 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolar Coordinate-Based 2D Pose Prior with Neural Distance Field
May 06, 2025



Human pose capture is essential for sports analysis, enabling precise evaluation of athletes' movements. While deep learning-based human pose estimation (HPE) models from RGB videos have achieved impressive performance on public datasets, their effectiveness in real-world sports scenarios is often hindered by motion blur, occlusions, and domain shifts across different pose representations. Fine-tuning these models can partially alleviate such challenges but typically requires large-scale annotated data and still struggles to generalize across diverse sports environments. To address these limitations, we propose a 2D pose prior-guided refinement approach based on Neural Distance Fields (NDF). Unlike existing approaches that rely solely on angular representations of human poses, we introduce a polar coordinate-based representation that explicitly incorporates joint connection lengths, enabling a more accurate correction of erroneous pose estimations. Additionally, we define a novel non-geodesic distance metric that separates angular and radial discrepancies, which we demonstrate is better suited for polar representations than traditional geodesic distances. To mitigate data scarcity, we develop a gradient-based batch-projection augmentation strategy, which synthesizes realistic pose samples through iterative refinement. Our method is evaluated on a long jump dataset, demonstrating its ability to improve 2D pose estimation across multiple pose representations, making it robust across different domains. Experimental results show that our approach enhances pose plausibility while requiring only limited training data. Code is available at: https://github.com/QGAN2019/polar-NDF.
The intrinsic motivation of reinforcement and imitation learning for sequential tasks
Dec 29, 2024



This work in the field of developmental cognitive robotics aims to devise a new domain bridging between reinforcement learning and imitation learning, with a model of the intrinsic motivation for learning agents to learn with guidance from tutors multiple tasks, including sequential tasks. The main contribution has been to propose a common formulation of intrinsic motivation based on empirical progress for a learning agent to choose automatically its learning curriculum by actively choosing its learning strategy for simple or sequential tasks: which task to learn, between autonomous exploration or imitation learning, between low-level actions or task decomposition, between several tutors. The originality is to design a learner that benefits not only passively from data provided by tutors, but to actively choose when to request tutoring and what and whom to ask. The learner is thus more robust to the quality of the tutoring and learns faster with fewer demonstrations. We developed the framework of socially guided intrinsic motivation with machine learning algorithms to learn multiple tasks by taking advantage of the generalisability properties of human demonstrations in a passive manner or in an active manner through requests of demonstrations from the best tutor for simple and composing subtasks. The latter relies on a representation of subtask composition proposed for a construction process, which should be refined by representations used for observational processes of analysing human movements and activities of daily living. With the outlook of a language-like communication with the tutor, we investigated the emergence of a symbolic representation of the continuous sensorimotor space and of tasks using intrinsic motivation. We proposed within the reinforcement learning framework, a reward function for interacting with tutors for automatic curriculum learning in multi-task learning.
Generative Pretrained Embedding and Hierarchical Irregular Time Series Representation for Daily Living Activity Recognition
Dec 27, 2024Within the evolving landscape of smart homes, the precise recognition of daily living activities using ambient sensor data stands paramount. This paper not only aims to bolster existing algorithms by evaluating two distinct pretrained embeddings suited for ambient sensor activations but also introduces a novel hierarchical architecture. We delve into an architecture anchored on Transformer Decoder-based pre-trained embeddings, reminiscent of the GPT design, and contrast it with the previously established state-of-the-art (SOTA) ELMo embeddings for ambient sensors. Our proposed hierarchical structure leverages the strengths of each pre-trained embedding, enabling the discernment of activity dependencies and sequence order, thereby enhancing classification precision. To further refine recognition, we incorporate into our proposed architecture an hour-of-the-day embedding. Empirical evaluations underscore the preeminence of the Transformer Decoder embedding in classification endeavors. Additionally, our innovative hierarchical design significantly bolsters the efficacy of both pre-trained embeddings, notably in capturing inter-activity nuances. The integration of temporal aspects subtly but distinctively augments classification, especially for time-sensitive activities. In conclusion, our GPT-inspired hierarchical approach, infused with temporal insights, outshines the SOTA ELMo benchmark.
A Medical Low-Back Pain Physical Rehabilitation Dataset for Human Body Movement Analysis
Jun 29, 2024



While automatic monitoring and coaching of exercises are showing encouraging results in non-medical applications, they still have limitations such as errors and limited use contexts. To allow the development and assessment of physical rehabilitation by an intelligent tutoring system, we identify in this article four challenges to address and propose a medical dataset of clinical patients carrying out low back-pain rehabilitation exercises. The dataset includes 3D Kinect skeleton positions and orientations, RGB videos, 2D skeleton data, and medical annotations to assess the correctness, and error classification and localisation of body part and timespan. Along this dataset, we perform a complete research path, from data collection to processing, and finally a small benchmark. We evaluated on the dataset two baseline movement recognition algorithms, pertaining to two different approaches: the probabilistic approach with a Gaussian Mixture Model (GMM), and the deep learning approach with a Long-Short Term Memory (LSTM). This dataset is valuable because it includes rehabilitation relevant motions in a clinical setting with patients in their rehabilitation program, using a cost-effective, portable, and convenient sensor, and because it shows the potential for improvement on these challenges.
Prerequisite Structure Discovery in Intelligent Tutoring Systems
Jan 18, 2024This paper addresses the importance of Knowledge Structure (KS) and Knowledge Tracing (KT) in improving the recommendation of educational content in intelligent tutoring systems. The KS represents the relations between different Knowledge Components (KCs), while KT predicts a learner's success based on her past history. The contribution of this research includes proposing a KT model that incorporates the KS as a learnable parameter, enabling the discovery of the underlying KS from learner trajectories. The quality of the uncovered KS is assessed by using it to recommend content and evaluating the recommendation algorithm with simulated students.
Reconciling Spatial and Temporal Abstractions for Goal Representation
Jan 18, 2024



Goal representation affects the performance of Hierarchical Reinforcement Learning (HRL) algorithms by decomposing the complex learning problem into easier subtasks. Recent studies show that representations that preserve temporally abstract environment dynamics are successful in solving difficult problems and provide theoretical guarantees for optimality. These methods however cannot scale to tasks where environment dynamics increase in complexity i.e. the temporally abstract transition relations depend on larger number of variables. On the other hand, other efforts have tried to use spatial abstraction to mitigate the previous issues. Their limitations include scalability to high dimensional environments and dependency on prior knowledge. In this paper, we propose a novel three-layer HRL algorithm that introduces, at different levels of the hierarchy, both a spatial and a temporal goal abstraction. We provide a theoretical study of the regret bounds of the learned policies. We evaluate the approach on complex continuous control tasks, demonstrating the effectiveness of spatial and temporal abstractions learned by this approach.
Goal Space Abstraction in Hierarchical Reinforcement Learning via Set-Based Reachability Analysis
Sep 14, 2023



Open-ended learning benefits immensely from the use of symbolic methods for goal representation as they offer ways to structure knowledge for efficient and transferable learning. However, the existing Hierarchical Reinforcement Learning (HRL) approaches relying on symbolic reasoning are often limited as they require a manual goal representation. The challenge in autonomously discovering a symbolic goal representation is that it must preserve critical information, such as the environment dynamics. In this paper, we propose a developmental mechanism for goal discovery via an emergent representation that abstracts (i.e., groups together) sets of environment states that have similar roles in the task. We introduce a Feudal HRL algorithm that concurrently learns both the goal representation and a hierarchical policy. The algorithm uses symbolic reachability analysis for neural networks to approximate the transition relation among sets of states and to refine the goal representation. We evaluate our approach on complex navigation tasks, showing the learned representation is interpretable, transferrable and results in data efficient learning.
Goal Space Abstraction in Hierarchical Reinforcement Learning via Reachability Analysis
Sep 12, 2023


Open-ended learning benefits immensely from the use of symbolic methods for goal representation as they offer ways to structure knowledge for efficient and transferable learning. However, the existing Hierarchical Reinforcement Learning (HRL) approaches relying on symbolic reasoning are often limited as they require a manual goal representation. The challenge in autonomously discovering a symbolic goal representation is that it must preserve critical information, such as the environment dynamics. In this work, we propose a developmental mechanism for subgoal discovery via an emergent representation that abstracts (i.e., groups together) sets of environment states that have similar roles in the task. We create a HRL algorithm that gradually learns this representation along with the policies and evaluate it on navigation tasks to show the learned representation is interpretable and results in data efficiency.
Robots Learn Increasingly Complex Tasks with Intrinsic Motivation and Automatic Curriculum Learning
Feb 11, 2022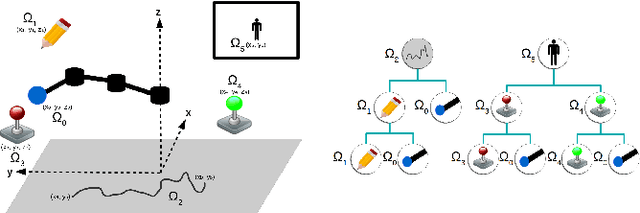
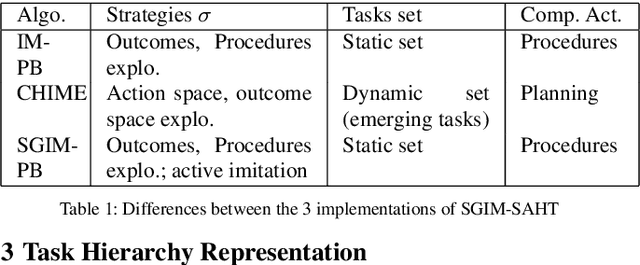
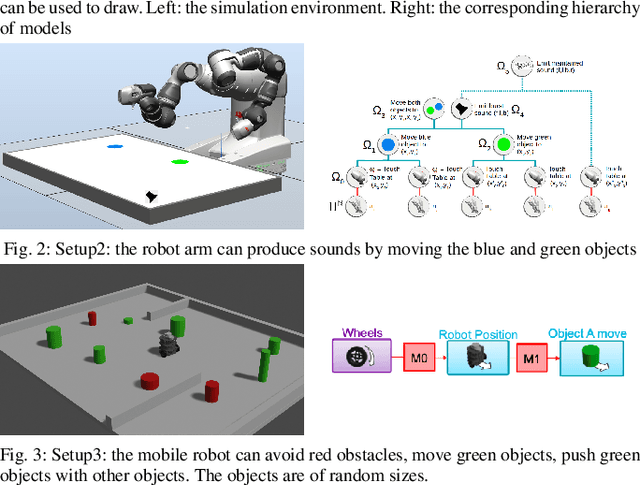
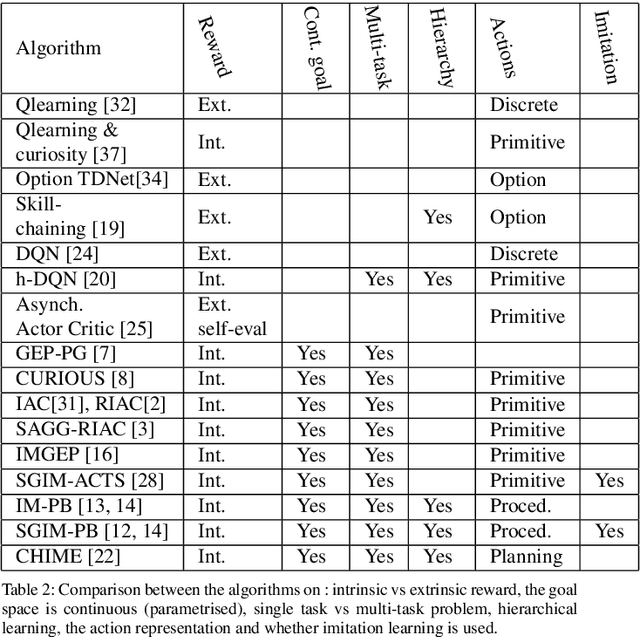
Multi-task learning by robots poses the challenge of the domain knowledge: complexity of tasks, complexity of the actions required, relationship between tasks for transfer learning. We demonstrate that this domain knowledge can be learned to address the challenges in life-long learning. Specifically, the hierarchy between tasks of various complexities is key to infer a curriculum from simple to composite tasks. We propose a framework for robots to learn sequences of actions of unbounded complexity in order to achieve multiple control tasks of various complexity. Our hierarchical reinforcement learning framework, named SGIM-SAHT, offers a new direction of research, and tries to unify partial implementations on robot arms and mobile robots. We outline our contributions to enable robots to map multiple control tasks to sequences of actions: representations of task dependencies, an intrinsically motivated exploration to learn task hierarchies, and active imitation learning. While learning the hierarchy of tasks, it infers its curriculum by deciding which tasks to explore first, how to transfer knowledge, and when, how and whom to imitate.
Human Activity Recognition (HAR) in Smart Homes
Dec 20, 2021Generally, Human Activity Recognition (HAR) consists of monitoring and analyzing the behavior of one or more persons in order to deduce their activity. In a smart home context, the HAR consists of monitoring daily activities of the residents. Thanks to this monitoring, a smart home can offer home assistance services to improve quality of life, autonomy and health of their residents, especially for elderly and dependent people.