 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault-Diagnosing SLAM for Varying Scale Change Detection
Sep 16, 2019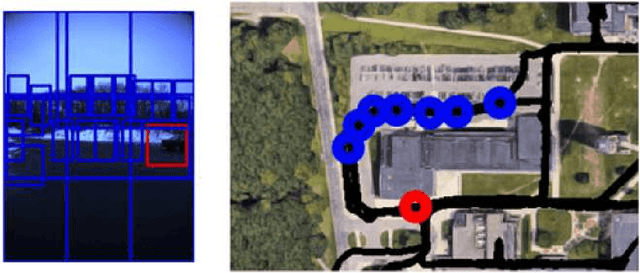
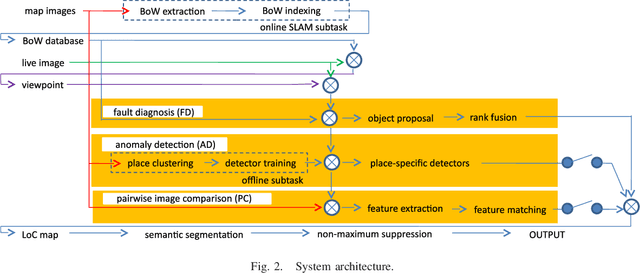

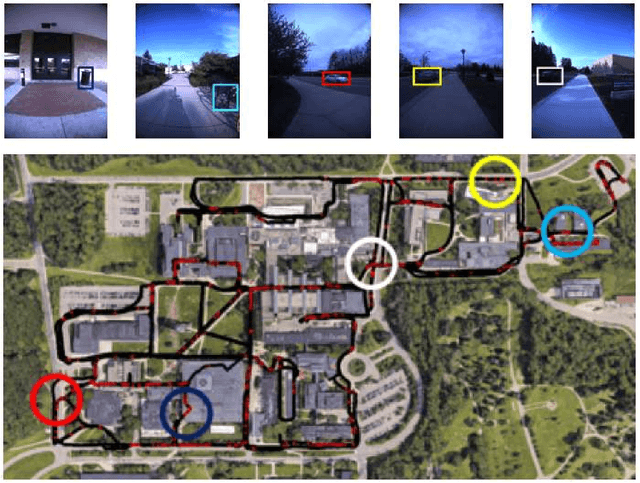
In this paper, we present a new fault diagnosis (FD) -based approach for detection of imagery changes that can detect significant changes as inconsistencies between different sub-modules (e.g., self-localizaiton) of visual SLAM. Unlike classical change detection approaches such as pairwise image comparison (PC) and anomaly detection (AD), neither the memorization of each map image nor the maintenance of up-to-date place-specific anomaly detectors are required in this FD approach. A significant challenge that is encountered when incorporating different SLAM sub-modules into FD involves dealing with the varying scales of objects that have changed (e.g., the appearance of small dangerous obstacles on the floor). To address this issue, we reconsider the bag-of-words (BoW) image representation, by exploiting its recent advances in terms of self-localization and change detection. As a key advantage, BoW image representation can be reorganized into any different scaling by simply cropping the original BoW image. Furthermore, we propose to combine different self-localization modules with strong and weak BoW features with different discriminativity, and to treat inconsistency between strong and weak self-localization as an indicator of change. The efficacy of the proposed approach for FD with/without AD and/or PC was experimentally validated.
Place-specific Background Modeling Using Recursive Autoencoders
Apr 07, 2019

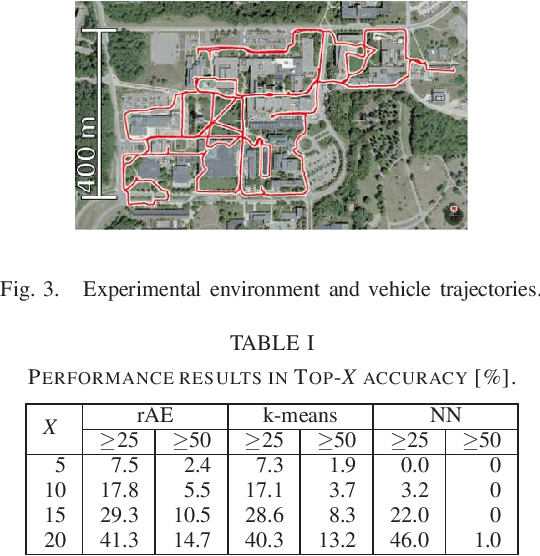
Image change detection (ICD) to detect changed objects in front of a vehicle with respect to a place-specific background model using an on-board monocular vision system is a fundamental problem in intelligent vehicle (IV). From the perspective of recent large-scale IV applications, it can be impractical in terms of space/time efficiency to train place-specific background models for every possible place. To address these issues, we introduce a new autoencoder (AE) based efficient ICD framework that combines the advantages of AE-based anomaly detection (AD) and AE-based image compression (IC). We propose a method that uses AE reconstruction errors as a single unified measure for training a minimal set of place-specific AEs and maintains detection accuracy. We introduce an efficient incremental recursive AE (rAE) training framework that recursively summarizes a large collection of background images into the AE set. The results of experiments on challenging cross-season ICD tasks validate the efficacy of the proposed approach.
Simultaneous Detection of Loop-Closures and Changed Objects
Feb 26, 2019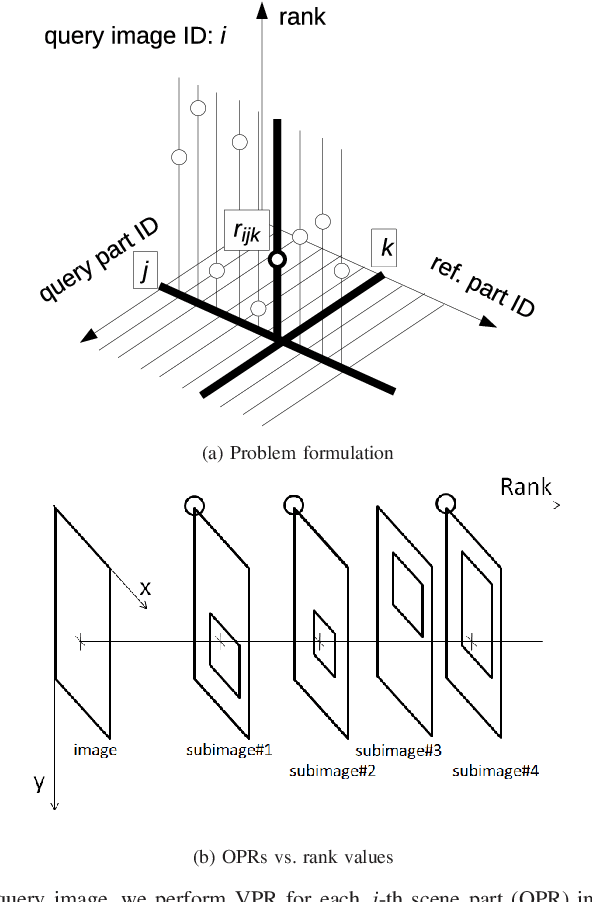

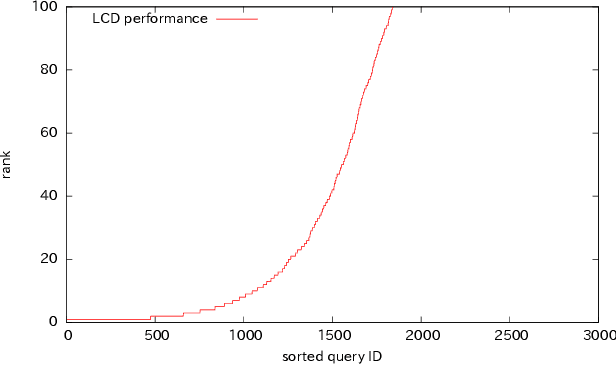
Loop-closure detection (LCD) in large non-stationary environments remains an important challenge in robotic visual simultaneous localization and mapping (vSLAM). To reduce computational and perceptual complexity, it is helpful if a vSLAM system has the ability to perform image change detection (ICD). Unlike previous applications of ICD, time-critical vSLAM applications cannot assume an offline background modeling stage, or rely on maintenance-intensive background models. To address this issue, we introduce a novel maintenance-free ICD framework that requires no background modeling. Specifically, we demonstrate that LCD can be reused as the main process for ICD with minimal extra cost. Based on these concepts, we develop a novel vSLAM component that enables simultaneous LCD and ICD. ICD experiments based on challenging cross-season LCD scenarios validate the efficacy of the proposed method.
Use of Generative Adversarial Network for Cross-Domain Change Detection
Dec 24, 2017
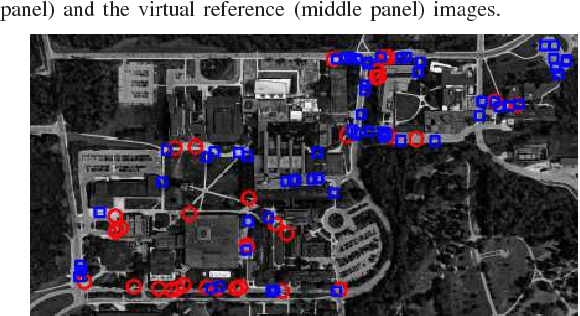

This paper addresses the problem of cross-domain change detection from a novel perspective of image-to-image translation. In general, change detection aims to identify interesting changes between a given query image and a reference image of the same scene taken at a different time. This problem becomes a challenging one when query and reference images involve different domains (e.g., time of the day, weather, and season) due to variations in object appearance and a limited amount of training examples. In this study, we address the above issue by leveraging a generative adversarial network (GAN). Our key concept is to use a limited amount of training data to train a GAN-based image translator that maps a reference image to a virtual image that cannot be discriminated from query domain images. This enables us to treat the cross-domain change detection task as an in-domain image comparison. This allows us to leverage the large body of literature on in-domain generic change detectors. In addition, we also consider the use of visual place recognition as a method for mining more appropriate reference images over the space of virtual images. Experiments validate efficacy of the proposed approach.