 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Inpainting Using Directional Tensor Product Complex Tight Framelets
Jul 11, 2014

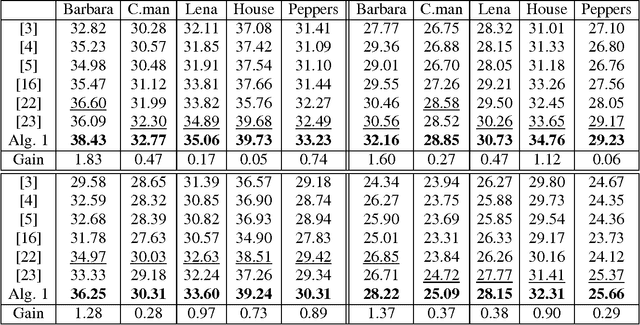
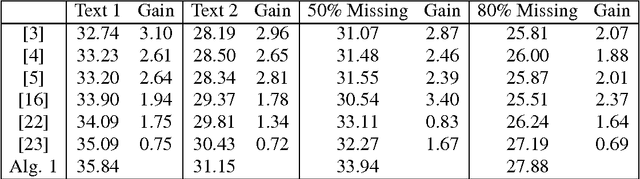

In this paper we are particularly interested in the image inpainting problem using directional complex tight wavelet frames. Under the assumption that frame coefficients of images are sparse, several iterative thresholding algorithms for the image inpainting problem have been proposed in the literature. The outputs of such iterative algorithms are closely linked to solutions of several convex minimization models using the balanced approach which simultaneously combines the $l_1$-regularization for sparsity of frame coefficients and the $l_2$-regularization for smoothness of the solution. Due to the redundancy of a tight frame, elements of a tight frame could be highly correlated and therefore, their corresponding frame coefficients of an image are expected to close to each other. This is called the grouping effect in statistics. In this paper, we establish the grouping effect property for frame-based convex minimization models using the balanced approach. This result on grouping effect partially explains the effectiveness of models using the balanced approach for several image restoration problems. Inspired by recent development on directional tensor product complex tight framelets (TP-CTFs) and their impressive performance for the image denoising problem, in this paper we propose an iterative thresholding algorithm using a single tight frame derived from TP-CTFs for the image inpainting problem. Experimental results show that our proposed algorithm can handle well both cartoons and textures simultaneously and performs comparably and often better than several well-known frame-based iterative thresholding algorithms for the image inpainting problem without noise. For the image inpainting problem with additive zero-mean i.i.d. Gaussian noise, our proposed algorithm using TP-CTFs performs superior than other known state-of-the-art frame-based image inpainting algorithms.
Axiom-based Grad-CAM: Towards Accurate Visualization and Explanation of CNNs
Aug 08, 2020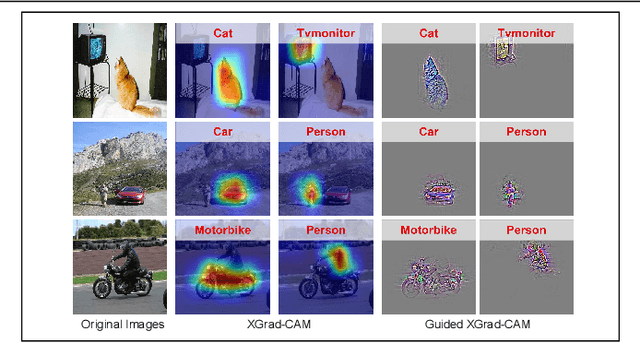
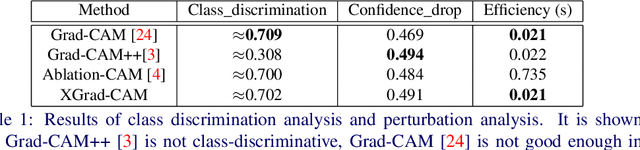
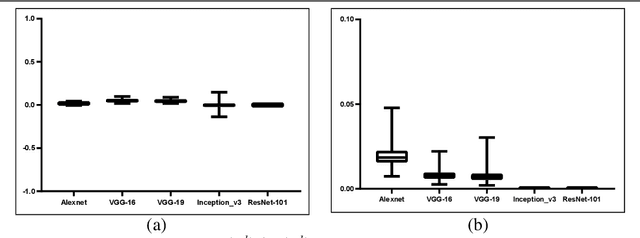
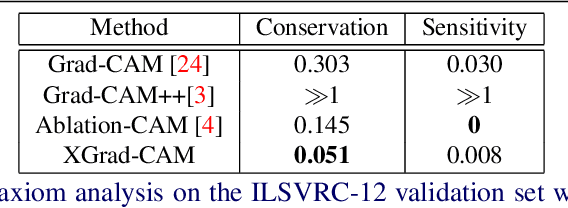
To have a better understanding and usage of Convolution Neural Networks (CNNs), the visualization and interpretation of CNNs has attracted increasing attention in recent years. In particular, several Class Activation Mapping (CAM) methods have been proposed to discover the connection between CNN's decision and image regions. In spite of the reasonable visualization, lack of clear and sufficient theoretical support is the main limitation of these methods. In this paper, we introduce two axioms -- Conservation and Sensitivity -- to the visualization paradigm of the CAM methods. Meanwhile, a dedicated Axiom-based Grad-CAM (XGrad-CAM) is proposed to satisfy these axioms as much as possible. Experiments demonstrate that XGrad-CAM is an enhanced version of Grad-CAM in terms of conservation and sensitivity. It is able to achieve better visualization performance than Grad-CAM, while also be class-discriminative and easy-to-implement compared with Grad-CAM++ and Ablation-CAM. The code is available at https://github.com/Fu0511/XGrad-CAM.
Vision Meets Wireless Positioning: Effective Person Re-identification with Recurrent Context Propagation
Sep 04, 2020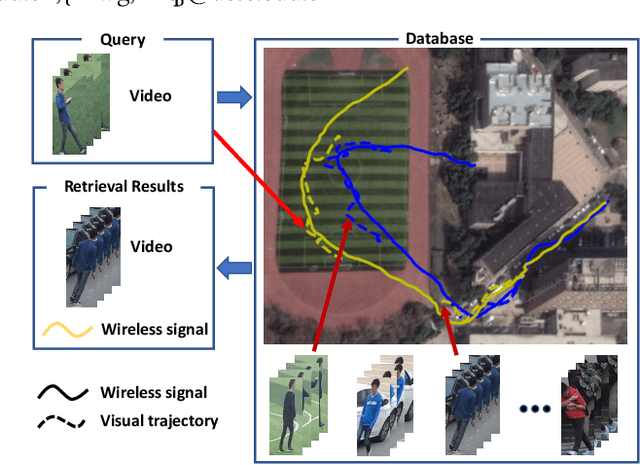


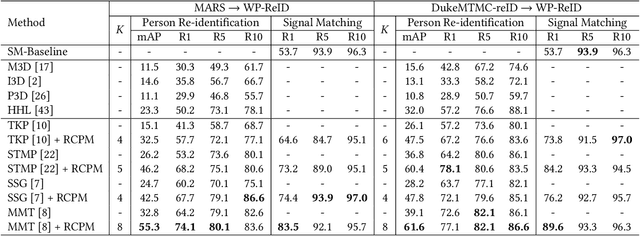
Existing person re-identification methods rely on the visual sensor to capture the pedestrians. The image or video data from visual sensor inevitably suffers the occlusion and dramatic variations of pedestrian postures, which degrades the re-identification performance and further limits its application to the open environment. On the other hand, for most people, one of the most important carry-on items is the mobile phone, which can be sensed by WiFi and cellular networks in the form of a wireless positioning signal. Such signal is robust to the pedestrian occlusion and visual appearance change, but suffers some positioning error. In this work, we approach person re-identification with the sensing data from both vision and wireless positioning. To take advantage of such cross-modality cues, we propose a novel recurrent context propagation module that enables information to propagate between visual data and wireless positioning data and finally improves the matching accuracy. To evaluate our approach, we contribute a new Wireless Positioning Person Re-identification (WP-ReID) dataset. Extensive experiments are conducted and demonstrate the effectiveness of the proposed algorithm. Code will be released at https://github.com/yolomax/WP-ReID.
I Like to Move It: 6D Pose Estimation as an Action Decision Process
Sep 26, 2020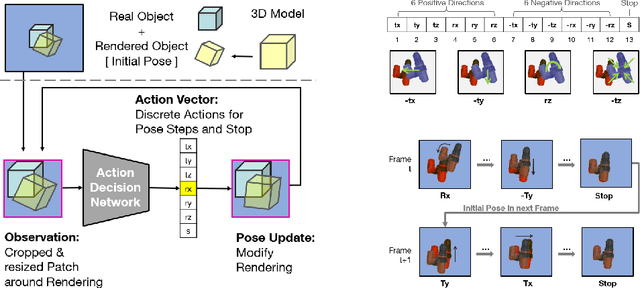
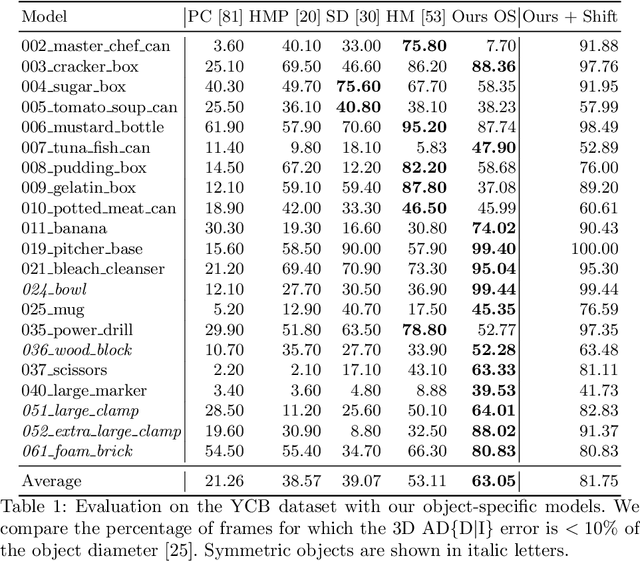
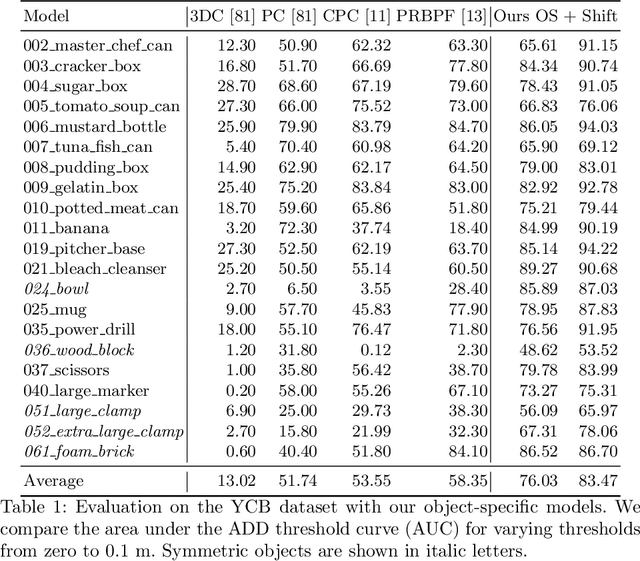
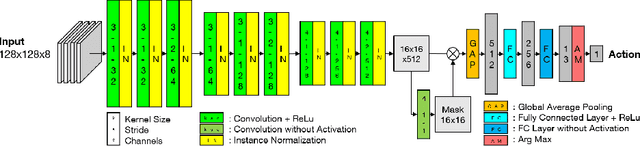
Object pose estimation is an integral part of robot vision and augmented reality. Robust and accurate pose prediction of both object rotation and translation is a crucial element to enable precise and safe human-machine interactions and to allow visualization in mixed reality. Previous 6D pose estimation methods treat the problem either as a regression task or discretize the pose space to classify. We reformulate the problem as an action decision process where an initial pose is updated in incremental discrete steps that sequentially move a virtual 3D rendering towards the correct solution. A neural network estimates likely moves from a single RGB image iteratively and determines so an acceptable final pose. In comparison to previous approaches that learn an object-specific pose embedding, a decision process allows for a lightweight architecture while it naturally generalizes to unseen objects. Moreover, the coherent action for process termination enables dynamic reduction of the computation cost if there are insignificant changes in a video sequence. While other methods only provide a static inference time, we can thereby automatically increase the runtime depending on the object motion. We evaluate robustness and accuracy of our action decision network on video scenes with known and unknown objects and show how this can improve the state-of-the-art on YCB videos significantly.
Paying Per-label Attention for Multi-label Extraction from Radiology Reports
Jul 31, 2020Training medical image analysis models requires large amounts of expertly annotated data which is time-consuming and expensive to obtain. Images are often accompanied by free-text radiology reports which are a rich source of information. In this paper, we tackle the automated extraction of structured labels from head CT reports for imaging of suspected stroke patients, using deep learning. Firstly, we propose a set of 31 labels which correspond to radiographic findings (e.g. hyperdensity) and clinical impressions (e.g. haemorrhage) related to neurological abnormalities. Secondly, inspired by previous work, we extend existing state-of-the-art neural network models with a label-dependent attention mechanism. Using this mechanism and simple synthetic data augmentation, we are able to robustly extract many labels with a single model, classified according to the radiologist's reporting (positive, uncertain, negative). This approach can be used in further research to effectively extract many labels from medical text.
Pixel-Level Self-Paced Learning for Super-Resolution
Mar 09, 2020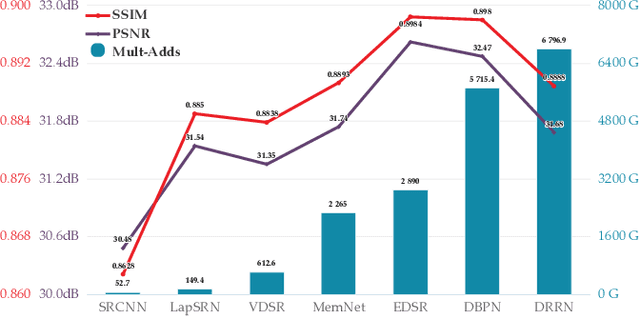
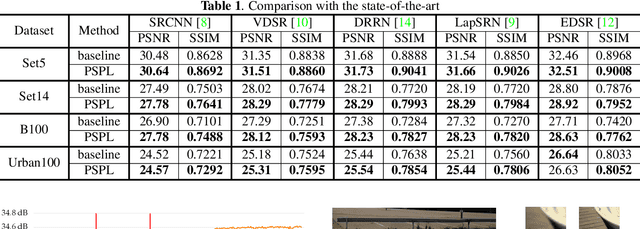
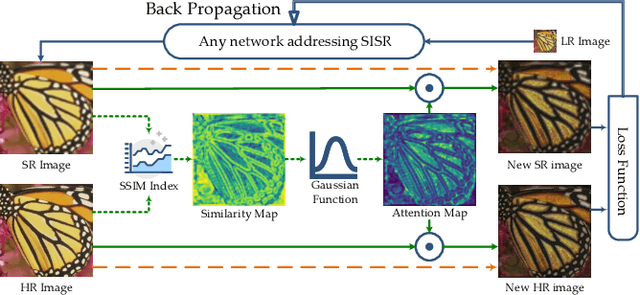
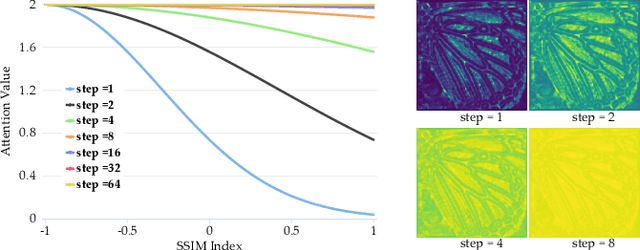
Recently, lots of deep networks are proposed to improve the quality of predicted super-resolution (SR) images, due to its widespread use in several image-based fields. However, with these networks being constructed deeper and deeper, they also cost much longer time for training, which may guide the learners to local optimization. To tackle this problem, this paper designs a training strategy named Pixel-level Self-Paced Learning (PSPL) to accelerate the convergence velocity of SISR models. PSPL imitating self-paced learning gives each pixel in the predicted SR image and its corresponding pixel in ground truth an attention weight, to guide the model to a better region in parameter space. Extensive experiments proved that PSPL could speed up the training of SISR models, and prompt several existing models to obtain new better results. Furthermore, the source code is available at https://github.com/Elin24/PSPL.
Refinements in Motion and Appearance for Online Multi-Object Tracking
Mar 17, 2020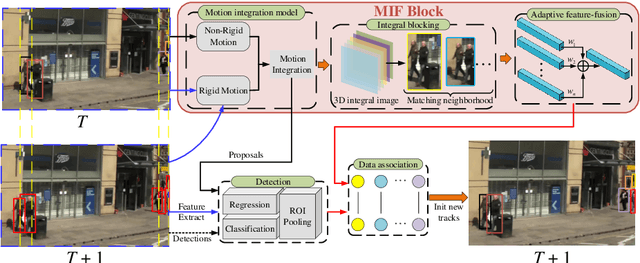
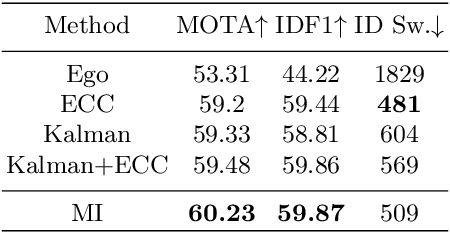
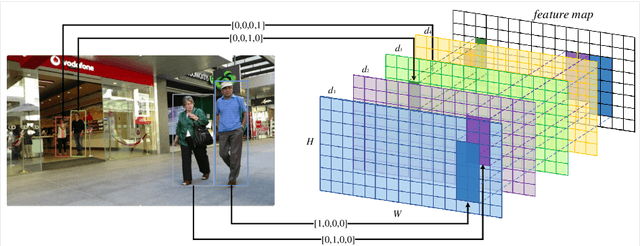
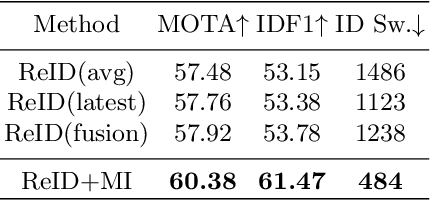
Modern multi-object tracking (MOT) system usually involves separated modules, such as motion model for location and appearance model for data association. However, the compatible problems within both motion and appearance models are always ignored. In this paper, a general architecture named as MIF is presented by seamlessly blending the Motion integration, three-dimensional(3D) Integral image and adaptive appearance feature Fusion. Since the uncertain pedestrian and camera motions are usually handled separately, the integrated motion model is designed using our defined intension of camera motion. Specifically, a 3D integral image based spatial blocking method is presented to efficiently cut useless connections between trajectories and candidates with spatial constraints. Then the appearance model and visibility prediction are jointly built. Considering scale, pose and visibility, the appearance features are adaptively fused to overcome the feature misalignment problem. Our MIF based tracker (MIFT) achieves the state-of-the-art accuracy with 60.1 MOTA on both MOT16&17 challenges.
Targeted Mismatch Adversarial Attack: Query with a Flower to Retrieve the Tower
Aug 24, 2019
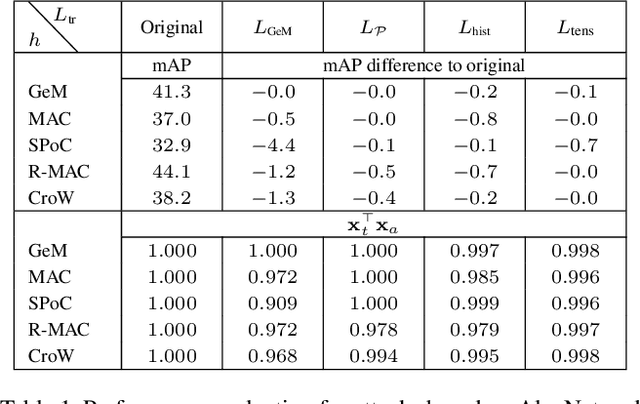
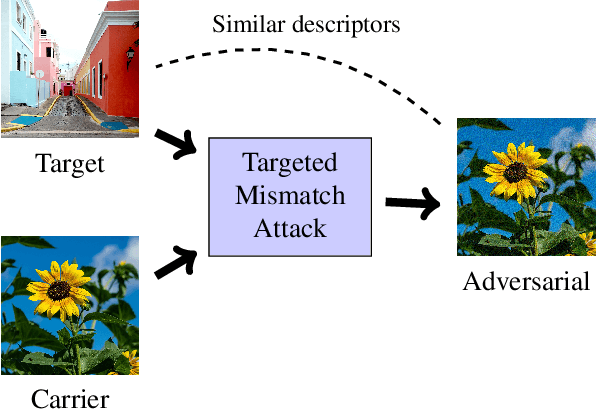
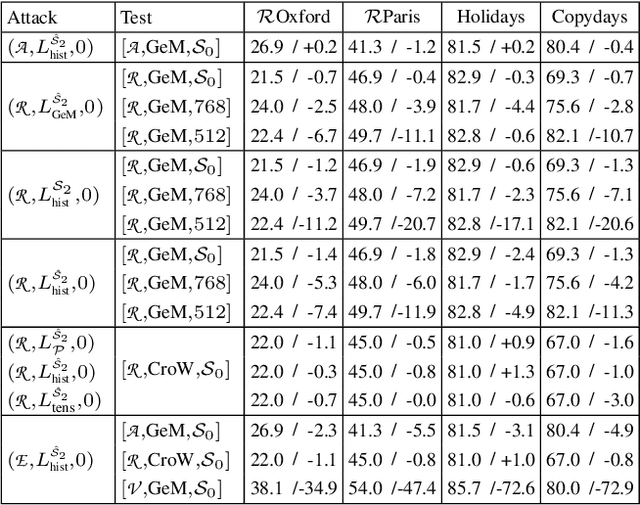
Access to online visual search engines implies sharing of private user content - the query images. We introduce the concept of targeted mismatch attack for deep learning based retrieval systems to generate an adversarial image to conceal the query image. The generated image looks nothing like the user intended query, but leads to identical or very similar retrieval results. Transferring attacks to fully unseen networks is challenging. We show successful attacks to partially unknown systems, by designing various loss functions for the adversarial image construction. These include loss functions, for example, for unknown global pooling operation or unknown input resolution by the retrieval system. We evaluate the attacks on standard retrieval benchmarks and compare the results retrieved with the original and adversarial image.
Backdoor Attacks on Facial Recognition in the Physical World
Jun 25, 2020
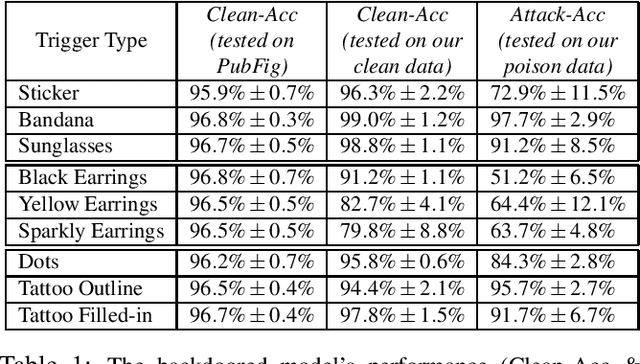

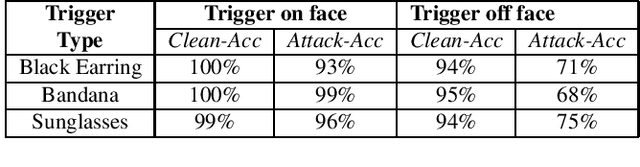
Backdoor attacks embed hidden malicious behaviors inside deep neural networks (DNNs) that are only activated when a specific "trigger" is present on some input to the model. A variety of these attacks have been successfully proposed and evaluated, generally using digitally generated patterns or images as triggers. Despite significant prior work on the topic, a key question remains unanswered: "can backdoor attacks be physically realized in the real world, and what limitations do attackers face in executing them?" In this paper, we present results of a detailed study on DNN backdoor attacks in the physical world, specifically focused on the task of facial recognition. We take 3205 photographs of 10 volunteers in a variety of settings and backgrounds and train a facial recognition model using transfer learning from VGGFace. We evaluate the effectiveness of 9 accessories as potential triggers, and analyze impact from external factors such as lighting and image quality. First, we find that triggers vary significantly in efficacy and a key factor is that facial recognition models are heavily tuned to features on the face and less so to features around the periphery. Second, the efficacy of most trigger objects is. negatively impacted by lower image quality but unaffected by lighting. Third, most triggers suffer from false positives, where non-trigger objects unintentionally activate the backdoor. Finally, we evaluate 4 backdoor defenses against physical backdoors. We show that they all perform poorly because physical triggers break key assumptions they made based on triggers in the digital domain. Our key takeaway is that implementing physical backdoors is much more challenging than described in literature for both attackers and defenders and much more work is necessary to understand how backdoors work in the real world.
Memory-Efficient Incremental Learning Through Feature Adaptation
Apr 01, 2020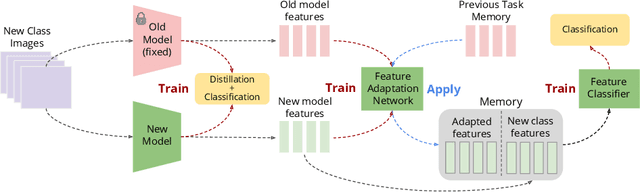
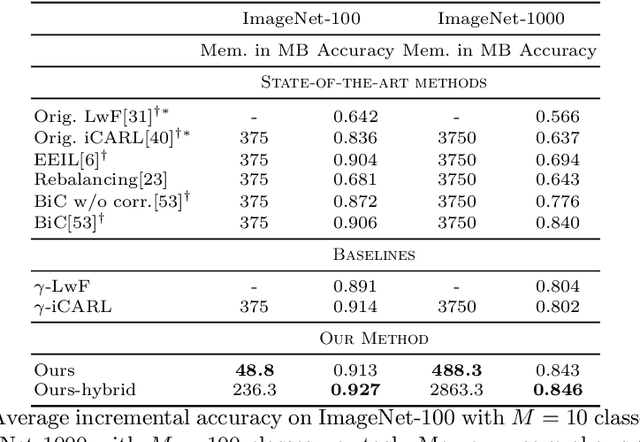
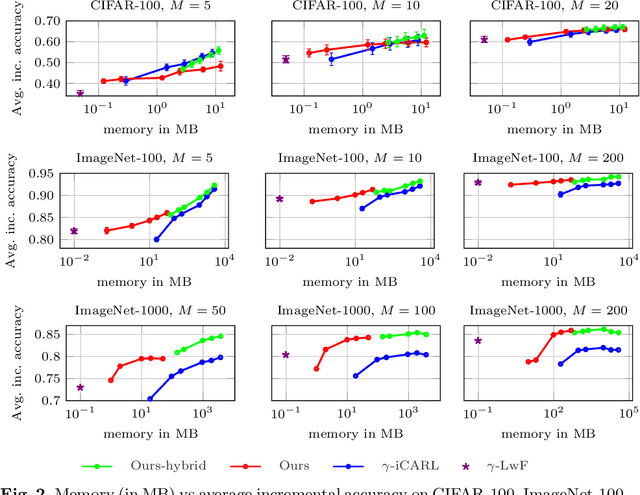
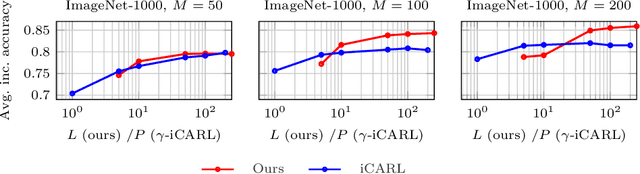
In this work we introduce an approach for incremental learning, which preserves feature descriptors instead of images unlike most existing work. Keeping such low-dimensional embeddings instead of images reduces the memory footprint significantly. We assume that the model is updated incrementally for new classes as new data becomes available sequentially. This requires adapting the previously stored feature vectors to the updated feature space without having access to the corresponding images. Feature adaptation is learned with a multi-layer perceptron, which is trained on feature pairs of an image corresponding to the outputs of the original and updated network. We validate experimentally that such a transformation generalizes well to the features of the previous set of classes, and maps features to a discriminative subspace in the feature space. As a result, the classifier is optimized jointly over new and old classes without requiring old class images. Experimental results show that our method achieves state-of-the-art classification accuracy in incremental learning benchmarks, while having at least an order of magnitude lower memory footprint compared to image preserving strategies.