 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal Approach for Face Anti-Spoofing in Non-Calibrated Systems using Disparity Maps
Oct 31, 2024



Face recognition technologies are increasingly used in various applications, yet they are vulnerable to face spoofing attacks. These spoofing attacks often involve unique 3D structures, such as printed papers or mobile device screens. Although stereo-depth cameras can detect such attacks effectively, their high-cost limits their widespread adoption. Conversely, two-sensor systems without extrinsic calibration offer a cost-effective alternative but are unable to calculate depth using stereo techniques. In this work, we propose a method to overcome this challenge by leveraging facial attributes to derive disparity information and estimate relative depth for anti-spoofing purposes, using non-calibrated systems. We introduce a multi-modal anti-spoofing model, coined Disparity Model, that incorporates created disparity maps as a third modality alongside the two original sensor modalities. We demonstrate the effectiveness of the Disparity Model in countering various spoof attacks using a comprehensive dataset collected from the Intel RealSense ID Solution F455. Our method outperformed existing methods in the literature, achieving an Equal Error Rate (EER) of 1.71% and a False Negative Rate (FNR) of 2.77% at a False Positive Rate (FPR) of 1%. These errors are lower by 2.45% and 7.94% than the errors of the best comparison method, respectively. Additionally, we introduce a model ensemble that addresses 3D spoof attacks as well, achieving an EER of 2.04% and an FNR of 3.83% at an FPR of 1%. Overall, our work provides a state-of-the-art solution for the challenging task of anti-spoofing in non-calibrated systems that lack depth information.
Multi-Loss Sub-Ensembles for Accurate Classification with Uncertainty Estimation
Oct 05, 2020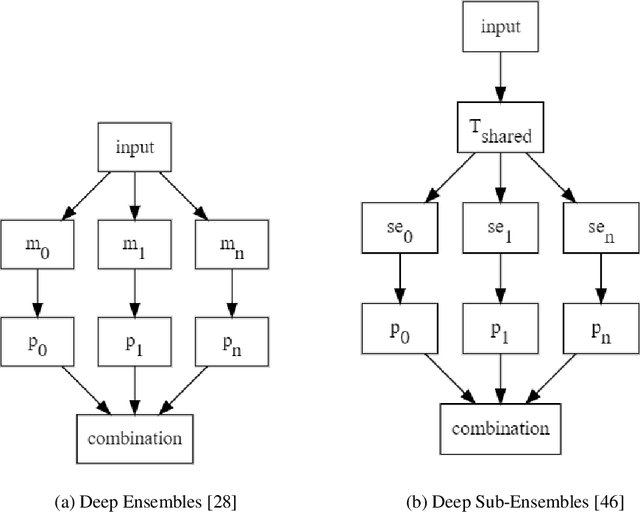
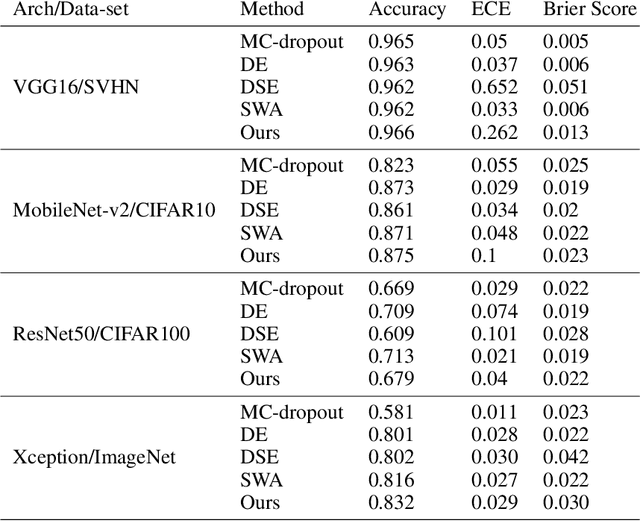
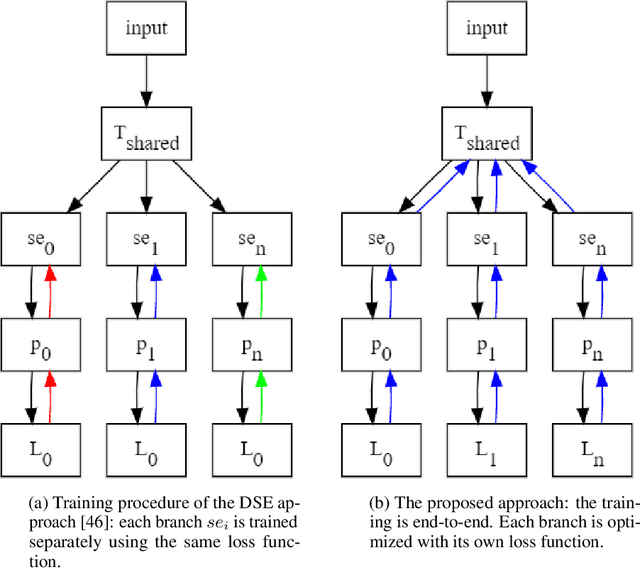
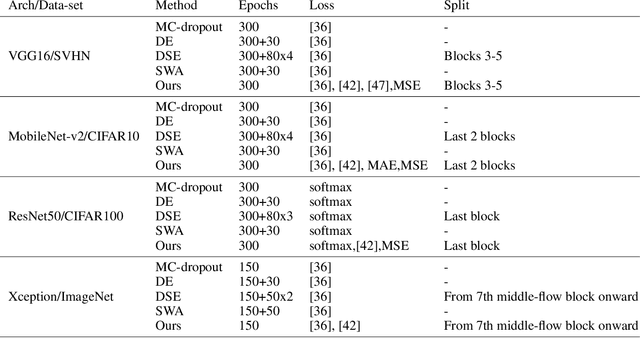
Deep neural networks (DNNs) have made a revolution in numerous fields during the last decade. However, in tasks with high safety requirements, such as medical or autonomous driving applications, providing an assessment of the models reliability can be vital. Uncertainty estimation for DNNs has been addressed using Bayesian methods, providing mathematically founded models for reliability assessment. These model are computationally expensive and generally impractical for many real-time use cases. Recently, non-Bayesian methods were proposed to tackle uncertainty estimation more efficiently. We propose an efficient method for uncertainty estimation in DNNs achieving high accuracy. We simulate the notion of multi-task learning on single-task problems by producing parallel predictions from similar models differing by their loss. This multi-loss approach allows one-phase training for single-task learning with uncertainty estimation. We keep our inference time relatively low by leveraging the advantage proposed by the Deep-Sub-Ensembles method. The novelty of this work resides in the proposed accurate variational inference with a simple and convenient training procedure, while remaining competitive in terms of computational time. We conduct experiments on SVHN, CIFAR10, CIFAR100 as well as Image-Net using different architectures. Our results show improved accuracy on the classification task and competitive results on several uncertainty measures.
Insights on Evaluation of Camera Re-localization Using Relative Pose Regression
Sep 23, 2020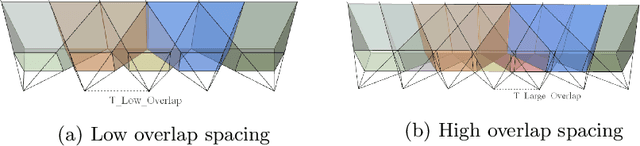
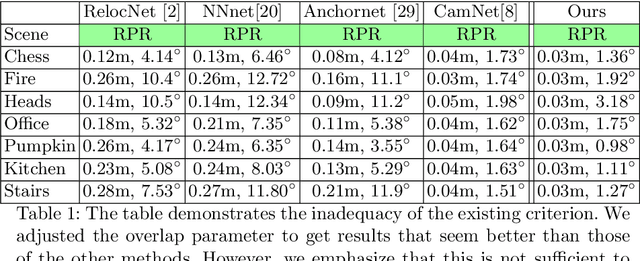
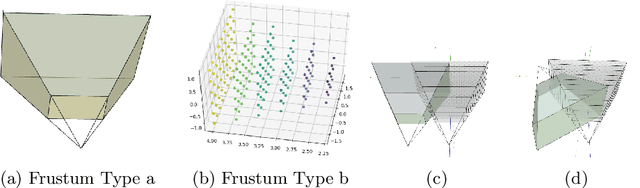
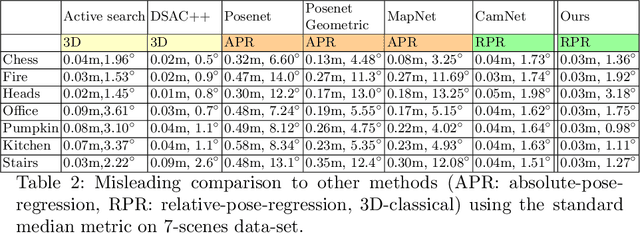
We consider the problem of relative pose regression in visual relocalization. Recently, several promising approaches have emerged in this area. We claim that even though they demonstrate on the same datasets using the same split to train and test, a faithful comparison between them was not available since on currently used evaluation metric, some approaches might perform favorably, while in reality performing worse. We reveal a tradeoff between accuracy and the 3D volume of the regressed subspace. We believe that unlike other relocalization approaches, in the case of relative pose regression, the regressed subspace 3D volume is less dependent on the scene and more affect by the method used to score the overlap, which determined how closely sampled viewpoints are. We propose three new metrics to remedy the issue mentioned above. The proposed metrics incorporate statistics about the regression subspace volume. We also propose a new pose regression network that serves as a new baseline for this task. We compare the performance of our trained model on Microsoft 7-Scenes and Cambridge Landmarks datasets both with the standard metrics and the newly proposed metrics and adjust the overlap score to reveal the tradeoff between the subspace and performance. The results show that the proposed metrics are more robust to different overlap threshold than the conventional approaches. Finally, we show that our network generalizes well, specifically, training on a single scene leads to little loss of performance on the other scenes.