 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning-Based Grading of Ductal Carcinoma In Situ in Breast Histopathology Images
Oct 07, 2020
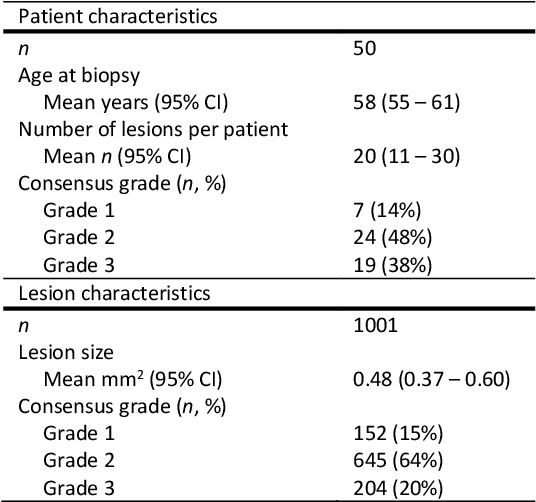
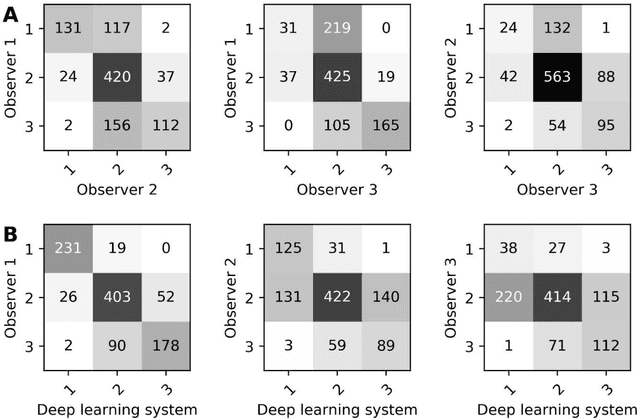
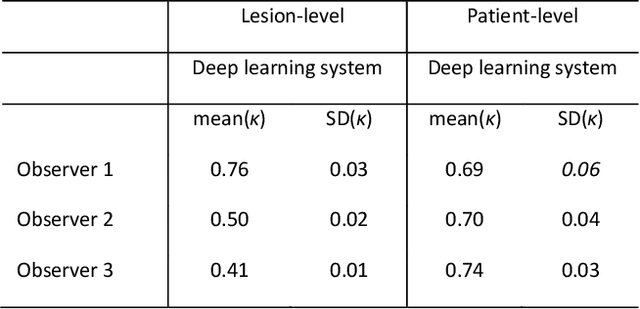
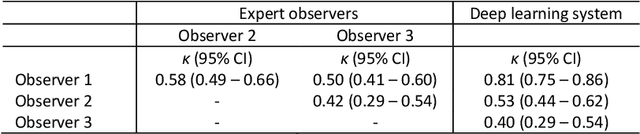
Ductal carcinoma in situ (DCIS) is a non-invasive breast cancer that can progress into invasive ductal carcinoma (IDC). Studies suggest DCIS is often overtreated since a considerable part of DCIS lesions may never progress into IDC. Lower grade lesions have a lower progression speed and risk, possibly allowing treatment de-escalation. However, studies show significant inter-observer variation in DCIS grading. Automated image analysis may provide an objective solution to address high subjectivity of DCIS grading by pathologists. In this study, we developed a deep learning-based DCIS grading system. It was developed using the consensus DCIS grade of three expert observers on a dataset of 1186 DCIS lesions from 59 patients. The inter-observer agreement, measured by quadratic weighted Cohen's kappa, was used to evaluate the system and compare its performance to that of expert observers. We present an analysis of the lesion-level and patient-level inter-observer agreement on an independent test set of 1001 lesions from 50 patients. The deep learning system (dl) achieved on average slightly higher inter-observer agreement to the observers (o1, o2 and o3) ($\kappa_{o1,dl}=0.81, \kappa_{o2,dl}=0.53, \kappa_{o3,dl}=0.40$) than the observers amongst each other ($\kappa_{o1,o2}=0.58, \kappa_{o1,o3}=0.50, \kappa_{o2,o3}=0.42$) at the lesion-level. At the patient-level, the deep learning system achieved similar agreement to the observers ($\kappa_{o1,dl}=0.77, \kappa_{o2,dl}=0.75, \kappa_{o3,dl}=0.70$) as the observers amongst each other ($\kappa_{o1,o2}=0.77, \kappa_{o1,o3}=0.75, \kappa_{o2,o3}=0.72$). In conclusion, we developed a deep learning-based DCIS grading system that achieved a performance similar to expert observers. We believe this is the first automated system that could assist pathologists by providing robust and reproducible second opinions on DCIS grade.
Deep Multi-Modal Image Correspondence Learning
Dec 05, 2016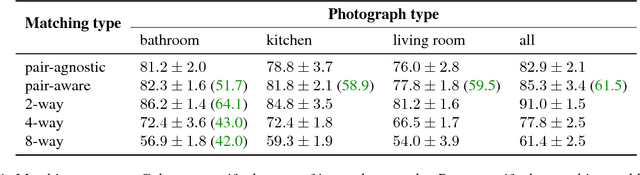
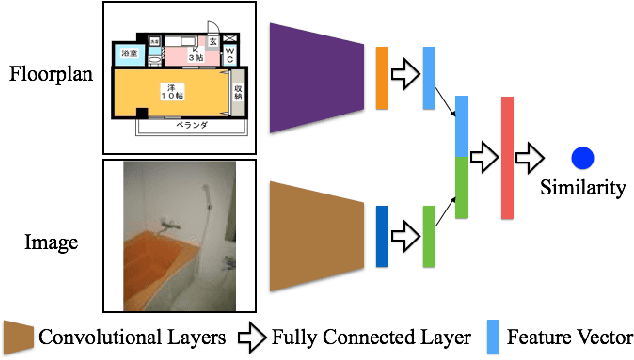
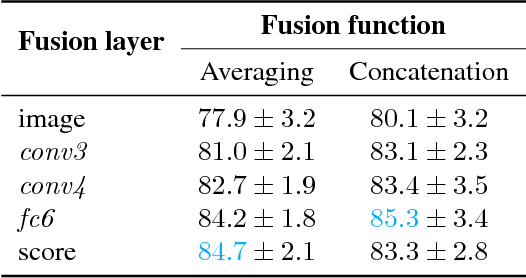
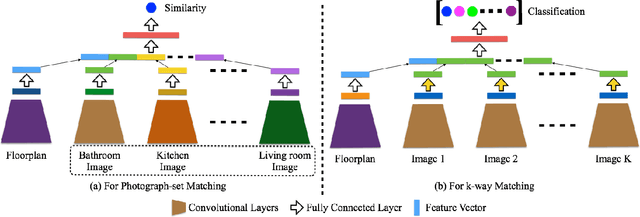
Inference of correspondences between images from different modalities is an extremely important perceptual ability that enables humans to understand and recognize cross-modal concepts. In this paper, we consider an instance of this problem that involves matching photographs of building interiors with their corresponding floorplan. This is a particularly challenging problem because a floorplan, as a stylized architectural drawing, is very different in appearance from a color photograph. Furthermore, individual photographs by themselves depict only a part of a floorplan (e.g., kitchen, bathroom, and living room). We propose the use of a number of different neural network architectures for this task, which are trained and evaluated on a novel large-scale dataset of 5 million floorplan images and 80 million associated photographs. Experimental evaluation reveals that our neural network architectures are able to identify visual cues that result in reliable matches across these two quite different modalities. In fact, the trained networks are able to even outperform human subjects in several challenging image matching problems. Our result implies that neural networks are effective at perceptual tasks that require long periods of reasoning even for humans to solve.
Recognizing Instagram Filtered Images with Feature De-stylization
Dec 30, 2019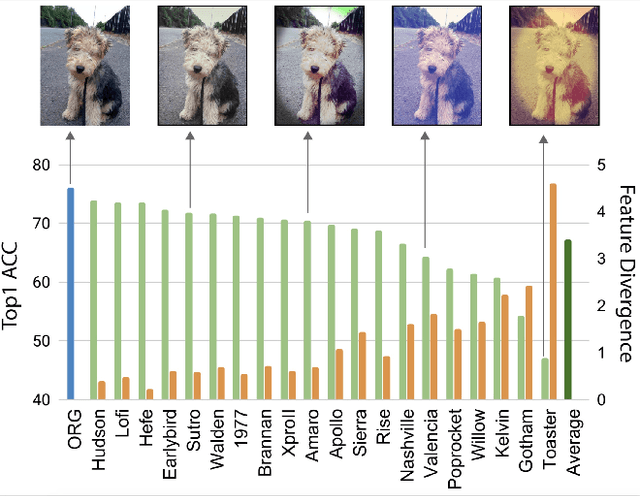


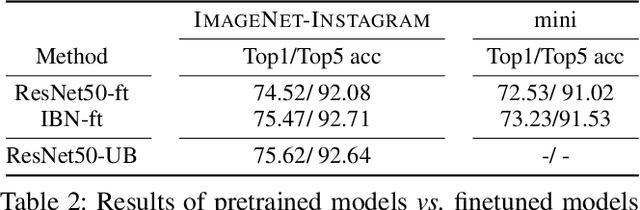
Deep neural networks have been shown to suffer from poor generalization when small perturbations are added (like Gaussian noise), yet little work has been done to evaluate their robustness to more natural image transformations like photo filters. This paper presents a study on how popular pretrained models are affected by commonly used Instagram filters. To this end, we introduce ImageNet-Instagram, a filtered version of ImageNet, where 20 popular Instagram filters are applied to each image in ImageNet. Our analysis suggests that simple structure preserving filters which only alter the global appearance of an image can lead to large differences in the convolutional feature space. To improve generalization, we introduce a lightweight de-stylization module that predicts parameters used for scaling and shifting feature maps to "undo" the changes incurred by filters, inverting the process of style transfer tasks. We further demonstrate the module can be readily plugged into modern CNN architectures together with skip connections. We conduct extensive studies on ImageNet-Instagram, and show quantitatively and qualitatively, that the proposed module, among other things, can effectively improve generalization by simply learning normalization parameters without retraining the entire network, thus recovering the alterations in the feature space caused by the filters.
Self-Supervised GAN Compression
Jul 03, 2020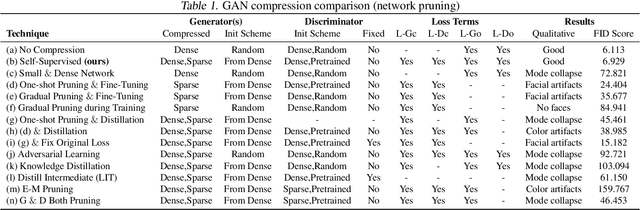

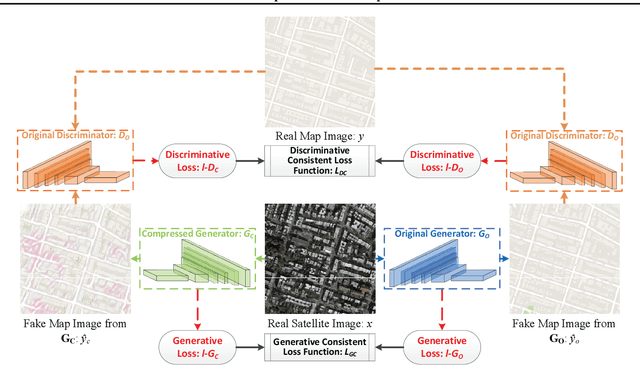
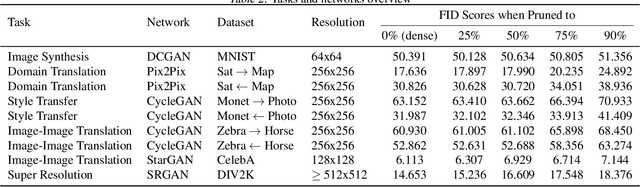
Deep learning's success has led to larger and larger models to handle more and more complex tasks; trained models can contain millions of parameters. These large models are compute- and memory-intensive, which makes it a challenge to deploy them with minimized latency, throughput, and storage requirements. Some model compression methods have been successfully applied to image classification and detection or language models, but there has been very little work compressing generative adversarial networks (GANs) performing complex tasks. In this paper, we show that a standard model compression technique, weight pruning, cannot be applied to GANs using existing methods. We then develop a self-supervised compression technique which uses the trained discriminator to supervise the training of a compressed generator. We show that this framework has a compelling performance to high degrees of sparsity, can be easily applied to new tasks and models, and enables meaningful comparisons between different pruning granularities.
Fault-Diagnosing SLAM for Varying Scale Change Detection
Sep 16, 2019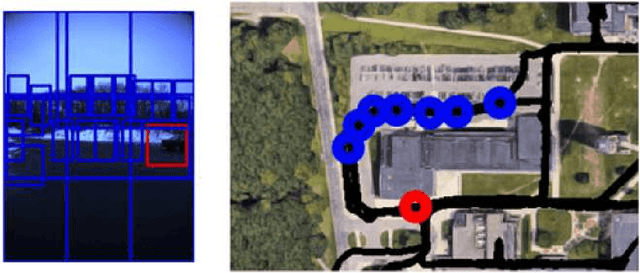
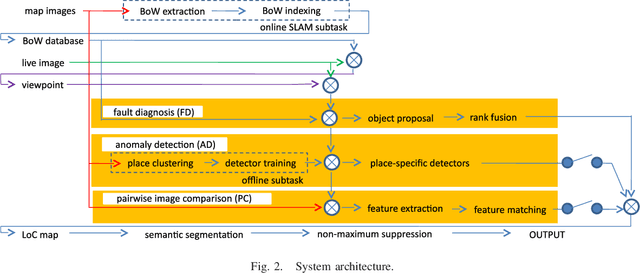

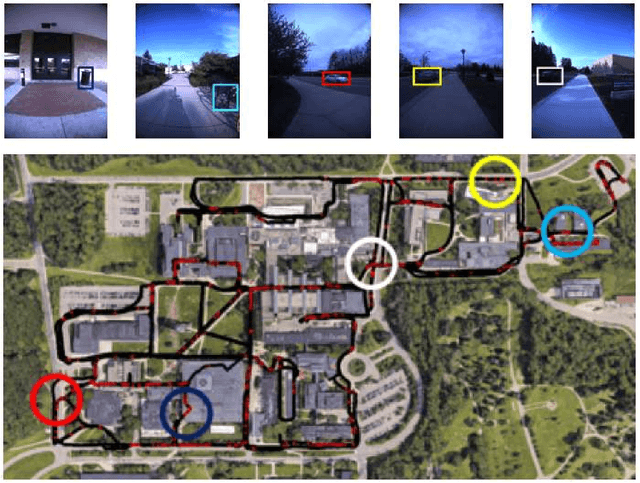
In this paper, we present a new fault diagnosis (FD) -based approach for detection of imagery changes that can detect significant changes as inconsistencies between different sub-modules (e.g., self-localizaiton) of visual SLAM. Unlike classical change detection approaches such as pairwise image comparison (PC) and anomaly detection (AD), neither the memorization of each map image nor the maintenance of up-to-date place-specific anomaly detectors are required in this FD approach. A significant challenge that is encountered when incorporating different SLAM sub-modules into FD involves dealing with the varying scales of objects that have changed (e.g., the appearance of small dangerous obstacles on the floor). To address this issue, we reconsider the bag-of-words (BoW) image representation, by exploiting its recent advances in terms of self-localization and change detection. As a key advantage, BoW image representation can be reorganized into any different scaling by simply cropping the original BoW image. Furthermore, we propose to combine different self-localization modules with strong and weak BoW features with different discriminativity, and to treat inconsistency between strong and weak self-localization as an indicator of change. The efficacy of the proposed approach for FD with/without AD and/or PC was experimentally validated.
Adversarial Colorization Of Icons Based On Structure And Color Conditions
Oct 03, 2019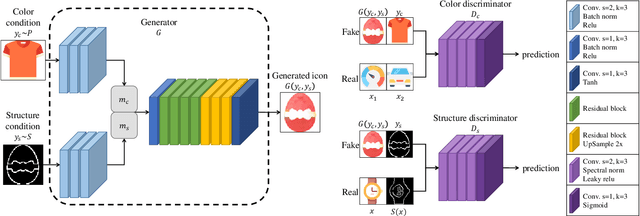
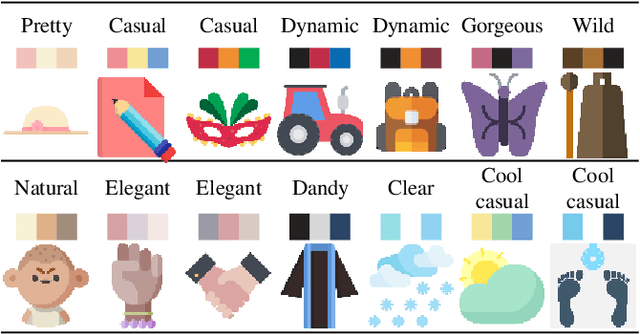

We present a system to help designers create icons that are widely used in banners, signboards, billboards, homepages, and mobile apps. Designers are tasked with drawing contours, whereas our system colorizes contours in different styles. This goal is achieved by training a dual conditional generative adversarial network (GAN) on our collected icon dataset. One condition requires the generated image and the drawn contour to possess a similar contour, while the other anticipates the image and the referenced icon to be similar in color style. Accordingly, the generator takes a contour image and a man-made icon image to colorize the contour, and then the discriminators determine whether the result fulfills the two conditions. The trained network is able to colorize icons demanded by designers and greatly reduces their workload. For the evaluation, we compared our dual conditional GAN to several state-of-the-art techniques. Experiment results demonstrate that our network is over the previous networks. Finally, we will provide the source code, icon dataset, and trained network for public use.
Self-Supervised Dynamic Networks for Covariate Shift Robustness
Jun 06, 2020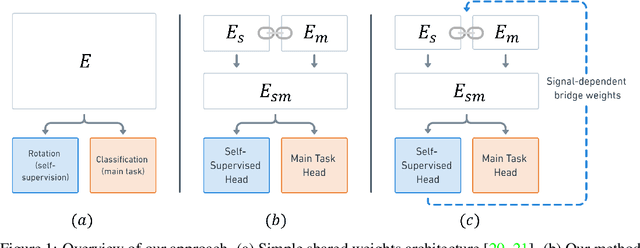

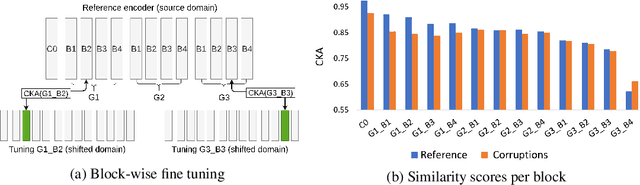
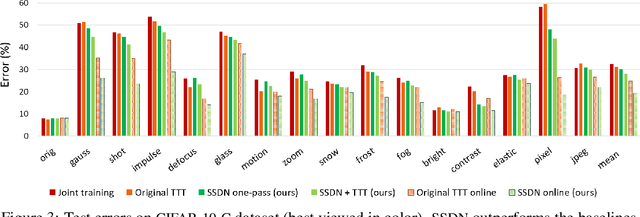
As supervised learning still dominates most AI applications, test-time performance is often unexpected. Specifically, a shift of the input covariates, caused by typical nuisances like background-noise, illumination variations or transcription errors, can lead to a significant decrease in prediction accuracy. Recently, it was shown that incorporating self-supervision can significantly improve covariate shift robustness. In this work, we propose Self-Supervised Dynamic Networks (SSDN): an input-dependent mechanism, inspired by dynamic networks, that allows a self-supervised network to predict the weights of the main network, and thus directly handle covariate shifts at test-time. We present the conceptual and empirical advantages of the proposed method on the problem of image classification under different covariate shifts, and show that it significantly outperforms comparable methods.
Learning Accurate and Human-Like Driving using Semantic Maps and Attention
Jul 10, 2020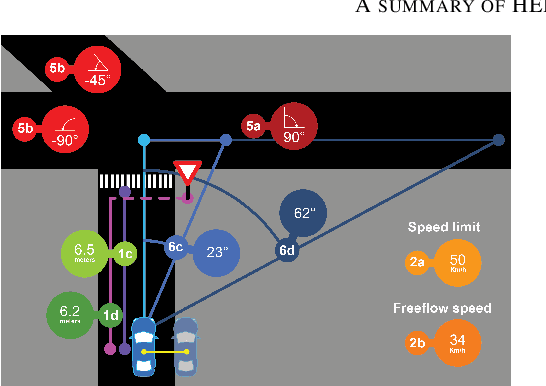
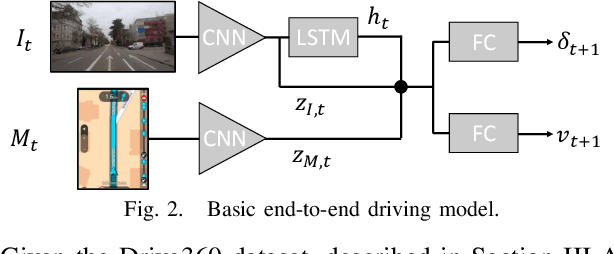
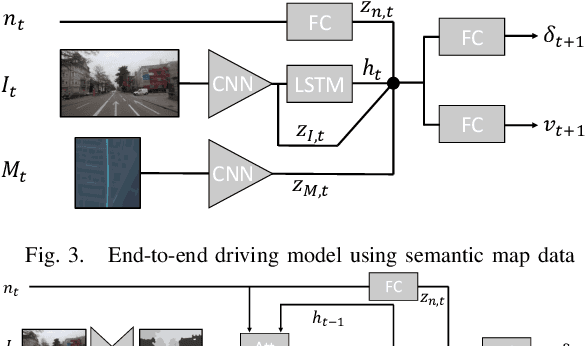
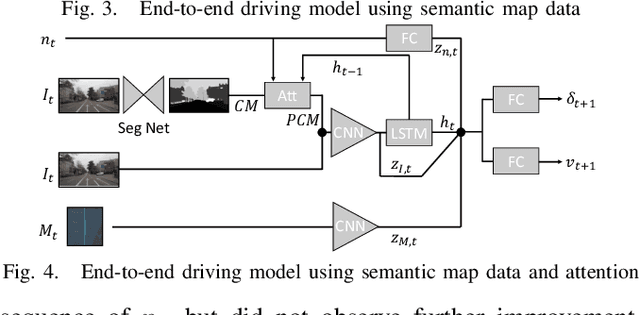
This paper investigates how end-to-end driving models can be improved to drive more accurately and human-like. To tackle the first issue we exploit semantic and visual maps from HERE Technologies and augment the existing Drive360 dataset with such. The maps are used in an attention mechanism that promotes segmentation confidence masks, thus focusing the network on semantic classes in the image that are important for the current driving situation. Human-like driving is achieved using adversarial learning, by not only minimizing the imitation loss with respect to the human driver but by further defining a discriminator, that forces the driving model to produce action sequences that are human-like. Our models are trained and evaluated on the Drive360 + HERE dataset, which features 60 hours and 3000 km of real-world driving data. Extensive experiments show that our driving models are more accurate and behave more human-like than previous methods.
Video Super Resolution Based on Deep Learning: A comprehensive survey
Jul 25, 2020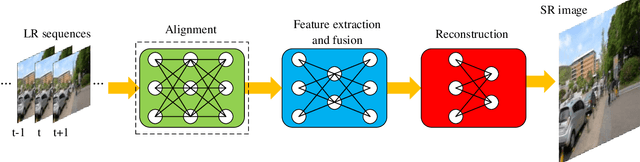
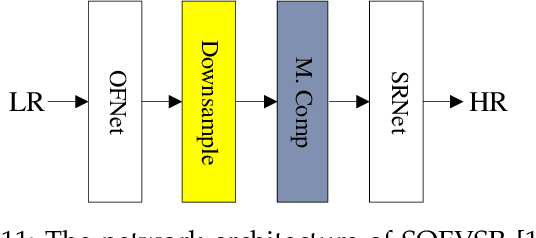
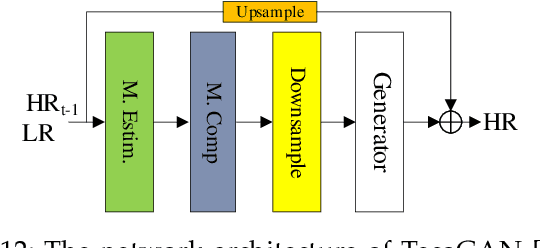
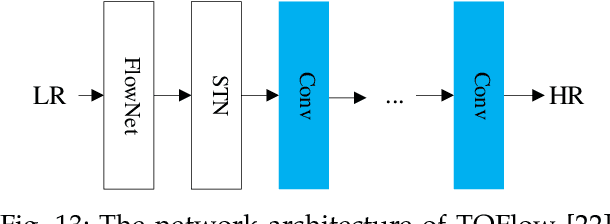
In recent years, deep learning has made great progress in the fields of image recognition, video analysis, natural language processing and speech recognition, including video super-resolution tasks. In this survey, we comprehensively investigate 28 state-of-the-art video super-resolution methods based on deep learning. It is well known that the leverage of information within video frames is important for video super-resolution. Hence we propose a taxonomy and classify the methods into six sub-categories according to the ways of utilizing inter-frame information. Moreover, the architectures and implementation details (including input and output, loss function and learning rate) of all the methods are depicted in details. Finally, we summarize and compare their performance on some benchmark datasets under different magnification factors. We also discuss some challenges, which need to be further addressed by researchers in the community of video super-resolution. Therefore, this work is expected to make a contribution to the future development of research in video super-resolution, and alleviate understandability and transferability of existing and future techniques into practice.
Semantic Segmentation of Histopathological Slides for the Classification of Cutaneous Lymphoma and Eczema
Sep 10, 2020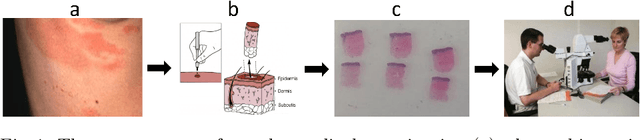
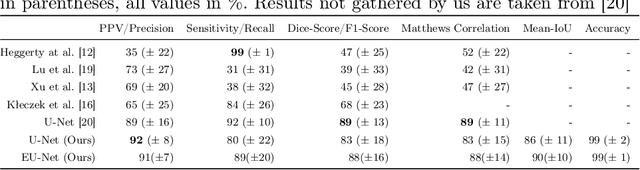
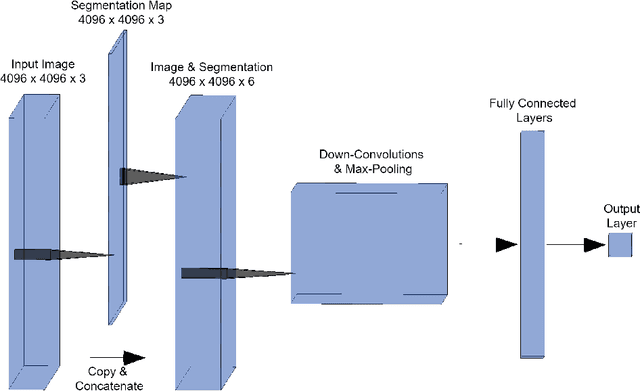

Mycosis fungoides (MF) is a rare, potentially life threatening skin disease, which in early stages clinically and histologically strongly resembles Eczema, a very common and benign skin condition. In order to increase the survival rate, one needs to provide the appropriate treatment early on. To this end, one crucial step for specialists is the evaluation of histopathological slides (glass slides), or Whole Slide Images (WSI), of the patients' skin tissue. We introduce a deep learning aided diagnostics tool that brings a two-fold value to the decision process of pathologists. First, our algorithm accurately segments WSI into regions that are relevant for an accurate diagnosis, achieving a Mean-IoU of 69% and a Matthews Correlation score of 83% on a novel dataset. Additionally, we also show that our model is competitive with the state of the art on a reference dataset. Second, using the segmentation map and the original image, we are able to predict if a patient has MF or Eczema. We created two models that can be applied in different stages of the diagnostic pipeline, potentially eliminating life-threatening mistakes. The classification outcome is considerably more interpretable than using only the WSI as the input, since it is also based on the segmentation map. Our segmentation model, which we call EU-Net, extends a classical U-Net with an EfficientNet-B7 encoder which was pre-trained on the Imagenet dataset.
* Submitted to https://link.springer.com/chapter/10.1007/978-3-030-52791-4_3