 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HoughNet: Integrating near and long-range evidence for bottom-up object detection
Jul 05, 2020

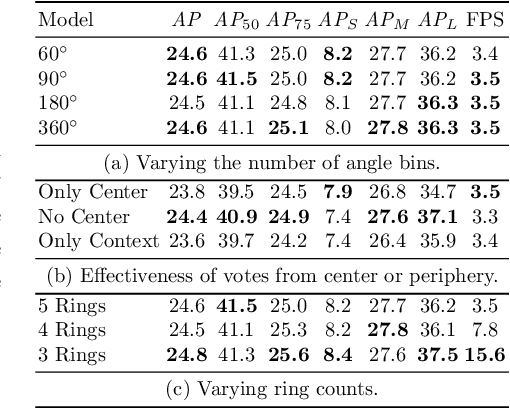
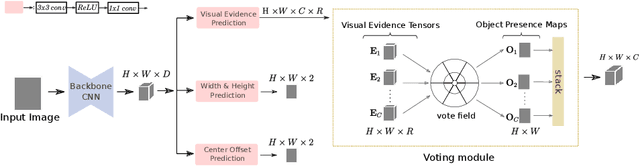
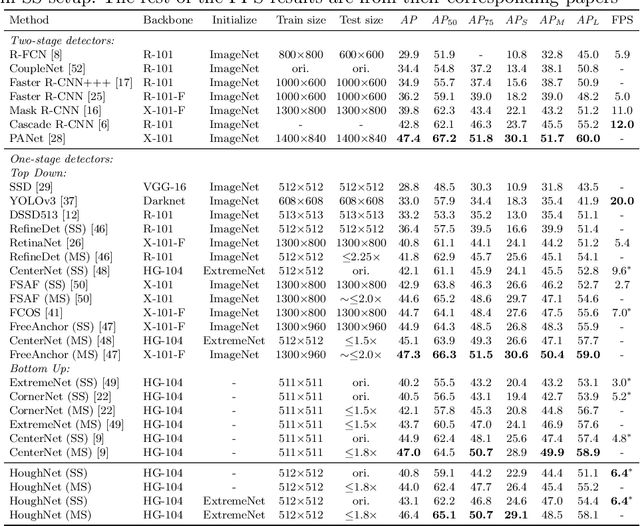
This paper presents HoughNet, a one-stage, anchor-free, voting-based, bottom-up object detection method. Inspired by the Generalized Hough Transform, HoughNet determines the presence of an object at a certain location by the sum of the votes cast on that location. Votes are collected from both near and long-distance locations based on a log-polar vote field. Thanks to this voting mechanism, HoughNet is able to integrate both near and long-range, class-conditional evidence for visual recognition, thereby generalizing and enhancing current object detection methodology, which typically relies on only local evidence. On the COCO dataset, HoughNet achieves 46.4 AP (and 65.1 AP_50), performing on par with the state-of-the-art in bottom-up object detection and outperforming most major one-stage and two-stage methods. We further validate the effectiveness of our proposal in another task, namely, "labels to photo" image generation by integrating the voting module of HoughNet to two different GAN models and showing that the accuracy is significantly improved in both cases. Code is available at: https://github.com/nerminsamet/houghnet
$Σ$-net: Ensembled Iterative Deep Neural Networks for Accelerated Parallel MR Image Reconstruction
Dec 11, 2019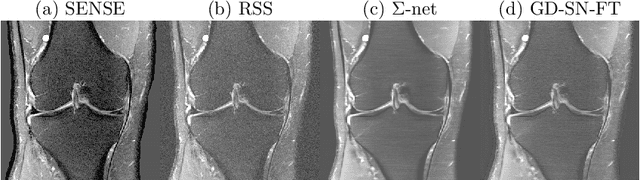
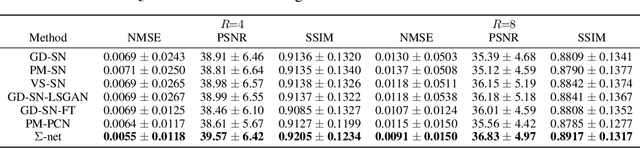
We explore an ensembled $\Sigma$-net for fast parallel MR imaging, including parallel coil networks, which perform implicit coil weighting, and sensitivity networks, involving explicit sensitivity maps. The networks in $\Sigma$-net are trained in a supervised way, including content and GAN losses, and with various ways of data consistency, i.e., proximal mappings, gradient descent and variable splitting. A semi-supervised finetuning scheme allows us to adapt to the k-space data at test time, which, however, decreases the quantitative metrics, although generating the visually most textured and sharp images. For this challenge, we focused on robust and high SSIM scores, which we achieved by ensembling all models to a $\Sigma$-net.
Incorporating Textual Evidence in Visual Storytelling
Nov 21, 2019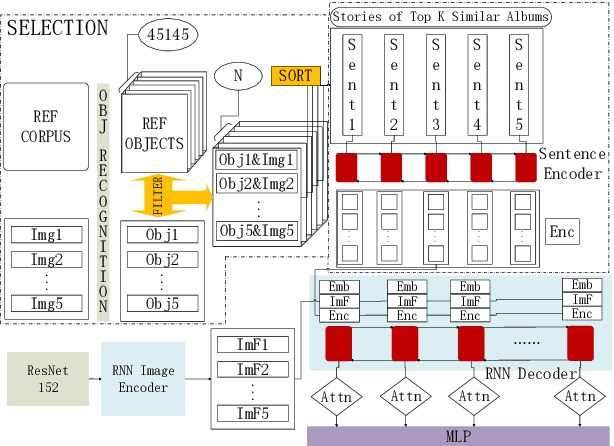
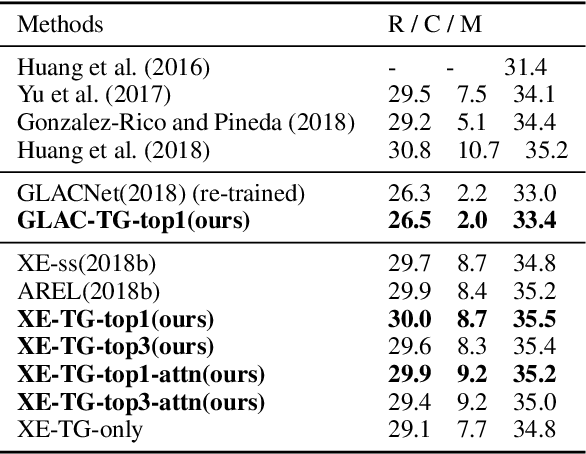
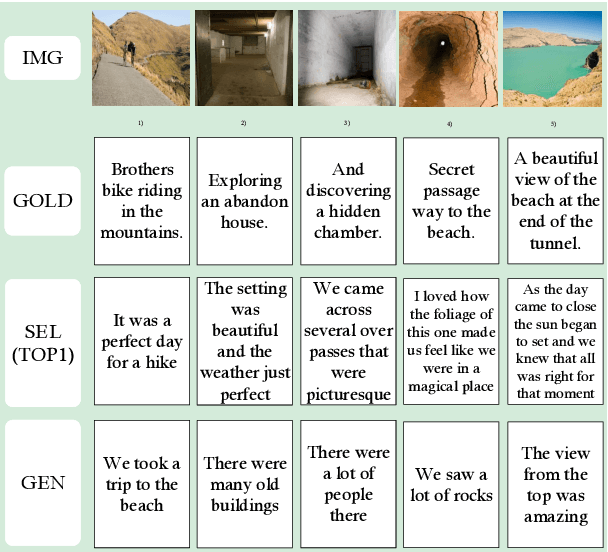
Previous work on visual storytelling mainly focused on exploring image sequence as evidence for storytelling and neglected textual evidence for guiding story generation. Motivated by human storytelling process which recalls stories for familiar images, we exploit textual evidence from similar images to help generate coherent and meaningful stories. To pick the images which may provide textual experience, we propose a two-step ranking method based on image object recognition techniques. To utilize textual information, we design an extended Seq2Seq model with two-channel encoder and attention. Experiments on the VIST dataset show that our method outperforms state-of-the-art baseline models without heavy engineering.
MetaPoison: Practical General-purpose Clean-label Data Poisoning
Apr 01, 2020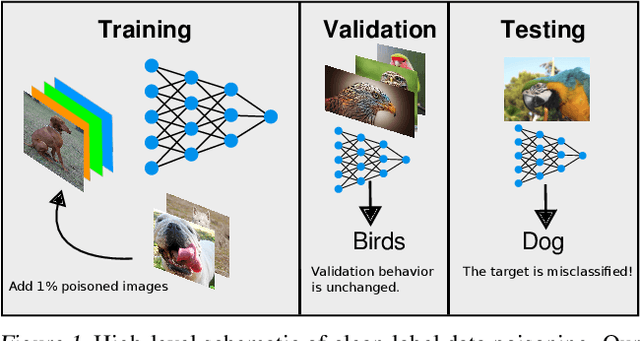
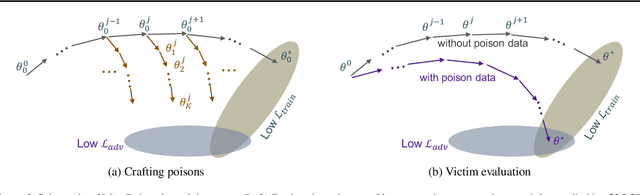
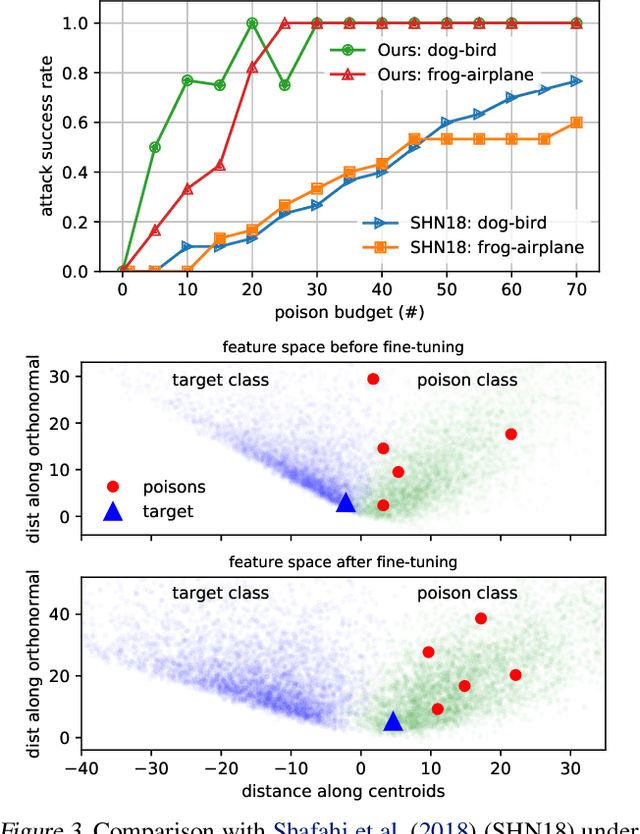
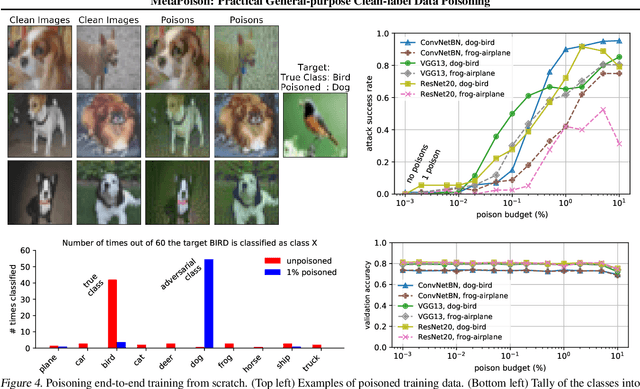
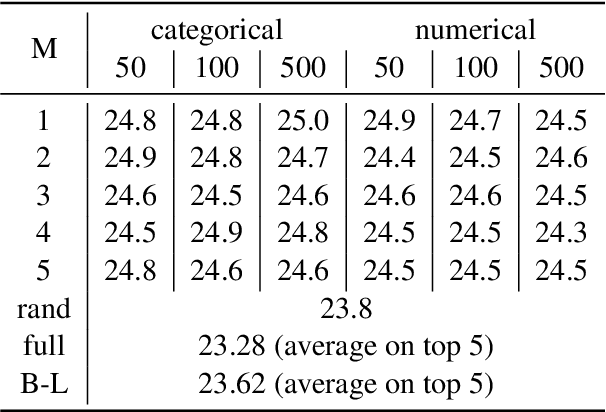
Data poisoning--the process by which an attacker takes control of a model by making imperceptible changes to a subset of the training data--is an emerging threat in the context of neural networks. Existing attacks for data poisoning have relied on hand-crafted heuristics. Instead, we pose crafting poisons more generally as a bi-level optimization problem, where the inner level corresponds to training a network on a poisoned dataset and the outer level corresponds to updating those poisons to achieve a desired behavior on the trained model. We then propose MetaPoison, a first-order method to solve this optimization quickly. MetaPoison is effective: it outperforms previous clean-label poisoning methods by a large margin under the same setting. MetaPoison is robust: its poisons transfer to a variety of victims with unknown hyperparameters and architectures. MetaPoison is also general-purpose, working not only in fine-tuning scenarios, but also for end-to-end training from scratch with remarkable success, e.g. causing a target image to be misclassified 90% of the time via manipulating just 1% of the dataset. Additionally, MetaPoison can achieve arbitrary adversary goals not previously possible--like using poisons of one class to make a target image don the label of another arbitrarily chosen class. Finally, MetaPoison works in the real-world. We demonstrate successful data poisoning of models trained on Google Cloud AutoML Vision. Code and premade poisons are provided at https://github.com/wronnyhuang/metapoison
BiHand: Recovering Hand Mesh with Multi-stage Bisected Hourglass Networks
Aug 12, 20203D hand estimation has been a long-standing research topic in computer vision. A recent trend aims not only to estimate the 3D hand joint locations but also to recover the mesh model. However, achieving those goals from a single RGB image remains challenging. In this paper, we introduce an end-to-end learnable model, BiHand, which consists of three cascaded stages, namely 2D seeding stage, 3D lifting stage, and mesh generation stage. At the output of BiHand, the full hand mesh will be recovered using the joint rotations and shape parameters predicted from the network. Inside each stage, BiHand adopts a novel bisecting design which allows the networks to encapsulate two closely related information (e.g. 2D keypoints and silhouette in 2D seeding stage, 3D joints, and depth map in 3D lifting stage, joint rotations and shape parameters in the mesh generation stage) in a single forward pass. As the information represents different geometry or structure details, bisecting the data flow can facilitate optimization and increase robustness. For quantitative evaluation, we conduct experiments on two public benchmarks, namely the Rendered Hand Dataset (RHD) and the Stereo Hand Pose Tracking Benchmark (STB). Extensive experiments show that our model can achieve superior accuracy in comparison with state-of-the-art methods, and can produce appealing 3D hand meshes in several severe conditions.
A Neuro-AI Interface for Evaluating Generative Adversarial Networks
Mar 05, 2020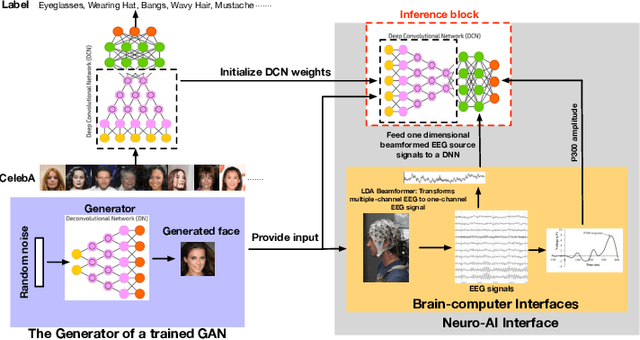
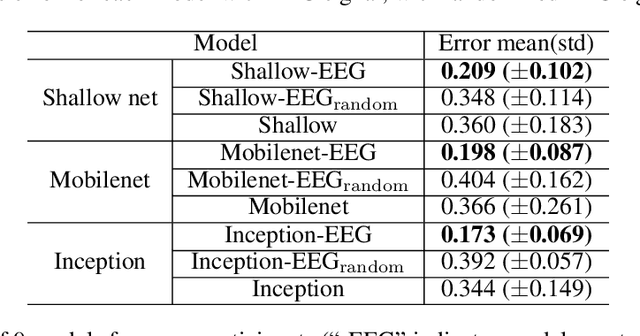
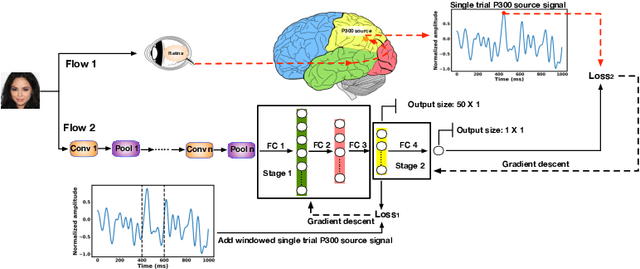
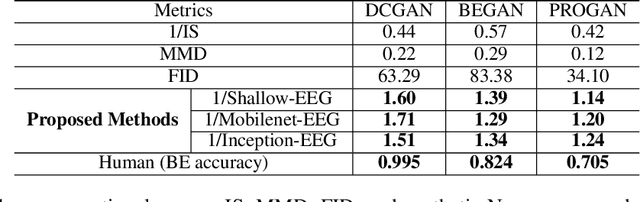
Generative adversarial networks (GANs) are increasingly attracting attention in the computer vision, natural language processing, speech synthesis and similar domains. However, evaluating the performance of GANs is still an open and challenging problem. Existing evaluation metrics primarily measure the dissimilarity between real and generated images using automated statistical methods. They often require large sample sizes for evaluation and do not directly reflect human perception of image quality. In this work, we introduce an evaluation metric called Neuroscore, for evaluating the performance of GANs, that more directly reflects psychoperceptual image quality through the utilization of brain signals. Our results show that Neuroscore has superior performance to the current evaluation metrics in that: (1) It is more consistent with human judgment; (2) The evaluation process needs much smaller numbers of samples; and (3) It is able to rank the quality of images on a per GAN basis. A convolutional neural network (CNN) based neuro-AI interface is proposed to predict Neuroscore from GAN-generated images directly without the need for neural responses. Importantly, we show that including neural responses during the training phase of the network can significantly improve the prediction capability of the proposed model. Codes and data can be referred at this link: https://github.com/villawang/Neuro-AI-Interface.
A Practical Guide to CNNs and Fisher Vectors for Image Instance Retrieval
Aug 25, 2015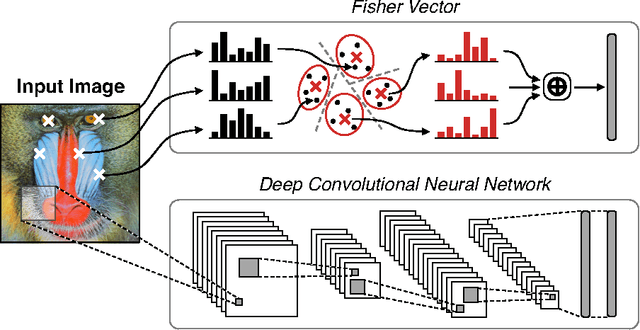
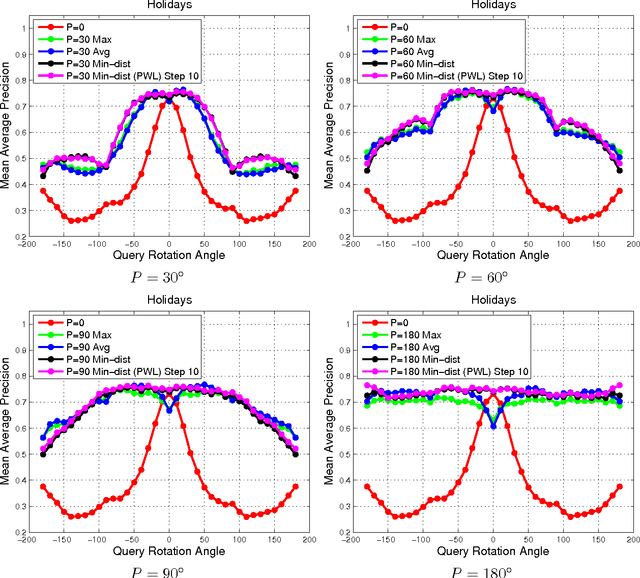
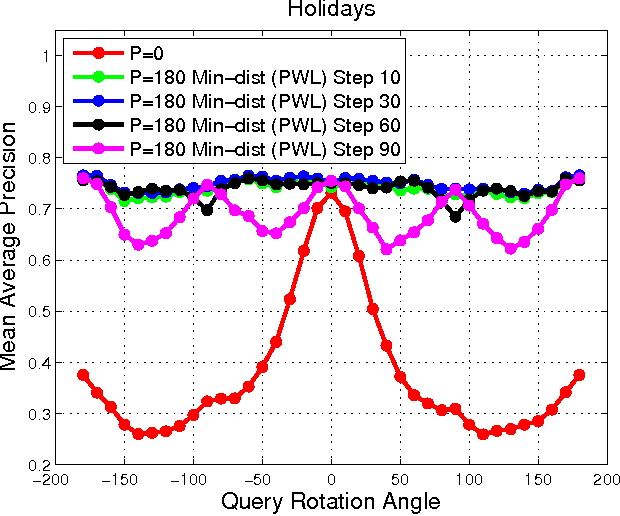
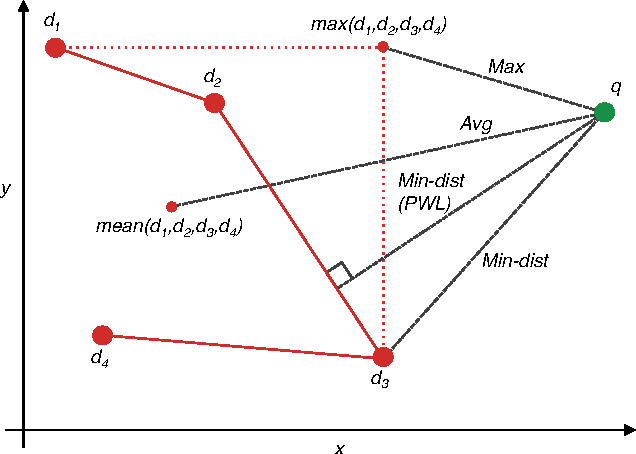
With deep learning becoming the dominant approach in computer vision, the use of representations extracted from Convolutional Neural Nets (CNNs) is quickly gaining ground on Fisher Vectors (FVs) as favoured state-of-the-art global image descriptors for image instance retrieval. While the good performance of CNNs for image classification are unambiguously recognised, which of the two has the upper hand in the image retrieval context is not entirely clear yet. In this work, we propose a comprehensive study that systematically evaluates FVs and CNNs for image retrieval. The first part compares the performances of FVs and CNNs on multiple publicly available data sets. We investigate a number of details specific to each method. For FVs, we compare sparse descriptors based on interest point detectors with dense single-scale and multi-scale variants. For CNNs, we focus on understanding the impact of depth, architecture and training data on retrieval results. Our study shows that no descriptor is systematically better than the other and that performance gains can usually be obtained by using both types together. The second part of the study focuses on the impact of geometrical transformations such as rotations and scale changes. FVs based on interest point detectors are intrinsically resilient to such transformations while CNNs do not have a built-in mechanism to ensure such invariance. We show that performance of CNNs can quickly degrade in presence of rotations while they are far less affected by changes in scale. We then propose a number of ways to incorporate the required invariances in the CNN pipeline. Overall, our work is intended as a reference guide offering practically useful and simply implementable guidelines to anyone looking for state-of-the-art global descriptors best suited to their specific image instance retrieval problem.
Explaining The Behavior Of Black-Box Prediction Algorithms With Causal Learning
Jun 03, 2020


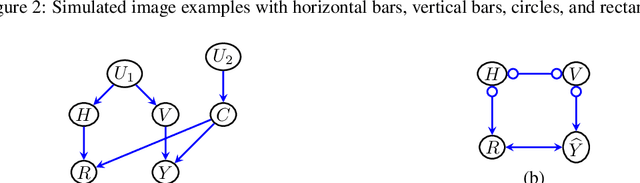
We propose to explain the behavior of black-box prediction methods (e.g., deep neural networks trained on image pixel data) using causal graphical models. Specifically, we explore learning the structure of a causal graph where the nodes represent prediction outcomes along with a set of macro-level "interpretable" features, while allowing for arbitrary unmeasured confounding among these variables. The resulting graph may indicate which of the interpretable features, if any, are possible causes of the prediction outcome and which may be merely associated with prediction outcomes due to confounding. The approach is motivated by a counterfactual theory of causal explanation wherein good explanations point to factors which are "difference-makers" in an interventionist sense. The resulting analysis may be useful in algorithm auditing and evaluation, by identifying features which make a causal difference to the algorithm's output.
Auto-pooling: Learning to Improve Invariance of Image Features from Image Sequences
Mar 18, 2013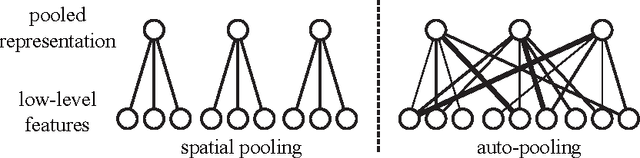
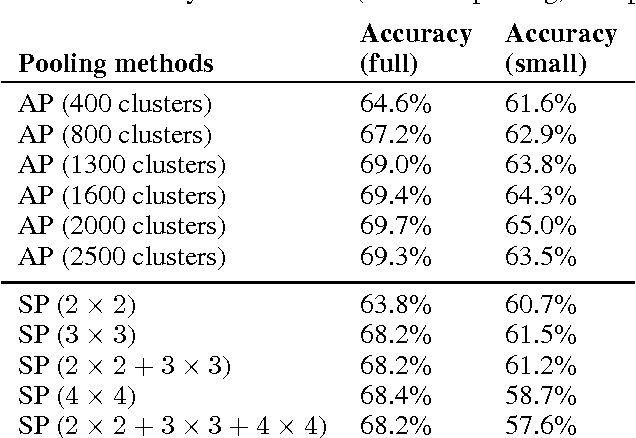
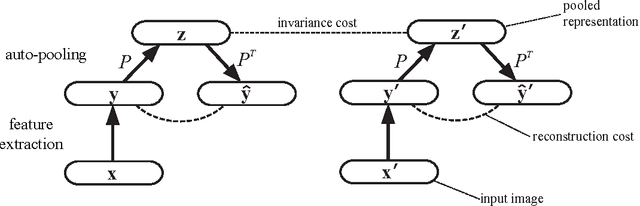
Learning invariant representations from images is one of the hardest challenges facing computer vision. Spatial pooling is widely used to create invariance to spatial shifting, but it is restricted to convolutional models. In this paper, we propose a novel pooling method that can learn soft clustering of features from image sequences. It is trained to improve the temporal coherence of features, while keeping the information loss at minimum. Our method does not use spatial information, so it can be used with non-convolutional models too. Experiments on images extracted from natural videos showed that our method can cluster similar features together. When trained by convolutional features, auto-pooling outperformed traditional spatial pooling on an image classification task, even though it does not use the spatial topology of features.
A Picture is Worth a Billion Bits: Real-Time Image Reconstruction from Dense Binary Pixels
Dec 05, 2015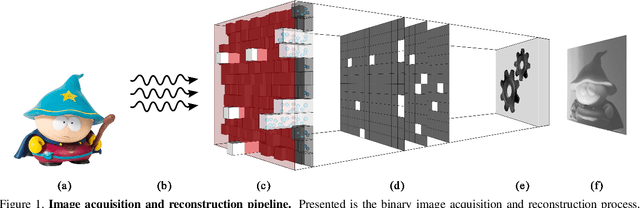
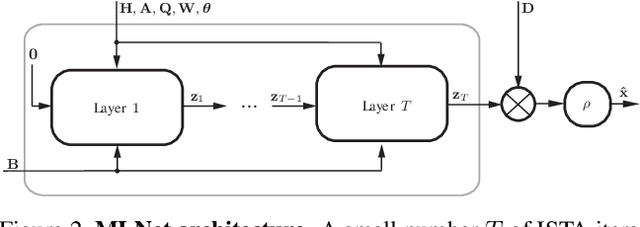
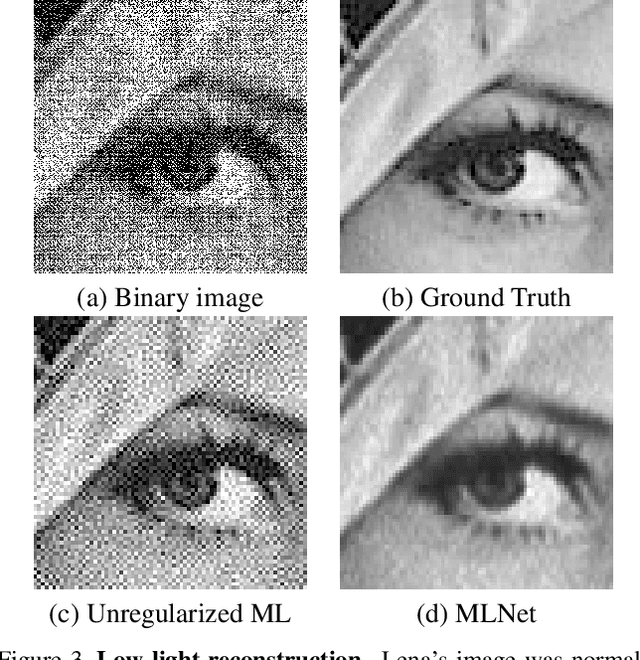
The pursuit of smaller pixel sizes at ever increasing resolution in digital image sensors is mainly driven by the stringent price and form-factor requirements of sensors and optics in the cellular phone market. Recently, Eric Fossum proposed a novel concept of an image sensor with dense sub-diffraction limit one-bit pixels jots, which can be considered a digital emulation of silver halide photographic film. This idea has been recently embodied as the EPFL Gigavision camera. A major bottleneck in the design of such sensors is the image reconstruction process, producing a continuous high dynamic range image from oversampled binary measurements. The extreme quantization of the Poisson statistics is incompatible with the assumptions of most standard image processing and enhancement frameworks. The recently proposed maximum-likelihood (ML) approach addresses this difficulty, but suffers from image artifacts and has impractically high computational complexity. In this work, we study a variant of a sensor with binary threshold pixels and propose a reconstruction algorithm combining an ML data fitting term with a sparse synthesis prior. We also show an efficient hardware-friendly real-time approximation of this inverse operator.Promising results are shown on synthetic data as well as on HDR data emulated using multiple exposures of a regular CMOS sensor.