 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeRx-Agent: A Knowledge-Grounded Multi-Agent Framework for Safe and Explainable Medication Recommendation
May 27, 2026Medication recommendation predicts medications for patient visits, but existing methods still face two key challenges. At the model level, traditional drug recommendation methods only predict structured drug codes with limited evidence grounding, while LLM agents can use richer clinical context but may lack safety verification and traceability. At the task level, existing benchmarks often use broad medication categories, which ignore subgroup-level safety differences and can lead to risk overestimation. We introduce the first fine-grained medication recommendation setting based on fourth-level ATC code generation. We propose Safe Prescription Agent (SafeRx-Agent), a knowledge-grounded multi-agent framework that uses patient context, external clinical knowledge, and safety verification to recommend traceable medication sets. Experimental results on MIMIC-III and MIMIC-IV datasets show that SafeRx-Agent improves fine-grained medication prediction accuracy while controlling drug interactions, contraindications, and medication set size.
From Table to Cell: Attention for Better Reasoning with TABALIGN
May 14, 2026Multi-step LLM reasoning over structured tables fails because planning and execution share no explicit cell-grounding contract. Existing methods constrain the planner to a left-to-right factorization at odds with table permutation invariance, and score intermediate states by generated content alone, overlooking cell grounding. We conduct a pilot study showing that diffusion language models (DLMs) produce more human-aligned and permutation-stable cell attention on tables than autoregressive models, with a 40.2% median reduction in attention-AUROC variability under row reordering. Motivated by this, we propose TABALIGN, a planned table reasoning framework that operationalizes the contract. TABALIGN pairs a masked DLM planner, whose bidirectional denoising emits plan steps as binary cell masks, with TABATTN, a lightweight verifier trained on 1,600 human-verified attention standards to score each step by its attention overlap with the plan-designated mask. Across eight benchmarks covering table question answering and fact verification, TABALIGN improves average accuracy by 15.76 percentage points over the strongest open-source baseline at comparable 8B-class scale, with a matched-backbone ablation attributing 2.87 percentage points of this gain to the DLM planner over an AR planner on a fixed reasoner. Cleaner DLM plans also accelerate downstream reasoning execution by 44.64%.
Co-Evolution of Policy and Internal Reward for Language Agents
Apr 03, 2026Large language model (LLM) agents learn by interacting with environments, but long-horizon training remains fundamentally bottlenecked by sparse and delayed rewards. Existing methods typically address this challenge through post-hoc credit assignment or external reward models, which provide limited guidance at inference time and often separate reward improvement from policy improvement. We propose Self-Guide, a self-generated internal reward for language agents that supports both inference-time guidance and training-time supervision. Specifically, the agent uses Self-Guide as a short self-guidance signal to steer the next action during inference, and converts the same signal into step-level internal reward for denser policy optimization during training. This creates a co-evolving loop: better policy produces better guidance, and better guidance further improves policy as internal reward. Across three agent benchmarks, inference-time self-guidance already yields clear gains, while jointly evolving policy and internal reward with GRPO brings further improvements (8\%) over baselines trained solely with environment reward. Overall, our results suggest that language agents can improve not only by collecting more experience, but also by learning to generate and refine their own internal reward during acting and learning.
TABQAWORLD: Optimizing Multimodal Reasoning for Multi-Turn Table Question Answering
Apr 03, 2026Multimodal reasoning has emerged as a powerful framework for enhancing reasoning capabilities of reasoning models. While multi-turn table reasoning methods have improved reasoning accuracy through tool use and reward modeling, they rely on fixed text serialization for table state readouts. This introduces representation errors in table encoding that significantly accumulate over multiple turns. Such accumulation is alleviated by tabular grounding methods in the expense of inference compute and cost, rendering real world deployment impractical. To address this, we introduce TABQAWORLD, a table reasoning framework that jointly optimizes tabular action through representation and estimation. For representation, TABQAWORLD employs an action-conditioned multimodal selection policy, which dynamically switches between visual and textual representations to maximize table state readout reliability. For estimation, TABQAWORLD optimizes stepwise reasoning trajectory through table metadata including dimension, data types and key values, safely planning trajectory and compressing low-complexity actions to reduce conversation turns and latency. Designed as a training-free framework, empirical evaluations show that TABQAWORLD achieves state-of-the-art performance with 4.87% accuracy improvements over baselines, with 5.42% accuracy gain and 33.35% inference latency reduction over static settings, establishing a new standard for reliable and efficient table reasoning.
Conditional Mutual information-based Contrastive Loss for Financial Time Series Forecasting
Feb 18, 2020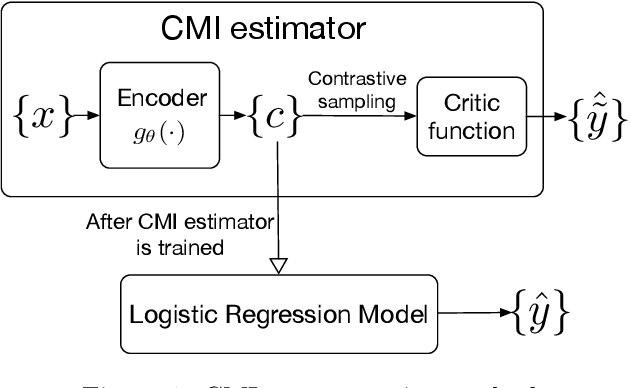



We present a method for financial time series forecasting using representation learning techniques. Recent progress on deep autoregressive models has shown their ability to capture long-term dependencies of the sequence data. However, the shortage of available financial data for training will make the deep models susceptible to the overfitting problem. In this paper, we propose a neural-network-powered conditional mutual information (CMI) estimator for learning representations for the forecasting task. Specifically, we first train an encoder to maximize the mutual information between the latent variables and the label information conditioned on the encoded observed variables. Then the features extracted from the trained encoder are used to learn a subsequent logistic regression model for predicting time series movements. Our proposed estimator transforms the CMI maximization problem to a classification problem whether two encoded representations are sampled from the same class or not. This is equivalent to perform pairwise comparisons of the training datapoints, and thus, improves the generalization ability of the deep autoregressive model. Empirical experiments indicate that our proposed method has the potential to advance the state-of-the-art performance.
Quantization-Based Regularization for Autoencoders
May 27, 2019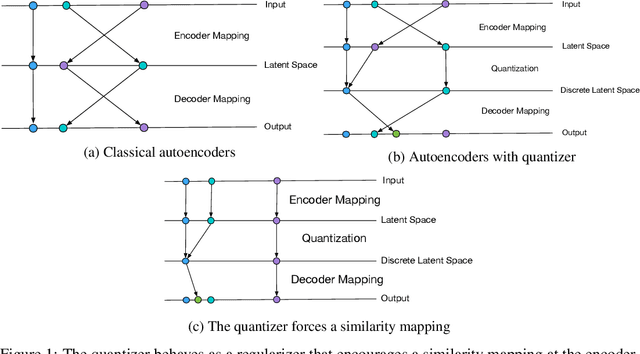
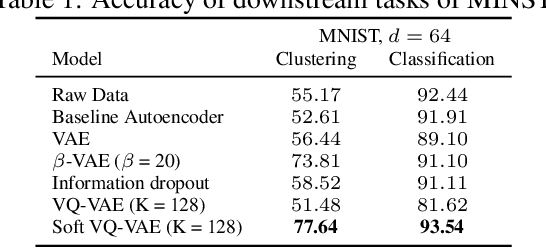
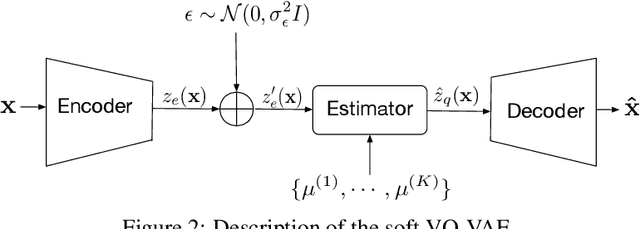
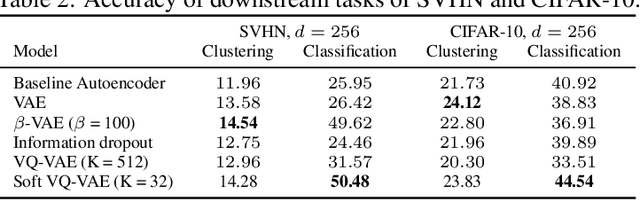
Autoencoders and their variations provide unsupervised models for learning low-dimensional representations for downstream tasks. Without proper regularization, autoencoder models are susceptible to the overfitting problem and the so-called posterior collapse phenomenon. In this paper, we introduce a quantization-based regularizer in the bottleneck stage of autoencoder models to learn meaningful latent representations. We combine both perspectives of Vector Quantized-Variational AutoEncoders (VQ-VAE) and classical denoising regularization schemes of neural networks. We interpret quantizers as regularizers that constrain latent representations while fostering a similarity mapping at the encoder. Before quantization, we impose noise on the latent variables and use a Bayesian estimator to optimize the quantizer-based representation. The introduced bottleneck Bayesian estimator outputs the posterior mean of the centroids to the decoder, and thus, is performing soft quantization of the latent variables. We show that our proposed regularization method results in improved latent representations for both supervised learning and clustering downstream tasks when compared to autoencoders using other bottleneck structures.
Variational Information Bottleneck on Vector Quantized Autoencoders
Aug 02, 2018In this paper, we provide an information-theoretic interpretation of the Vector Quantized-Variational Autoencoder (VQ-VAE). We show that the loss function of the original VQ-VAE can be derived from the variational deterministic information bottleneck (VDIB) principle. On the other hand, the VQ-VAE trained by the Expectation Maximization (EM) algorithm can be viewed as an approximation to the variational information bottleneck(VIB) principle.
Learning Product Codebooks using Vector Quantized Autoencoders for Image Retrieval
Jul 19, 2018
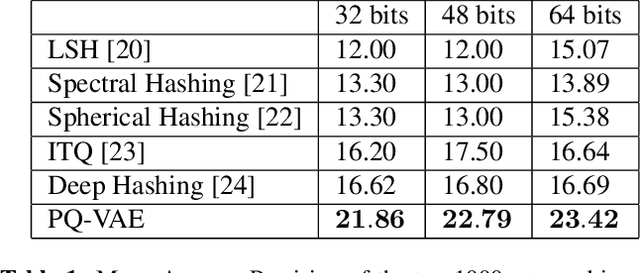
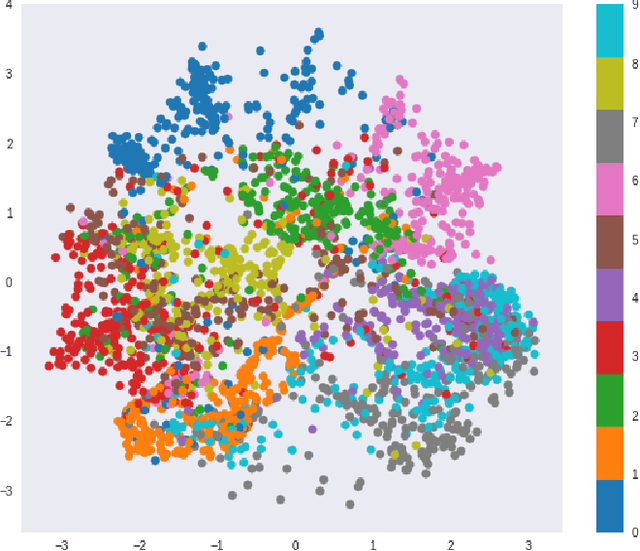
The Vector Quantized-Variational Autoencoder (VQ-VAE) [1] provides an unsupervised model for learning discrete representations by combining vector quantization and autoencoders. The VQ-VAE can avoid the issue of "posterior collapse" so that its learned discrete representation is meaningful. In this paper, we incorporate the product quantization into the bottleneck stage of VQ-VAE and propose an end-to-end unsupervised learning model for the image retrieval tasks. Compared to the classic vector quantization, product quantization has the advantage of generating large size codebook and fast retrieval can be achieved by using the lookup tables that store the distance between every two sub-codewords. In our proposed model, the product codebook is jointly learned with the encoders and decoders of the autoencoders. The encodings of query and database images can be generated by feeding the images into the trained encoder and learned product codebook. The experiment shows that our proposed model outperforms other state-of-the-art hashing and quantization methods for the image retrieval task.