 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatial Pyramid Convolutional Neural Network for Social Event Detection in Static Image
Dec 13, 2016
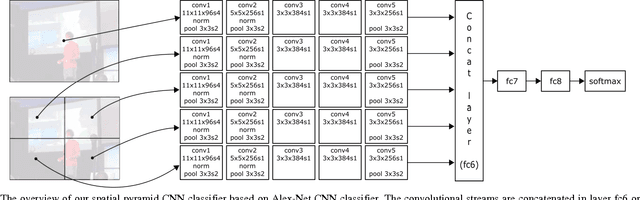
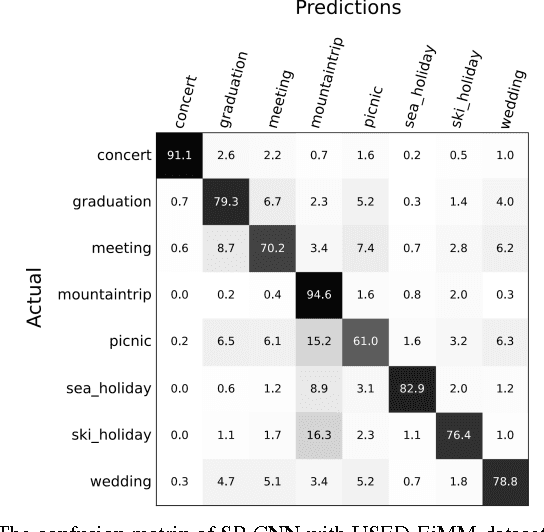
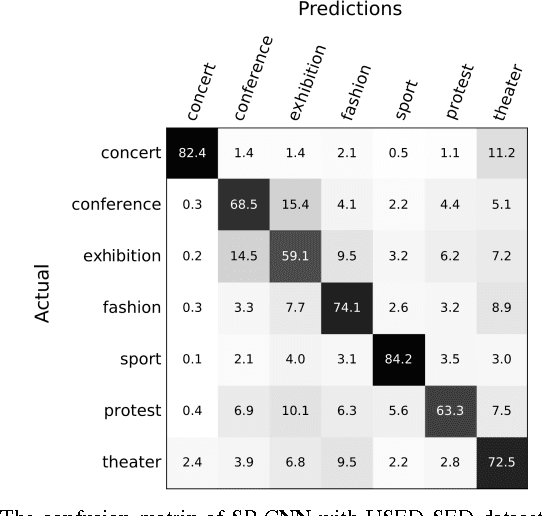
Social event detection in a static image is a very challenging problem and it's very useful for internet of things applications including automatic photo organization, ads recommender system, or image captioning. Several publications show that variety of objects, scene, and people can be very ambiguous for the system to decide the event that occurs in the image. We proposed the spatial pyramid configuration of convolutional neural network (CNN) classifier for social event detection in a static image. By applying the spatial pyramid configuration to the CNN classifier, the detail that occurs in the image can observe more accurately by the classifier. USED dataset provided by Ahmad et al. is used to evaluate our proposed method, which consists of two different image sets, EiMM, and SED dataset. As a result, the average accuracy of our system outperforms the baseline method by 15% and 2% respectively.
Towards Automatic Manipulation of Intra-cardiac Echocardiography Catheter
Sep 12, 2020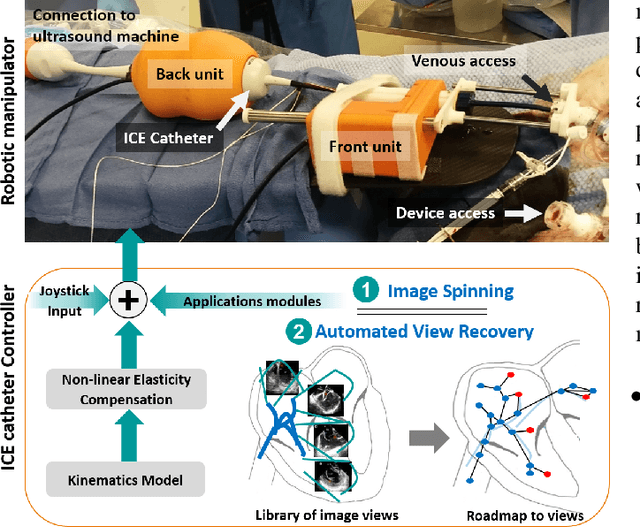
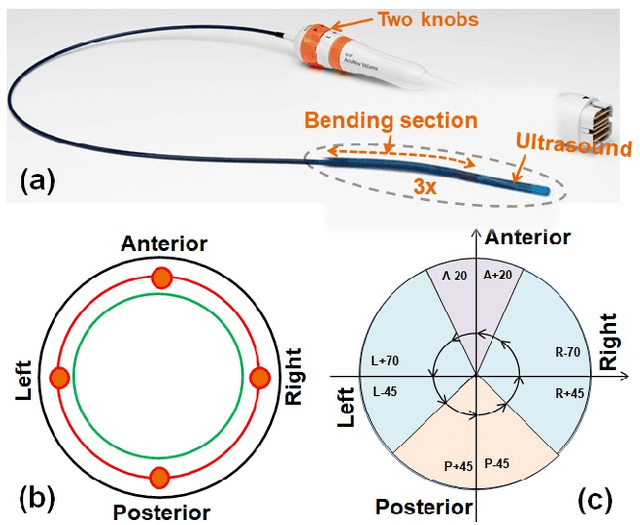
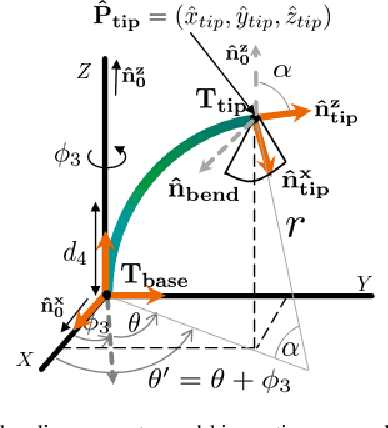
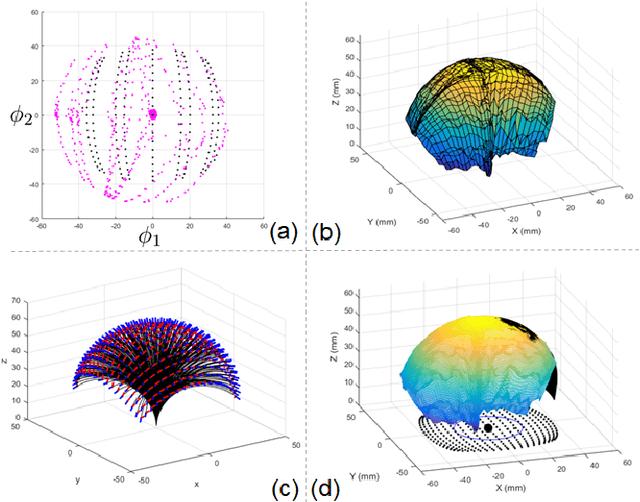
Intra-cardiac Echocardiography (ICE) has been evolving as a real-time imaging modality of choice for guiding electrophiosology and structural heart interventions. ICE provides real-time imaging of anatomy, catheters, and complications such as pericardial effusion or thrombus formation. However, there now exists a high cognitive demand on physicians with the increased reliance on intraprocedural imaging. In response, we present a robotic manipulator for AcuNav ICE catheters to alleviate the physician's burden and support applied methods for more automated. Herein, we introduce two methods towards these goals: (1) a data-driven method to compensate kinematic model errors due to non-linear elasticity in catheter bending, providing more precise robotic control and (2) an automated image recovery process that allows physicians to bookmark images during intervention and automatically return with the push of a button. To validate our error compensation method, we demonstrate a complex rotation of the ultrasound imaging plane evaluated on benchtop. Automated view recovery is validated by repeated imaging of landmarks on benchtop and in vivo experiments with position- and image-based analysis. Results support that a robotic-assist system for more autonomous ICE can provide a safe and efficient tool, potentially reducing the execution time and allowing more complex procedures to become common place.
Differentiable Rendering: A Survey
Jun 22, 2020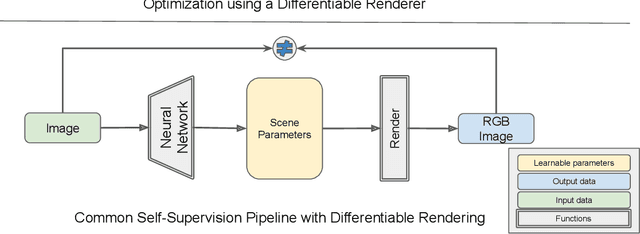
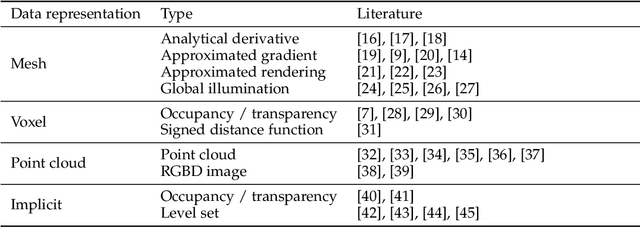
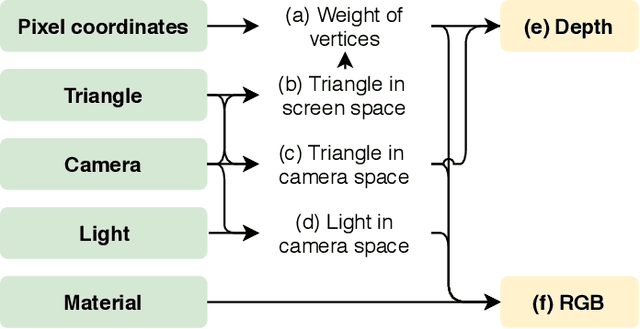

Deep neural networks (DNNs) have shown remarkable performance improvements on vision-related tasks such as object detection or image segmentation. Despite their success, they generally lack the understanding of 3D objects which form the image, as it is not always possible to collect 3D information about the scene or to easily annotate it. Differentiable rendering is a novel field which allows the gradients of 3D objects to be calculated and propagated through images. It also reduces the requirement of 3D data collection and annotation, while enabling higher success rate in various applications. This paper reviews existing literature and discusses the current state of differentiable rendering, its applications and open research problems.
Flare Prediction Using Photospheric and Coronal Image Data
Aug 03, 2017
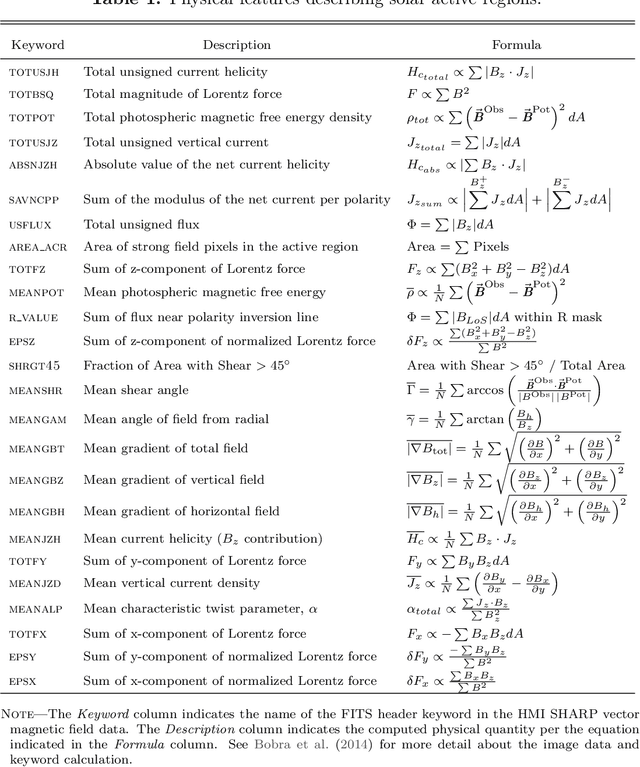
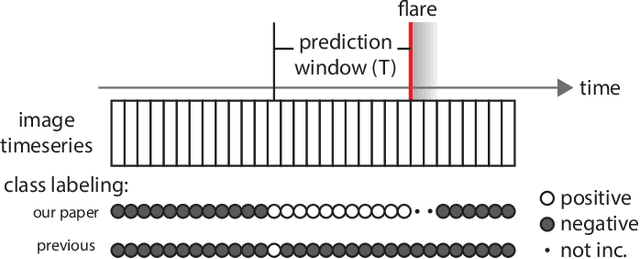

The precise physical process that triggers solar flares is not currently understood. Here we attempt to capture the signature of this mechanism in solar image data of various wavelengths and use these signatures to predict flaring activity. We do this by developing an algorithm that [1] automatically generates features in 5.5 TB of image data taken by the Solar Dynamics Observatory of the solar photosphere, chromosphere, transition region, and corona during the time period between May 2010 and May 2014, [2] combines these features with other features based on flaring history and a physical understanding of putative flaring processes, and [3] classifies these features to predict whether a solar active region will flare within a time period of $T$ hours, where $T$ = 2 and 24. We find that when optimizing for the True Skill Score (TSS), photospheric vector magnetic field data combined with flaring history yields the best performance, and when optimizing for the area under the precision-recall curve, all the data are helpful. Our model performance yields a TSS of $0.84 \pm 0.03$ and $0.81 \pm 0.03$ in the $T$ = 2 and 24 hour cases, respectively, and a value of $0.13 \pm 0.07$ and $0.43 \pm 0.08$ for the area under the precision-recall curve in the $T$ = 2 and 24 hour cases, respectively. These relatively high scores are similar to, but not greater than, other attempts to predict solar flares. Given the similar values of algorithm performance across various types of models reported in the literature, we conclude that we can expect a certain baseline predictive capacity using these data. This is the first attempt to predict solar flares using photospheric vector magnetic field data as well as multiple wavelengths of image data from the chromosphere, transition region, and corona.
3D Reconstruction of Simple Objects from A Single View Silhouette Image
Jan 17, 2017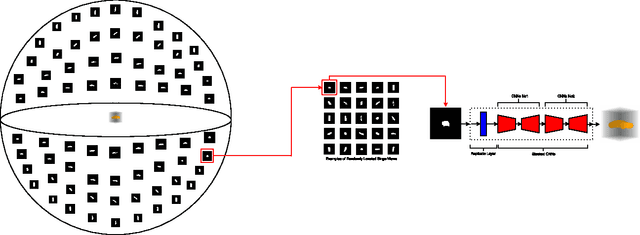


While recent deep neural networks have achieved promising results for 3D reconstruction from a single-view image, these rely on the availability of RGB textures in images and extra information as supervision. In this work, we propose novel stacked hierarchical networks and an end to end training strategy to tackle a more challenging task for the first time, 3D reconstruction from a single-view 2D silhouette image. We demonstrate that our model is able to conduct 3D reconstruction from a single-view silhouette image both qualitatively and quantitatively. Evaluation is performed using Shapenet for the single-view reconstruction and results are presented in comparison with a single network, to highlight the improvements obtained with the proposed stacked networks and the end to end training strategy. Furthermore, 3D re- construction in forms of IoU is compared with the state of art 3D reconstruction from a single-view RGB image, and the proposed model achieves higher IoU than the state of art of reconstruction from a single view RGB image.
Online Adaptation for Consistent Mesh Reconstruction in the Wild
Dec 06, 2020

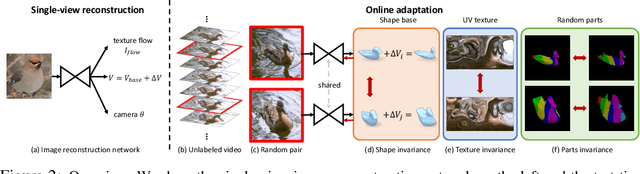
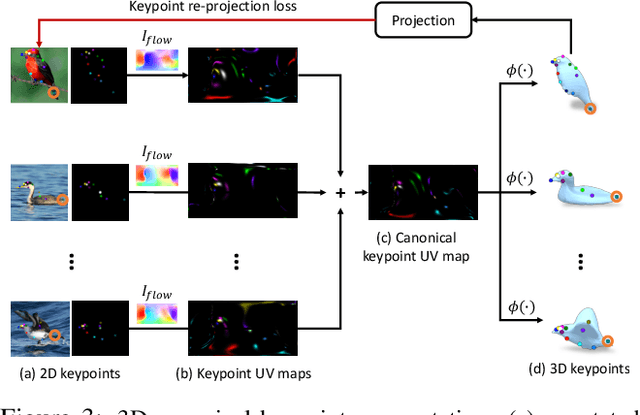
This paper presents an algorithm to reconstruct temporally consistent 3D meshes of deformable object instances from videos in the wild. Without requiring annotations of 3D mesh, 2D keypoints, or camera pose for each video frame, we pose video-based reconstruction as a self-supervised online adaptation problem applied to any incoming test video. We first learn a category-specific 3D reconstruction model from a collection of single-view images of the same category that jointly predicts the shape, texture, and camera pose of an image. Then, at inference time, we adapt the model to a test video over time using self-supervised regularization terms that exploit temporal consistency of an object instance to enforce that all reconstructed meshes share a common texture map, a base shape, as well as parts. We demonstrate that our algorithm recovers temporally consistent and reliable 3D structures from videos of non-rigid objects including those of animals captured in the wild -- an extremely challenging task rarely addressed before.
MAD-VAE: Manifold Awareness Defense Variational Autoencoder
Oct 31, 2020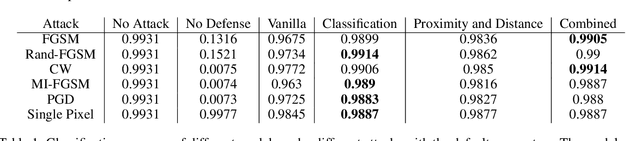


Although deep generative models such as Defense-GAN and Defense-VAE have made significant progress in terms of adversarial defenses of image classification neural networks, several methods have been found to circumvent these defenses. Based on Defense-VAE, in our research we introduce several methods to improve the robustness of defense models. The methods introduced in this paper are straight forward yet show promise over the vanilla Defense-VAE. With extensive experiments on MNIST data set, we have demonstrated the effectiveness of our algorithms against different attacks. Our experiments also include attacks on the latent space of the defensive model. We also discuss the applicability of existing adversarial latent space attacks as they may have a significant flaw.
AU-Guided Unsupervised Domain Adaptive Facial Expression Recognition
Dec 18, 2020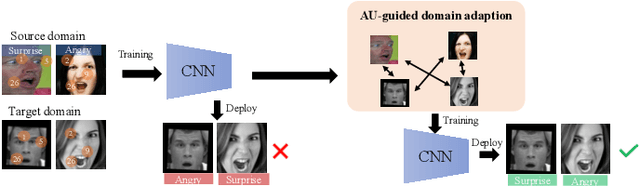
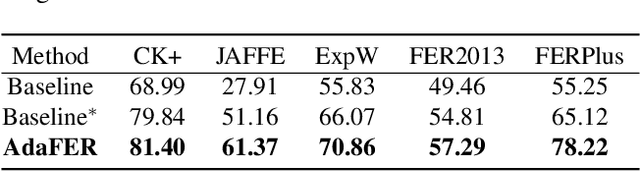
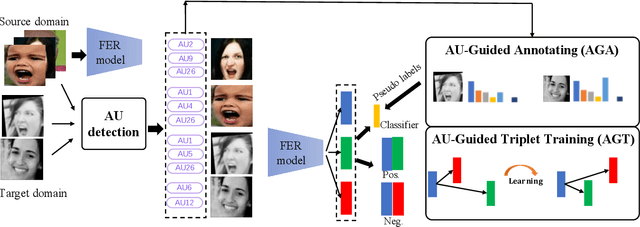
The domain diversities including inconsistent annotation and varied image collection conditions inevitably exist among different facial expression recognition (FER) datasets, which pose an evident challenge for adapting the FER model trained on one dataset to another one. Recent works mainly focus on domain-invariant deep feature learning with adversarial learning mechanism, ignoring the sibling facial action unit (AU) detection task which has obtained great progress. Considering AUs objectively determine facial expressions, this paper proposes an AU-guided unsupervised Domain Adaptive FER (AdaFER) framework. In AdaFER, we first leverage an advanced model for AU detection on both source and target domain. Then, we compare the AU results to perform AU-guided annotating, i.e., target faces that own the same AUs with source faces would inherit the labels from source domain. Meanwhile, to achieve domain-invariant compact features, we utilize an AU-guided triplet training which randomly collects anchor-positive-negative triplets on both domains with AUs. We conduct extensive experiments on several popular benchmarks and show that AdaFER achieves state-of-the-art results on all the benchmarks.
NoPeopleAllowed: The Three-Step Approach to Weakly Supervised Semantic Segmentation
Jun 13, 2020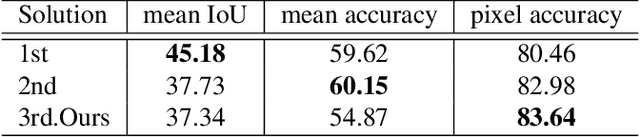


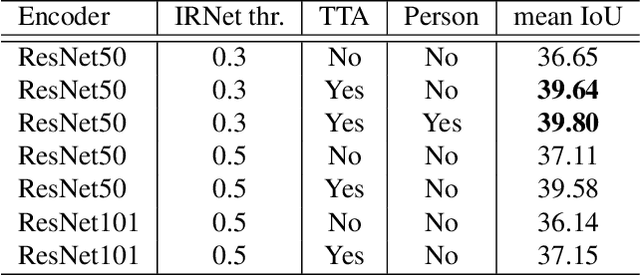
We propose a novel approach to weakly supervised semantic segmentation, which consists of three consecutive steps. The first two steps extract high-quality pseudo masks from image-level annotated data, which are then used to train a segmentation model on the third step. The presented approach also addresses two problems in the data: class imbalance and missing labels. Using only image-level annotations as supervision, our method is capable of segmenting various classes and complex objects. It achieves 37.34 mean IoU on the test set, placing 3rd at the LID Challenge in the task of weakly supervised semantic segmentation.
An Efficient Generation Method based on Dynamic Curvature of the Reference Curve for Robust Trajectory Planning
Dec 29, 2020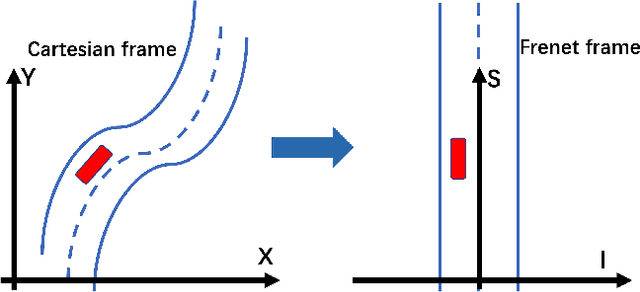
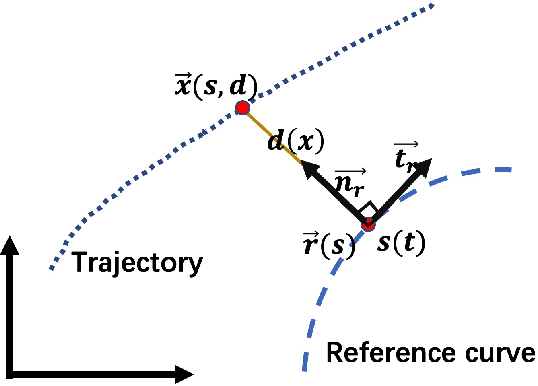
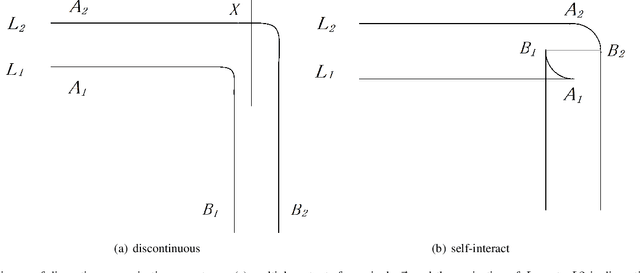
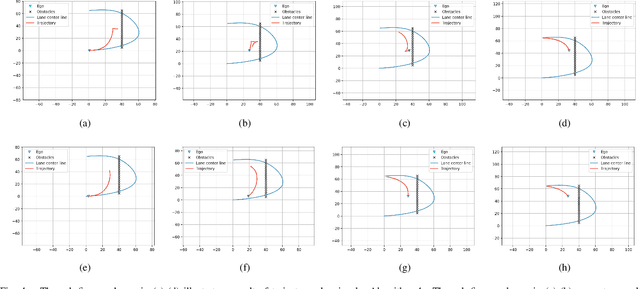
Trajectory planning is a fundamental task on various autonomous driving platforms, such as social robotics and self-driving cars. Many trajectory planning algorithms use a reference curve based Frenet frame with time to reduce the planning dimension. However, there is a common implicit assumption in classic trajectory planning approaches, which is that the generated trajectory should follow the reference curve continuously. This assumption is not always true in real applications and it might cause some undesired issues in planning. One issue is that the projection of the planned trajectory onto the reference curve maybe discontinuous. Then, some segments on the reference curve are not the image of any part of the planned path. Another issue is that the planned path might self-intersect when following a simple reference curve continuously. The generated trajectories are unnatural and suboptimal ones when these issues happen. In this paper, we firstly demonstrate these issues and then introduce an efficient trajectory generation method which uses a new transformation from the Cartesian frame to Frenet frames. Experimental results on a simulated street scenario demonstrated the effectiveness of the proposed method.