 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
All-In-One: Facial Expression Transfer, Editing and Recognition Using A Single Network
Nov 16, 2019
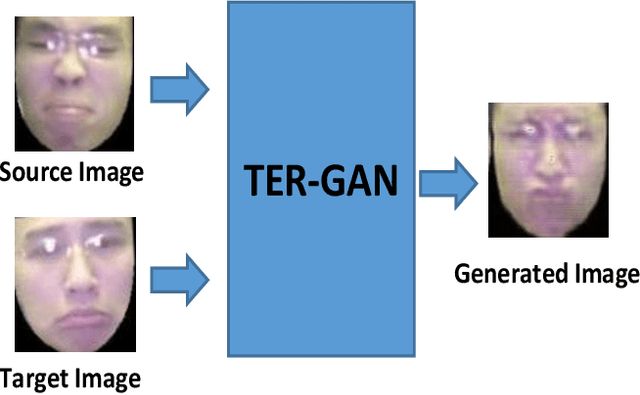
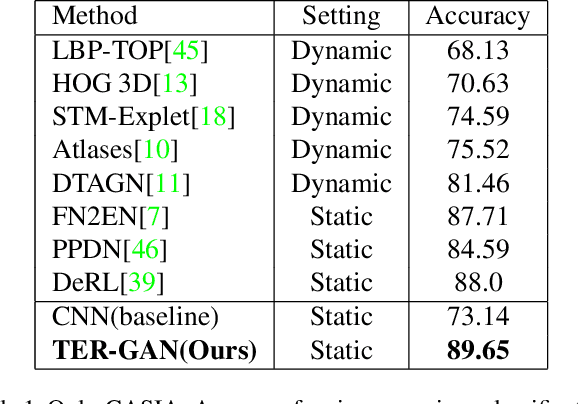
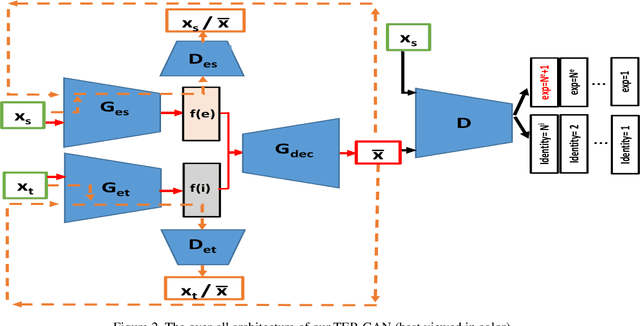

In this paper, we present a unified architecture known as Transfer-Editing and Recognition Generative Adversarial Network (TER-GAN) which can be used: 1. to transfer facial expressions from one identity to another identity, known as Facial Expression Transfer (FET), 2. to transform the expression of a given image to a target expression, while preserving the identity of the image, known as Facial Expression Editing (FEE), and 3. to recognize the facial expression of a face image, known as Facial Expression Recognition (FER). In TER-GAN, we combine the capabilities of generative models to generate synthetic images, while learning important information about the input images during the reconstruction process. More specifically, two encoders are used in TER-GAN to encode identity and expression information from two input images, and a synthetic expression image is generated by the decoder part of TER-GAN. To improve the feature disentanglement and extraction process, we also introduce a novel expression consistency loss and an identity consistency loss which exploit extra expression and identity information from generated images. Experimental results show that the proposed method can be used for efficient facial expression transfer, facial expression editing and facial expression recognition. In order to evaluate the proposed technique and to compare our results with state-of-the-art methods, we have used the Oulu-CASIA dataset for our experiments.
An implementation of an imitation game with ASD children to learn nursery rhymes
Apr 10, 2020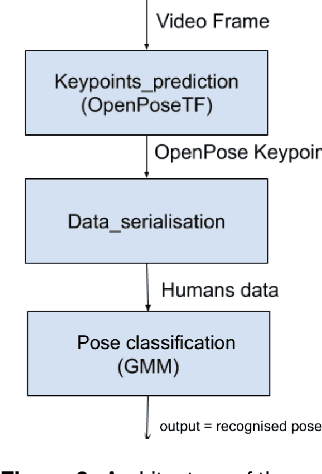
Previous studies have suggested that being imitated by an adult is an effective intervention with children with autism and developmental delay. The purpose of this study is to investigate if an imitation game with a robot can arise interest from children and constitute an effective tool to be used in clinical activities. In this paper, we describe the design of our nursery rhyme imitation game, its implementation based on RGB image pose recognition and the preliminary tests we performed.
Effect of Input Noise Dimension in GANs
Apr 15, 2020
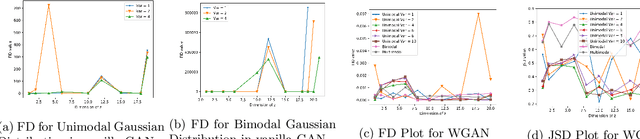


Generative Adversarial Networks (GANs) are by far the most successful generative models. Learning the transformation which maps a low dimensional input noise to the data distribution forms the foundation for GANs. Although they have been applied in various domains, they are prone to certain challenges like mode collapse and unstable training. To overcome the challenges, researchers have proposed novel loss functions, architectures, and optimization methods. In our work here, unlike the previous approaches, we focus on the input noise and its role in the generation. We aim to quantitatively and qualitatively study the effect of the dimension of the input noise on the performance of GANs. For quantitative measures, typically \emph{Fr\'{e}chet Inception Distance (FID)} and \emph{Inception Score (IS)} are used as performance measure on image data-sets. We compare the FID and IS values for DCGAN and WGAN-GP. We use three different image data-sets -- each consisting of different levels of complexity. Through our experiments, we show that the right dimension of input noise for optimal results depends on the data-set and architecture used. We also observe that the state of the art performance measures does not provide enough useful insights. Hence we conclude that we need further theoretical analysis for understanding the relationship between the low dimensional distribution and the generated images. We also require better performance measures.
MIPGAN -- Generating Robust and High QualityMorph Attacks Using Identity Prior Driven GAN
Sep 03, 2020
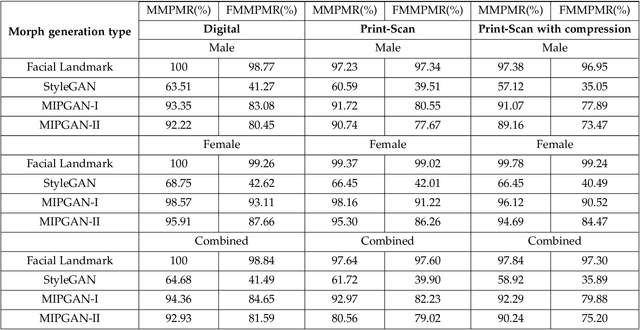
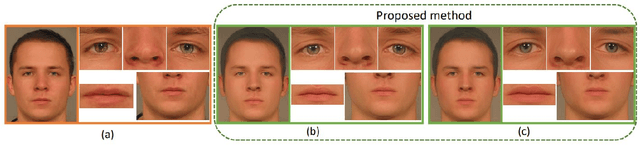
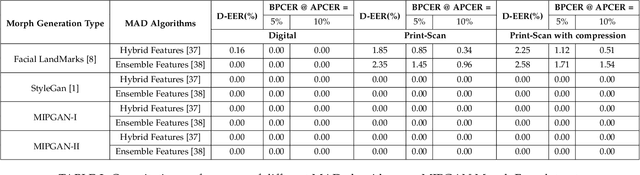
Face morphing attacks target to circumvent Face Recognition Systems (FRS) by employing face images derived from multiple data subjects (e.g., accomplices and malicious actors). Morphed images can verify against contributing data subjects with a reasonable success rate, given they have a high degree of identity resemblance. The success of the morphing attacks is directly dependent on the quality of the generated morph images. We present a new approach for generating robust attacks extending our earlier framework for generating face morphs. We present a new approach using an Identity Prior Driven Generative Adversarial Network, which we refer to as \textit{MIPGAN (Morphing through Identity Prior driven GAN)}. The proposed MIPGAN is derived from the StyleGAN with a newly formulated loss function exploiting perceptual quality and identity factor to generate a high quality morphed face image with minimal artifacts and with higher resolution. We demonstrate the proposed approach's applicability to generate robust morph attacks by evaluating it against a commercial Face Recognition System (FRS) and demonstrate the success rate of attacks. Extensive experiments are carried out to assess the FRS's vulnerability against the proposed morphed face generation technique on three types of data such as digital images, re-digitized (printed and scanned) images, and compressed images after re-digitization from newly generated \textit{MIPGAN Face Morph Dataset}. The obtained results demonstrate that the proposed approach of morph generation profoundly threatens the FRS.
An Empirical Analysis of Backward Compatibility in Machine Learning Systems
Aug 11, 2020

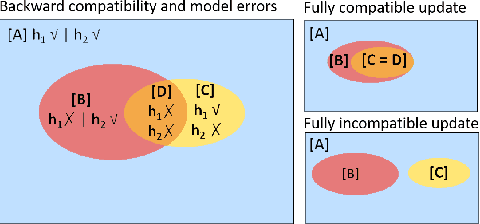

In many applications of machine learning (ML), updates are performed with the goal of enhancing model performance. However, current practices for updating models rely solely on isolated, aggregate performance analyses, overlooking important dependencies, expectations, and needs in real-world deployments. We consider how updates, intended to improve ML models, can introduce new errors that can significantly affect downstream systems and users. For example, updates in models used in cloud-based classification services, such as image recognition, can cause unexpected erroneous behavior in systems that make calls to the services. Prior work has shown the importance of "backward compatibility" for maintaining human trust. We study challenges with backward compatibility across different ML architectures and datasets, focusing on common settings including data shifts with structured noise and ML employed in inferential pipelines. Our results show that (i) compatibility issues arise even without data shift due to optimization stochasticity, (ii) training on large-scale noisy datasets often results in significant decreases in backward compatibility even when model accuracy increases, and (iii) distributions of incompatible points align with noise bias, motivating the need for compatibility aware de-noising and robustness methods.
They are wearing a mask! Identification of Subjects Wearing a Surgical Mask from their Speech by means of x-vectors and Fisher Vectors
Aug 23, 2020
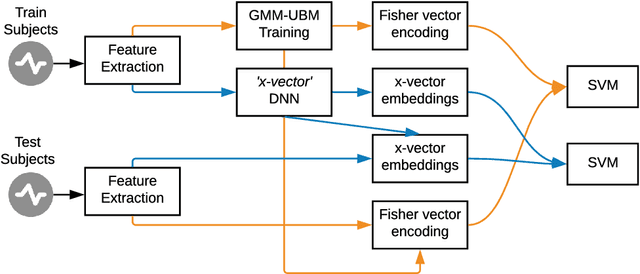
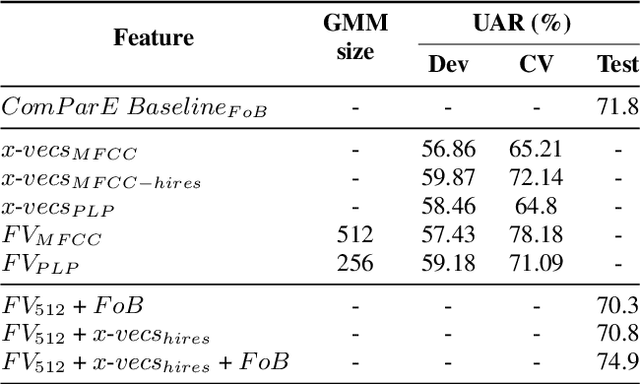
Challenges based on Computational Paralinguistics in the INTERSPEECH Conference have always had a good reception among the attendees owing to its competitive academic and research demands. This year, the INTERSPEECH 2020 Computational Paralinguistics Challenge offers three different problems; here, the Mask Sub-Challenge is of specific interest. This challenge involves the classification of speech recorded from subjects while wearing a surgical mask. In this study, to address the above-mentioned problem we employ two different types of feature extraction methods. The x-vectors embeddings, which is the current state-of-the-art approach for Speaker Recognition; and the Fisher Vector (FV), that is a method originally intended for Image Recognition, but here we utilize it to discriminate utterances. These approaches employ distinct frame-level representations: MFCC and PLP. Using Support Vector Machines (SVM) as the classifier, we perform a technical comparison between the performances of the FV encodings and the x-vector embeddings for this particular classification task. We find that the Fisher vector encodings provide better representations of the utterances than the x-vectors do for this specific dataset. Moreover, we show that a fusion of our best configurations outperforms all the baseline scores of the Mask Sub-Challenge.
Cross-Scale Residual Network for Multiple Tasks:Image Super-resolution, Denoising, and Deblocking
Nov 04, 2019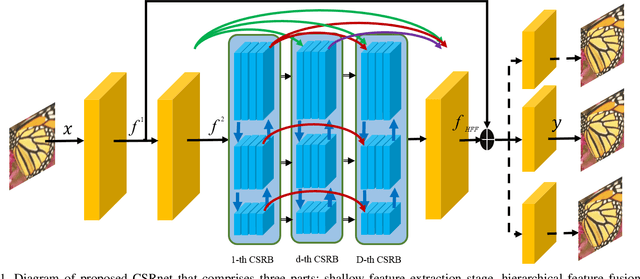


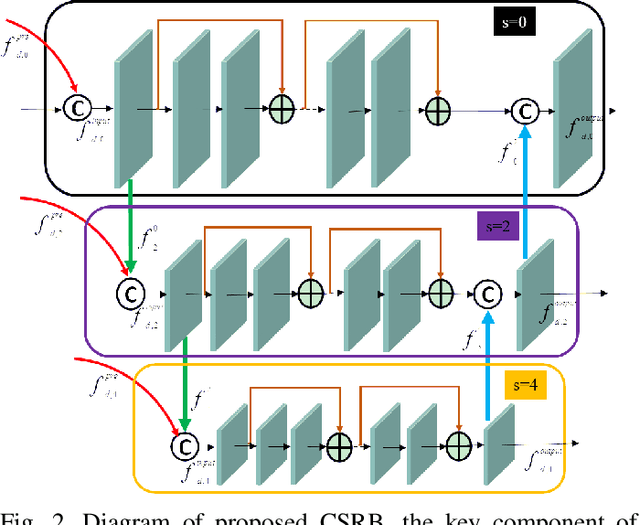
In general, image restoration involves mapping from low quality images to their high-quality counterparts. Such optimal mapping is usually non-linear and learnable by machine learning. Recently, deep convolutional neural networks have proven promising for such learning processing. It is desirable for an image processing network to support well with three vital tasks, namely, super-resolution, denoising, and deblocking. It is commonly recognized that these tasks have strong correlations. Therefore, it is imperative to harness the inter-task correlations. To this end, we propose the cross-scale residual network to exploit scale-related features and the inter-task correlations among the three tasks. The proposed network can extract multiple spatial scale features and establish multiple temporal feature reusage. Our experiments show that the proposed approach outperforms state-of-the-art methods in both quantitative and qualitative evaluations for multiple image restoration tasks.
A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
Aug 23, 2020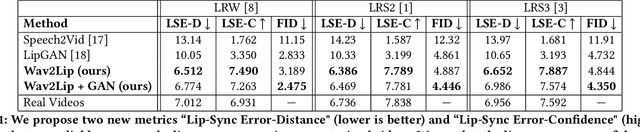
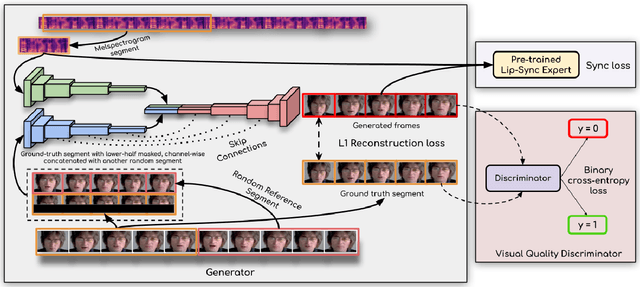
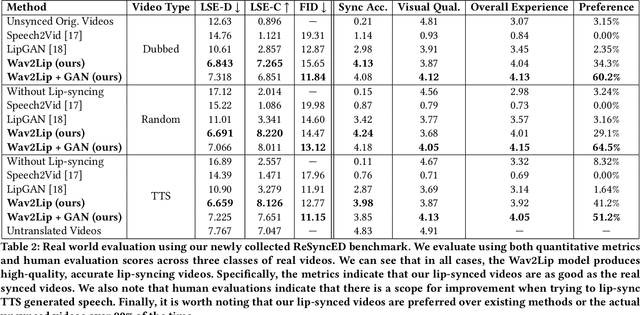
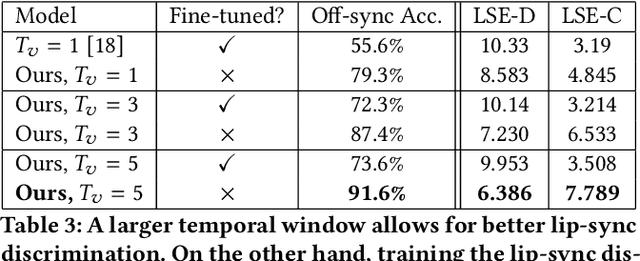
In this work, we investigate the problem of lip-syncing a talking face video of an arbitrary identity to match a target speech segment. Current works excel at producing accurate lip movements on a static image or videos of specific people seen during the training phase. However, they fail to accurately morph the lip movements of arbitrary identities in dynamic, unconstrained talking face videos, resulting in significant parts of the video being out-of-sync with the new audio. We identify key reasons pertaining to this and hence resolve them by learning from a powerful lip-sync discriminator. Next, we propose new, rigorous evaluation benchmarks and metrics to accurately measure lip synchronization in unconstrained videos. Extensive quantitative evaluations on our challenging benchmarks show that the lip-sync accuracy of the videos generated by our Wav2Lip model is almost as good as real synced videos. We provide a demo video clearly showing the substantial impact of our Wav2Lip model and evaluation benchmarks on our website: \url{cvit.iiit.ac.in/research/projects/cvit-projects/a-lip-sync-expert-is-all-you-need-for-speech-to-lip-generation-in-the-wild}. The code and models are released at this GitHub repository: \url{github.com/Rudrabha/Wav2Lip}. You can also try out the interactive demo at this link: \url{bhaasha.iiit.ac.in/lipsync}.
Self-Supervised Monocular Depth Estimation: Solving the Dynamic Object Problem by Semantic Guidance
Jul 14, 2020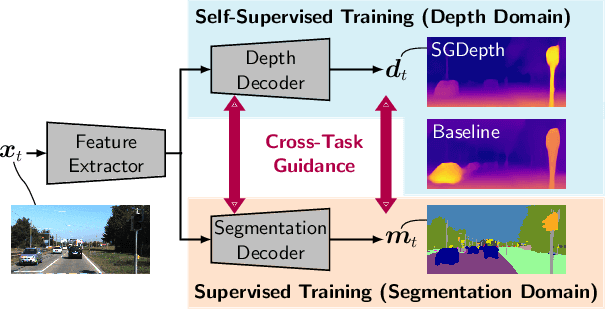
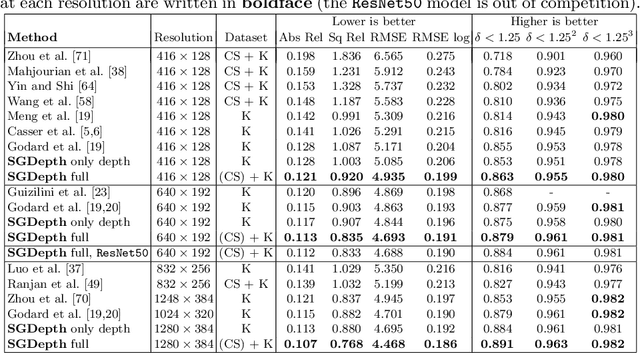
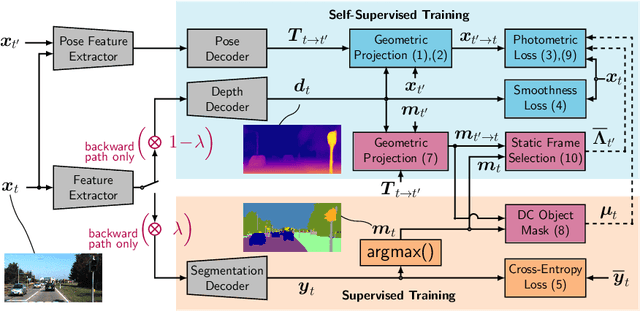
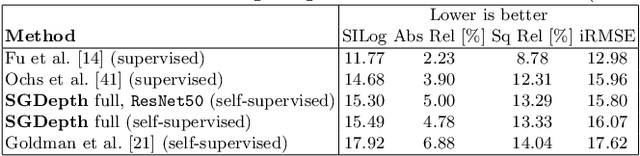
Self-supervised monocular depth estimation presents a powerful method to obtain 3D scene information from single camera images, which is trainable on arbitrary image sequences without requiring depth labels, e.g., from a LiDAR sensor. In this work we present a new self-supervised semantically-guided depth estimation (SGDepth) method to deal with moving dynamic-class (DC) objects, such as moving cars and pedestrians, which violate the static-world assumptions typically made during training of such models. Specifically, we propose (i) mutually beneficial cross-domain training of (supervised) semantic segmentation and self-supervised depth estimation with task-specific network heads, (ii) a semantic masking scheme providing guidance to prevent moving DC objects from contaminating the photometric loss, and (iii) a detection method for frames with non-moving DC objects, from which the depth of DC objects can be learned. We demonstrate the performance of our method on several benchmarks, in particular on the Eigen split, where we exceed all baselines without test-time refinement in all measures.
Dual-reference Age Synthesis
Aug 07, 2019
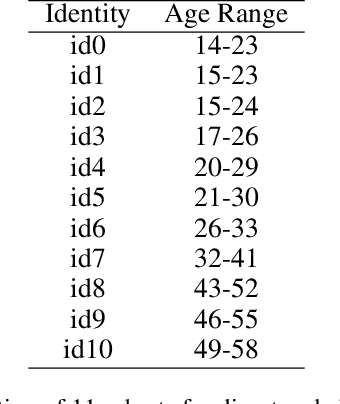

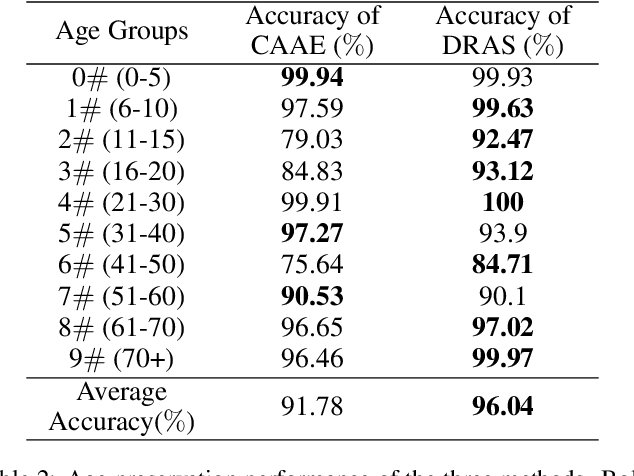
Age synthesis has received much attention in recent years. State-of-the-art methods typically take an input image and utilize a numeral to control the age of the generated image. In this paper, we revisit the age synthesis and ask: is a numeral capable enough to describe the human age? We propose a new framework Dual-reference Age Synthesis (DRAS) that takes two images as inputs to generate an image which shares the same personality of the first image and has the similar age with the second image. In the proposed framework, we employ a joint manifold feature which consists of disentangled age and identity information. The final images are generated by training a generative adversarial network which competes against an age agent and an identity agent. Experimental results demonstrate the appealing performance and flexibility of the proposed framework by comparing with the state-of-the-art and ground truth.