 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TP-LSD: Tri-Points Based Line Segment Detector
Sep 11, 2020
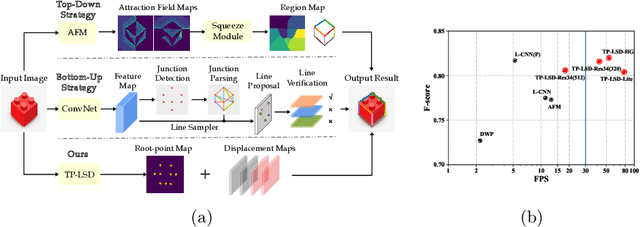
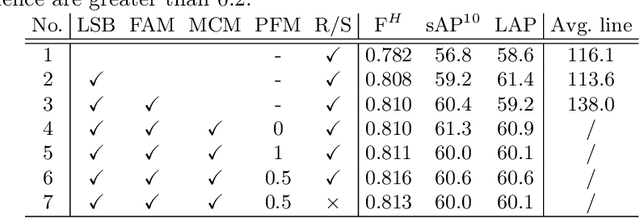

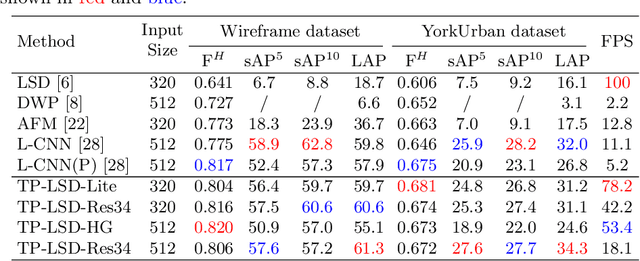
This paper proposes a novel deep convolutional model, Tri-Points Based Line Segment Detector (TP-LSD), to detect line segments in an image at real-time speed. The previous related methods typically use the two-step strategy, relying on either heuristic post-process or extra classifier. To realize one-step detection with a faster and more compact model, we introduce the tri-points representation, converting the line segment detection to the end-to-end prediction of a root-point and two endpoints for each line segment. TP-LSD has two branches: tri-points extraction branch and line segmentation branch. The former predicts the heat map of root-points and the two displacement maps of endpoints. The latter segments the pixels on straight lines out from background. Moreover, the line segmentation map is reused in the first branch as structural prior. We propose an additional novel evaluation metric and evaluate our method on Wireframe and YorkUrban datasets, demonstrating not only the competitive accuracy compared to the most recent methods, but also the real-time run speed up to 78 FPS with the $320\times 320$ input.
* Accepted by ECCV 2020
TailorGAN: Making User-Defined Fashion Designs
Jan 17, 2020

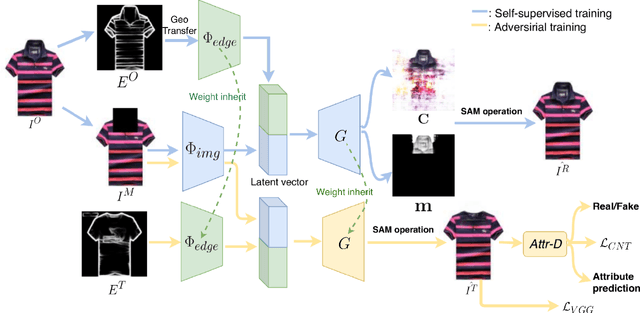

Attribute editing has become an important and emerging topic of computer vision. In this paper, we consider a task: given a reference garment image A and another image B with target attribute (collar/sleeve), generate a photo-realistic image which combines the texture from reference A and the new attribute from reference B. The highly convoluted attributes and the lack of paired data are the main challenges to the task. To overcome those limitations, we propose a novel self-supervised model to synthesize garment images with disentangled attributes (e.g., collar and sleeves) without paired data. Our method consists of a reconstruction learning step and an adversarial learning step. The model learns texture and location information through reconstruction learning. And, the model's capability is generalized to achieve single-attribute manipulation by adversarial learning. Meanwhile, we compose a new dataset, named GarmentSet, with annotation of landmarks of collars and sleeves on clean garment images. Extensive experiments on this dataset and real-world samples demonstrate that our method can synthesize much better results than the state-of-the-art methods in both quantitative and qualitative comparisons.
* fashion
Contextual Grounding of Natural Language Entities in Images
Nov 05, 2019
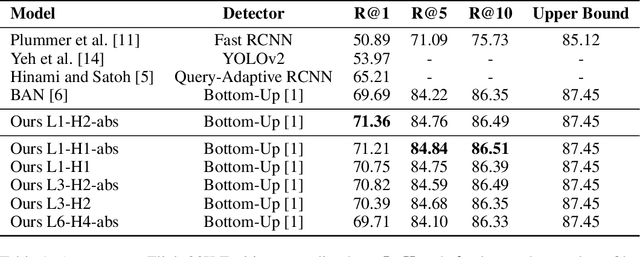
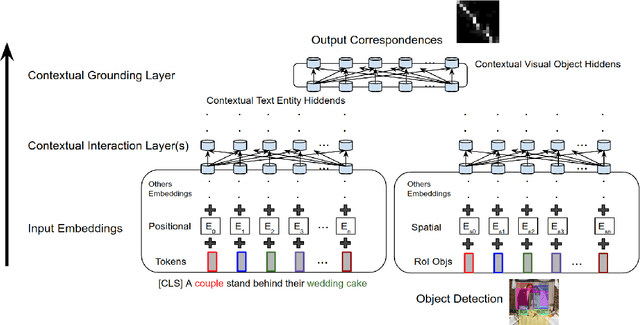
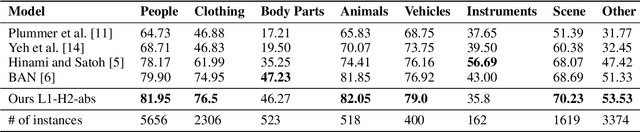
In this paper, we introduce a contextual grounding approach that captures the context in corresponding text entities and image regions to improve the grounding accuracy. Specifically, the proposed architecture accepts pre-trained text token embeddings and image object features from an off-the-shelf object detector as input. Additional encoding to capture the positional and spatial information can be added to enhance the feature quality. There are separate text and image branches facilitating respective architectural refinements for different modalities. The text branch is pre-trained on a large-scale masked language modeling task while the image branch is trained from scratch. Next, the model learns the contextual representations of the text tokens and image objects through layers of high-order interaction respectively. The final grounding head ranks the correspondence between the textual and visual representations through cross-modal interaction. In the evaluation, we show that our model achieves the state-of-the-art grounding accuracy of 71.36% over the Flickr30K Entities dataset. No additional pre-training is necessary to deliver competitive results compared with related work that often requires task-agnostic and task-specific pre-training on cross-modal dadasets. The implementation is publicly available at https://gitlab.com/necla-ml/grounding.
Understanding 3D CNN Behavior for Alzheimer's Disease Diagnosis from Brain PET Scan
Dec 26, 2019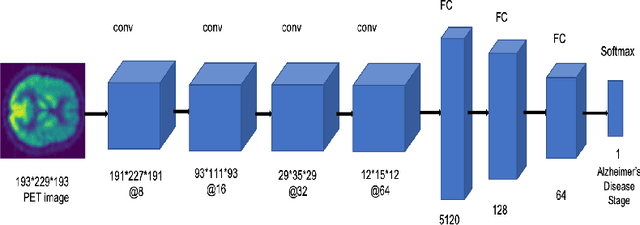

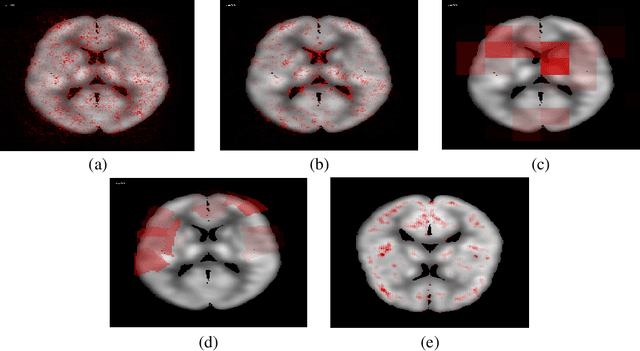
In recent days, Convolutional Neural Networks (CNN) have demonstrated impressive performance in medical image analysis. However, there is a lack of clear understanding of why and how the Convolutional Neural Network performs so well for image analysis task. How CNN analyzes an image and discriminates among samples of different classes are usually considered as non-transparent. As a result, it becomes difficult to apply CNN based approaches in clinical procedures and automated disease diagnosis systems. In this paper, we consider this issue and work on visualizing and understanding the decision of Convolutional Neural Network for Alzheimer's Disease (AD) Diagnosis. We develop a 3D deep convolutional neural network for AD diagnosis using brain PET scans and propose using five visualizations techniques - Sensitivity Analysis (Backpropagation), Guided Backpropagation, Occlusion, Brain Area Occlusion, and Layer-wise Relevance Propagation (LRP) to understand the decision of the CNN by highlighting the relevant areas in the PET data.
Attention Mechanism Enhanced Kernel Prediction Networks for Denoising of Burst Images
Oct 18, 2019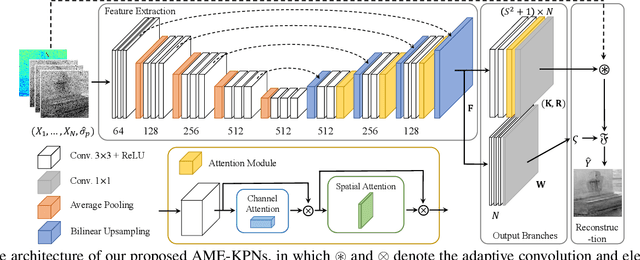
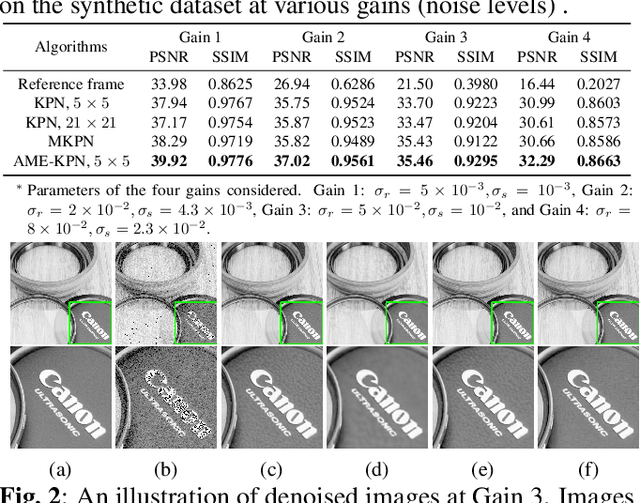
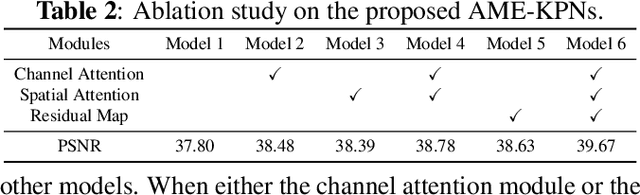
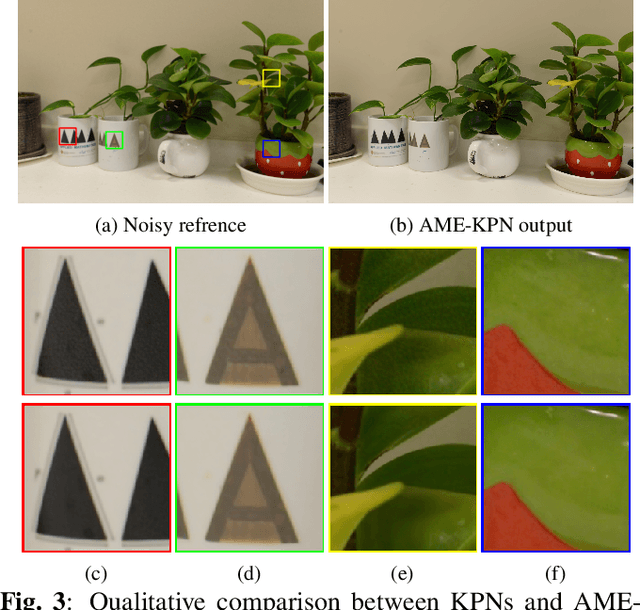
Deep learning based image denoising methods have been extensively investigated. In this paper, attention mechanism enhanced kernel prediction networks (AME-KPNs) are proposed for burst image denoising, in which, nearly cost-free attention modules are adopted to first refine the feature maps and to further make a full use of the inter-frame and intra-frame redundancies within the whole image burst. The proposed AME-KPNs output per-pixel spatially-adaptive kernels, residual maps and corresponding weight maps, in which, the predicted kernels roughly restore clean pixels at their corresponding locations via an adaptive convolution operation, and subsequently, residuals are weighted and summed to compensate the limited receptive field of predicted kernels. Simulations and real-world experiments are conducted to illustrate the robustness of the proposed AME-KPNs in burst image denoising.
Weakly- and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation
Oct 05, 2015
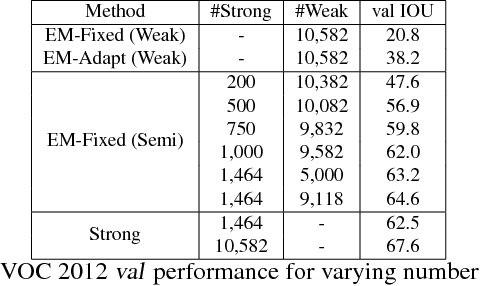
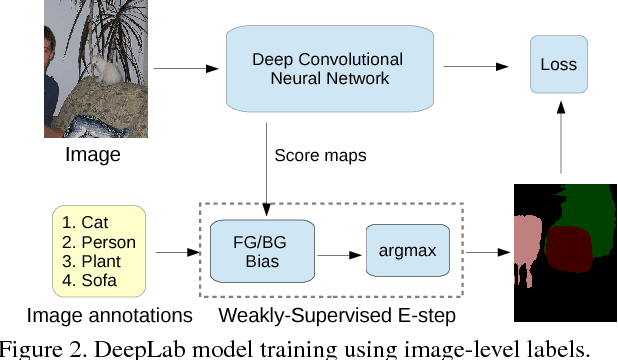
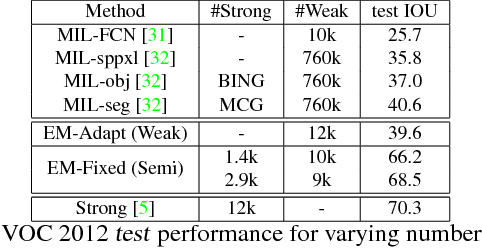
Deep convolutional neural networks (DCNNs) trained on a large number of images with strong pixel-level annotations have recently significantly pushed the state-of-art in semantic image segmentation. We study the more challenging problem of learning DCNNs for semantic image segmentation from either (1) weakly annotated training data such as bounding boxes or image-level labels or (2) a combination of few strongly labeled and many weakly labeled images, sourced from one or multiple datasets. We develop Expectation-Maximization (EM) methods for semantic image segmentation model training under these weakly supervised and semi-supervised settings. Extensive experimental evaluation shows that the proposed techniques can learn models delivering competitive results on the challenging PASCAL VOC 2012 image segmentation benchmark, while requiring significantly less annotation effort. We share source code implementing the proposed system at https://bitbucket.org/deeplab/deeplab-public.
Risk-Aware Planning and Assignment for Ground Vehicles using Uncertain Perception from Aerial Vehicles
Mar 25, 2020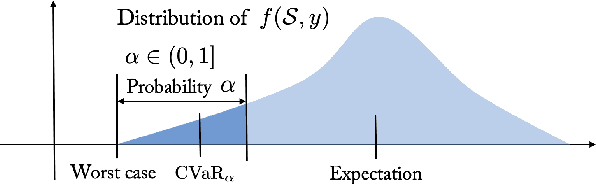
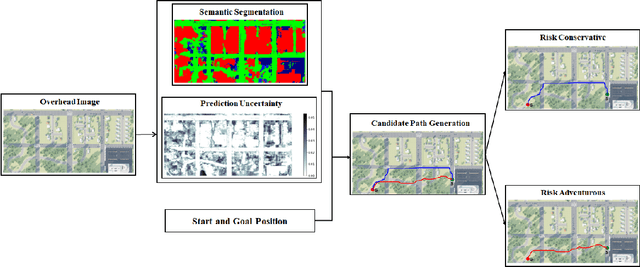
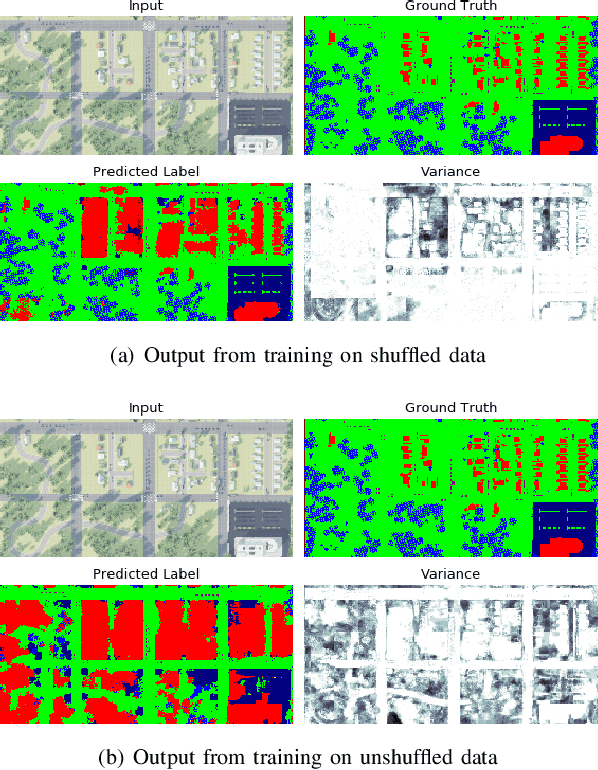
We propose a risk-aware framework for multi-robot, multi-demand assignment and planning in unknown environments. Our motivation is disaster response and search-and-rescue scenarios where ground vehicles must reach demand locations as soon as possible. We consider a setting where the terrain information is available only in the form of an aerial, georeferenced image. Deep learning techniques can be used for semantic segmentation of the aerial image to create a cost map for safe ground robot navigation. Such segmentation may still be noisy. Hence, we present a joint planning and perception framework that accounts for the risk introduced due to noisy perception. Our contributions are two-fold: (i) we show how to use Bayesian deep learning techniques to extract risk at the perception level; and (ii) use a risk-theoretical measure, CVaR, for risk-aware planning and assignment. The pipeline is theoretically established, then empirically analyzed through two datasets. We find that accounting for risk at both levels produces quantifiably safer paths and assignments.
Multi-stage transfer learning for lung segmentation using portable X-ray devices for patients with COVID-19
Oct 30, 2020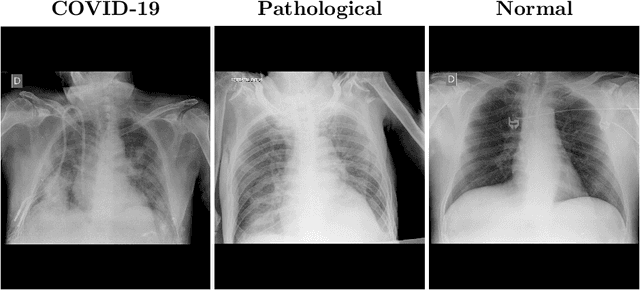
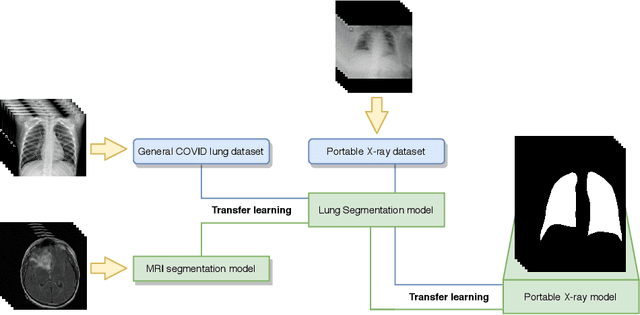

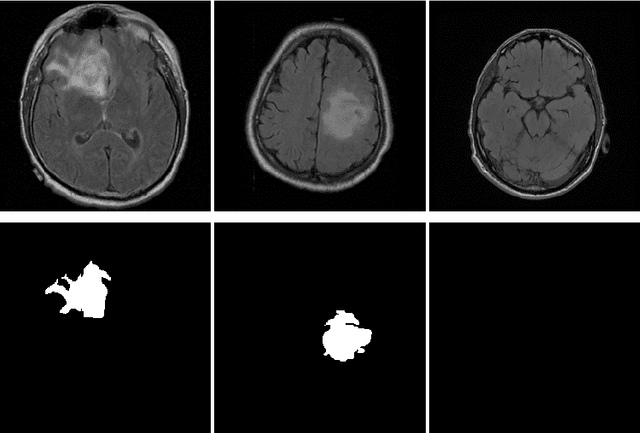
In 2020, the SARS-CoV-2 virus causes a global pandemic of the new human coronavirus disease COVID-19. This pathogen primarily infects the respiratory system of the afflicted, usually resulting in pneumonia and in a severe case of acute respiratory distress syndrome. These disease developments result in the formation of different pathological structures in the lungs, similar to those observed in other viral pneumonias that can be detected by the use of chest X-rays. For this reason, the detection and analysis of the pulmonary regions, the main focus of affection of COVID-19, becomes a crucial part of both clinical and automatic diagnosis processes. Due to the overload of the health services, portable X-ray devices are widely used, representing an alternative to fixed devices to reduce the risk of cross-contamination. However, these devices entail different complications as the image quality that, together with the subjectivity of the clinician, make the diagnostic process more difficult. In this work, we developed a novel fully automatic methodology specially designed for the identification of these lung regions in X-ray images of low quality as those from portable devices. To do so, we took advantage of a large dataset from magnetic resonance imaging of a similar pathology and performed two stages of transfer learning to obtain a robust methodology with a low number of images from portable X-ray devices. This way, our methodology obtained a satisfactory accuracy of $0.9761 \pm 0.0100$ for patients with COVID-19, $0.9801 \pm 0.0104$ for normal patients and $0.9769 \pm 0.0111$ for patients with pulmonary diseases with similar characteristics as COVID-19 (such as pneumonia) but not genuine COVID-19.
Puzzle-AE: Novelty Detection in Images through Solving Puzzles
Aug 29, 2020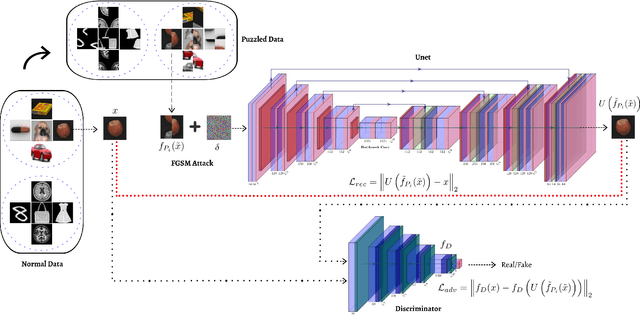
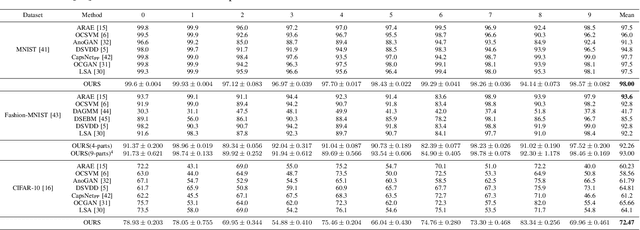
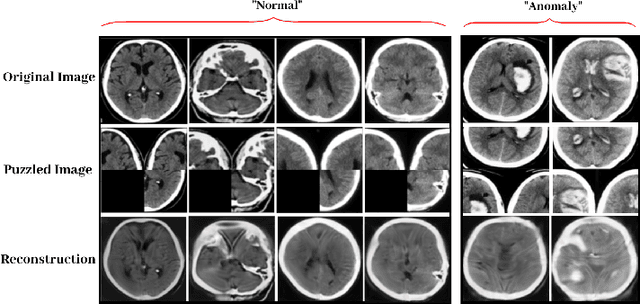

Autoencoder (AE) has proved to be an effective framework for novelty detection. However, they do not typically show promising results on other kinds of real-world datasets, which are exhibiting high intra-class variations, such as CIFAR-10. AEs are not generally able to learn a latent space that solely captures common features of the normal class, resulting in both high false positive and false negative rates due to modeling features that are irrelevant to the normal class. Recently, self-supervised learning has shown great promise in representation learning. To this end, we propose a new AE framework that is trained based on solving puzzles on randomly permuted image patches. Based on this framework, we achieve competitive or superior results compared to SOTA anomaly detection methods on various toy and real-world datasets. Unlike many competitors in this field, the proposed framework is stable, has real-time performance, more general and agnostic to choices of the model hyper-parameters, can work effectively under small sample size settings, and does not require unprincipled early stopping.
Independent finite approximations for Bayesian nonparametric inference: construction, error bounds, and practical implications
Sep 22, 2020
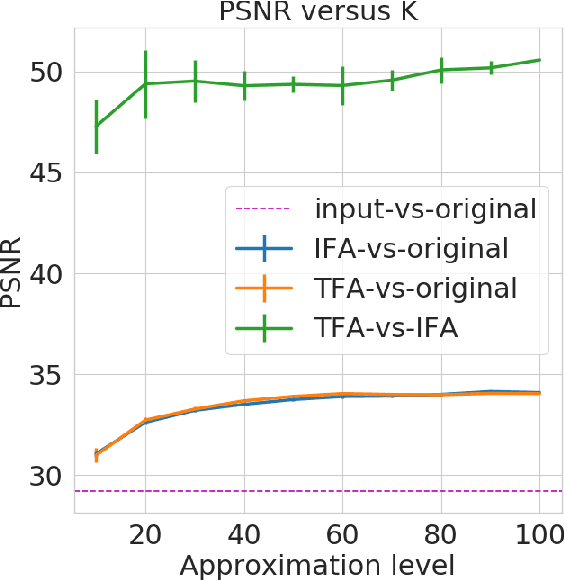
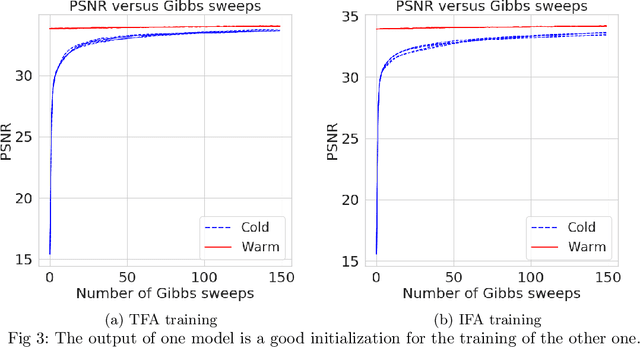
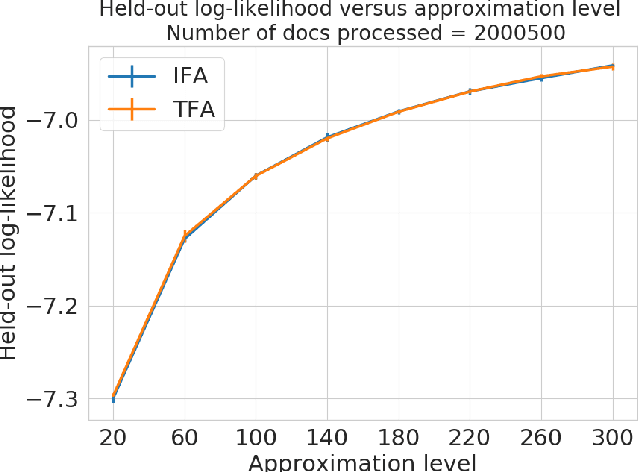
Bayesian nonparametrics based on completely random measures (CRMs) offers a flexible modeling approach when the number of clusters or latent components in a dataset is unknown. However, managing the infinite dimensionality of CRMs often leads to slow computation. Practical inference typically relies on either integrating out the infinite-dimensional parameter or using a finite approximation: a truncated finite approximation (TFA) or an independent finite approximation (IFA). The atom weights of TFAs are constructed sequentially, while the atoms of IFAs are independent, which (1) make them well-suited for parallel and distributed computation and (2) facilitates more convenient inference schemes. While IFAs have been developed in certain special cases in the past, there has not yet been a general template for construction or a systematic comparison to TFAs. We show how to construct IFAs for approximating distributions in a large family of CRMs, encompassing all those typically used in practice. We quantify the approximation error between IFAs and the target nonparametric prior, and prove that, in the worst-case, TFAs provide more component-efficient approximations than IFAs. However, in experiments on image denoising and topic modeling tasks with real data, we find that the error of Bayesian approximation methods overwhelms any finite approximation error, and IFAs perform very similarly to TFAs.