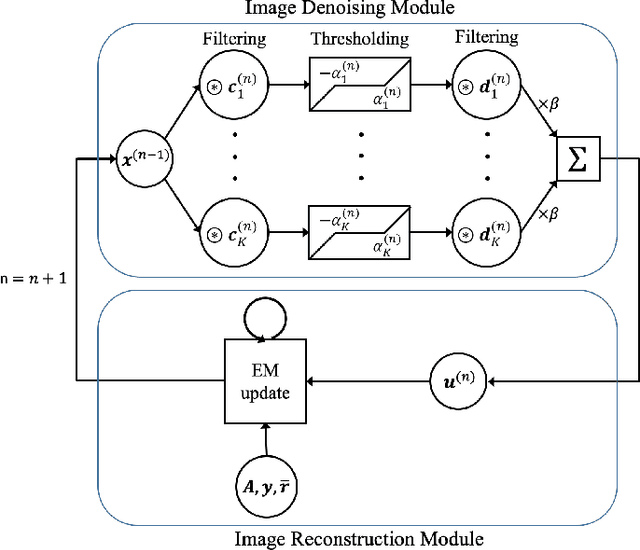
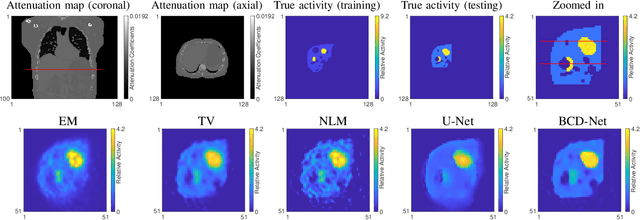
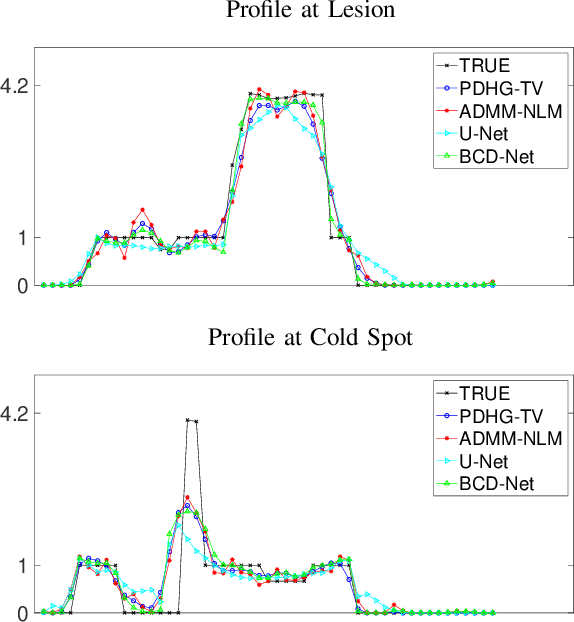

Image reconstruction in low-count PET is particularly challenging because gammas from natural radioactivity in Lu-based crystals cause high random fractions that lower the measurement signal-to-noise-ratio (SNR). In model-based image reconstruction (MBIR), using more iterations of an unregularized method may increase the noise, so incorporating regularization into the image reconstruction is desirable to control the noise. New regularization methods based on learned convolutional operators are emerging in MBIR. We modify the architecture of a variational neural network, BCD-Net, for PET MBIR, and demonstrate the efficacy of the trained BCD-Net using XCAT phantom data that simulates the low true coincidence count-rates with high random fractions typical for Y-90 PET patient imaging after Y-90 microsphere radioembolization. Numerical results show that the proposed BCD-Net significantly improves PET reconstruction performance compared to MBIR methods using non-trained regularizers, total variation (TV) and non-local means (NLM), and a non-MBIR method using a single forward pass deep neural network, U-Net. BCD-Net improved activity recovery for a hot sphere significantly and reduced noise, whereas non-trained regularizers had a trade-off between noise and quantification. BCD-Net improved CNR and RMSE by 43.4% (85.7%) and 12.9% (29.1%) compared to TV (NLM) regularized MBIR. Moreover, whereas the image reconstruction results show that the non-MBIR U-Net over-fits the training data, BCD-Net successfully generalizes to data that differs from training data. Improvements were also demonstrated for the clinically relevant phantom measurement data where we used training and testing datasets having very different activity distribution and count-level.