 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Holistic Approach for Modeling and Synthesis of Image Processing Applications for Heterogeneous Computing Architectures
Feb 26, 2015
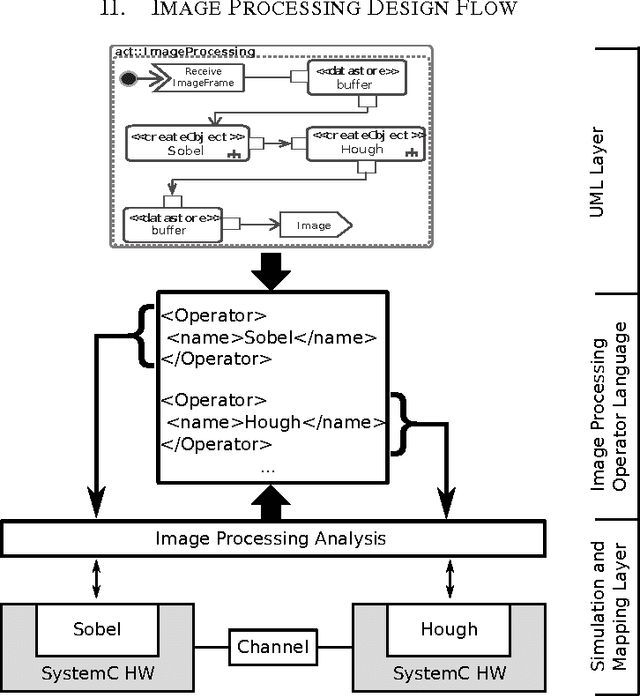
Image processing applications are common in every field of our daily life. However, most of them are very complex and contain several tasks with different complexities which result in varying requirements for computing architectures. Nevertheless, a general processing scheme in every image processing application has a similar structure, called image processing pipeline: (1) capturing an image, (2) pre-processing using local operators, (3) processing with global operators and (4) post-processing using complex operations. Therefore, application-specialized hardware solutions based on heterogeneous architectures are used for image processing. Unfortunately the development of applications for heterogeneous hardware architectures is challenging due to the distribution of computational tasks among processors and programmable logic units. Nowadays, image processing systems are started from scratch which is time-consuming, error-prone and inflexible. A new methodology for modeling and implementing is needed in order to reduce the development time of heterogenous image processing systems. This paper introduces a new holistic top down approach for image processing systems. Two challenges have to be investigated. First, designers ought to be able to model their complete image processing pipeline on an abstract layer using UML. Second, we want to close the gap between the abstract system and the system architecture.
Deep Plug-and-play Prior for Low-rank Tensor Completion
May 11, 2019
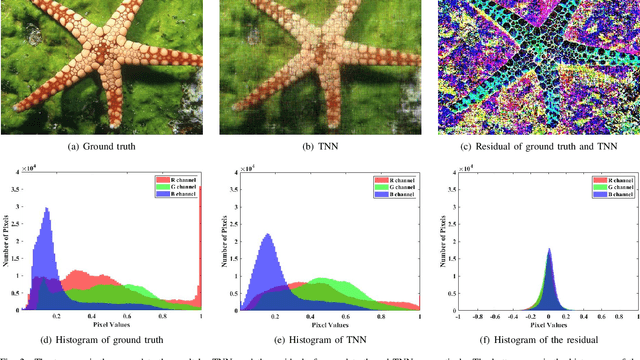


Tensor image data sets such as color images and multispectral images are highly correlated and they contain a lot of image details. The main aim of this paper is to propose and develop a regularized tensor completion model for tensor image data completion. In the objective function, we adopt the newly emerged tensor nuclear norm (TNN) to characterize the global structure of such tensor image data sets. Also, we formulate an implicit regularizer to plug in the convolutional neural network (CNN) denoiser, which is convinced to express the image prior learned from a large amount of natural images. The resulting model can be solved efficiently via an alternating directional method of multipliers algorithm. Experimental results (on color images, videos, and multispectral images) are presented to show that both image global structure and details can be recovered very well, and to illustrate that the performance of the proposed method is better than that of testing methods in terms of PSNR and SSIM.
Visual Agreement Regularized Training for Multi-Modal Machine Translation
Dec 27, 2019
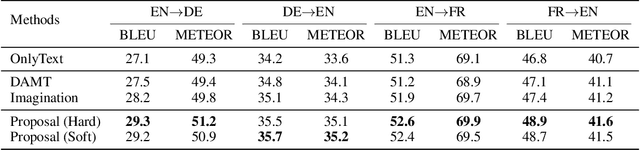
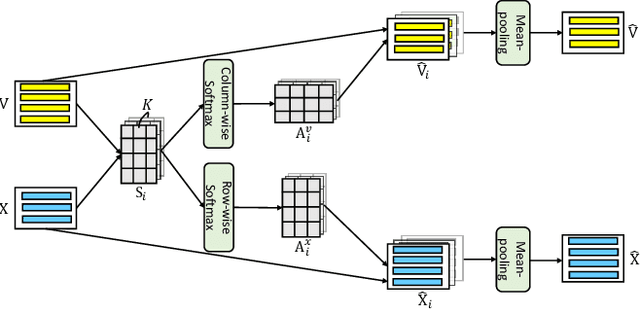
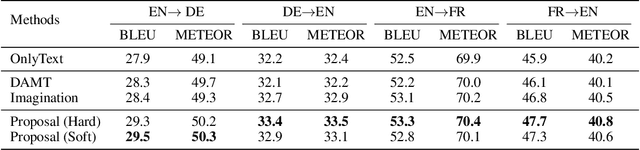
Multi-modal machine translation aims at translating the source sentence into a different language in the presence of the paired image. Previous work suggests that additional visual information only provides dispensable help to translation, which is needed in several very special cases such as translating ambiguous words. To make better use of visual information, this work presents visual agreement regularized training. The proposed approach jointly trains the source-to-target and target-to-source translation models and encourages them to share the same focus on the visual information when generating semantically equivalent visual words (e.g. "ball" in English and "ballon" in French). Besides, a simple yet effective multi-head co-attention model is also introduced to capture interactions between visual and textual features. The results show that our approaches can outperform competitive baselines by a large margin on the Multi30k dataset. Further analysis demonstrates that the proposed regularized training can effectively improve the agreement of attention on the image, leading to better use of visual information.
Multiple Sclerosis Lesion Activity Segmentation with Attention-Guided Two-Path CNNs
Aug 05, 2020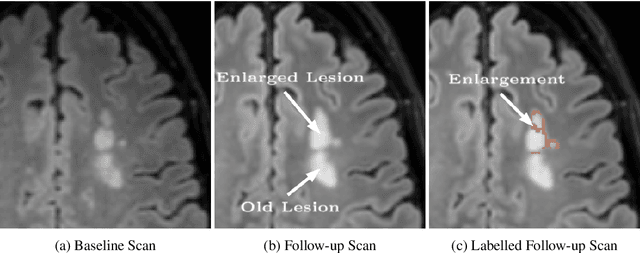
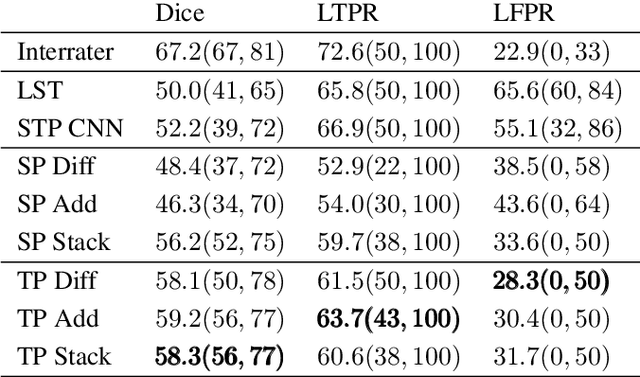
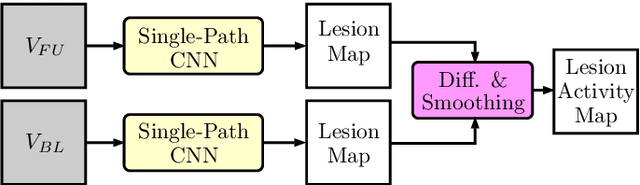
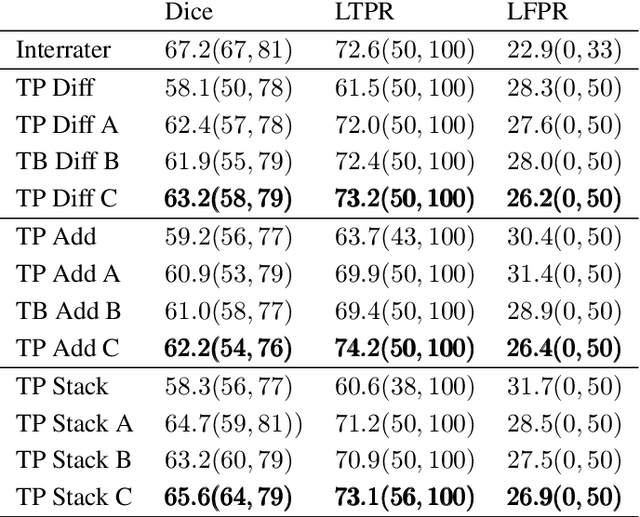
Multiple sclerosis is an inflammatory autoimmune demyelinating disease that is characterized by lesions in the central nervous system. Typically, magnetic resonance imaging (MRI) is used for tracking disease progression. Automatic image processing methods can be used to segment lesions and derive quantitative lesion parameters. So far, methods have focused on lesion segmentation for individual MRI scans. However, for monitoring disease progression, \textit{lesion activity} in terms of new and enlarging lesions between two time points is a crucial biomarker. For this problem, several classic methods have been proposed, e.g., using difference volumes. Despite their success for single-volume lesion segmentation, deep learning approaches are still rare for lesion activity segmentation. In this work, convolutional neural networks (CNNs) are studied for lesion activity segmentation from two time points. For this task, CNNs are designed and evaluated that combine the information from two points in different ways. In particular, two-path architectures with attention-guided interactions are proposed that enable effective information exchange between the two time point's processing paths. It is demonstrated that deep learning-based methods outperform classic approaches and it is shown that attention-guided interactions significantly improve performance. Furthermore, the attention modules produce plausible attention maps that have a masking effect that suppresses old, irrelevant lesions. A lesion-wise false positive rate of 26.4% is achieved at a true positive rate of 74.2%, which is not significantly different from the interrater performance.
Active Contour Models for Manifold Valued Image Segmentation
Nov 11, 2013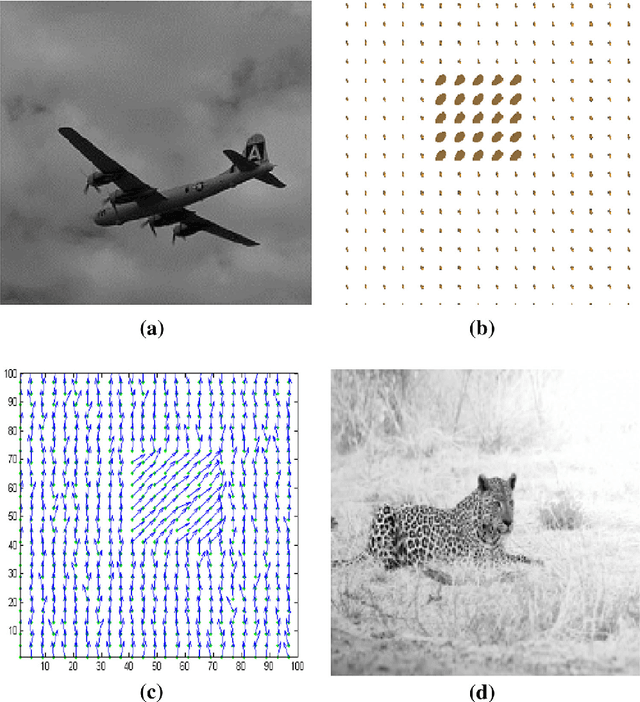
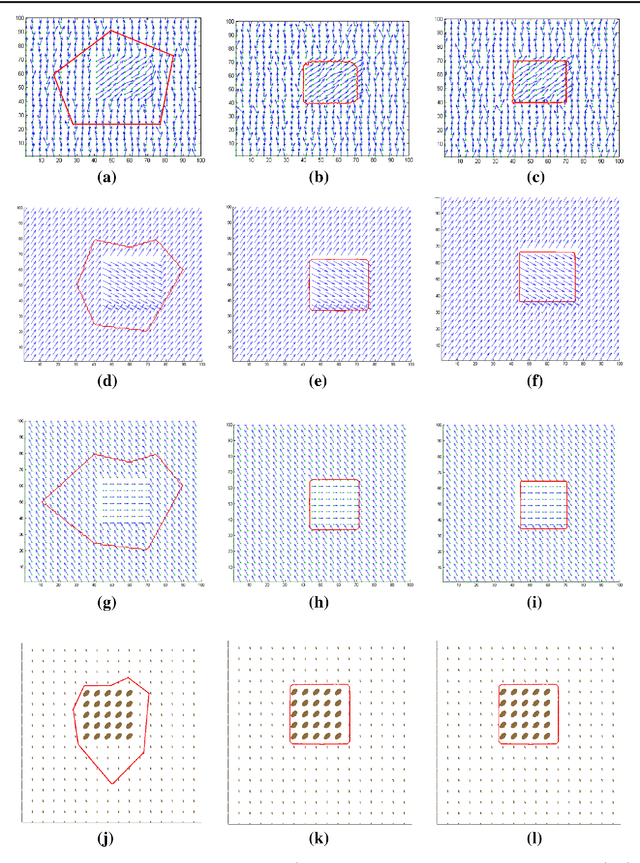
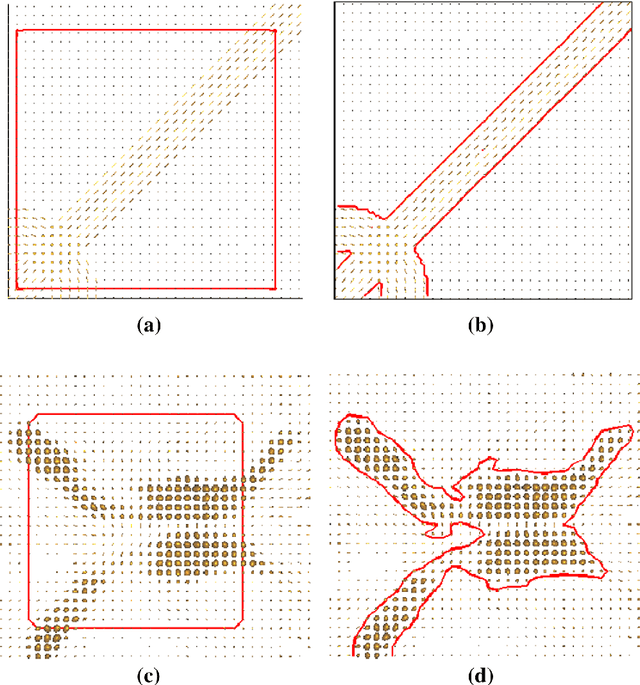
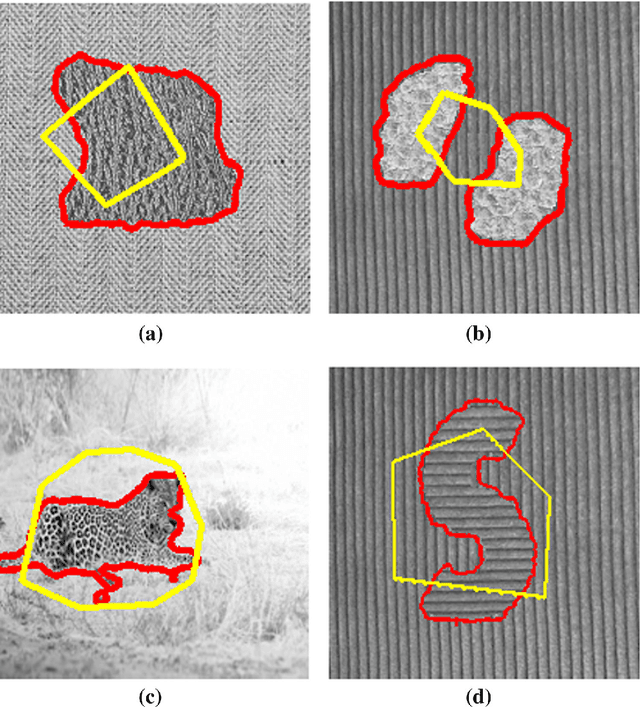
Image segmentation is the process of partitioning a image into different regions or groups based on some characteristics like color, texture, motion or shape etc. Active contours is a popular variational method for object segmentation in images, in which the user initializes a contour which evolves in order to optimize an objective function designed such that the desired object boundary is the optimal solution. Recently, imaging modalities that produce Manifold valued images have come up, for example, DT-MRI images, vector fields. The traditional active contour model does not work on such images. In this paper, we generalize the active contour model to work on Manifold valued images. As expected, our algorithm detects regions with similar Manifold values in the image. Our algorithm also produces expected results on usual gray-scale images, since these are nothing but trivial examples of Manifold valued images. As another application of our general active contour model, we perform texture segmentation on gray-scale images by first creating an appropriate Manifold valued image. We demonstrate segmentation results for manifold valued images and texture images.
Distributed Evolution of Deep Autoencoders
Apr 16, 2020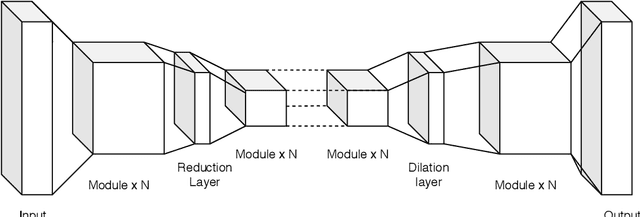
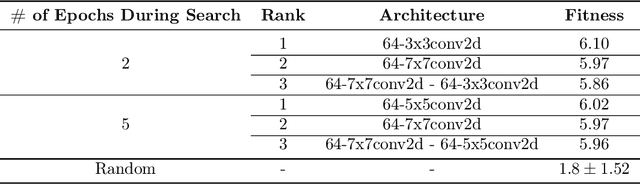

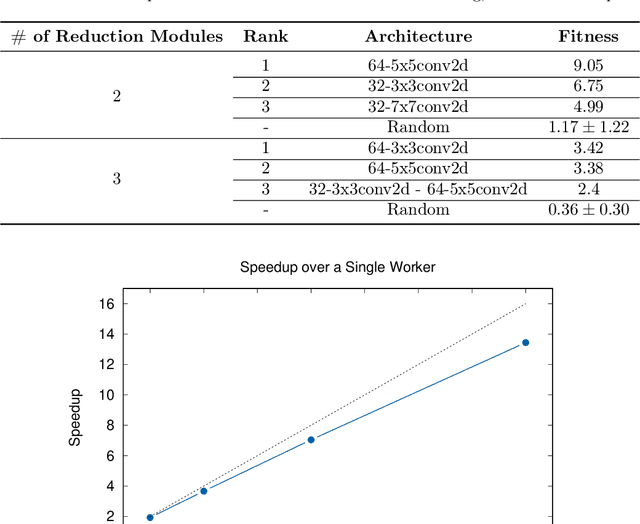
Autoencoders have seen wide success in domains ranging from feature selection to information retrieval. Despite this success, designing an autoencoder for a given task remains a challenging undertaking due to the lack of firm intuition on how the backing neural network architectures of the encoder and decoder impact the overall performance of the autoencoder. In this work we present a distributed system that uses an efficient evolutionary algorithm to design a modular autoencoder. We demonstrate the effectiveness of this system on the tasks of manifold learning and image denoising. The system beats random search by nearly an order of magnitude on both tasks while achieving near linear horizontal scaling as additional worker nodes are added to the system.
An Abstraction Model for Semantic Segmentation Algorithms
Dec 27, 2019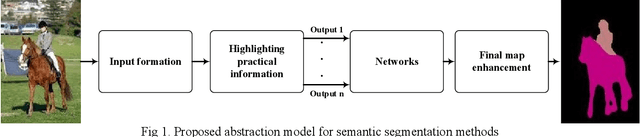
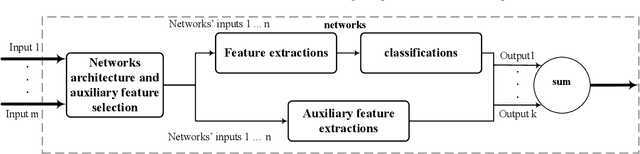
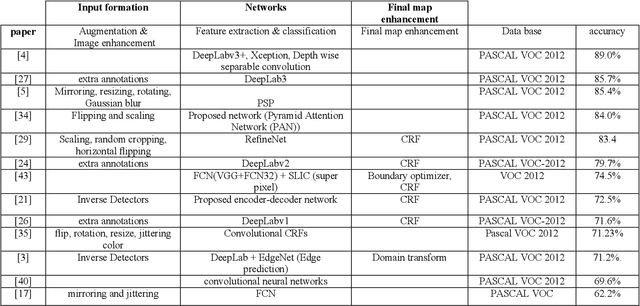
Semantic segmentation is a process of classifying each pixel in the image. Due to its advantages, sematic segmentation is used in many tasks such as cancer detection, robot-assisted surgery, satellite image analysis, self-driving car control, etc. In this process, accuracy and efficiency are the two crucial goals for this purpose, and there are several state of the art neural networks. In each method, by employing different techniques, new solutions have been presented for increasing efficiency, accuracy, and reducing the costs. The diversity of the implemented approaches for semantic segmentation makes it difficult for researches to achieve a comprehensive view of the field. To offer a comprehensive view, in this paper, an abstraction model for the task of semantic segmentation is offered. The proposed framework consists of four general blocks that cover the majority of majority of methods that have been proposed for semantic segmentation. We also compare different approaches and consider the importance of each part in the overall performance of a method.
AE TextSpotter: Learning Visual and Linguistic Representation for Ambiguous Text Spotting
Aug 05, 2020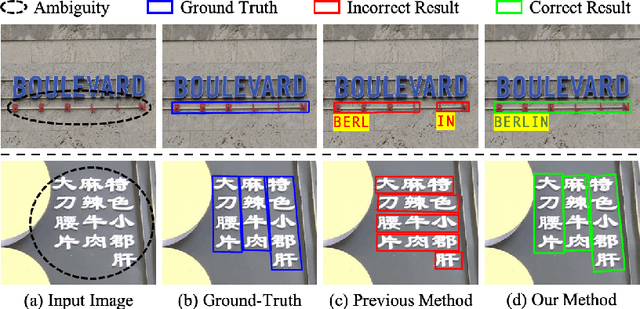
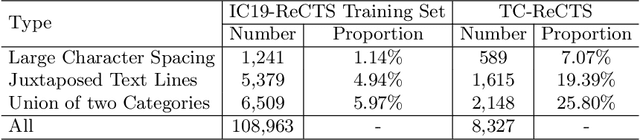

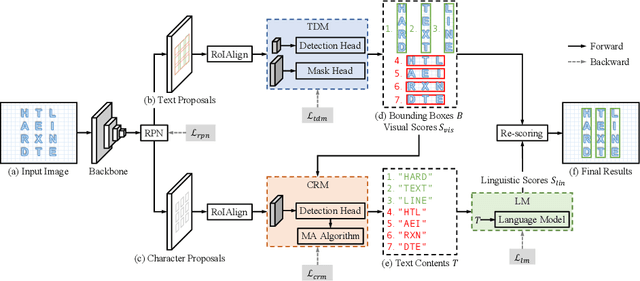
Scene text spotting aims to detect and recognize the entire word or sentence with multiple characters in natural images. It is still challenging because ambiguity often occurs when the spacing between characters is large or the characters are evenly spread in multiple rows and columns, making many visually plausible groupings of the characters (e.g. "BERLIN" is incorrectly detected as "BERL" and "IN" in Fig. 1(c)). Unlike previous works that merely employed visual features for text detection, this work proposes a novel text spotter, named Ambiguity Eliminating Text Spotter (AE TextSpotter), which learns both visual and linguistic features to significantly reduce ambiguity in text detection. The proposed AE TextSpotter has three important benefits. 1) The linguistic representation is learned together with the visual representation in a framework. To our knowledge, it is the first time to improve text detection by using a language model. 2) A carefully designed language module is utilized to reduce the detection confidence of incorrect text lines, making them easily pruned in the detection stage. 3) Extensive experiments show that AE TextSpotter outperforms other state-of-the-art methods by a large margin. For example, we carefully select a validation set of extremely ambiguous samples from the IC19-ReCTS dataset, where our approach surpasses other methods by more than 4%. The image list and evaluation scripts of the validation set have been released at https://github.com/whai362/TDA-ReCTS.
News Cover Assessment via Multi-task Learning
Jul 18, 2019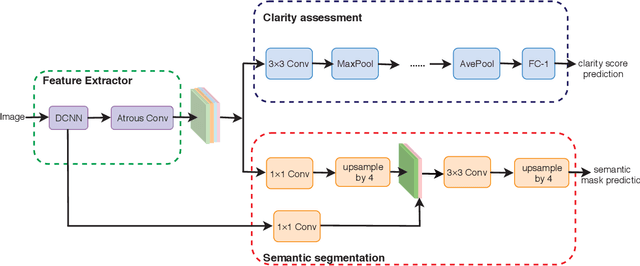



Online personalized news product needs a suitable cover for the article. The news cover demands to be with high image quality, and draw readers' attention at same time, which is extraordinary challenging due to the subjectivity of the task. In this paper, we assess the news cover from image clarity and object salience perspective. We propose an end-to-end multi-task learning network for image clarity assessment and semantic segmentation simultaneously, the results of which can be guided for news cover assessment. The proposed network is based on a modified DeepLabv3+ model. The network backbone is used for multiple scale spatial features exaction, followed by two branches for image clarity assessment and semantic segmentation, respectively. The experiment results show that the proposed model is able to capture important content in images and performs better than single-task learning baselines on our proposed game content based CIA dataset.
To complete or to estimate, that is the question: A Multi-Task Approach to Depth Completion and Monocular Depth Estimation
Aug 15, 2019
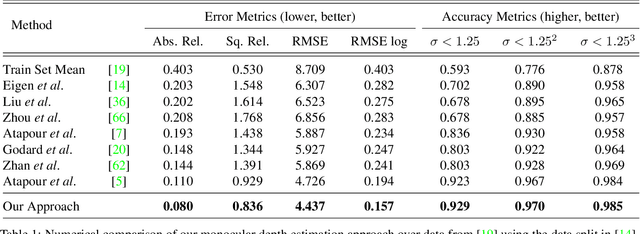
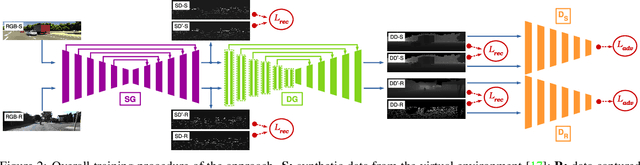
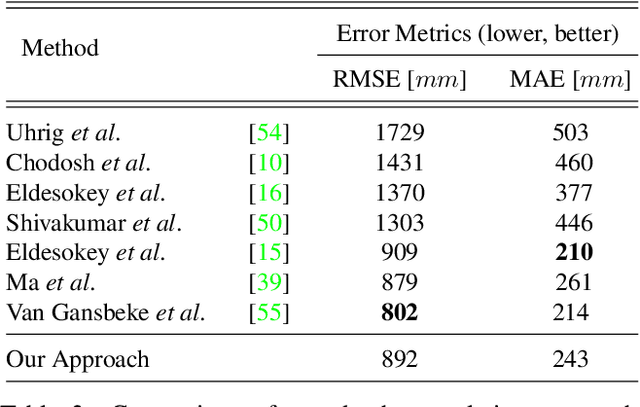
Robust three-dimensional scene understanding is now an ever-growing area of research highly relevant in many real-world applications such as autonomous driving and robotic navigation. In this paper, we propose a multi-task learning-based model capable of performing two tasks:- sparse depth completion (i.e. generating complete dense scene depth given a sparse depth image as the input) and monocular depth estimation (i.e. predicting scene depth from a single RGB image) via two sub-networks jointly trained end to end using data randomly sampled from a publicly available corpus of synthetic and real-world images. The first sub-network generates a sparse depth image by learning lower level features from the scene and the second predicts a full dense depth image of the entire scene, leading to a better geometric and contextual understanding of the scene and, as a result, superior performance of the approach. The entire model can be used to infer complete scene depth from a single RGB image or the second network can be used alone to perform depth completion given a sparse depth input. Using adversarial training, a robust objective function, a deep architecture relying on skip connections and a blend of synthetic and real-world training data, our approach is capable of producing superior high quality scene depth. Extensive experimental evaluation demonstrates the efficacy of our approach compared to contemporary state-of-the-art techniques across both problem domains.