 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Loss Sub-Ensembles for Accurate Classification with Uncertainty Estimation
Oct 05, 2020
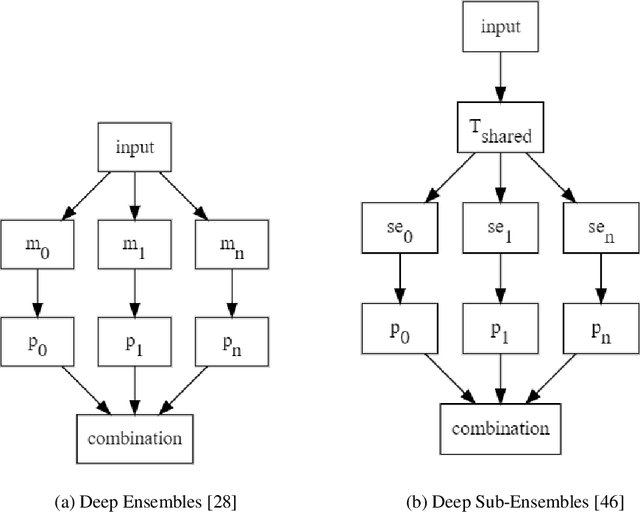
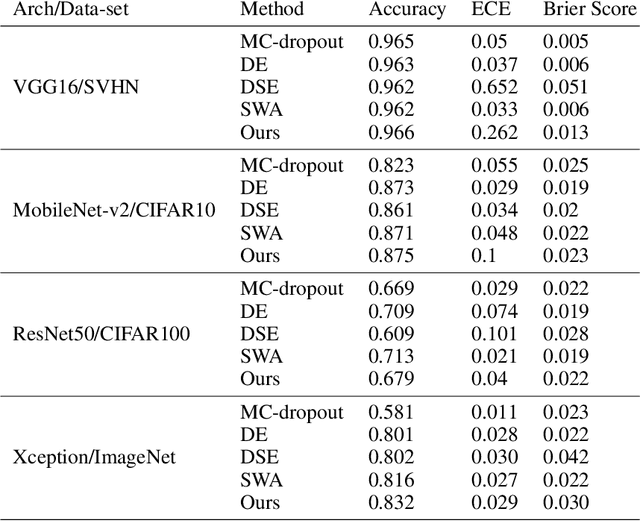
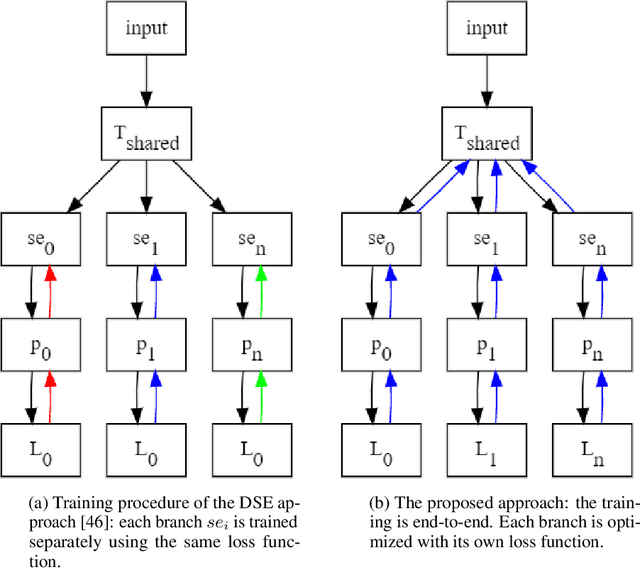
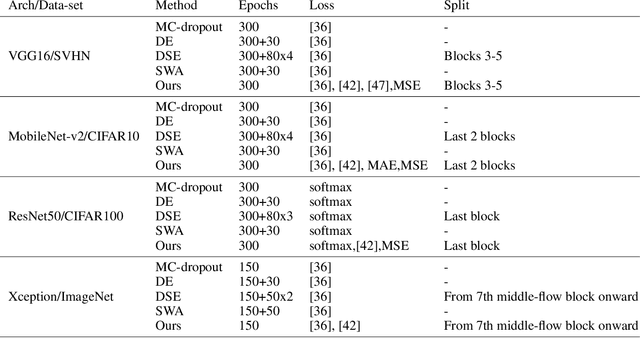
Deep neural networks (DNNs) have made a revolution in numerous fields during the last decade. However, in tasks with high safety requirements, such as medical or autonomous driving applications, providing an assessment of the models reliability can be vital. Uncertainty estimation for DNNs has been addressed using Bayesian methods, providing mathematically founded models for reliability assessment. These model are computationally expensive and generally impractical for many real-time use cases. Recently, non-Bayesian methods were proposed to tackle uncertainty estimation more efficiently. We propose an efficient method for uncertainty estimation in DNNs achieving high accuracy. We simulate the notion of multi-task learning on single-task problems by producing parallel predictions from similar models differing by their loss. This multi-loss approach allows one-phase training for single-task learning with uncertainty estimation. We keep our inference time relatively low by leveraging the advantage proposed by the Deep-Sub-Ensembles method. The novelty of this work resides in the proposed accurate variational inference with a simple and convenient training procedure, while remaining competitive in terms of computational time. We conduct experiments on SVHN, CIFAR10, CIFAR100 as well as Image-Net using different architectures. Our results show improved accuracy on the classification task and competitive results on several uncertainty measures.
Canonical 3D Deformer Maps: Unifying parametric and non-parametric methods for dense weakly-supervised category reconstruction
Aug 28, 2020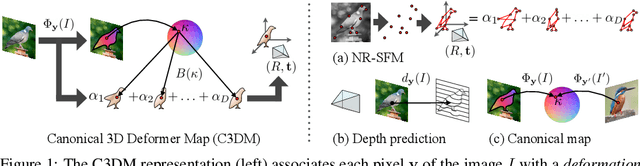
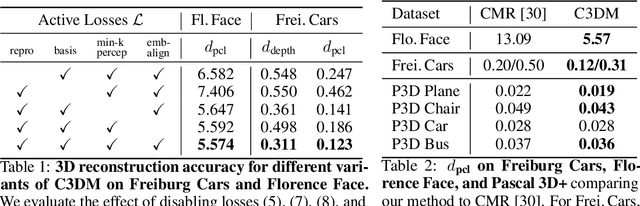
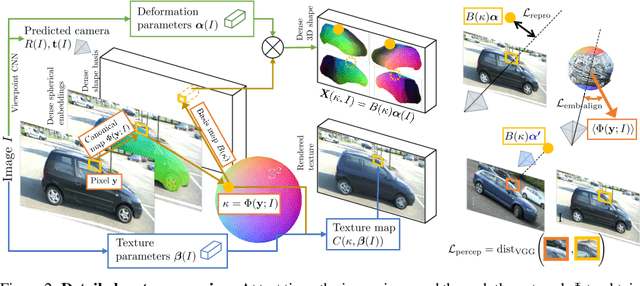

We propose the Canonical 3D Deformer Map, a new representation of the 3D shape of common object categories that can be learned from a collection of 2D images of independent objects. Our method builds in a novel way on concepts from parametric deformation models, non-parametric 3D reconstruction, and canonical embeddings, combining their individual advantages. In particular, it learns to associate each image pixel with a deformation model of the corresponding 3D object point which is canonical, i.e. intrinsic to the identity of the point and shared across objects of the category. The result is a method that, given only sparse 2D supervision at training time, can, at test time, reconstruct the 3D shape and texture of objects from single views, while establishing meaningful dense correspondences between object instances. It also achieves state-of-the-art results in dense 3D reconstruction on public in-the-wild datasets of faces, cars, and birds.
Adversarial Training of Variational Auto-encoders for High Fidelity Image Generation
Apr 27, 2018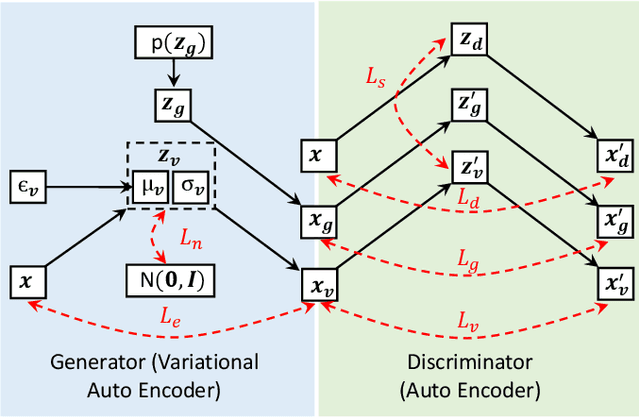
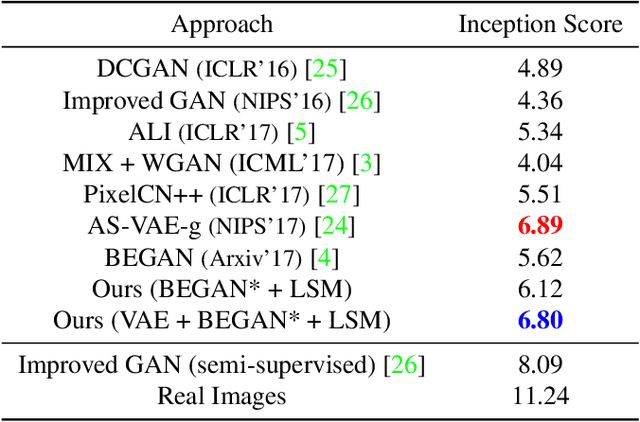


Variational auto-encoders (VAEs) provide an attractive solution to image generation problem. However, they tend to produce blurred and over-smoothed images due to their dependence on pixel-wise reconstruction loss. This paper introduces a new approach to alleviate this problem in the VAE based generative models. Our model simultaneously learns to match the data, reconstruction loss and the latent distributions of real and fake images to improve the quality of generated samples. To compute the loss distributions, we introduce an auto-encoder based discriminator model which allows an adversarial learning procedure. The discriminator in our model also provides perceptual guidance to the VAE by matching the learned similarity metric of the real and fake samples in the latent space. To stabilize the overall training process, our model uses an error feedback approach to maintain the equilibrium between competing networks in the model. Our experiments show that the generated samples from our proposed model exhibit a diverse set of attributes and facial expressions and scale up to high-resolution images very well.
Discoverability in Satellite Imagery: A Good Sentence is Worth a Thousand Pictures
Jan 03, 2020
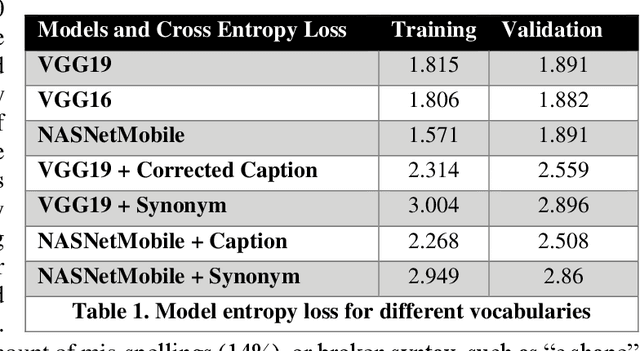

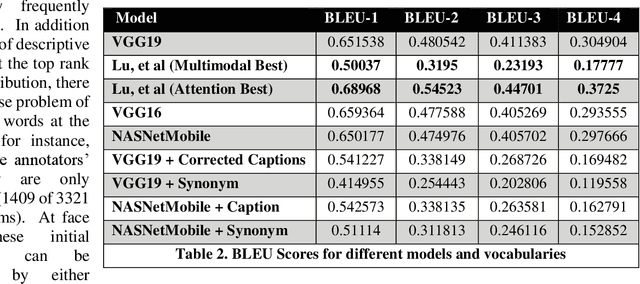
Small satellite constellations provide daily global coverage of the earth's landmass, but image enrichment relies on automating key tasks like change detection or feature searches. For example, to extract text annotations from raw pixels requires two dependent machine learning models, one to analyze the overhead image and the other to generate a descriptive caption. We evaluate seven models on the previously largest benchmark for satellite image captions. We extend the labeled image samples five-fold, then augment, correct and prune the vocabulary to approach a rough min-max (minimum word, maximum description). This outcome compares favorably to previous work with large pre-trained image models but offers a hundred-fold reduction in model size without sacrificing overall accuracy (when measured with log entropy loss). These smaller models provide new deployment opportunities, particularly when pushed to edge processors, on-board satellites, or distributed ground stations. To quantify a caption's descriptiveness, we introduce a novel multi-class confusion or error matrix to score both human-labeled test data and never-labeled images that include bounding box detection but lack full sentence captions. This work suggests future captioning strategies, particularly ones that can enrich the class coverage beyond land use applications and that lessen color-centered and adjacency adjectives ("green", "near", "between", etc.). Many modern language transformers present novel and exploitable models with world knowledge gleaned from training from their vast online corpus. One interesting, but easy example might learn the word association between wind and waves, thus enriching a beach scene with more than just color descriptions that otherwise might be accessed from raw pixels without text annotation.
Phase Congruency Parameter Optimization for Enhanced Detection of Image Features for both Natural and Medical Applications
May 05, 2017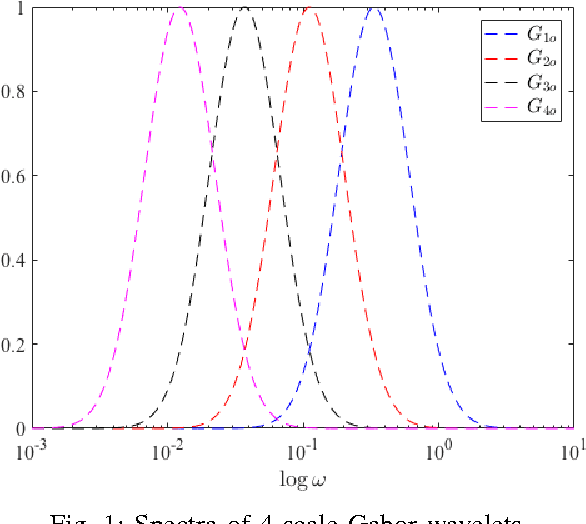

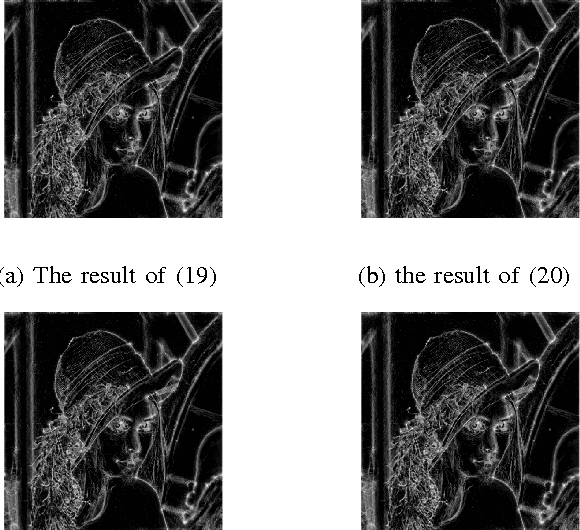

Following the presentation and proof of the hypothesis that image features are particularly perceived at points where the Fourier components are maximally in phase, the concept of phase congruency (PC) is introduced. Subsequently, a two-dimensional multi-scale phase congruency (2D-MSPC) is developed, which has been an important tool for detecting and evaluation of image features. However, the 2D-MSPC requires many parameters to be appropriately tuned for optimal image features detection. In this paper, we defined a criterion for parameter optimization of the 2D-MSPC, which is a function of its maximum and minimum moments. We formulated the problem in various optimal and suboptimal frameworks, and discussed the conditions and features of the suboptimal solutions. The effectiveness of the proposed method was verified through several examples, ranging from natural objects to medical images from patients with a neurological disease, multiple sclerosis.
Data Augmentation Using Adversarial Training for Construction-Equipment Classification
Nov 27, 2019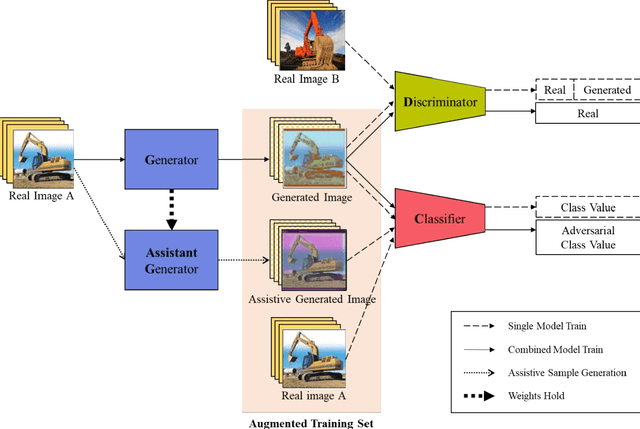
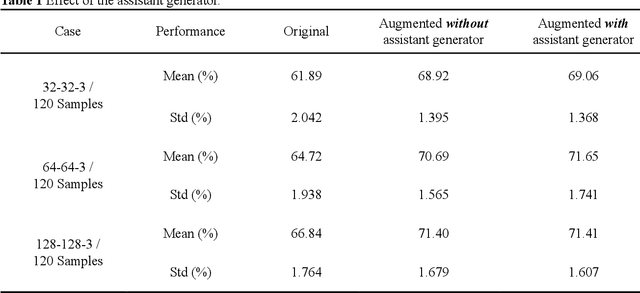
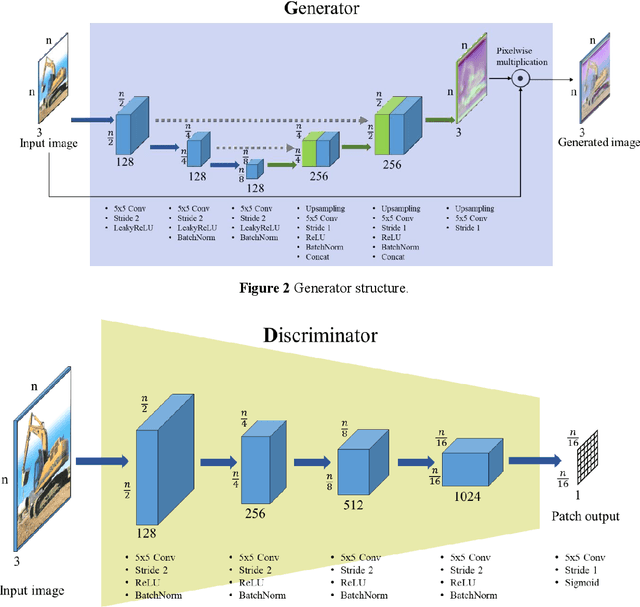
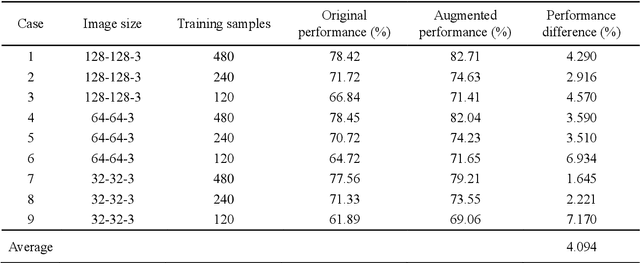
Deep learning-based construction-site image analysis has recently made great progress with regard to accuracy and speed, but it requires a large amount of data. Acquiring sufficient amount of labeled construction-image data is a prerequisite for deep learning-based construction-image recognition and requires considerable time and effort. In this paper, we propose a "data augmentation" scheme based on generative adversarial networks (GANs) for construction-equipment classification. The proposed method combines a GAN and additional "adversarial training" to stably perform "data augmentation" for construction equipment. The "data augmentation" was verified via binary classification experiments involving excavator images, and the average accuracy improvement was 4.094%. In the experiment, three image sizes (32-32-3, 64-64-3, and 128-128-3) and 120, 240, and 480 training samples were used to demonstrate the robustness of the proposed method. These results demonstrated that the proposed method can effectively and reliably generate construction-equipment images and train deep learning-based classifiers for construction equipment.
FAT: Training Neural Networks for Reliable Inference Under Hardware Faults
Nov 11, 2020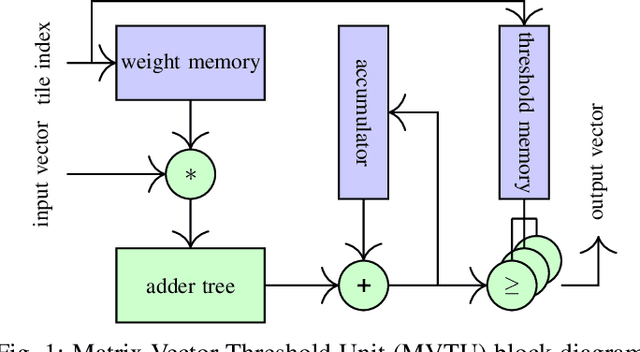
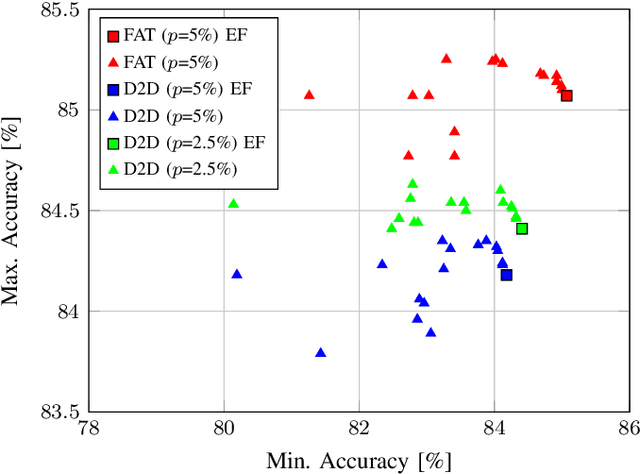
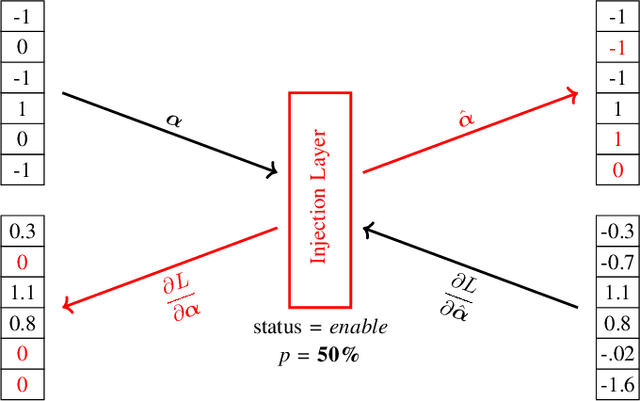
Deep neural networks (DNNs) are state-of-the-art algorithms for multiple applications, spanning from image classification to speech recognition. While providing excellent accuracy, they often have enormous compute and memory requirements. As a result of this, quantized neural networks (QNNs) are increasingly being adopted and deployed especially on embedded devices, thanks to their high accuracy, but also since they have significantly lower compute and memory requirements compared to their floating point equivalents. QNN deployment is also being evaluated for safety-critical applications, such as automotive, avionics, medical or industrial. These systems require functional safety, guaranteeing failure-free behaviour even in the presence of hardware faults. In general fault tolerance can be achieved by adding redundancy to the system, which further exacerbates the overall computational demands and makes it difficult to meet the power and performance requirements. In order to decrease the hardware cost for achieving functional safety, it is vital to explore domain-specific solutions which can exploit the inherent features of DNNs. In this work we present a novel methodology called fault-aware training (FAT), which includes error modeling during neural network (NN) training, to make QNNs resilient to specific fault models on the device. Our experiments show that by injecting faults in the convolutional layers during training, highly accurate convolutional neural networks (CNNs) can be trained which exhibits much better error tolerance compared to the original. Furthermore, we show that redundant systems which are built from QNNs trained with FAT achieve higher worse-case accuracy at lower hardware cost. This has been validated for numerous classification tasks including CIFAR10, GTSRB, SVHN and ImageNet.
Simple Primary Colour Editing for Consumer Product Images
Jun 06, 2020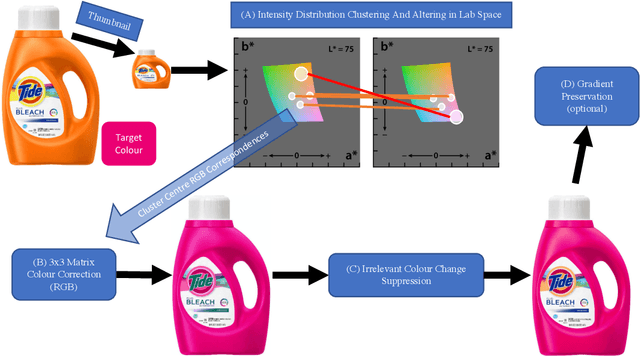
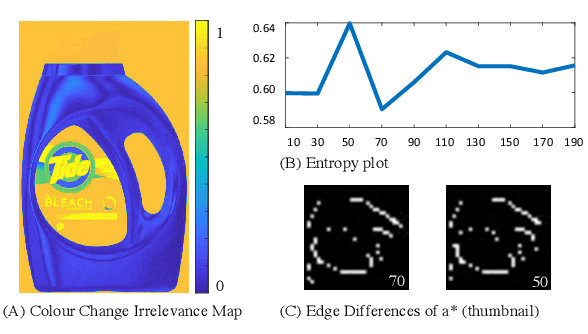


We present a simple primary colour editing method for consumer product images. We show that by using colour correction and colour blending, we can automate the pain-staking colour editing task and save time for consumer colour preference researchers. To improve the colour harmony between the primary colour and its complementary colours, our algorithm also tunes the other colours in the image. Preliminary experiment has shown some promising results compared with a state-of-the-art method and human editing.
Learning to Caricature via Semantic Shape Transform
Aug 13, 2020

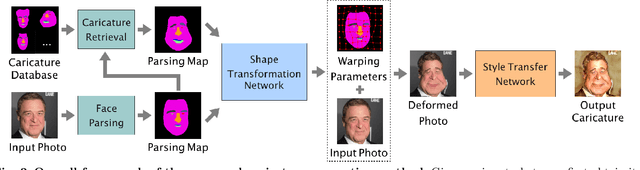
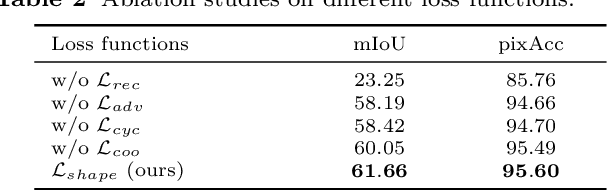
Caricature is an artistic drawing created to abstract or exaggerate facial features of a person. Rendering visually pleasing caricatures is a difficult task that requires professional skills, and thus it is of great interest to design a method to automatically generate such drawings. To deal with large shape changes, we propose an algorithm based on a semantic shape transform to produce diverse and plausible shape exaggerations. Specifically, we predict pixel-wise semantic correspondences and perform image warping on the input photo to achieve dense shape transformation. We show that the proposed framework is able to render visually pleasing shape exaggerations while maintaining their facial structures. In addition, our model allows users to manipulate the shape via the semantic map. We demonstrate the effectiveness of our approach on a large photograph-caricature benchmark dataset with comparisons to the state-of-the-art methods.
A Bayesian Hyperprior Approach for Joint Image Denoising and Interpolation, with an Application to HDR Imaging
Jun 10, 2017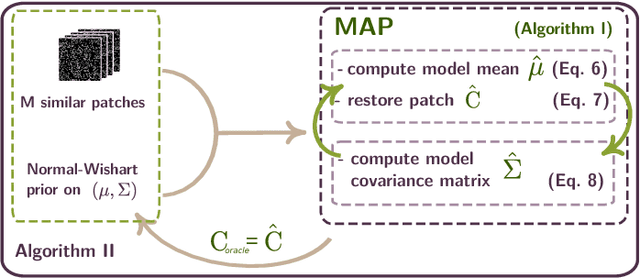



Recently, impressive denoising results have been achieved by Bayesian approaches which assume Gaussian models for the image patches. This improvement in performance can be attributed to the use of per-patch models. Unfortunately such an approach is particularly unstable for most inverse problems beyond denoising. In this work, we propose the use of a hyperprior to model image patches, in order to stabilize the estimation procedure. There are two main advantages to the proposed restoration scheme: Firstly it is adapted to diagonal degradation matrices, and in particular to missing data problems (e.g. inpainting of missing pixels or zooming). Secondly it can deal with signal dependent noise models, particularly suited to digital cameras. As such, the scheme is especially adapted to computational photography. In order to illustrate this point, we provide an application to high dynamic range imaging from a single image taken with a modified sensor, which shows the effectiveness of the proposed scheme.