 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep learning based prediction of Alzheimer's disease from magnetic resonance images
Jan 13, 2021
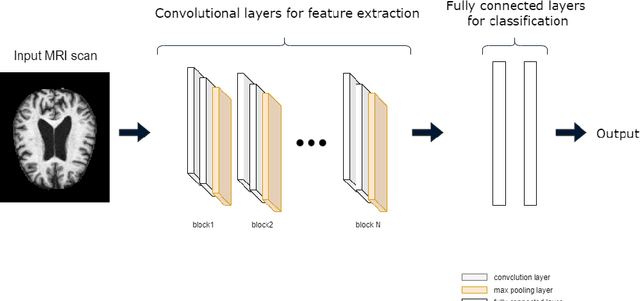
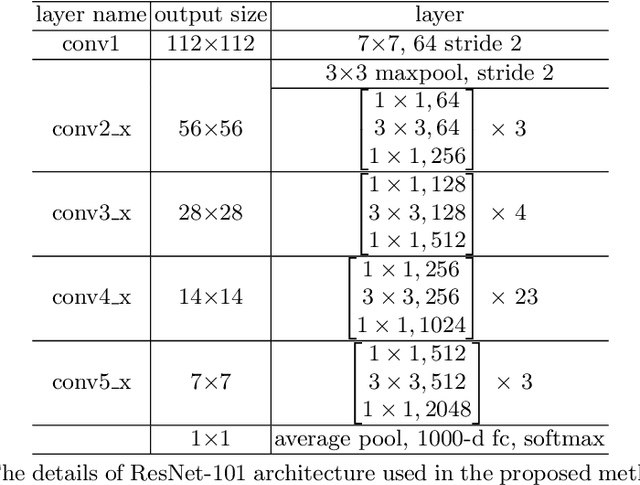
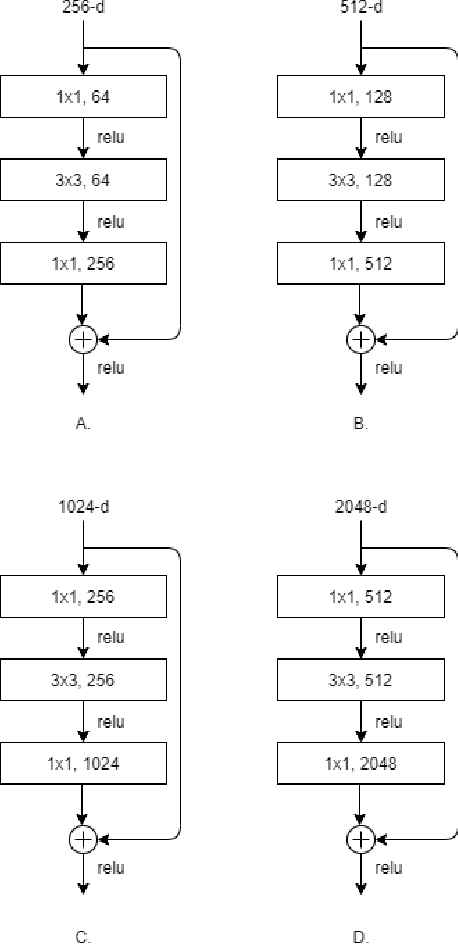
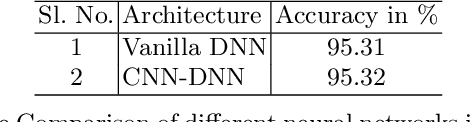
Alzheimer's disease (AD) is an irreversible, progressive neuro degenerative disorder that slowly destroys memory and thinking skills and eventually, the ability to carry out the simplest tasks. In this paper, a deep neural network based prediction of AD from magnetic resonance images (MRI) is proposed. The state of the art image classification networks like VGG, residual networks (ResNet) etc. with transfer learning shows promising results. Performance of pre-trained versions of these networks are improved by transfer learning. ResNet based architecture with large number of layers is found to give the best result in terms of predicting different stages of the disease. The experiments are conducted on Kaggle dataset.
Multi Receptive Field Network for Semantic Segmentation
Nov 17, 2020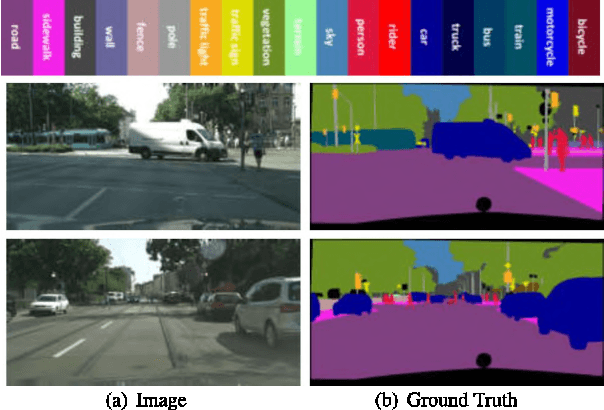
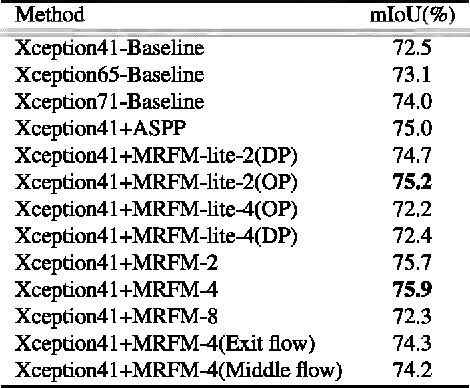
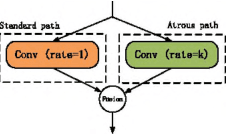

Semantic segmentation is one of the key tasks in computer vision, which is to assign a category label to each pixel in an image. Despite significant progress achieved recently, most existing methods still suffer from two challenging issues: 1) the size of objects and stuff in an image can be very diverse, demanding for incorporating multi-scale features into the fully convolutional networks (FCNs); 2) the pixels close to or at the boundaries of object/stuff are hard to classify due to the intrinsic weakness of convolutional networks. To address the first issue, we propose a new Multi-Receptive Field Module (MRFM), explicitly taking multi-scale features into account. For the second issue, we design an edge-aware loss which is effective in distinguishing the boundaries of object/stuff. With these two designs, our Multi Receptive Field Network achieves new state-of-the-art results on two widely-used semantic segmentation benchmark datasets. Specifically, we achieve a mean IoU of 83.0 on the Cityscapes dataset and 88.4 mean IoU on the Pascal VOC2012 dataset.
Topo-boundary: A Benchmark Dataset on Topological Road-boundary Detection Using Aerial Images for Autonomous Driving
Mar 31, 2021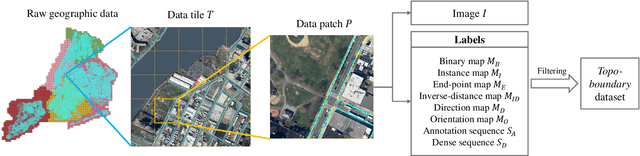

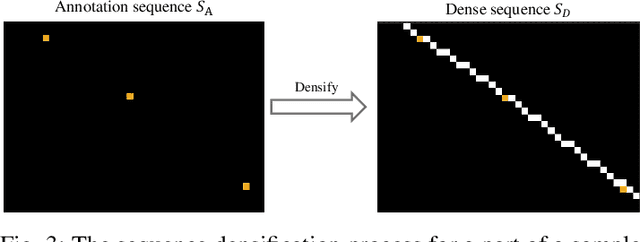
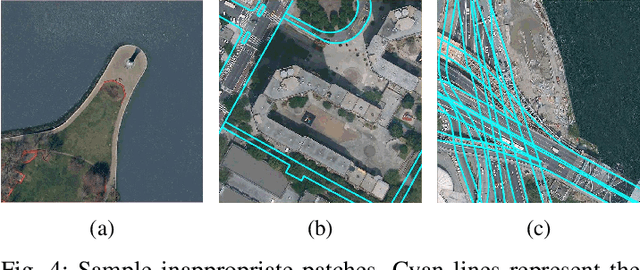
Road-boundary detection is important for autonomous driving. For example, it can be used to constrain vehicles running on road areas, which ensures driving safety. Compared with on-line road-boundary detection using on-vehicle cameras/Lidars, off-line detection using aerial images could alleviate the severe occlusion issue. Moreover, the off-line detection results can be directly used to annotate high-definition (HD) maps. In recent years, deep-learning technologies have been used in off-line detection. But there is still lacking a publicly available dataset for this task, which hinders the research progress in this area. So in this paper, we propose a new benchmark dataset, named \textit{Topo-boundary}, for off-line topological road-boundary detection. The dataset contains 21,556 $1000\times1000$-sized 4-channel aerial images. Each image is provided with 8 training labels for different sub-tasks. We also design a new entropy-based metric for connectivity evaluation, which could better handle noises or outliers. We implement and evaluate 3 segmentation-based baselines and 5 graph-based baselines using the dataset. We also propose a new imitation-learning-based baseline which is enhanced from our previous work. The superiority of our enhancement is demonstrated from the comparison. The dataset and our-implemented codes for the baselines are available at https://sites.google.com/view/topo-boundary.
Generalizing Face Forgery Detection with High-frequency Features
Mar 23, 2021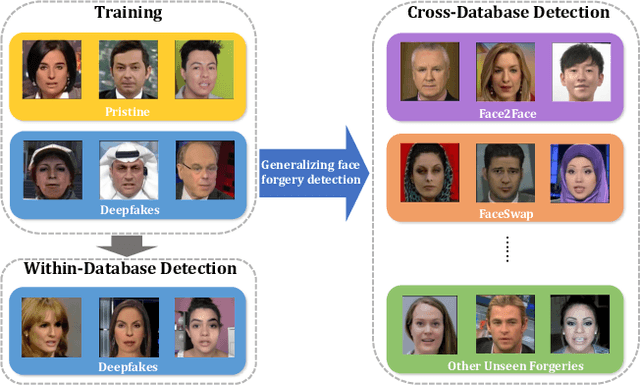
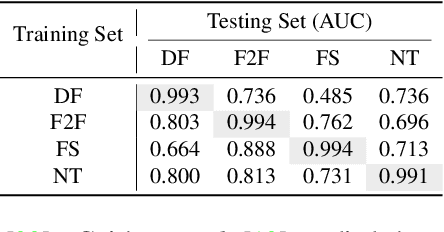


Current face forgery detection methods achieve high accuracy under the within-database scenario where training and testing forgeries are synthesized by the same algorithm. However, few of them gain satisfying performance under the cross-database scenario where training and testing forgeries are synthesized by different algorithms. In this paper, we find that current CNN-based detectors tend to overfit to method-specific color textures and thus fail to generalize. Observing that image noises remove color textures and expose discrepancies between authentic and tampered regions, we propose to utilize the high-frequency noises for face forgery detection. We carefully devise three functional modules to take full advantage of the high-frequency features. The first is the multi-scale high-frequency feature extraction module that extracts high-frequency noises at multiple scales and composes a novel modality. The second is the residual-guided spatial attention module that guides the low-level RGB feature extractor to concentrate more on forgery traces from a new perspective. The last is the cross-modality attention module that leverages the correlation between the two complementary modalities to promote feature learning for each other. Comprehensive evaluations on several benchmark databases corroborate the superior generalization performance of our proposed method.
Motion-blurred Video Interpolation and Extrapolation
Mar 04, 2021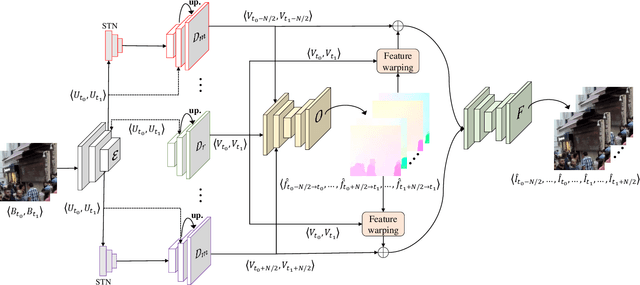
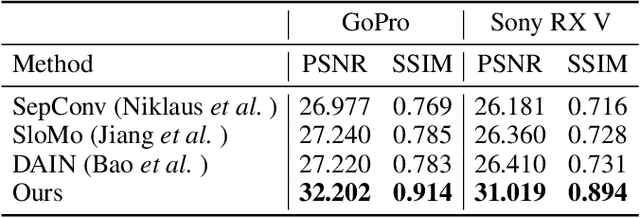

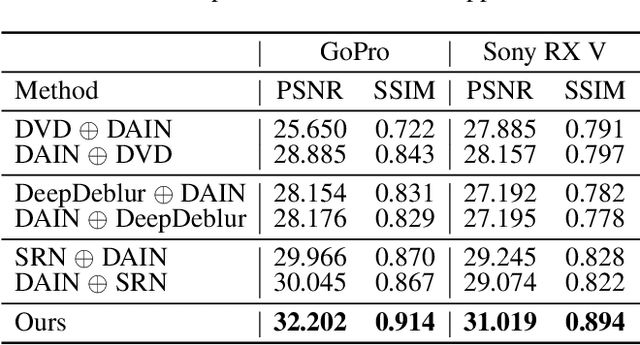
Abrupt motion of camera or objects in a scene result in a blurry video, and therefore recovering high quality video requires two types of enhancements: visual enhancement and temporal upsampling. A broad range of research attempted to recover clean frames from blurred image sequences or temporally upsample frames by interpolation, yet there are very limited studies handling both problems jointly. In this work, we present a novel framework for deblurring, interpolating and extrapolating sharp frames from a motion-blurred video in an end-to-end manner. We design our framework by first learning the pixel-level motion that caused the blur from the given inputs via optical flow estimation and then predict multiple clean frames by warping the decoded features with the estimated flows. To ensure temporal coherence across predicted frames and address potential temporal ambiguity, we propose a simple, yet effective flow-based rule. The effectiveness and favorability of our approach are highlighted through extensive qualitative and quantitative evaluations on motion-blurred datasets from high speed videos.
Pattern Recognition Scheme for Large-Scale Cloud Detection over Landmarks
Dec 08, 2020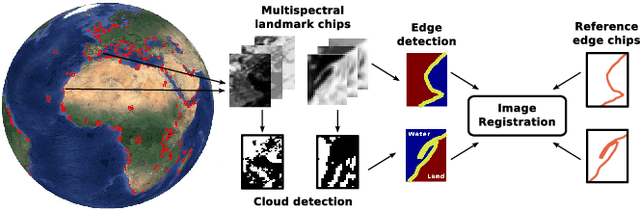

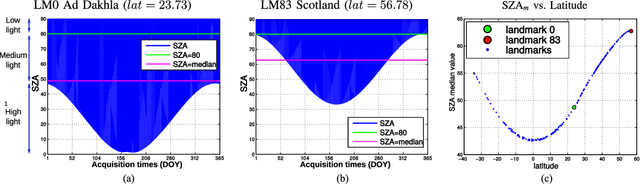
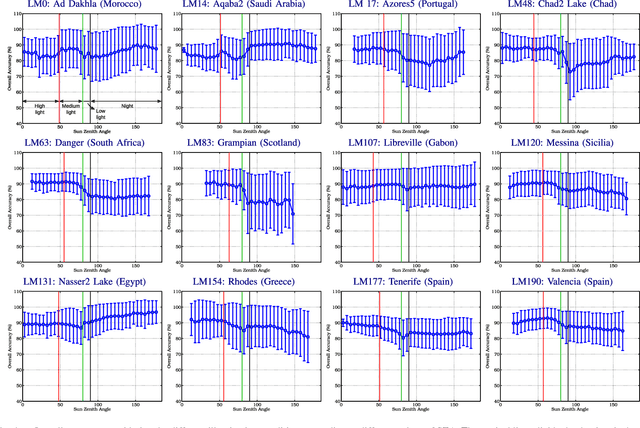
Landmark recognition and matching is a critical step in many Image Navigation and Registration (INR) models for geostationary satellite services, as well as to maintain the geometric quality assessment (GQA) in the instrument data processing chain of Earth observation satellites. Matching the landmark accurately is of paramount relevance, and the process can be strongly impacted by the cloud contamination of a given landmark. This paper introduces a complete pattern recognition methodology able to detect the presence of clouds over landmarks using Meteosat Second Generation (MSG) data. The methodology is based on the ensemble combination of dedicated support vector machines (SVMs) dependent on the particular landmark and illumination conditions. This divide-and-conquer strategy is motivated by the data complexity and follows a physically-based strategy that considers variability both in seasonality and illumination conditions along the day to split observations. In addition, it allows training the classification scheme with millions of samples at an affordable computational costs. The image archive was composed of 200 landmark test sites with near 7 million multispectral images that correspond to MSG acquisitions during 2010. Results are analyzed in terms of cloud detection accuracy and computational cost. We provide illustrative source code and a portion of the huge training data to the community.
Turkey Behavior Identification System with a GUI Using Deep Learning and Video Analytics
Feb 09, 2021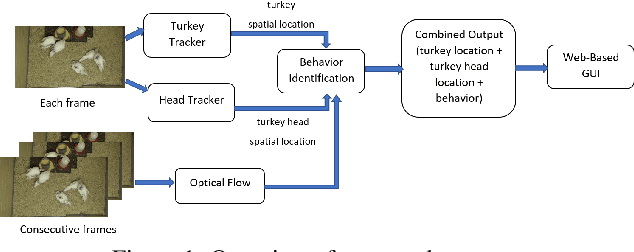
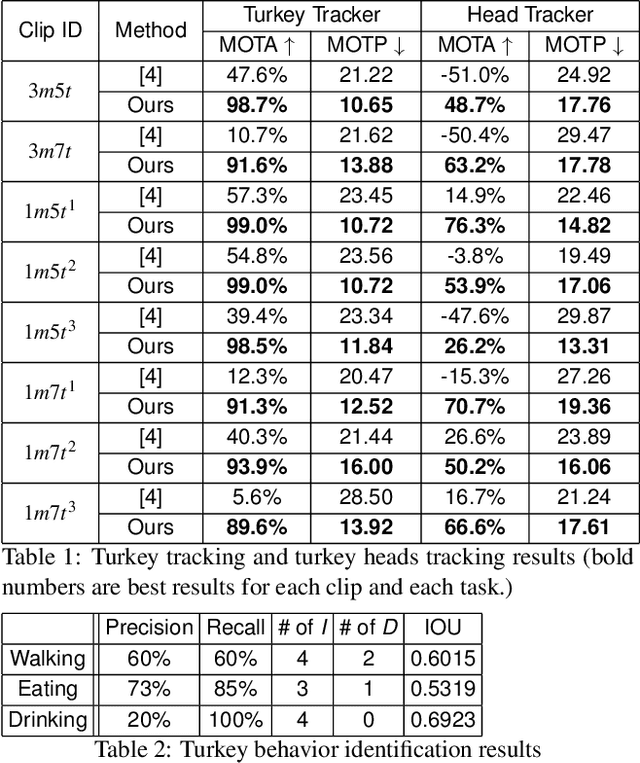


In this paper, we propose a video analytics system to identify the behavior of turkeys. Turkey behavior provides evidence to assess turkey welfare, which can be negatively impacted by uncomfortable ambient temperature and various diseases. In particular, healthy and sick turkeys behave differently in terms of the duration and frequency of activities such as eating, drinking, preening, and aggressive interactions. Our system incorporates recent advances in object detection and tracking to automate the process of identifying and analyzing turkey behavior captured by commercial grade cameras. We combine deep-learning and traditional image processing methods to address challenges in this practical agricultural problem. Our system also includes a web-based user interface to create visualization of automated analysis results. Together, we provide an improved tool for turkey researchers to assess turkey welfare without the time-consuming and labor-intensive manual inspection.
Learning Product Codebooks using Vector Quantized Autoencoders for Image Retrieval
Jul 19, 2018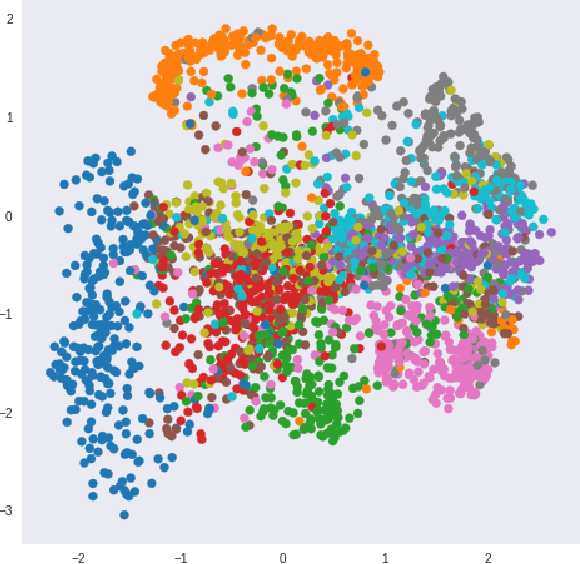
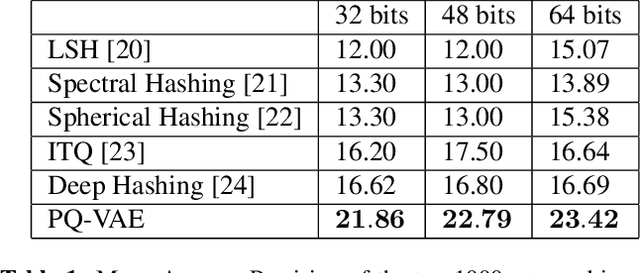
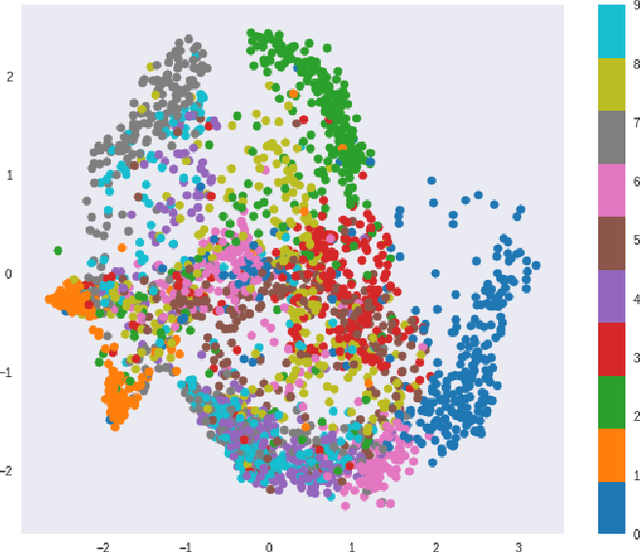
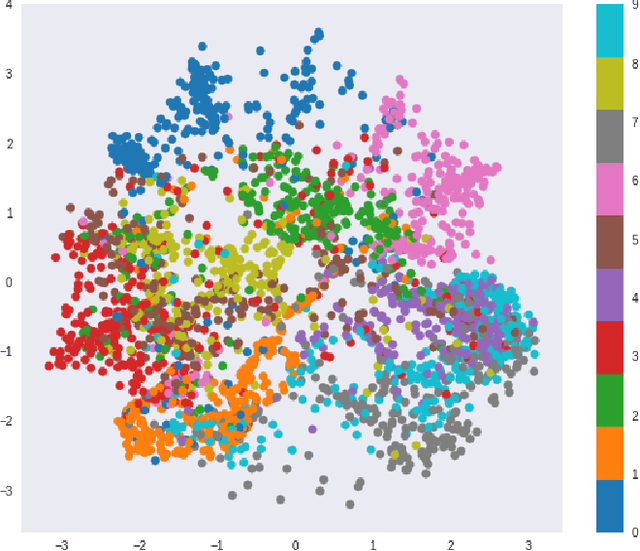
The Vector Quantized-Variational Autoencoder (VQ-VAE) [1] provides an unsupervised model for learning discrete representations by combining vector quantization and autoencoders. The VQ-VAE can avoid the issue of "posterior collapse" so that its learned discrete representation is meaningful. In this paper, we incorporate the product quantization into the bottleneck stage of VQ-VAE and propose an end-to-end unsupervised learning model for the image retrieval tasks. Compared to the classic vector quantization, product quantization has the advantage of generating large size codebook and fast retrieval can be achieved by using the lookup tables that store the distance between every two sub-codewords. In our proposed model, the product codebook is jointly learned with the encoders and decoders of the autoencoders. The encodings of query and database images can be generated by feeding the images into the trained encoder and learned product codebook. The experiment shows that our proposed model outperforms other state-of-the-art hashing and quantization methods for the image retrieval task.
How Unique Is a Face: An Investigative Study
Feb 09, 2021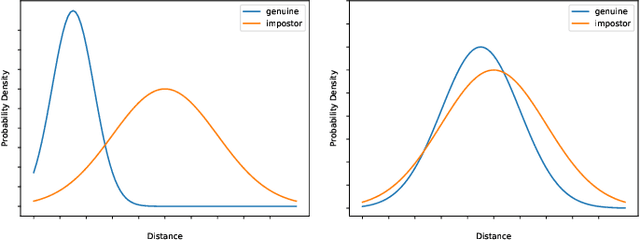

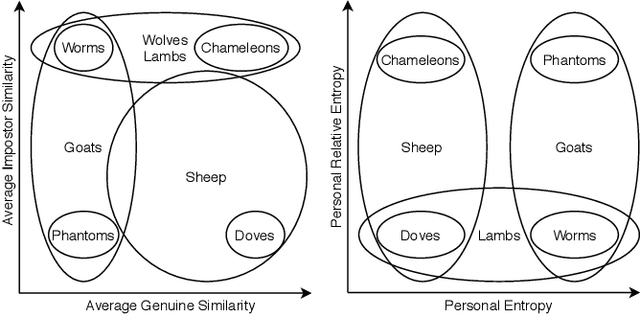
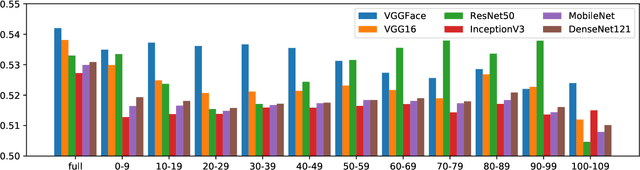
Face recognition has been widely accepted as a means of identification in applications ranging from border control to security in the banking sector. Surprisingly, while widely accepted, we still lack the understanding of uniqueness or distinctiveness of faces as biometric modality. In this work, we study the impact of factors such as image resolution, feature representation, database size, age and gender on uniqueness denoted by the Kullback-Leibler divergence between genuine and impostor distributions. Towards understanding the impact, we present experimental results on the datasets AT&T, LFW, IMDb-Face, as well as ND-TWINS, with the feature extraction algorithms VGGFace, VGG16, ResNet50, InceptionV3, MobileNet and DenseNet121, that reveal the quantitative impact of the named factors. While these are early results, our findings indicate the need for a better understanding of the concept of biometric uniqueness and its implication on face recognition.
Spatial-Channel Transformer Network for Trajectory Prediction on the Traffic Scenes
Jan 27, 2021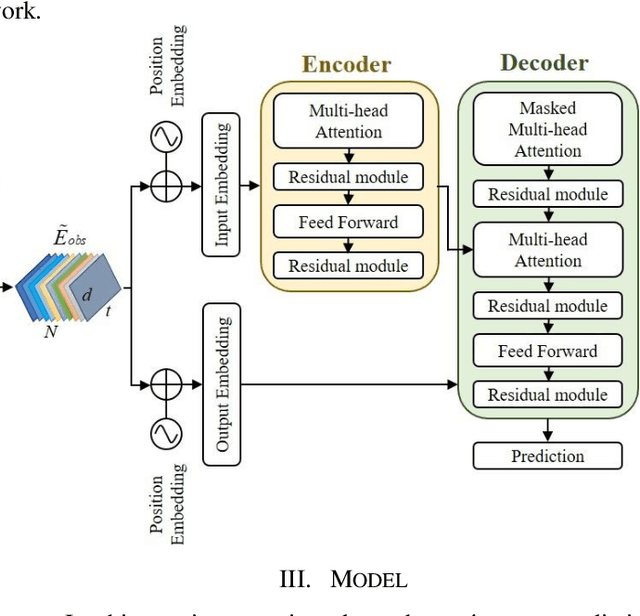
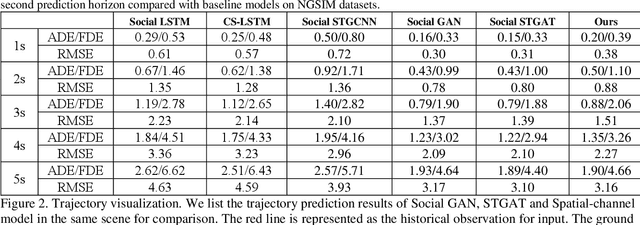
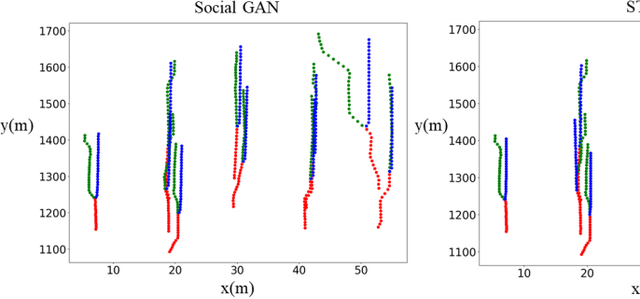
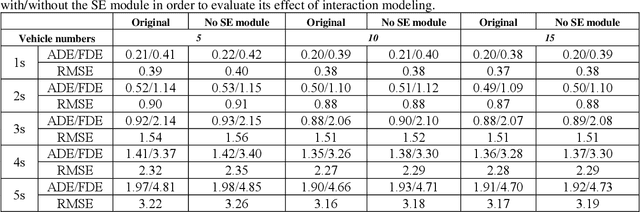
Predicting motion of surrounding agents is critical to real-world applications of tactical path planning for autonomous driving. Due to the complex temporal dependencies and social interactions of agents, on-line trajectory prediction is a challenging task. With the development of attention mechanism in recent years, transformer model has been applied in natural language sequence processing first and then image processing. In this paper, we present a Spatial-Channel Transformer Network for trajectory prediction with attention functions. Instead of RNN models, we employ transformer model to capture the spatial-temporal features of agents. A channel-wise module is inserted to measure the social interaction between agents. We find that the Spatial-Channel Transformer Network achieves promising results on real-world trajectory prediction datasets on the traffic scenes.