 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Depth-Preserving Real-Time Arbitrary Style Transfer
Jun 03, 2019
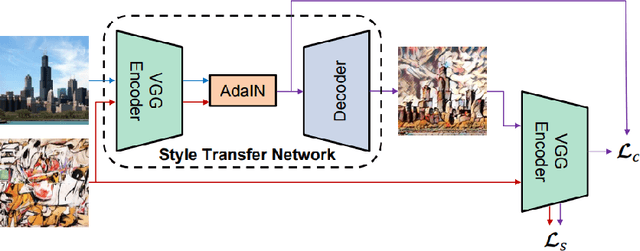

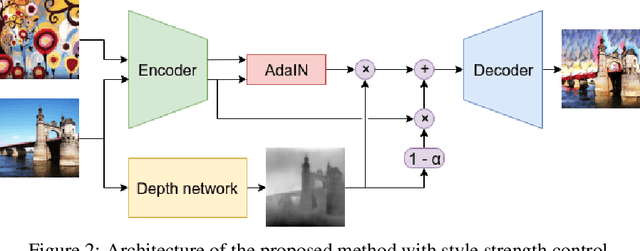

Style transfer is the process of rendering one image with some content in the style of another image, representing the style. Recent studies of Liu et al. (2017) have shown significant improvement of style transfer rendering quality by adjusting traditional methods of Gatys et al. (2016) and Johnson et al. (2016) with regularizer, forcing preservation of the depth map of the content image. However these traditional methods are either computationally inefficient or require training a separate neural network for new style. AdaIN method of Huang et al. (2017) allows efficient transferring of arbitrary style without training a separate model but is not able to reproduce the depth map of the content image. We propose an extension to this method, allowing depth map preservation. Qualitative analysis and results of user evaluation study indicate that the proposed method provides better stylizations, compared to the original style transfer methods of Gatys et al. (2016) and Huang et al. (2017).
A Comprehensive Approach to Unsupervised Embedding Learning based on AND Algorithm
Feb 26, 2020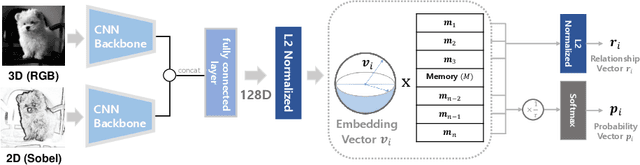
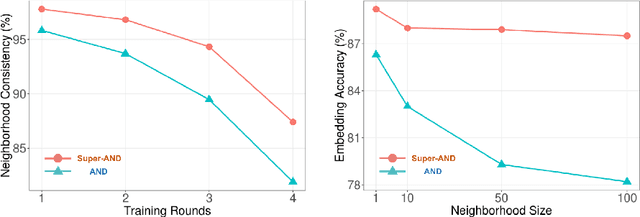
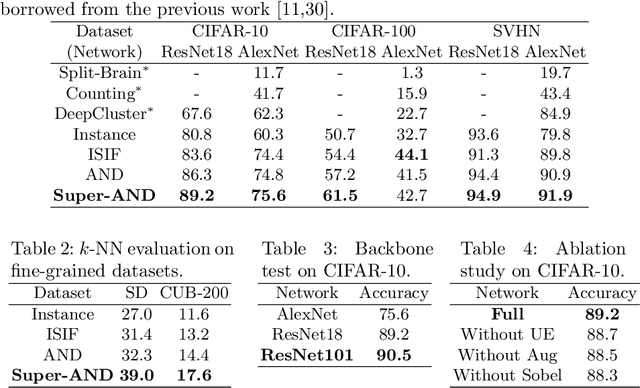

Unsupervised embedding learning aims to extract good representation from data without the need for any manual labels, which has been a critical challenge in many supervised learning tasks. This paper proposes a new unsupervised embedding approach, called Super-AND, which extends the current state-of-the-art model. Super-AND has its unique set of losses that can gather similar samples nearby within a low-density space while keeping invariant features intact against data augmentation. Super-AND outperforms all existing approaches and achieves an accuracy of 89.2% on the image classification task for CIFAR-10. We discuss the practical implications of this method in assisting semi-supervised tasks.
Robustness Verification for Classifier Ensembles
May 12, 2020
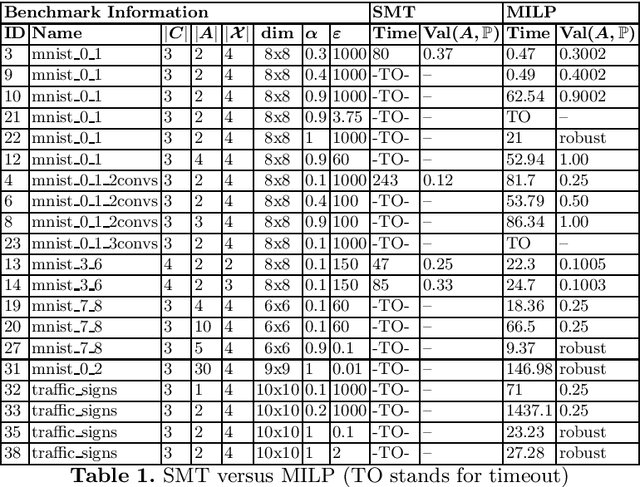

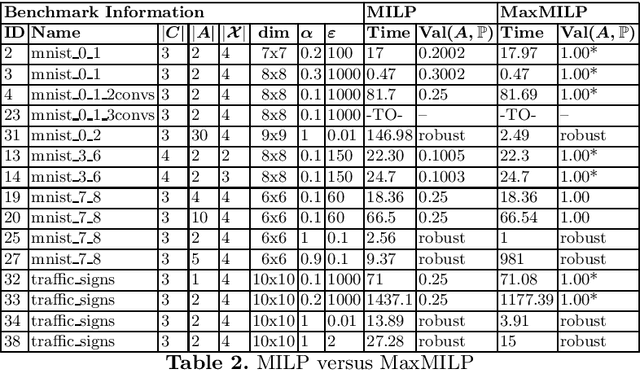
We give a formal verification procedure that decides whether a classifier ensemble is robust against arbitrary randomized attacks. Such attacks consist of a set of deterministic attacks and a distribution over this set. The robustness-checking problem consists of assessing, given a set of classifiers and a labelled data set, whether there exists a randomized attack that induces a certain expected loss against all classifiers. We show the NP-hardness of the problem and provide an upper bound on the number of attacks that is sufficient to form an optimal randomized attack. These results provide an effective way to reason about the robustness of a classifier ensemble. We provide SMT and MILP encodings to compute optimal randomized attacks or prove that there is no attack inducing a certain expected loss. In the latter case, the classifier ensemble is provably robust. Our prototype implementation verifies multiple neural-network ensembles trained for image-classification tasks. The experimental results using the MILP encoding are promising both in terms of scalability and the general applicability of our verification procedure.
Improving Limited Angle CT Reconstruction with a Robust GAN Prior
Oct 03, 2019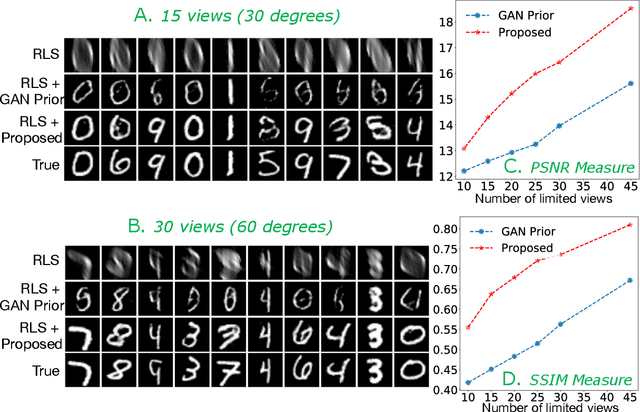
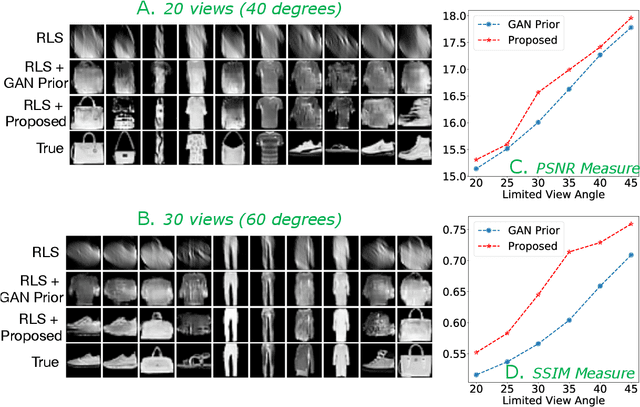
Limited angle CT reconstruction is an under-determined linear inverse problem that requires appropriate regularization techniques to be solved. In this work we study how pre-trained generative adversarial networks (GANs) can be used to clean noisy, highly artifact laden reconstructions from conventional techniques, by effectively projecting onto the inferred image manifold. In particular, we use a robust version of the popularly used GAN prior for inverse problems, based on a recent technique called corruption mimicking, that significantly improves the reconstruction quality. The proposed approach operates in the image space directly, as a result of which it does not need to be trained or require access to the measurement model, is scanner agnostic, and can work over a wide range of sensing scenarios.
Cost Volume Pyramid Based Depth Inference for Multi-View Stereo
Dec 18, 2019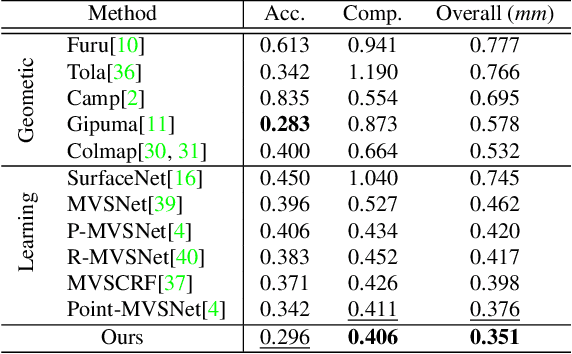
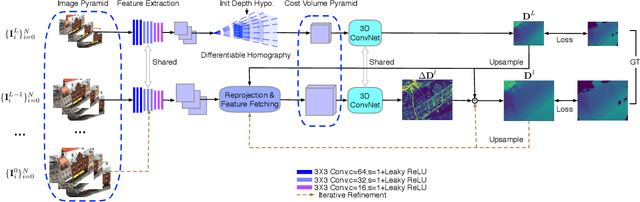
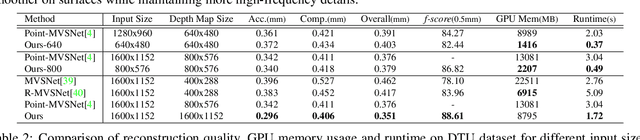
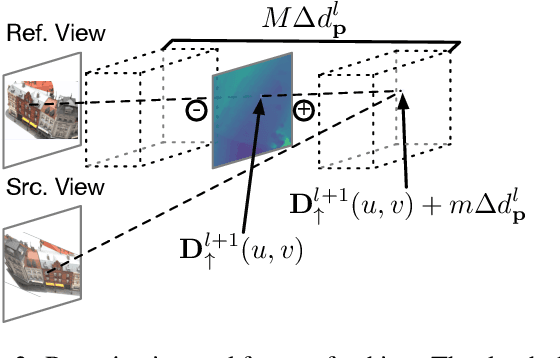
We propose a cost volume based neural network for depth inference from multi-view images. We demonstrate that building a cost volume pyramid in a coarse-to-fine manner instead of constructing a cost volume at a fixed resolution leads to a compact, lightweight network and allows us inferring high resolution depth maps to achieve better reconstruction results. To this end, a cost volume based on uniform sampling of fronto-parallel planes across entire depth range is first built at the coarsest resolution of an image. Given current depth estimate, new cost volumes are constructed iteratively on the pixelwise depth residual to perform depth map refinement. While sharing similar insight with Point-MVSNet as predicting and refining depth iteratively, we show that working on cost volume pyramid can lead to a more compact, yet efficient network structure compared with the Point-MVSNet on 3D points. We further provide detailed analyses of relation between (residual) depth sampling and image resolution, which serves as a principle for building compact cost volume pyramid. Experimental results on benchmark datasets show that our model can perform 6x faster and has similar performance as state-of-the-art methods.
Detection of Makeup Presentation Attacks based on Deep Face Representations
Jun 09, 2020

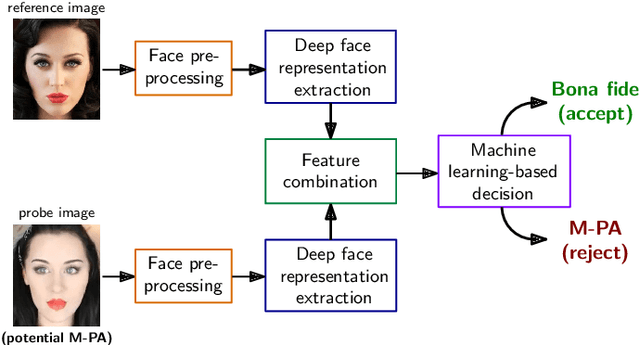
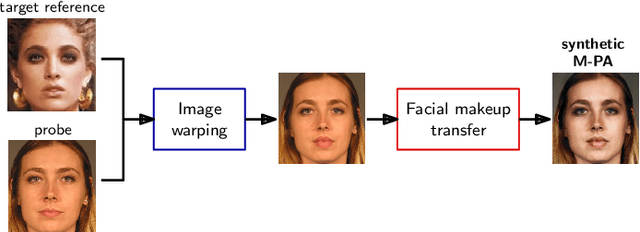
Facial cosmetics have the ability to substantially alter the facial appearance, which can negatively affect the decisions of a face recognition. In addition, it was recently shown that the application of makeup can be abused to launch so-called makeup presentation attacks. In such attacks, the attacker might apply heavy makeup in order to achieve the facial appearance of a target subject for the purpose of impersonation. In this work, we assess the vulnerability of a COTS face recognition system to makeup presentation attacks employing the publicly available Makeup Induced Face Spoofing (MIFS) database. It is shown that makeup presentation attacks might seriously impact the security of the face recognition system. Further, we propose an attack detection scheme which distinguishes makeup presentation attacks from genuine authentication attempts by analysing differences in deep face representations obtained from potential makeup presentation attacks and corresponding target face images. The proposed detection system employs a machine learning-based classifier, which is trained with synthetically generated makeup presentation attacks utilizing a generative adversarial network for facial makeup transfer in conjunction with image warping. Experimental evaluations conducted using the MIFS database reveal a detection equal error rate of 0.7% for the task of separating genuine authentication attempts from makeup presentation attacks.
Exploiting Image-trained CNN Architectures for Unconstrained Video Classification
May 08, 2015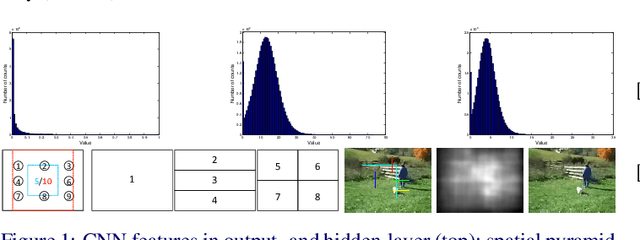
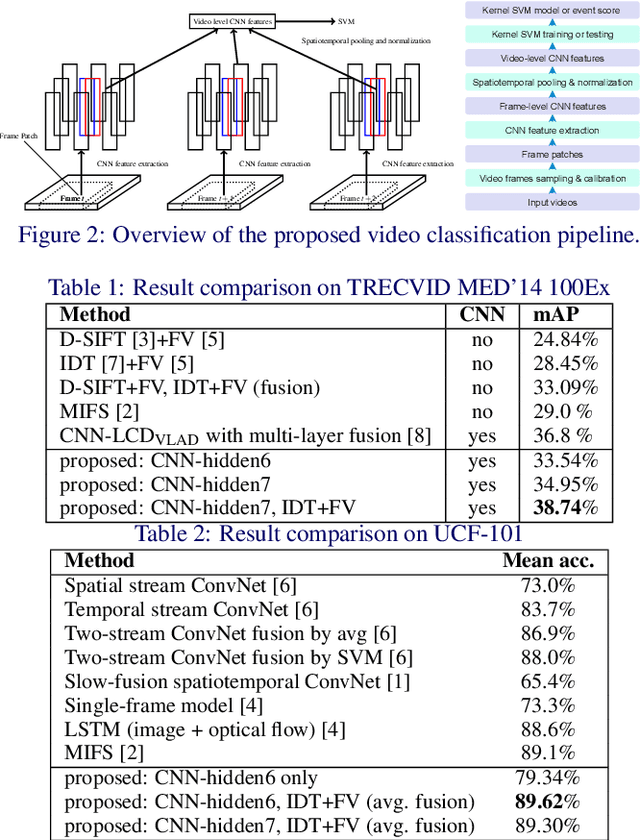
We conduct an in-depth exploration of different strategies for doing event detection in videos using convolutional neural networks (CNNs) trained for image classification. We study different ways of performing spatial and temporal pooling, feature normalization, choice of CNN layers as well as choice of classifiers. Making judicious choices along these dimensions led to a very significant increase in performance over more naive approaches that have been used till now. We evaluate our approach on the challenging TRECVID MED'14 dataset with two popular CNN architectures pretrained on ImageNet. On this MED'14 dataset, our methods, based entirely on image-trained CNN features, can outperform several state-of-the-art non-CNN models. Our proposed late fusion of CNN- and motion-based features can further increase the mean average precision (mAP) on MED'14 from 34.95% to 38.74%. The fusion approach achieves the state-of-the-art classification performance on the challenging UCF-101 dataset.
Globally Optimal Segmentation of Mutually Interacting Surfaces using Deep Learning
Jul 02, 2020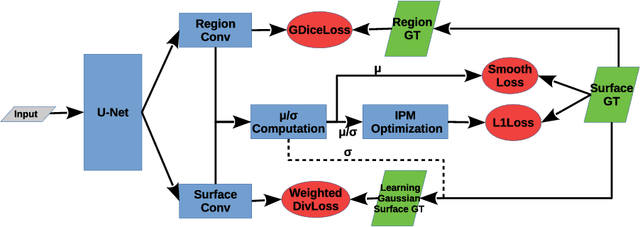
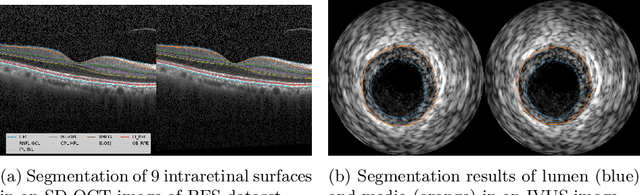
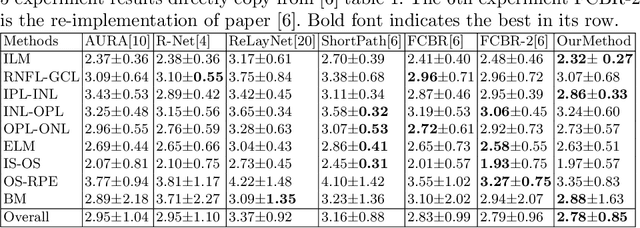

Segmentation of multiple surfaces in medical images is a challenging problem, further complicated by the frequent presence of weak boundary and mutual influence between adjacent objects. The traditional graph-based optimal surface segmentation method has proven its effectiveness with its ability of capturing various surface priors in a uniform graph model. However, its efficacy heavily relies on handcrafted features that are used to define the surface cost for the "goodness" of a surface. Recently, deep learning (DL) is emerging as powerful tools for medical image segmentation thanks to its superior feature learning capability. Unfortunately, due to the scarcity of training data in medical imaging, it is nontrivial for DL networks to implicitly learn the global structure of the target surfaces, including surface interactions. In this work, we propose to parameterize the surface cost functions in the graph model and leverage DL to learn those parameters. The multiple optimal surfaces are then simultaneously detected by minimizing the total surface cost while explicitly enforcing the mutual surface interaction constraints. The optimization problem is solved by the primal-dual Internal Point Method, which can be implemented by a layer of neural networks, enabling efficient end-to-end training of the whole network. Experiments on Spectral Domain Optical Coherence Tomography (SD-OCT) retinal layer segmentation and Intravascular Ultrasound (IVUS) vessel wall segmentation demonstrated very promising results. All source code is public to facilitate further research at this direction.
Stochastic Conditional Generative Networks with Basis Decomposition
Sep 25, 2019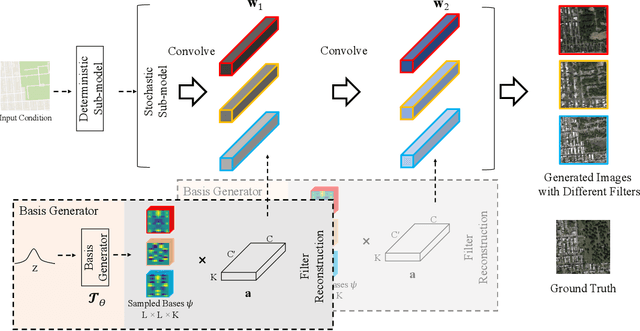
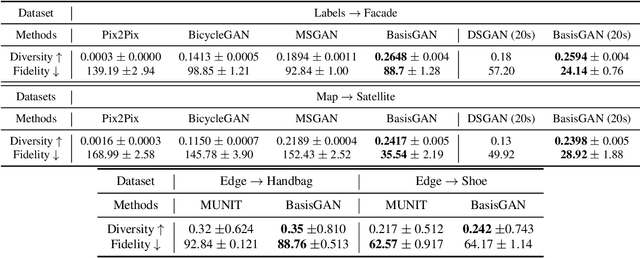


While generative adversarial networks (GANs) have revolutionized machine learning, a number of open questions remain to fully understand them and exploit their power. One of these questions is how to efficiently achieve proper diversity and sampling of the multi-mode data space. To address this, we introduce BasisGAN, a stochastic conditional multi-mode image generator. By exploiting the observation that a convolutional filter can be well approximated as a linear combination of a small set of basis elements, we learn a plug-and-played basis generator to stochastically generate basis elements, with just a few hundred of parameters, to fully embed stochasticity into convolutional filters. By sampling basis elements instead of filters, we dramatically reduce the cost of modeling the parameter space with no sacrifice on either image diversity or fidelity. To illustrate this proposed plug-and-play framework, we construct variants of BasisGAN based on state-of-the-art conditional image generation networks, and train the networks by simply plugging in a basis generator, without additional auxiliary components, hyperparameters, or training objectives. The experimental success is complemented with theoretical results indicating how the perturbations introduced by the proposed sampling of basis elements can propagate to the appearance of generated images.
Model Learning: Primal Dual Networks for Fast MR imaging
Aug 07, 2019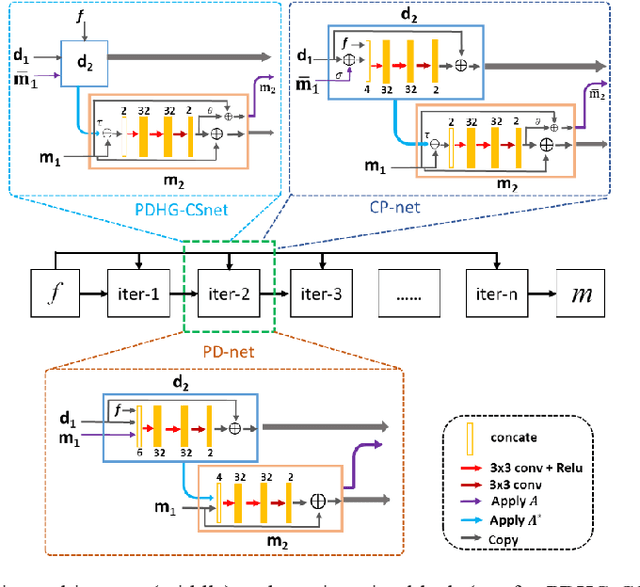
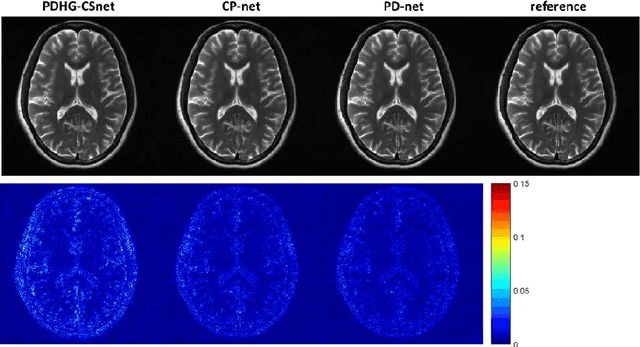
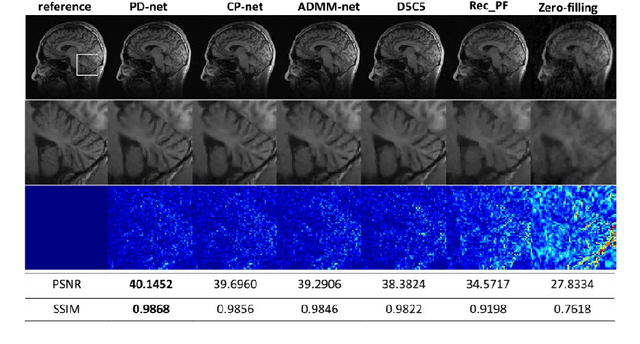
Magnetic resonance imaging (MRI) is known to be a slow imaging modality and undersampling in k-space has been used to increase the imaging speed. However, image reconstruction from undersampled k-space data is an ill-posed inverse problem. Iterative algorithms based on compressed sensing have been used to address the issue. In this work, we unroll the iterations of the primal-dual hybrid gradient algorithm to a learnable deep network architecture, and gradually relax the constraints to reconstruct MR images from highly undersampled k-space data. The proposed method combines the theoretical convergence guarantee of optimi-zation methods with the powerful learning capability of deep networks. As the constraints are gradually relaxed, the reconstruction model is finally learned from the training data by updating in k-space and image domain alternatively. Experi-ments on in vivo MR data demonstrate that the proposed method achieves supe-rior MR reconstructions from highly undersampled k-space data over other state-of-the-art image reconstruction methods.