 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Denoising Using Interquartile Range Filter with Local Averaging
Feb 05, 2013
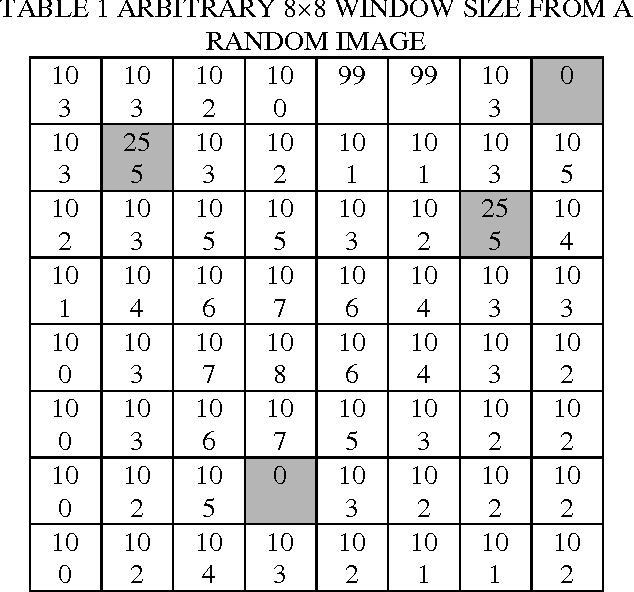
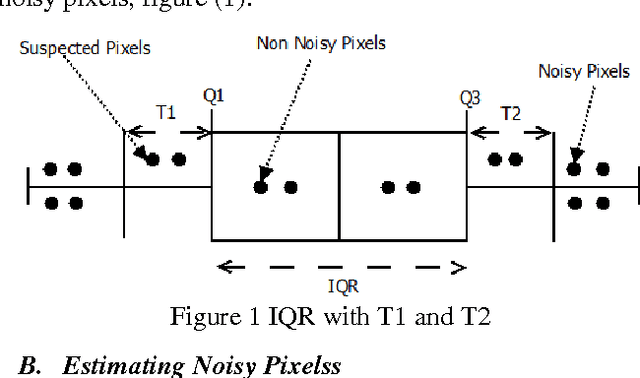

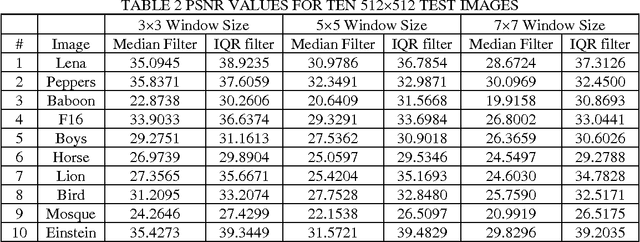
Image denoising is one of the fundamental problems in image processing. In this paper, a novel approach to suppress noise from the image is conducted by applying the interquartile range (IQR) which is one of the statistical methods used to detect outlier effect from a dataset. A window of size kXk was implemented to support IQR filter. Each pixel outside the IQR range of the kXk window is treated as noisy pixel. The estimation of the noisy pixels was obtained by local averaging. The essential advantage of applying IQR filter is to preserve edge sharpness better of the original image. A variety of test images have been used to support the proposed filter and PSNR was calculated and compared with median filter. The experimental results on standard test images demonstrate this filter is simpler and better performing than median filter.
* 5 pages, 8 figures, 2 tables
Vehicle Driving Assistant
Feb 10, 2020



Autonomous vehicles has been a common term in our day to day life with car manufacturers like Tesla shipping cars that are SAE Level 3. While these vehicles include a slew of features such as parking assistance and cruise control,they have mostly been tailored to foreign roads. Potholes, and the abundance of them, is something that is unique to our Indian roads. We believe that successful detection of potholes from visual images can be applied in a variety of scenarios. Moreover, the sheer variety in the color, shape and size of potholes makes this problem an apt candidate to be solved using modern machine learning and image processing techniques.
Camera-Lidar Integration: Probabilistic sensor fusion for semantic mapping
Jul 09, 2020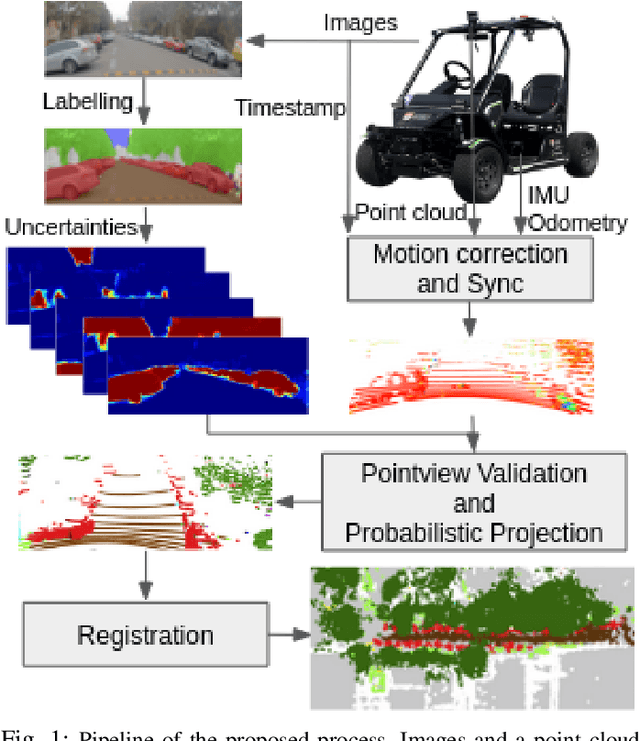
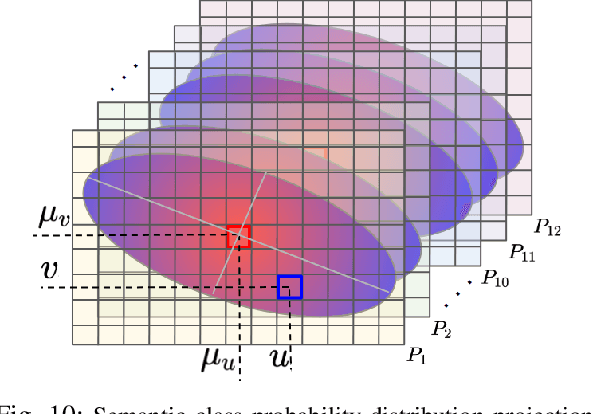
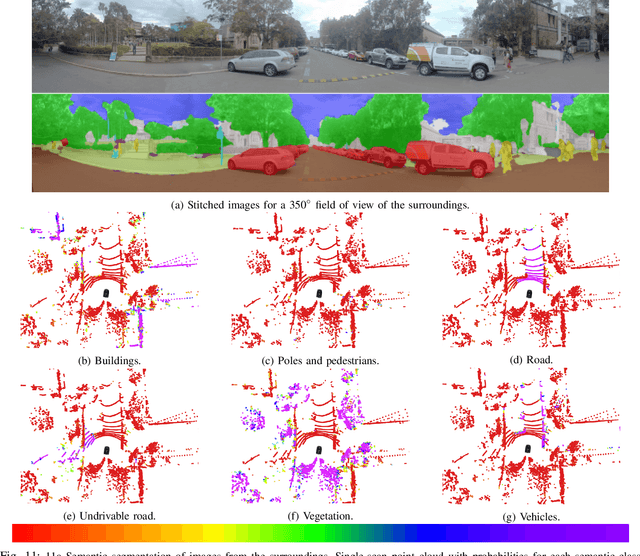
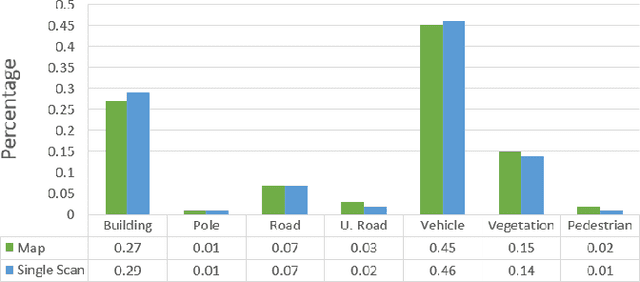
An automated vehicle operating in an urban environment must be able to perceive and recognise object/obstacles in a three-dimensional world while navigating in a constantly changing environment. In order to plan and execute accurate sophisticated driving maneuvers, a high-level contextual understanding of the surroundings is essential. Due to the recent progress in image processing, it is now possible to obtain high definition semantic information in 2D from monocular cameras, though cameras cannot reliably provide the highly accurate 3D information provided by lasers. The fusion of these two sensor modalities can overcome the shortcomings of each individual sensor, though there are a number of important challenges that need to be addressed in a probabilistic manner. In this paper, we address the common, yet challenging, lidar/camera/semantic fusion problems which are seldom approached in a wholly probabilistic manner. Our approach is capable of using a multi-sensor platform to build a three-dimensional semantic voxelized map that considers the uncertainty of all of the processes involved. We present a probabilistic pipeline that incorporates uncertainties from the sensor readings (cameras, lidar, IMU and wheel encoders), compensation for the motion of the vehicle, and heuristic label probabilities for the semantic images. We also present a novel and efficient viewpoint validation algorithm to check for occlusions from the camera frames. A probabilistic projection is performed from the camera images to the lidar point cloud. Each labelled lidar scan then feeds into an octree map building algorithm that updates the class probabilities of the map voxels every time a new observation is available. We validate our approach using a set of qualitative and quantitative experimental tests on the USyd Dataset.
Adversarial Deepfakes: Evaluating Vulnerability of Deepfake Detectors to Adversarial Examples
Mar 14, 2020
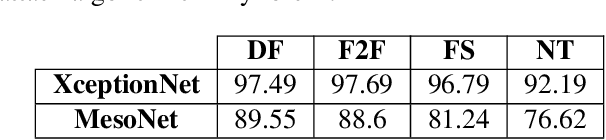
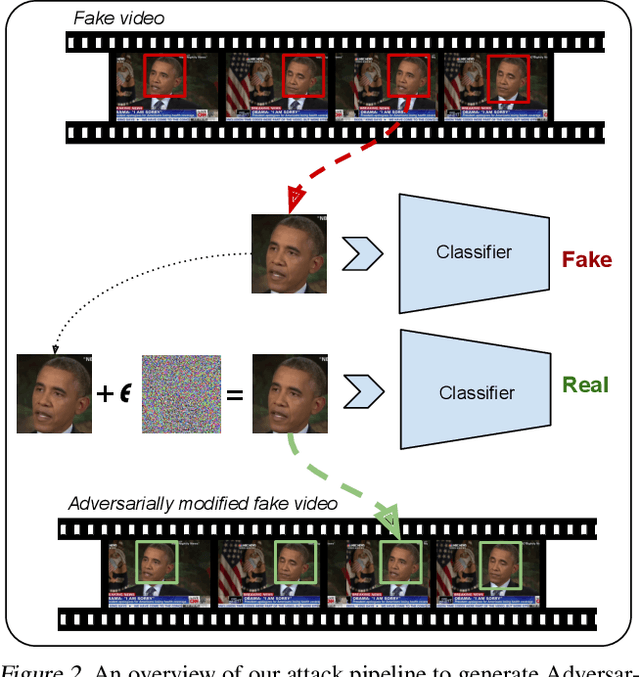
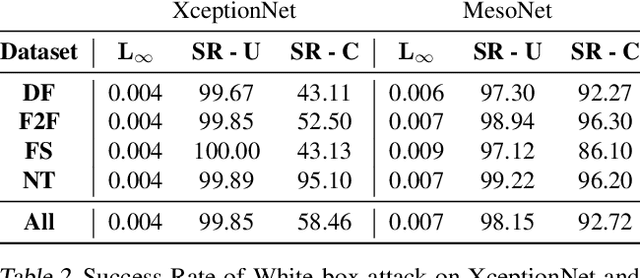
Recent advances in video manipulation techniques have made the generation of fake videos more accessible than ever before. Manipulated videos can fuel disinformation and reduce trust in media. Therefore detection of fake videos has garnered immense interest in academia and industry. Recently developed Deepfake detection methods rely on deep neural networks (DNNs) to distinguish AI-generated fake videos from real videos. In this work, we demonstrate that it is possible to bypass such detectors by adversarially modifying fake videos synthesized using existing Deepfake generation methods. We further demonstrate that our adversarial perturbations are robust to image and video compression codecs, making them a real-world threat. We present pipelines in both white-box and black-box attack scenarios that can fool DNN based Deepfake detectors into classifying fake videos as real.
High-Accuracy Malware Classification with a Malware-Optimized Deep Learning Model
Apr 10, 2020
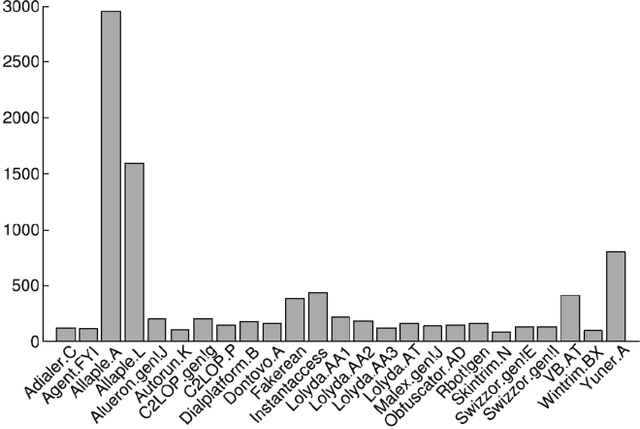
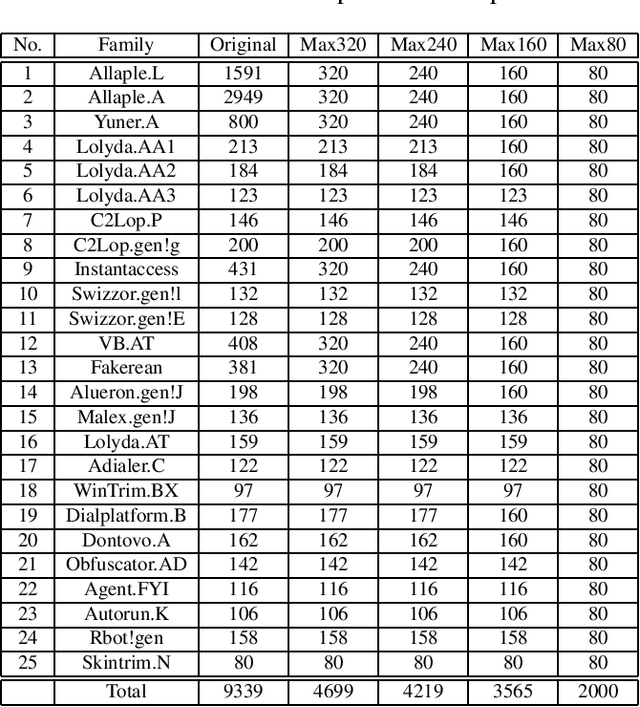
Malware threats are a serious problem for computer security, and the ability to detect and classify malware is critical for maintaining the security level of a computer. Recently, a number of researchers are investigating techniques for classifying malware families using malware visualization, which convert the binary structure of malware into grayscale images. Although there have been many reports that applied CNN to malware visualization image classification, it has not been revealed how to pick out a model that fits a given malware dataset and achieves higher classification accuracy. We propose a strategy to select a Deep learning model that fits the malware visualization images. Our strategy uses the fine-tuning method for the pre-trained CNN model and a dataset that solves the imbalance problem. We chose the VGG19 model based on the proposed strategy to classify the Malimg dataset. Experimental results show that the classification accuracy is 99.72 %, which is higher than other previously proposed malware classification methods.
Weakly-Supervised 3D Pose Estimation from a Single Image using Multi-View Consistency
Sep 13, 2019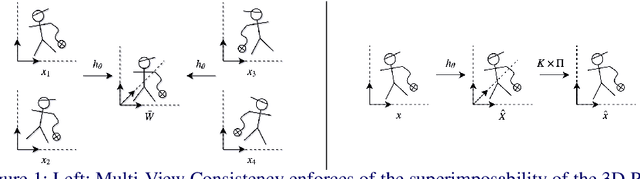
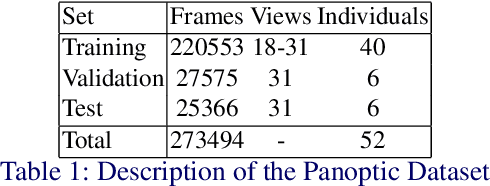


We present a novel data-driven regularizer for weakly-supervised learning of 3D human pose estimation that eliminates the drift problem that affects existing approaches. We do this by moving the stereo reconstruction problem into the loss of the network itself. This avoids the need to reconstruct 3D data prior to training and unlike previous semi-supervised approaches, avoids the need for a warm-up period of supervised training. The conceptual and implementational simplicity of our approach is fundamental to its appeal. Not only is it straightforward to augment many weakly-supervised approaches with our additional re-projection based loss, but it is obvious how it shapes reconstructions and prevents drift. As such we believe it will be a valuable tool for any researcher working in weakly-supervised 3D reconstruction. Evaluating on Panoptic, the largest multi-camera and markerless dataset available, we obtain an accuracy that is essentially indistinguishable from a strongly-supervised approach making full use of 3D groundtruth in training.
Effective and Robust Detection of Adversarial Examples via Benford-Fourier Coefficients
May 12, 2020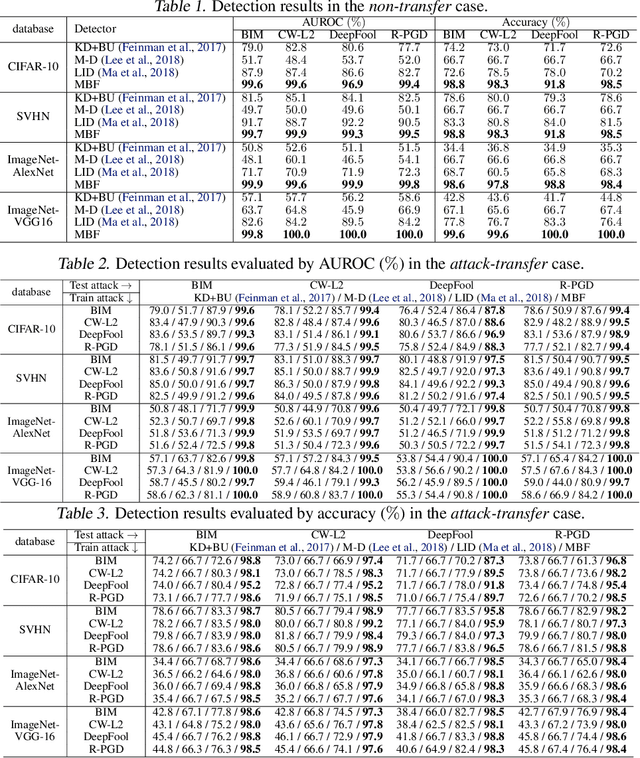
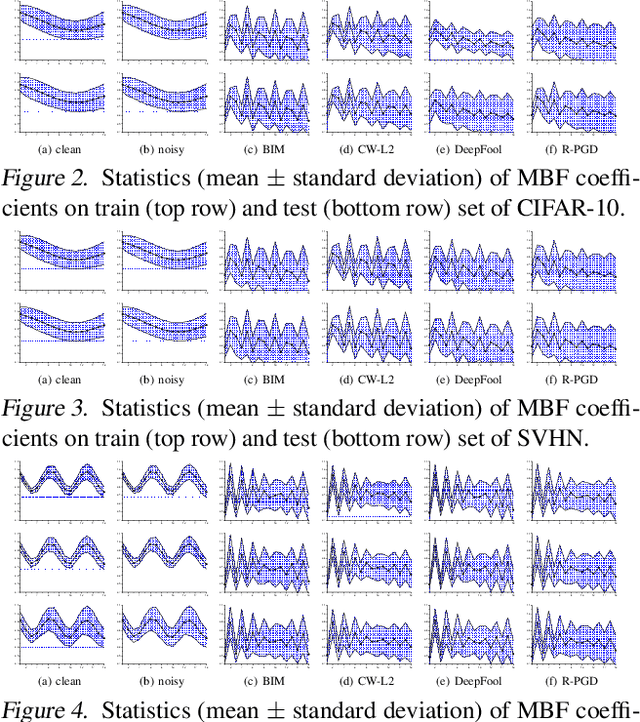
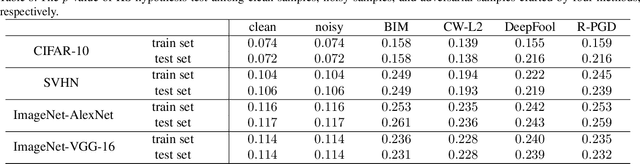
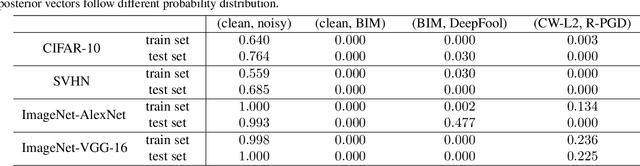
Adversarial examples have been well known as a serious threat to deep neural networks (DNNs). In this work, we study the detection of adversarial examples, based on the assumption that the output and internal responses of one DNN model for both adversarial and benign examples follow the generalized Gaussian distribution (GGD), but with different parameters (i.e., shape factor, mean, and variance). GGD is a general distribution family to cover many popular distributions (e.g., Laplacian, Gaussian, or uniform). It is more likely to approximate the intrinsic distributions of internal responses than any specific distribution. Besides, since the shape factor is more robust to different databases rather than the other two parameters, we propose to construct discriminative features via the shape factor for adversarial detection, employing the magnitude of Benford-Fourier coefficients (MBF), which can be easily estimated using responses. Finally, a support vector machine is trained as the adversarial detector through leveraging the MBF features. Extensive experiments in terms of image classification demonstrate that the proposed detector is much more effective and robust on detecting adversarial examples of different crafting methods and different sources, compared to state-of-the-art adversarial detection methods.
Two-Stream Aural-Visual Affect Analysis in the Wild
Mar 03, 2020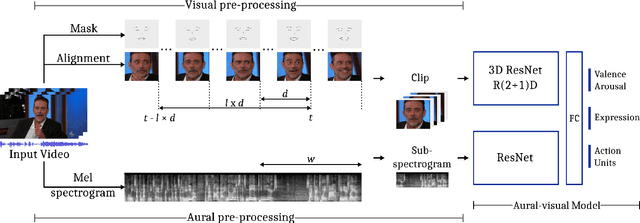
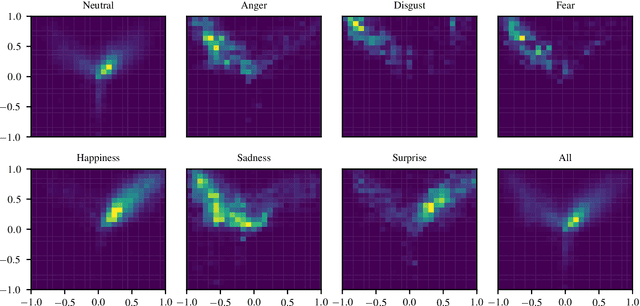

Human affect recognition is an essential part of natural human-computer interaction. However, current methods are still in their infancy, especially for in-the-wild data. In this work, we introduce our submission to the Affective Behavior Analysis in-the-wild (ABAW) 2020 competition. We propose a two-stream aural-visual analysis model to recognize affective behavior from videos. Audio and image streams are first processed separately and fed into a convolutional neural network. Instead of applying recurrent architectures for temporal analysis we only use temporal convolutions. Furthermore, the model is given access to additional features extracted during face-alignment. At training time, we exploit correlations between different emotion representations to improve performance. Our model achieves promising results on the challenging Aff-Wild2 database.
Robust Meta-learning for Mixed Linear Regression with Small Batches
Jun 18, 2020
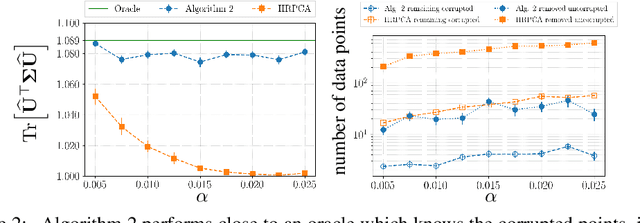
A common challenge faced in practical supervised learning, such as medical image processing and robotic interactions, is that there are plenty of tasks but each task cannot afford to collect enough labeled examples to be learned in isolation. However, by exploiting the similarities across those tasks, one can hope to overcome such data scarcity. Under a canonical scenario where each task is drawn from a mixture of k linear regressions, we study a fundamental question: can abundant small-data tasks compensate for the lack of big-data tasks? Existing second moment based approaches show that such a trade-off is efficiently achievable, with the help of medium-sized tasks with $\Omega(k^{1/2})$ examples each. However, this algorithm is brittle in two important scenarios. The predictions can be arbitrarily bad (i) even with only a few outliers in the dataset; or (ii) even if the medium-sized tasks are slightly smaller with $o(k^{1/2})$ examples each. We introduce a spectral approach that is simultaneously robust under both scenarios. To this end, we first design a novel outlier-robust principal component analysis algorithm that achieves an optimal accuracy. This is followed by a sum-of-squares algorithm to exploit the information from higher order moments. Together, this approach is robust against outliers and achieves a graceful statistical trade-off; the lack of $\Omega(k^{1/2})$-size tasks can be compensated for with smaller tasks, which can now be as small as $O(\log k)$.
Registering large volume serial-section electron microscopy image sets for neural circuit reconstruction using FFT signal whitening
Dec 14, 2016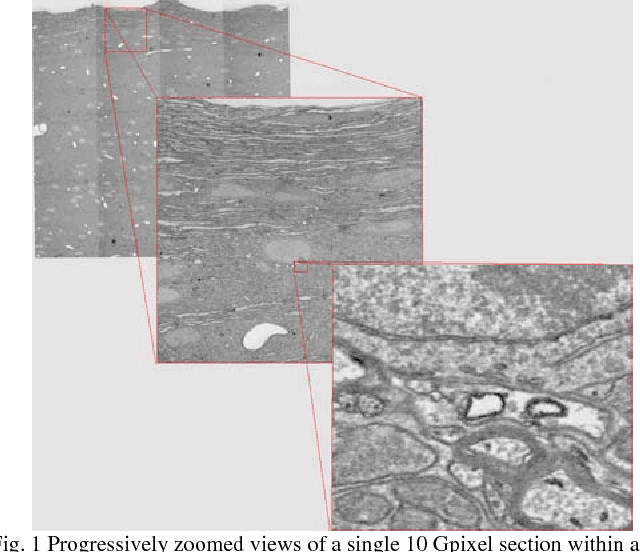
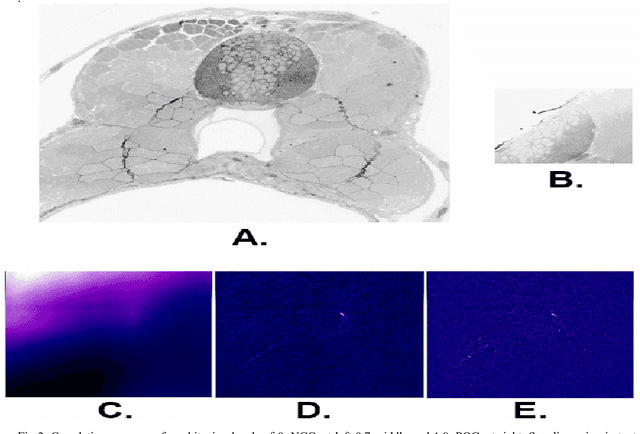
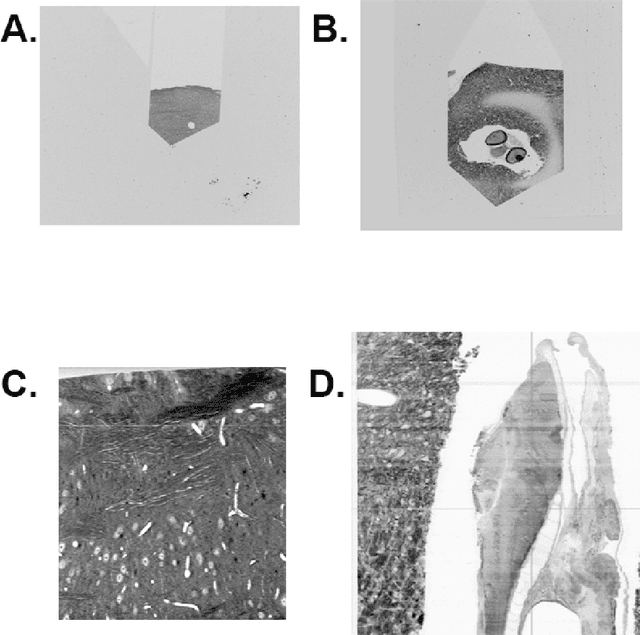
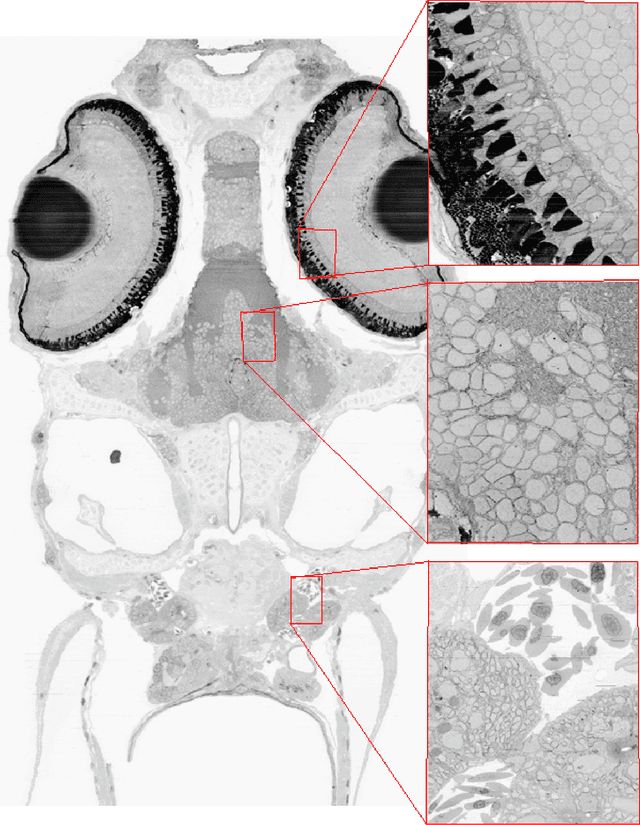
The detailed reconstruction of neural anatomy for connectomics studies requires a combination of resolution and large three-dimensional data capture provided by serial section electron microscopy (ssEM). The convergence of high throughput ssEM imaging and improved tissue preparation methods now allows ssEM capture of complete specimen volumes up to cubic millimeter scale. The resulting multi-terabyte image sets span thousands of serial sections and must be precisely registered into coherent volumetric forms in which neural circuits can be traced and segmented. This paper introduces a Signal Whitening Fourier Transform Image Registration approach (SWiFT-IR) under development at the Pittsburgh Supercomputing Center and its use to align mouse and zebrafish brain datasets acquired using the wafer mapper ssEM imaging technology recently developed at Harvard University. Unlike other methods now used for ssEM registration, SWiFT-IR modifies its spatial frequency response during image matching to maximize a signal-to-noise measure used as its primary indicator of alignment quality. This alignment signal is more robust to rapid variations in biological content and unavoidable data distortions than either phase-only or standard Pearson correlation, thus allowing more precise alignment and statistical confidence. These improvements in turn enable an iterative registration procedure based on projections through multiple sections rather than more typical adjacent-pair matching methods. This projection approach, when coupled with known anatomical constraints and iteratively applied in a multi-resolution pyramid fashion, drives the alignment into a smooth form that properly represents complex and widely varying anatomical content such as the full cross-section zebrafish data.