 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SS-CAM: Smoothed Score-CAM for Sharper Visual Feature Localization
Jul 15, 2020
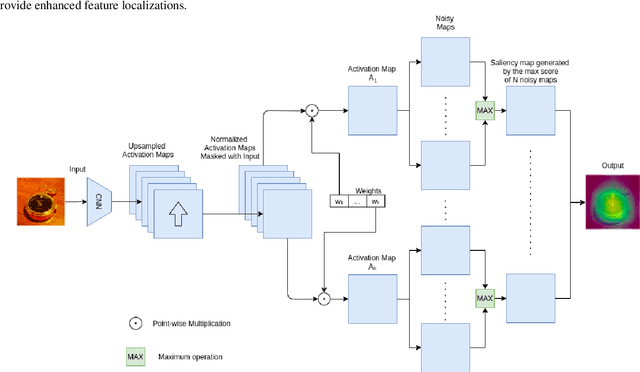

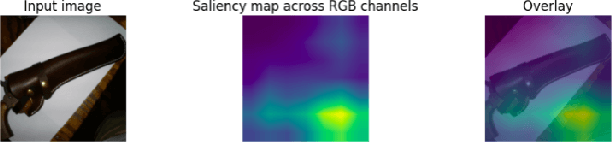
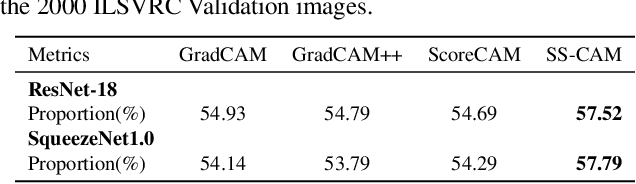
Interpretation of the underlying mechanisms of Deep Convolutional Neural Networks has become an important aspect of research in the field of deep learning due to their applications in high-risk environments. To explain these black-box architectures there have been many methods applied so the internal decisions can be analyzed and understood. In this paper, built on the top of Score-CAM, we introduce an enhanced visual explanation in terms of visual sharpness called SS-CAM, which produces centralized localization of object features within an image through a smooth operation. We evaluate our method on the ILSVRC 2012 Validation dataset, which outperforms Score-CAM on both faithfulness and localization tasks.
Handling Noisy Labels via One-Step Abductive Multi-Target Learning
Nov 25, 2020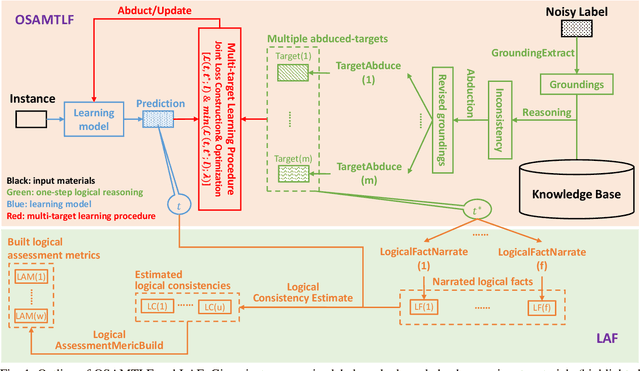
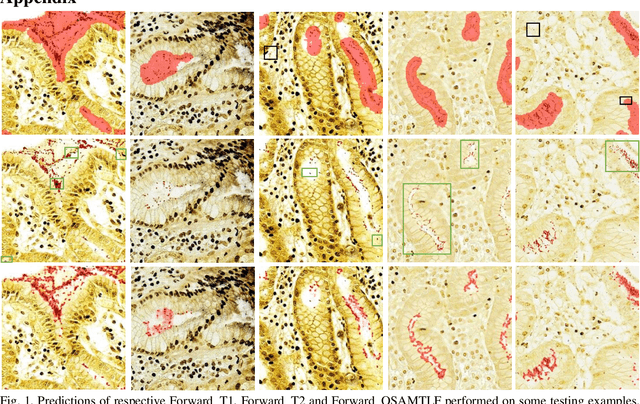
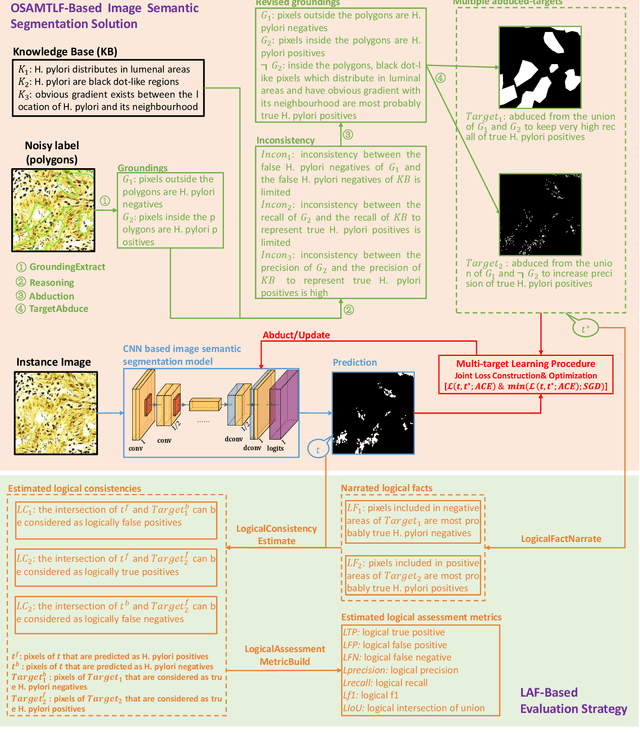
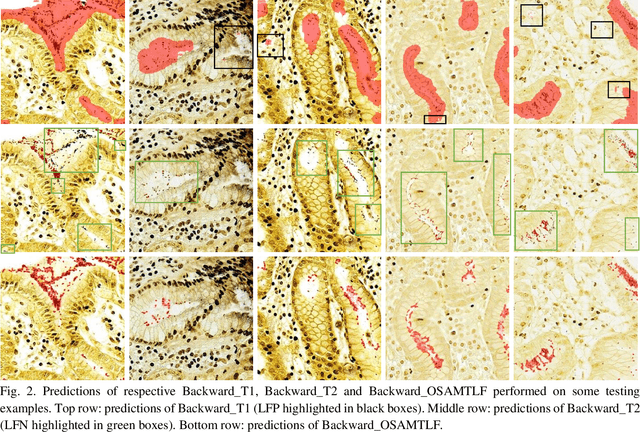
Learning from noisy labels is an important concern because of the lack of accurate ground-truth labels in plenty of real-world scenarios. In practice, various approaches for this concern first make corrections corresponding to potentially noisy-labeled instances, and then update predictive model with information of the made corrections. However, in specific areas, such as medical histopathology whole slide image analysis (MHWSIA), it is often difficult or even impossible for experts to manually achieve the noisy-free ground-truth labels which leads to labels with heavy noise. This situation raises two more difficult problems: 1) the methodology of approaches making corrections corresponding to potentially noisy-labeled instances has limitations due to the heavy noise existing in labels; and 2) the appropriate evaluation strategy for validation/testing is unclear because of the great difficulty in collecting the noisy-free ground-truth labels. In this paper, we focus on alleviating these two problems. For the problem 1), we present a one-step abductive multi-target learning framework (OSAMTLF) that imposes a one-step logical reasoning upon machine learning via a multi-target learning procedure to abduct the predictions of the learning model to be subject to our prior knowledge. For the problem 2), we propose a logical assessment formula (LAF) that evaluates the logical rationality of the outputs of an approach by estimating the consistencies between the predictions of the learning model and the logical facts narrated from the results of the one-step logical reasoning of OSAMTLF. Applying OSAMTLF and LAF to the Helicobacter pylori (H. pylori) segmentation task in MHWSIA, we show that OSAMTLF is able to abduct the machine learning model achieving logically more rational predictions, which is beyond the capability of various state-of-the-art approaches for learning from noisy labels.
Image reconstruction with imperfect forward models and applications in deblurring
Oct 23, 2017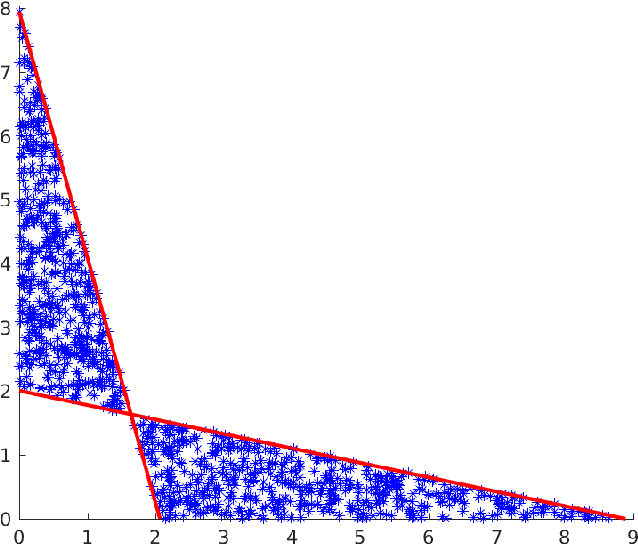
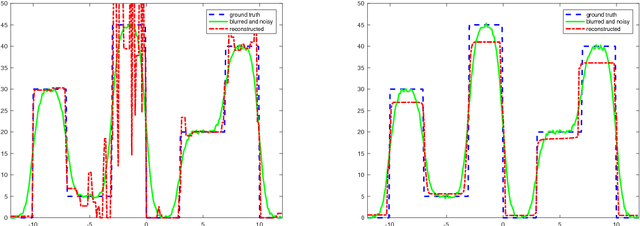

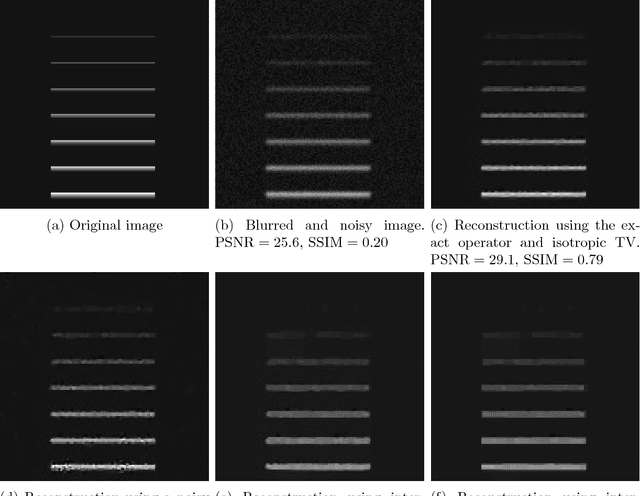
We present and analyse an approach to image reconstruction problems with imperfect forward models based on partially ordered spaces - Banach lattices. In this approach, errors in the data and in the forward models are described using order intervals. The method can be characterised as the lattice analogue of the residual method, where the feasible set is defined by linear inequality constraints. The study of this feasible set is the main contribution of this paper. Convexity of this feasible set is examined in several settings and modifications for introducing additional information about the forward operator are considered. Numerical examples demonstrate the performance of the method in deblurring with errors in the blurring kernel.
Guiding Long-Short Term Memory for Image Caption Generation
Sep 16, 2015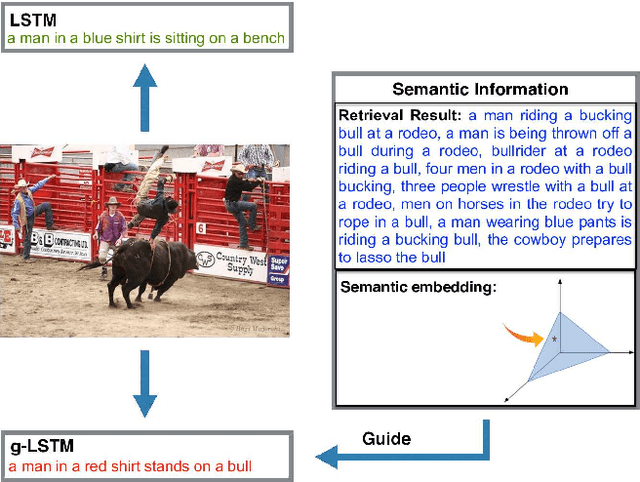
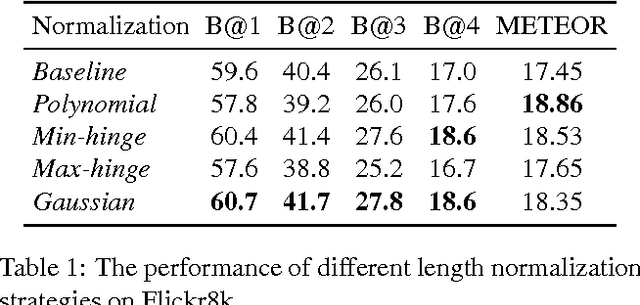
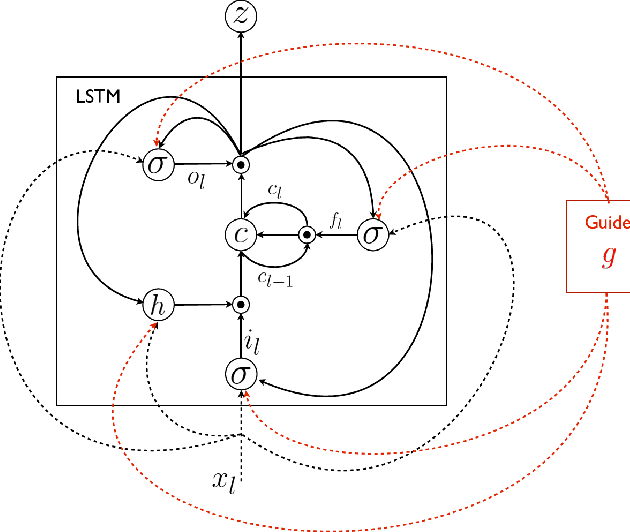

In this work we focus on the problem of image caption generation. We propose an extension of the long short term memory (LSTM) model, which we coin gLSTM for short. In particular, we add semantic information extracted from the image as extra input to each unit of the LSTM block, with the aim of guiding the model towards solutions that are more tightly coupled to the image content. Additionally, we explore different length normalization strategies for beam search in order to prevent from favoring short sentences. On various benchmark datasets such as Flickr8K, Flickr30K and MS COCO, we obtain results that are on par with or even outperform the current state-of-the-art.
SGDN: Segmentation-Based Grasp Detection Network For Unsymmetrical Three-Finger Gripper
May 17, 2020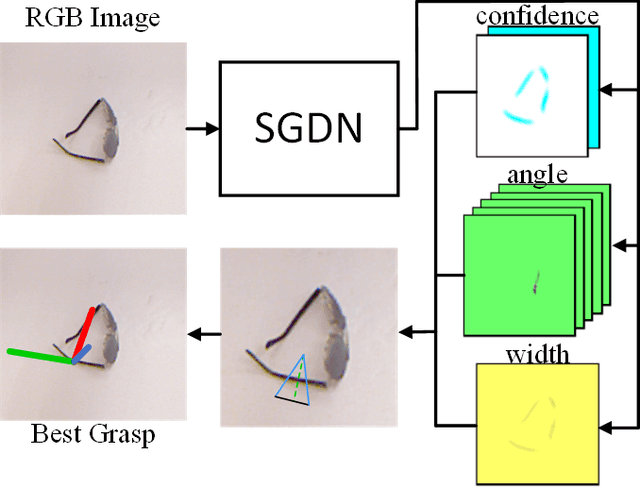
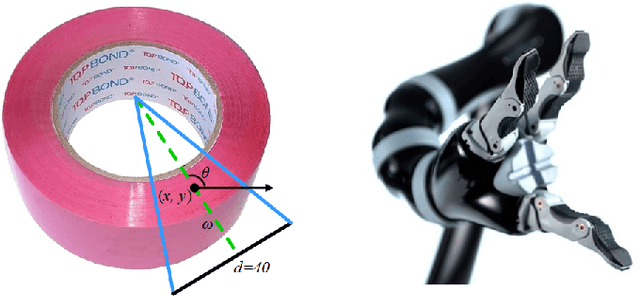

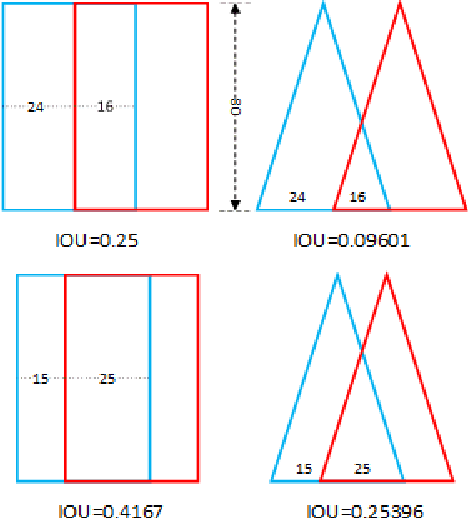
In this paper, we present Segmentation-Based Grasp Detection Network (SGDN) to predict a feasible robotic grasping for a unsymmetrical three-finger robotic gripper using RGB images. The feasible grasping of a target should be a collection of grasp regions with the same grasp angle and width. In other words, a simplified planar grasp representation should be pixel-level rather than region-level such as five-dimensional grasp representation.Therefore, we propose a pixel-level grasp representation, oriented base-fixed triangle. It is also more suitable for unsymmetrical three-finger gripper which cannot grasp symmetrically when grasping some objects, the grasp angle is at [0, 2{\pi}) instead of [0, {\pi}) of parallel plate gripper.In order to predict the appropriate grasp region and its corresponding grasp angle and width in the RGB image, SGDN uses DeepLabv3+ as a feature extractor, and uses a three-channel grasp predictor to predict feasible oriented base-fixed triangle grasp representation of each pixel.On the re-annotated Cornell Grasp Dataset, our model achieves an accuracy of 96.8% and 92.27% on image-wise split and object-wise split respectively, and obtains accurate predictions consistent with the state-of-the-art methods.
Transferring and Regularizing Prediction for Semantic Segmentation
Jun 11, 2020
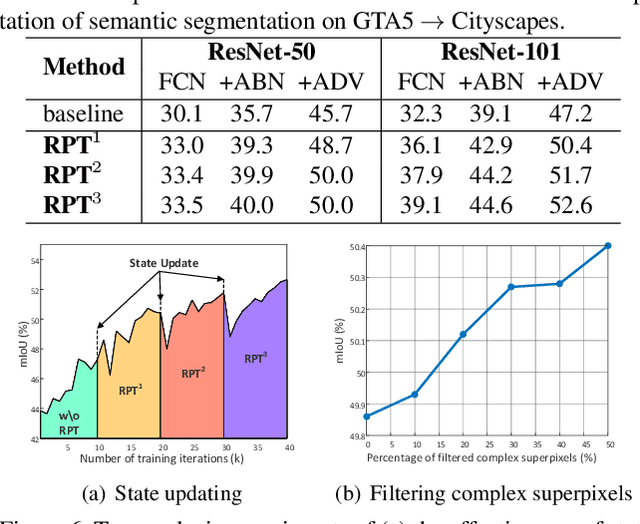
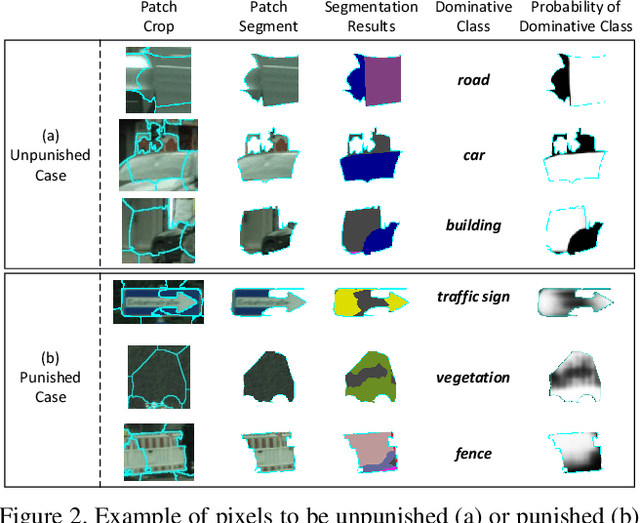

Semantic segmentation often requires a large set of images with pixel-level annotations. In the view of extremely expensive expert labeling, recent research has shown that the models trained on photo-realistic synthetic data (e.g., computer games) with computer-generated annotations can be adapted to real images. Despite this progress, without constraining the prediction on real images, the models will easily overfit on synthetic data due to severe domain mismatch. In this paper, we novelly exploit the intrinsic properties of semantic segmentation to alleviate such problem for model transfer. Specifically, we present a Regularizer of Prediction Transfer (RPT) that imposes the intrinsic properties as constraints to regularize model transfer in an unsupervised fashion. These constraints include patch-level, cluster-level and context-level semantic prediction consistencies at different levels of image formation. As the transfer is label-free and data-driven, the robustness of prediction is addressed by selectively involving a subset of image regions for model regularization. Extensive experiments are conducted to verify the proposal of RPT on the transfer of models trained on GTA5 and SYNTHIA (synthetic data) to Cityscapes dataset (urban street scenes). RPT shows consistent improvements when injecting the constraints on several neural networks for semantic segmentation. More remarkably, when integrating RPT into the adversarial-based segmentation framework, we report to-date the best results: mIoU of 53.2%/51.7% when transferring from GTA5/SYNTHIA to Cityscapes, respectively.
Efficient B-mode Ultrasound Image Reconstruction from Sub-sampled RF Data using Deep Learning
Aug 07, 2018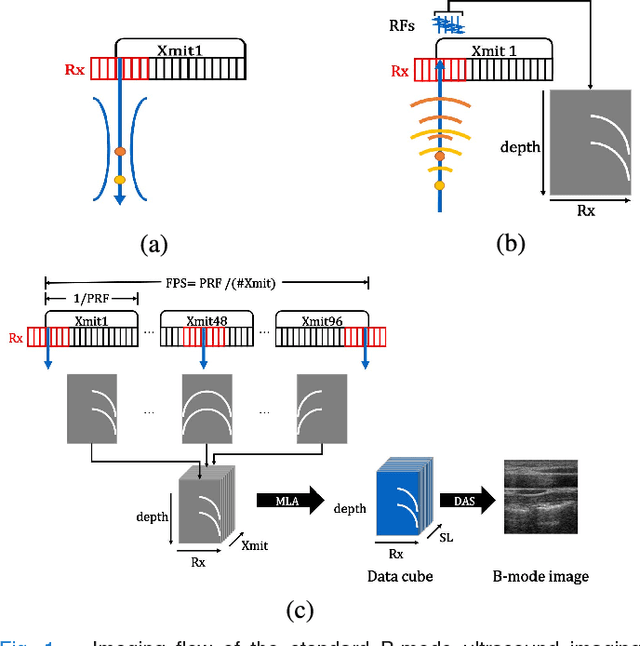
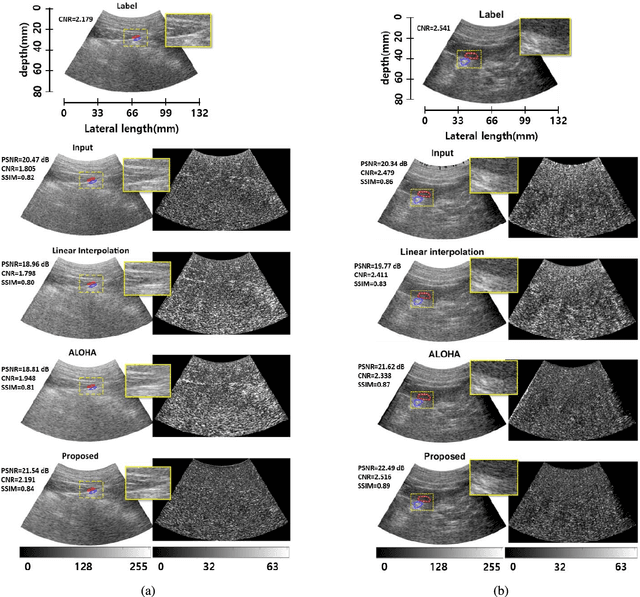
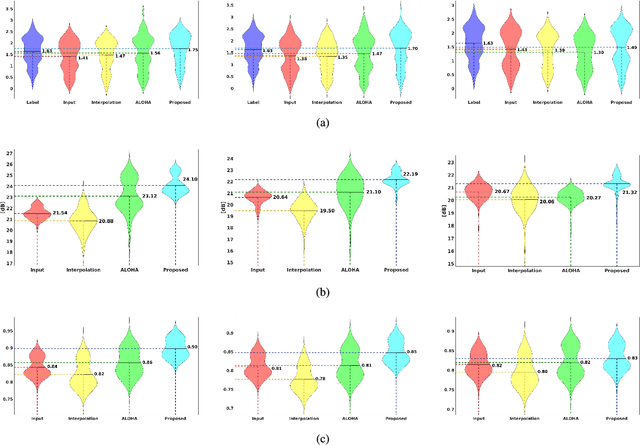
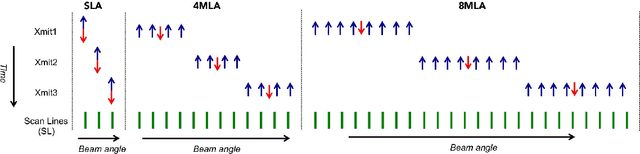
In portable, three dimensional, and ultra-fast ultrasound imaging systems, there is an increasing demand for the reconstruction of high quality images from a limited number of radio-frequency (RF) measurements due to receiver (Rx) or transmit (Xmit) event sub-sampling. However, due to the presence of side lobe artifacts from RF sub-sampling, the standard beamformer often produces blurry images with less contrast, which are unsuitable for diagnostic purposes. Existing compressed sensing approaches often require either hardware changes or computationally expensive algorithms, but their quality improvements are limited. To address this problem, here we propose a novel deep learning approach that directly interpolates the missing RF data by utilizing redundancy in the Rx-Xmit plane. Our extensive experimental results using sub-sampled RF data from a multi-line acquisition B-mode system confirm that the proposed method can effectively reduce the data rate without sacrificing image quality.
Seeing Eye-to-Eye? A Comparison of Object Recognition Performance in Humans and Deep Convolutional Neural Networks under Image Manipulation
Jul 13, 2020
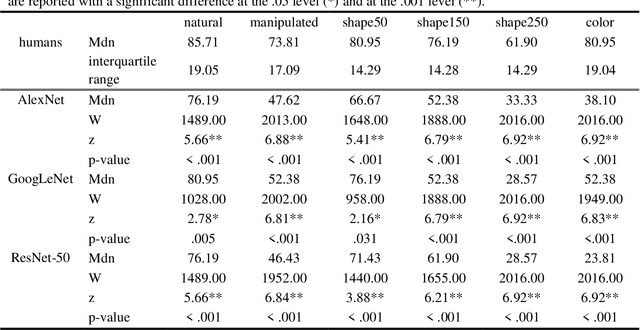
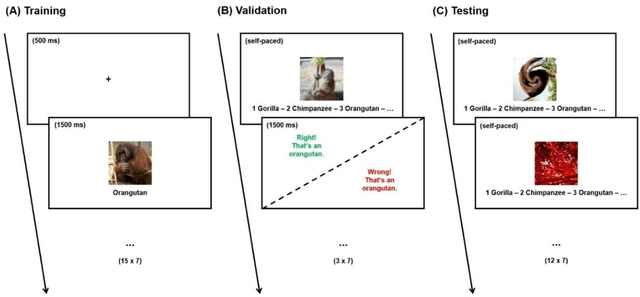
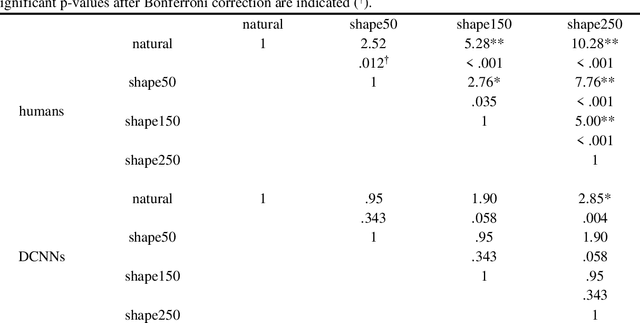
For a considerable time, deep convolutional neural networks (DCNNs) have reached human benchmark performance in object recognition. On that account, computational neuroscience and the field of machine learning have started to attribute numerous similarities and differences to artificial and biological vision. This study aims towards a behavioral comparison of visual core object recognition between humans and feedforward neural networks in a classification learning paradigm on an ImageNet data set. For this purpose, human participants (n = 65) competed in an online experiment against different feedforward DCNNs. The designed approach based on a typical learning process of seven different monkey categories included a training and validation phase with natural examples, as well as a testing phase with novel shape and color manipulations. Analyses of accuracy revealed that humans not only outperform DCNNs on all conditions, but also display significantly greater robustness towards shape and most notably color alterations. Furthermore, a precise examination of behavioral patterns highlights these findings by revealing independent classification errors between the groups. The obtained results endorse an implementation of recurrent circuits similar to the primate ventral stream in artificial vision models as a way to achieve adequate object generalization abilities across unexperienced manipulations.
Exemplar Normalization for Learning Deep Representation
Mar 20, 2020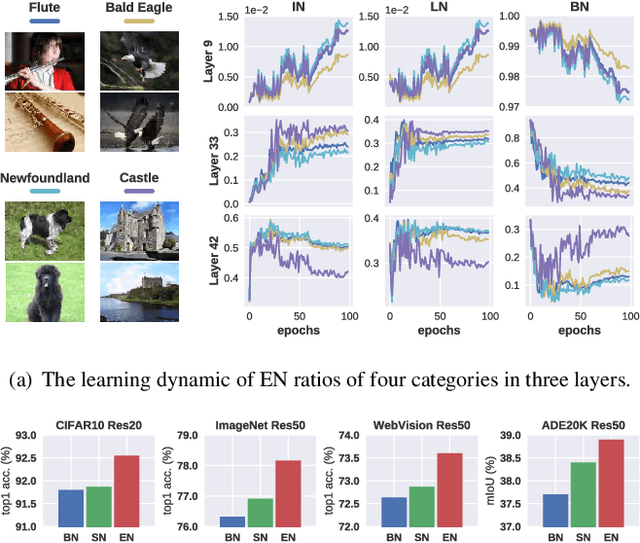
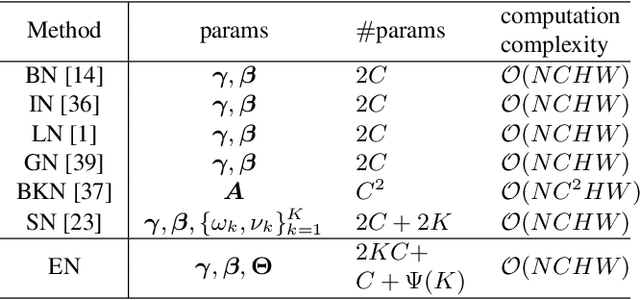
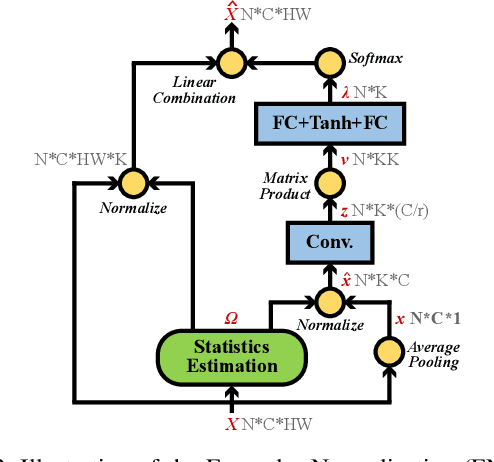
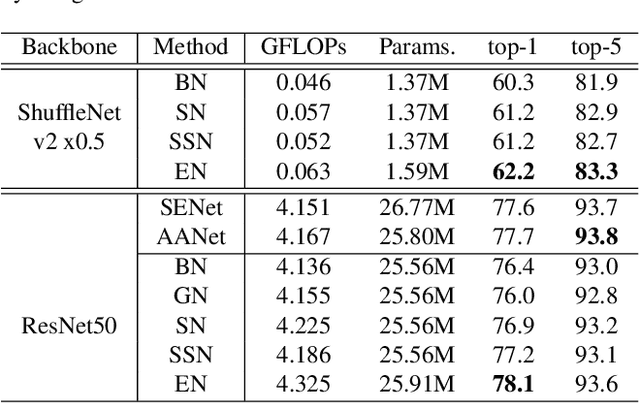
Normalization techniques are important in different advanced neural networks and different tasks. This work investigates a novel dynamic learning-to-normalize (L2N) problem by proposing Exemplar Normalization (EN), which is able to learn different normalization methods for different convolutional layers and image samples of a deep network. EN significantly improves flexibility of the recently proposed switchable normalization (SN), which solves a static L2N problem by linearly combining several normalizers in each normalization layer (the combination is the same for all samples). Instead of directly employing a multi-layer perceptron (MLP) to learn data-dependent parameters as conditional batch normalization (cBN) did, the internal architecture of EN is carefully designed to stabilize its optimization, leading to many appealing benefits. (1) EN enables different convolutional layers, image samples, categories, benchmarks, and tasks to use different normalization methods, shedding light on analyzing them in a holistic view. (2) EN is effective for various network architectures and tasks. (3) It could replace any normalization layers in a deep network and still produce stable model training. Extensive experiments demonstrate the effectiveness of EN in a wide spectrum of tasks including image recognition, noisy label learning, and semantic segmentation. For example, by replacing BN in the ordinary ResNet50, improvement produced by EN is 300% more than that of SN on both ImageNet and the noisy WebVision dataset.
Ensemble Multi-Source Domain Adaptation with Pseudolabels
Sep 29, 2020
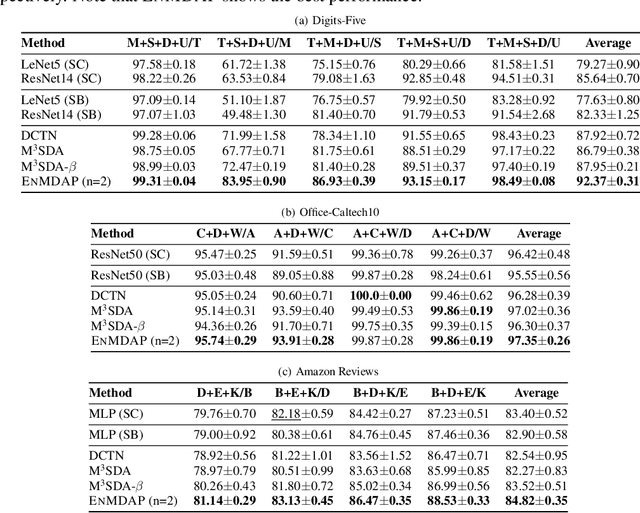
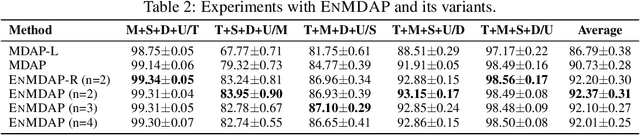
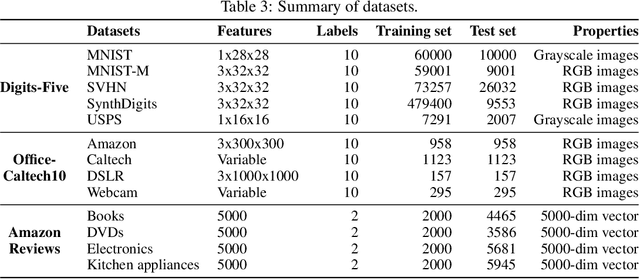
Given multiple source datasets with labels, how can we train a target model with no labeled data? Multi-source domain adaptation (MSDA) aims to train a model using multiple source datasets different from a target dataset in the absence of target data labels. MSDA is a crucial problem applicable to many practical cases where labels for the target data are unavailable due to privacy issues. Existing MSDA frameworks are limited since they align data without considering conditional distributions p(x|y) of each domain. They also miss a lot of target label information by not considering the target label at all and relying on only one feature extractor. In this paper, we propose Ensemble Multi-source Domain Adaptation with Pseudolabels (EnMDAP), a novel method for multi-source domain adaptation. EnMDAP exploits label-wise moment matching to align conditional distributions p(x|y), using pseudolabels for the unavailable target labels, and introduces ensemble learning theme by using multiple feature extractors for accurate domain adaptation. Extensive experiments show that EnMDAP provides the state-of-the-art performance for multi-source domain adaptation tasks in both of image domains and text domains.