 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fully Test-time Adaptation by Entropy Minimization
Jun 18, 2020

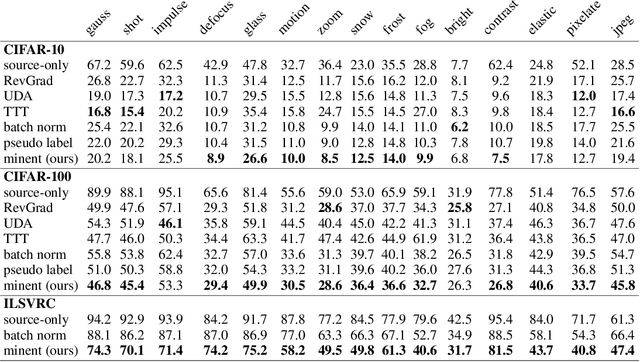

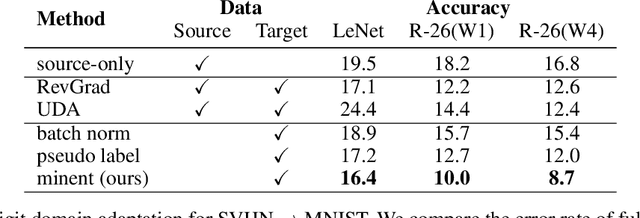
Faced with new and different data during testing, a model must adapt itself. We consider the setting of fully test-time adaptation, in which a supervised model confronts unlabeled test data from a different distribution, without the help of its labeled training data. We propose an entropy minimization approach for adaptation: we take the model's confidence as our objective as measured by the entropy of its predictions. During testing, we adapt the model by modulating its representation with affine transformations to minimize entropy. Our experiments show improved robustness to corruptions for image classification on CIFAR-10/100 and ILSVRC and demonstrate the feasibility of target-only domain adaptation for digit classification on MNIST and SVHN.
Frame-To-Frame Consistent Semantic Segmentation
Aug 27, 2020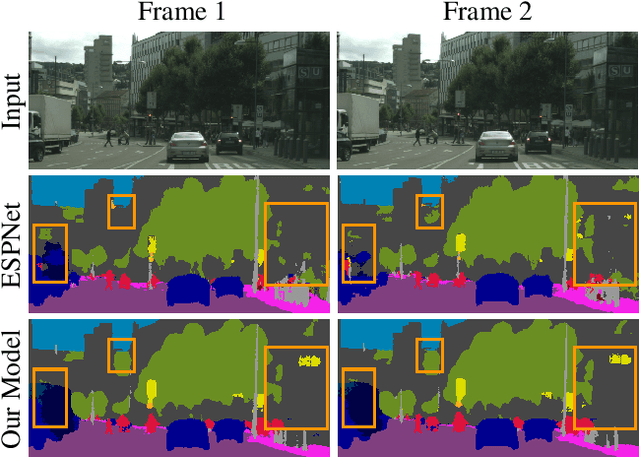
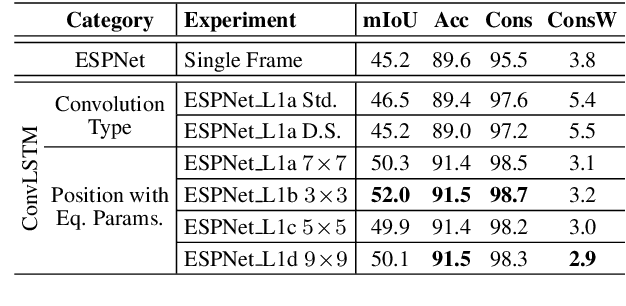
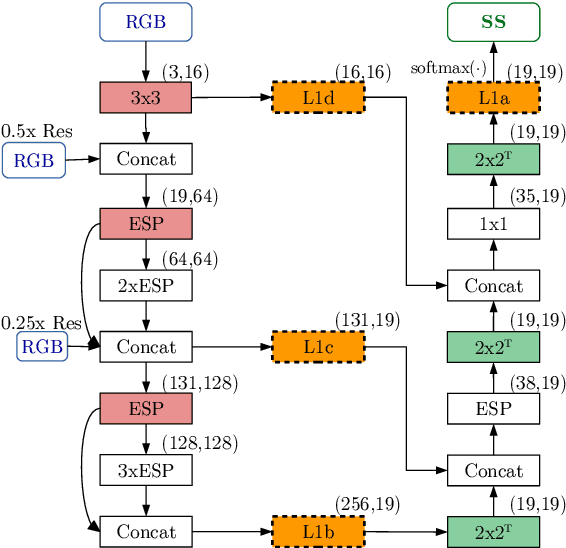
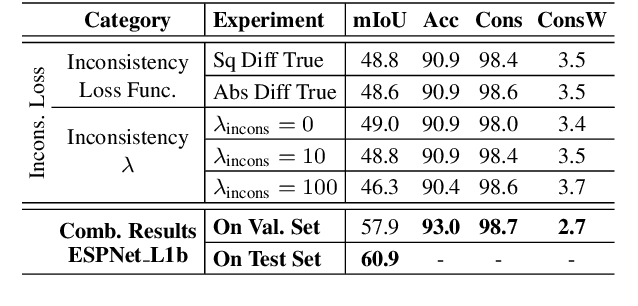
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing. Code and videos are available at https://github.com/mrebol/f2f-consistent-semantic-segmentation
Incorporating Relational Background Knowledge into Reinforcement Learning via Differentiable Inductive Logic Programming
Mar 23, 2020

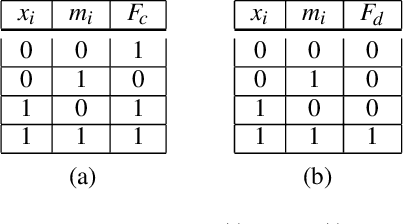
Relational Reinforcement Learning (RRL) can offers various desirable features. Most importantly, it allows for incorporating expert knowledge into the learning, and hence leading to much faster learning and better generalization compared to the standard deep reinforcement learning. However, most of the existing RRL approaches are either incapable of incorporating expert background knowledge (e.g., in the form of explicit predicate language) or are not able to learn directly from non-relational data such as image. In this paper, we propose a novel deep RRL based on a differentiable Inductive Logic Programming (ILP) that can effectively learn relational information from image and present the state of the environment as first order logic predicates. Additionally, it can take the expert background knowledge and incorporate it into the learning problem using appropriate predicates. The differentiable ILP allows an end to end optimization of the entire framework for learning the policy in RRL. We show the efficacy of this novel RRL framework using environments such as BoxWorld, GridWorld as well as relational reasoning for the Sort-of-CLEVR dataset.
A Study on Effects of Implicit and Explicit Language Model Information for DBLSTM-CTC Based Handwriting Recognition
Jul 31, 2020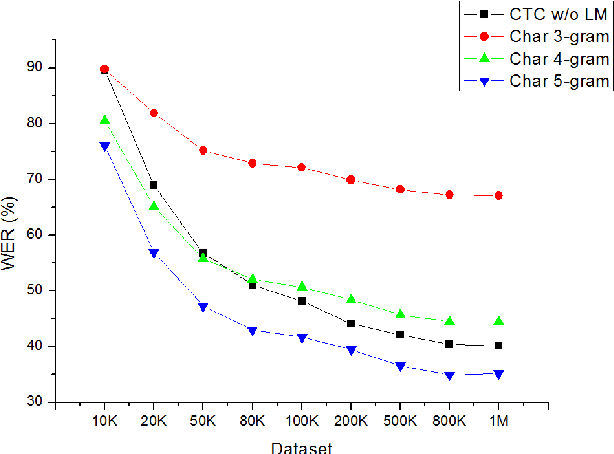


Deep Bidirectional Long Short-Term Memory (D-BLSTM) with a Connectionist Temporal Classification (CTC) output layer has been established as one of the state-of-the-art solutions for handwriting recognition. It is well known that the DBLSTM trained by using a CTC objective function will learn both local character image dependency for character modeling and long-range contextual dependency for implicit language modeling. In this paper, we study the effects of implicit and explicit language model information for DBLSTM-CTC based handwriting recognition by comparing the performance of using or without using an explicit language model in decoding. It is observed that even using one million lines of training sentences to train the DBLSTM, using an explicit language model is still helpful. To deal with such a large-scale training problem, a GPU-based training tool has been developed for CTC training of DBLSTM by using a mini-batch based epochwise Back Propagation Through Time (BPTT) algorithm.
Discretization-Aware Architecture Search
Jul 07, 2020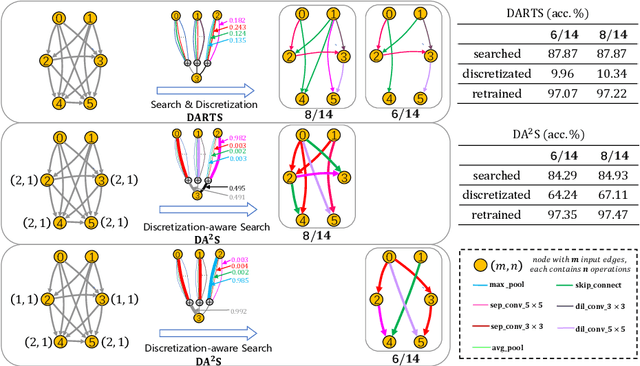
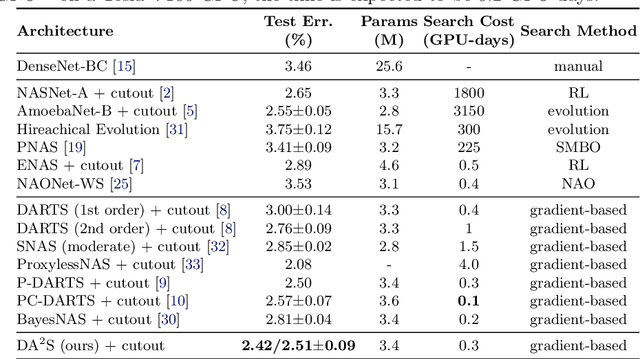


The search cost of neural architecture search (NAS) has been largely reduced by weight-sharing methods. These methods optimize a super-network with all possible edges and operations, and determine the optimal sub-network by discretization, \textit{i.e.}, pruning off weak candidates. The discretization process, performed on either operations or edges, incurs significant inaccuracy and thus the quality of the final architecture is not guaranteed. This paper presents discretization-aware architecture search (DA\textsuperscript{2}S), with the core idea being adding a loss term to push the super-network towards the configuration of desired topology, so that the accuracy loss brought by discretization is largely alleviated. Experiments on standard image classification benchmarks demonstrate the superiority of our approach, in particular, under imbalanced target network configurations that were not studied before.
PointMixup: Augmentation for Point Clouds
Aug 14, 2020
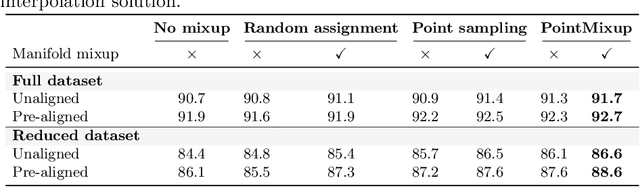
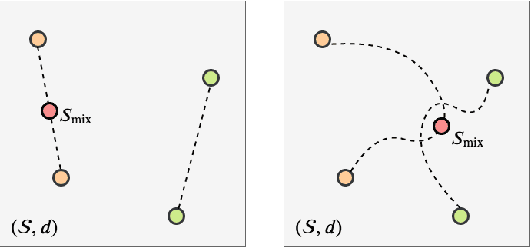
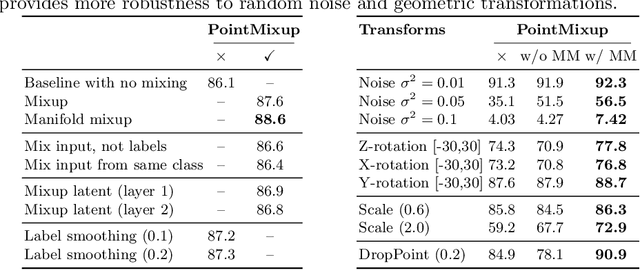
This paper introduces data augmentation for point clouds by interpolation between examples. Data augmentation by interpolation has shown to be a simple and effective approach in the image domain. Such a mixup is however not directly transferable to point clouds, as we do not have a one-to-one correspondence between the points of two different objects. In this paper, we define data augmentation between point clouds as a shortest path linear interpolation. To that end, we introduce PointMixup, an interpolation method that generates new examples through an optimal assignment of the path function between two point clouds. We prove that our PointMixup finds the shortest path between two point clouds and that the interpolation is assignment invariant and linear. With the definition of interpolation, PointMixup allows to introduce strong interpolation-based regularizers such as mixup and manifold mixup to the point cloud domain. Experimentally, we show the potential of PointMixup for point cloud classification, especially when examples are scarce, as well as increased robustness to noise and geometric transformations to points. The code for PointMixup and the experimental details are publicly available.
Decision Support System for Detection and Classification of Skin Cancer using CNN
Dec 09, 2019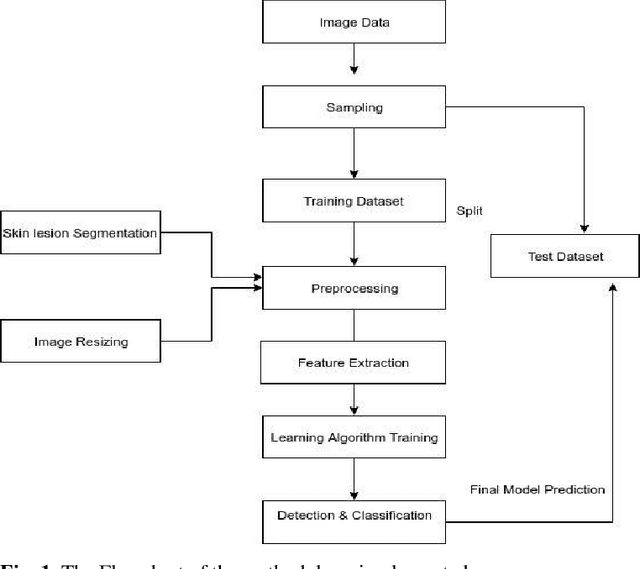
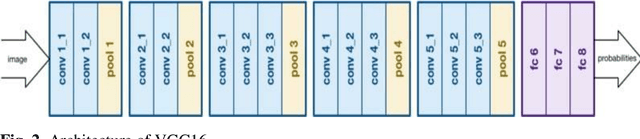
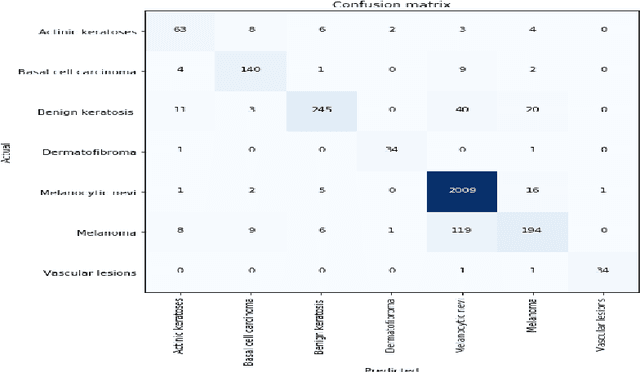
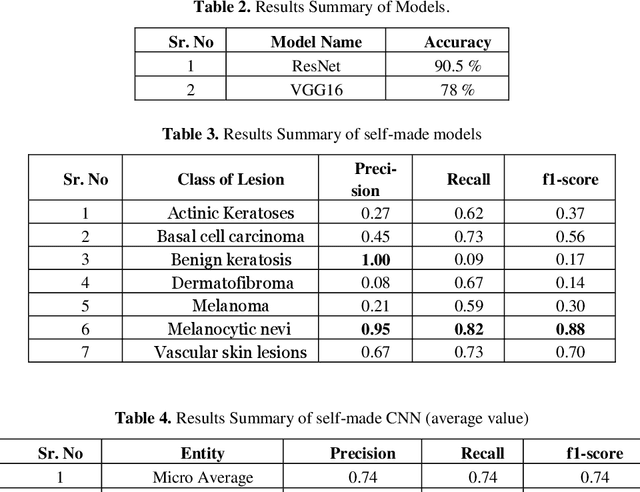
Skin Cancer is one of the most deathful of all the cancers. It is bound to spread to different parts of the body on the off chance that it is not analyzed and treated at the beginning time. It is mostly because of the abnormal growth of skin cells, often develops when the body is exposed to sunlight. The Detection Furthermore, the characterization of skin malignant growth in the beginning time is a costly and challenging procedure. It is classified where it develops and its cell type. High Precision and recall are required for the classification of lesions. The paper aims to use MNIST HAM-10000 dataset containing dermoscopy images. The objective is to propose a system that detects skin cancer and classifies it in different classes by using the Convolution Neural Network. The diagnosing methodology uses Image processing and deep learning model. The dermoscopy image of skin cancer taken, undergone various techniques to remove the noise and picture resolution. The image count is also increased by using various image augmentation techniques. In the end, the Transfer Learning method is used to increase the classification accuracy of the images further. Our CNN model gave a weighted average Precision of 0.88, a weighted Recall average of 0.74, and a weighted f1-score of 0.77. The transfer learning approach applied using ResNet model yielded an accuracy of 90.51%
The Effect of Visual Design in Image Classification
Aug 20, 2019
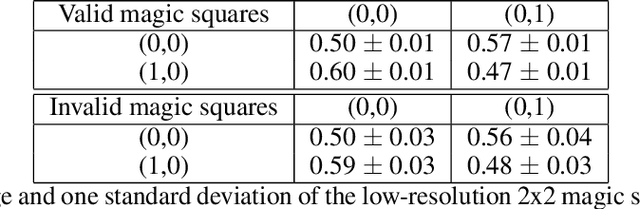
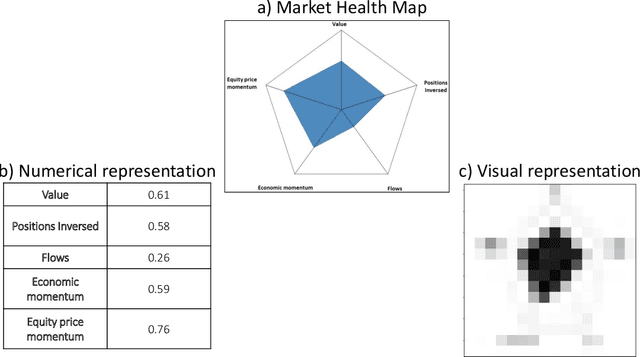
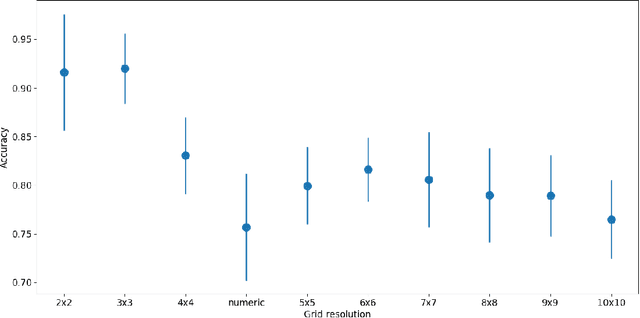
Financial companies continuously analyze the state of the markets to rethink and adjust their investment strategies. While the analysis is done on the digital form of data, decisions are often made based on graphical representations in white papers or presentation slides. In this study, we examine whether binary decisions are better to be decided based on the numeric or the visual representation of the same data. Using two data sets, a matrix of numerical data with spatial dependencies and financial data describing the state of the S&P index, we compare the results of supervised classification based on the original numerical representation and the visual transformation of the same data. We show that, for these data sets, the visual transformation results in higher predictability skill compared to the original form of the data. We suggest thinking of the visual representation of numeric data, effectively, as a combination of dimensional reduction and feature engineering techniques. In particular, if the visual layout encapsulates the full complexity of the data. In this view, thoughtful visual design can guard against overfitting, or introduce new features -- all of which benefit the learning process, and effectively lead to better recognition of meaningful patterns.
Generative Adversarial Text to Image Synthesis
Jun 05, 2016
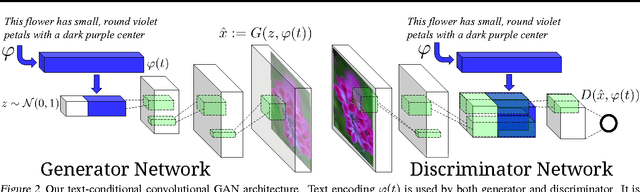

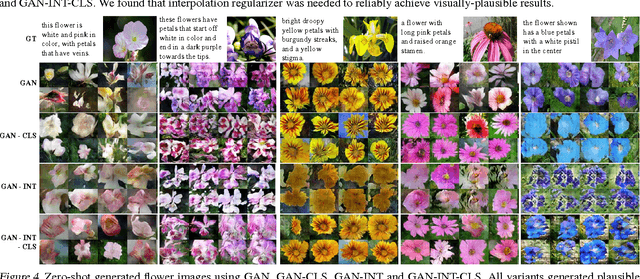
Automatic synthesis of realistic images from text would be interesting and useful, but current AI systems are still far from this goal. However, in recent years generic and powerful recurrent neural network architectures have been developed to learn discriminative text feature representations. Meanwhile, deep convolutional generative adversarial networks (GANs) have begun to generate highly compelling images of specific categories, such as faces, album covers, and room interiors. In this work, we develop a novel deep architecture and GAN formulation to effectively bridge these advances in text and image model- ing, translating visual concepts from characters to pixels. We demonstrate the capability of our model to generate plausible images of birds and flowers from detailed text descriptions.
Class-Specific Blind Deconvolutional Phase Retrieval Under a Generative Prior
Feb 28, 2020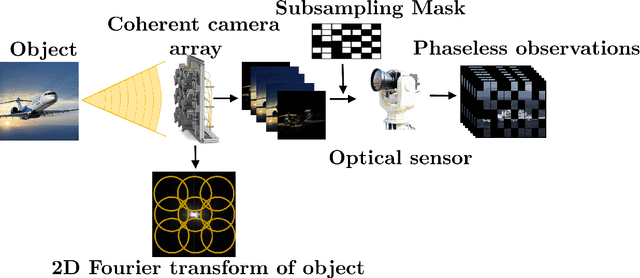
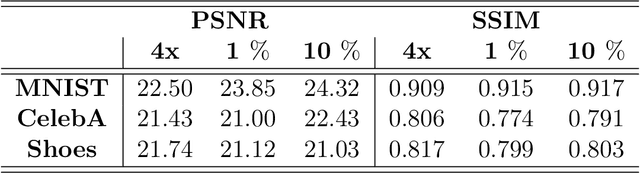


In this paper, we consider the highly ill-posed problem of jointly recovering two real-valued signals from the phaseless measurements of their circular convolution. The problem arises in various imaging modalities such as Fourier ptychography, X-ray crystallography, and in visible light communication. We propose to solve this inverse problem using alternating gradient descent algorithm under two pretrained deep generative networks as priors; one is trained on sharp images and the other on blur kernels. The proposed recovery algorithm strives to find a sharp image and a blur kernel in the range of the respective pre-generators that \textit{best} explain the forward measurement model. In doing so, we are able to reconstruct quality image estimates. Moreover, the numerics show that the proposed approach performs well on the challenging measurement models that reflect the physically realizable imaging systems and is also robust to noise