 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapformer: Adaptive Channel Management for Multivariate Time Series Forecasting
Nov 18, 2025



In multivariate time series forecasting (MTSF), accurately modeling the intricate dependencies among multiple variables remains a significant challenge due to the inherent limitations of traditional approaches. Most existing models adopt either \textbf{channel-independent} (CI) or \textbf{channel-dependent} (CD) strategies, each presenting distinct drawbacks. CI methods fail to leverage the potential insights from inter-channel interactions, resulting in models that may not fully exploit the underlying statistical dependencies present in the data. Conversely, CD approaches often incorporate too much extraneous information, risking model overfitting and predictive inefficiency. To address these issues, we introduce the Adaptive Forecasting Transformer (\textbf{Adapformer}), an advanced Transformer-based framework that merges the benefits of CI and CD methodologies through effective channel management. The core of Adapformer lies in its dual-stage encoder-decoder architecture, which includes the \textbf{A}daptive \textbf{C}hannel \textbf{E}nhancer (\textbf{ACE}) for enriching embedding processes and the \textbf{A}daptive \textbf{C}hannel \textbf{F}orecaster (\textbf{ACF}) for refining the predictions. ACE enhances token representations by selectively incorporating essential dependencies, while ACF streamlines the decoding process by focusing on the most relevant covariates, substantially reducing noise and redundancy. Our rigorous testing on diverse datasets shows that Adapformer achieves superior performance over existing models, enhancing both predictive accuracy and computational efficiency, thus making it state-of-the-art in MTSF.
Deep Transfer Learning: Model Framework and Error Analysis
Oct 12, 2024



This paper presents a framework for deep transfer learning, which aims to leverage information from multi-domain upstream data with a large number of samples $n$ to a single-domain downstream task with a considerably smaller number of samples $m$, where $m \ll n$, in order to enhance performance on downstream task. Our framework has several intriguing features. First, it allows the existence of both shared and specific features among multi-domain data and provides a framework for automatic identification, achieving precise transfer and utilization of information. Second, our model framework explicitly indicates the upstream features that contribute to downstream tasks, establishing a relationship between upstream domains and downstream tasks, thereby enhancing interpretability. Error analysis demonstrates that the transfer under our framework can significantly improve the convergence rate for learning Lipschitz functions in downstream supervised tasks, reducing it from $\tilde{O}(m^{-\frac{1}{2(d+2)}}+n^{-\frac{1}{2(d+2)}})$ ("no transfer") to $\tilde{O}(m^{-\frac{1}{2(d^*+3)}} + n^{-\frac{1}{2(d+2)}})$ ("partial transfer"), and even to $\tilde{O}(m^{-1/2}+n^{-\frac{1}{2(d+2)}})$ ("complete transfer"), where $d^* \ll d$ and $d$ is the dimension of the observed data. Our theoretical findings are substantiated by empirical experiments conducted on image classification datasets, along with a regression dataset.
Detecting Adversarial Data via Perturbation Forgery
May 25, 2024



As a defense strategy against adversarial attacks, adversarial detection aims to identify and filter out adversarial data from the data flow based on discrepancies in distribution and noise patterns between natural and adversarial data. Although previous detection methods achieve high performance in detecting gradient-based adversarial attacks, new attacks based on generative models with imbalanced and anisotropic noise patterns evade detection. Even worse, existing techniques either necessitate access to attack data before deploying a defense or incur a significant time cost for inference, rendering them impractical for defending against newly emerging attacks that are unseen by defenders. In this paper, we explore the proximity relationship between adversarial noise distributions and demonstrate the existence of an open covering for them. By learning to distinguish this open covering from the distribution of natural data, we can develop a detector with strong generalization capabilities against all types of adversarial attacks. Based on this insight, we heuristically propose Perturbation Forgery, which includes noise distribution perturbation, sparse mask generation, and pseudo-adversarial data production, to train an adversarial detector capable of detecting unseen gradient-based, generative-model-based, and physical adversarial attacks, while remaining agnostic to any specific models. Comprehensive experiments conducted on multiple general and facial datasets, with a wide spectrum of attacks, validate the strong generalization of our method.
Generalizing Face Forgery Detection with High-frequency Features
Mar 23, 2021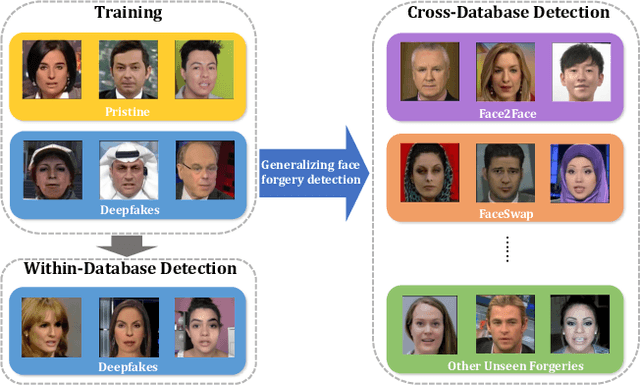
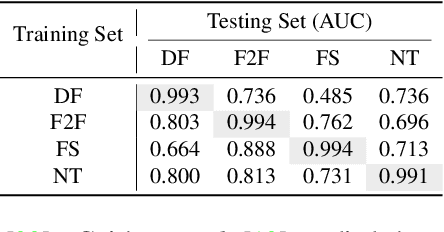


Current face forgery detection methods achieve high accuracy under the within-database scenario where training and testing forgeries are synthesized by the same algorithm. However, few of them gain satisfying performance under the cross-database scenario where training and testing forgeries are synthesized by different algorithms. In this paper, we find that current CNN-based detectors tend to overfit to method-specific color textures and thus fail to generalize. Observing that image noises remove color textures and expose discrepancies between authentic and tampered regions, we propose to utilize the high-frequency noises for face forgery detection. We carefully devise three functional modules to take full advantage of the high-frequency features. The first is the multi-scale high-frequency feature extraction module that extracts high-frequency noises at multiple scales and composes a novel modality. The second is the residual-guided spatial attention module that guides the low-level RGB feature extractor to concentrate more on forgery traces from a new perspective. The last is the cross-modality attention module that leverages the correlation between the two complementary modalities to promote feature learning for each other. Comprehensive evaluations on several benchmark databases corroborate the superior generalization performance of our proposed method.
RGB-D Individual Segmentation
Nov 11, 2019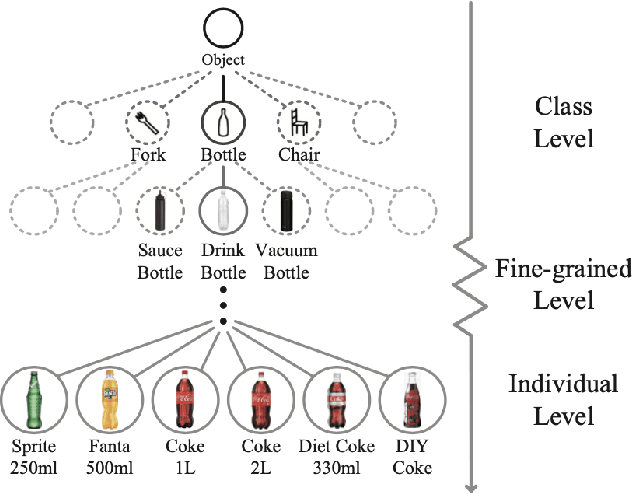
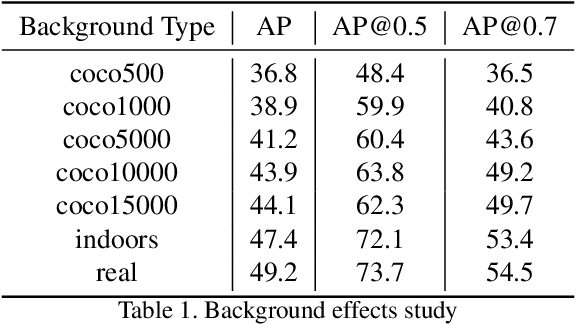
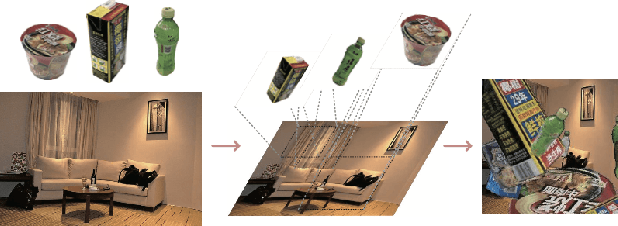
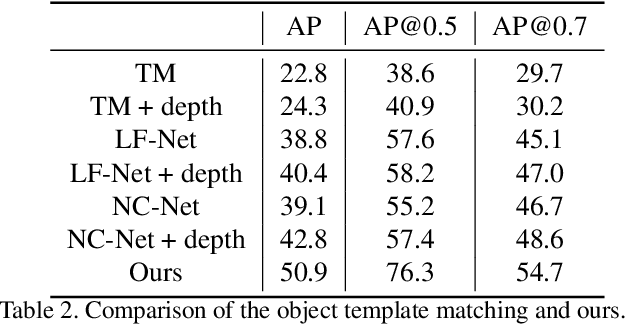
Fine-grained recognition task deals with sub-category classification problem, which is important for real-world applications. In this work, we are particularly interested in the segmentation task on the \emph{finest-grained} level, which is specifically named "individual segmentation". In other words, the individual-level category has no sub-category under it. Segmentation problem in the individual level reveals some new properties, limited training data for single individual object, unknown background, and difficulty for the use of depth. To address these new problems, we propose a "Context Less-Aware" (CoLA) pipeline, which produces RGB-D object-predominated images that have less background context, and enables a scale-aware training and testing with 3D information. Extensive experiments show that the proposed CoLA strategy largely outperforms baseline methods on YCB-Video dataset and our proposed Supermarket-10K dataset. Code, trained model and new dataset will be published with this paper.