 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AttnGrounder: Talking to Cars with Attention
Sep 11, 2020

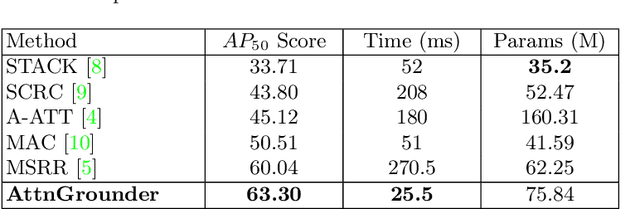
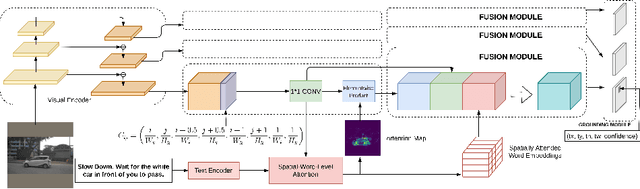
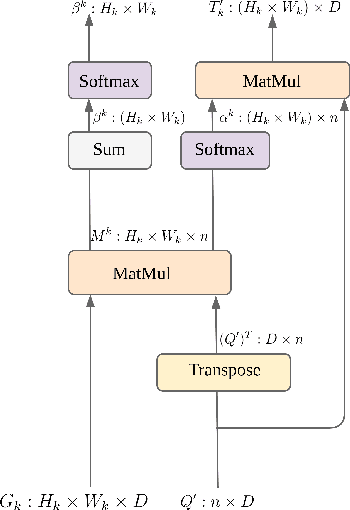
We propose Attention Grounder (AttnGrounder), a single-stage end-to-end trainable model for the task of visual grounding. Visual grounding aims to localize a specific object in an image based on a given natural language text query. Unlike previous methods that use the same text representation for every image region, we use a visual-text attention module that relates each word in the given query with every region in the corresponding image for constructing a region dependent text representation. Furthermore, for improving the localization ability of our model, we use our visual-text attention module to generate an attention mask around the referred object. The attention mask is trained as an auxiliary task using a rectangular mask generated with the provided ground-truth coordinates. We evaluate AttnGrounder on the Talk2Car dataset and show an improvement of 3.26% over the existing methods.
Learning to Create Better Ads: Generation and Ranking Approaches for Ad Creative Refinement
Aug 17, 2020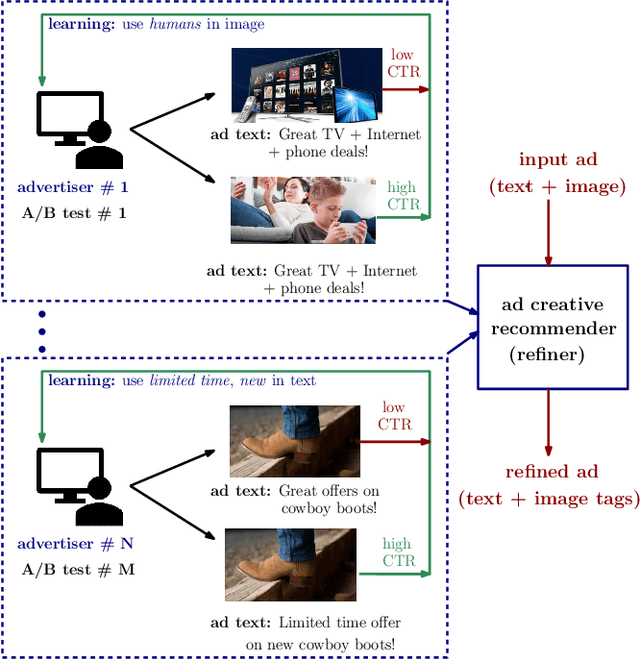
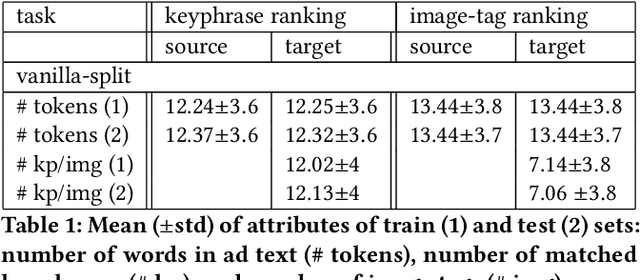
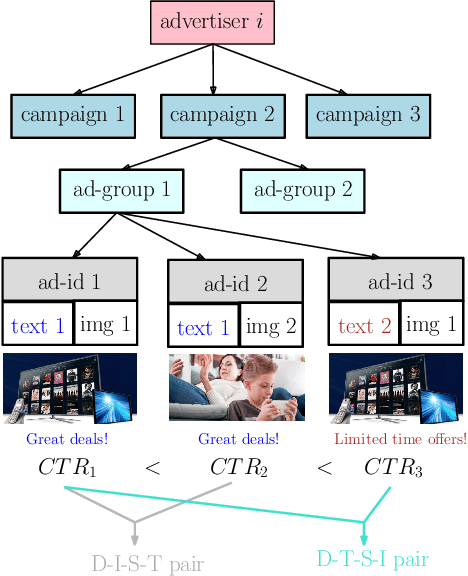
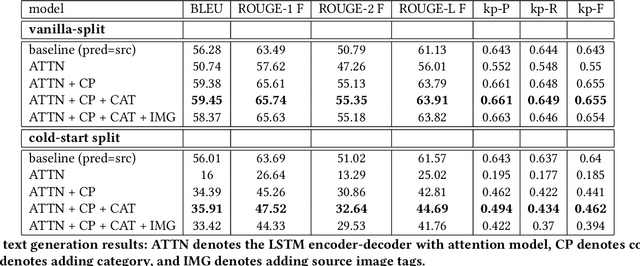
In the online advertising industry, the process of designing an ad creative (i.e., ad text and image) requires manual labor. Typically, each advertiser launches multiple creatives via online A/B tests to infer effective creatives for the target audience, that are then refined further in an iterative fashion. Due to the manual nature of this process, it is time-consuming to learn, refine, and deploy the modified creatives. Since major ad platforms typically run A/B tests for multiple advertisers in parallel, we explore the possibility of collaboratively learning ad creative refinement via A/B tests of multiple advertisers. In particular, given an input ad creative, we study approaches to refine the given ad text and image by: (i) generating new ad text, (ii) recommending keyphrases for new ad text, and (iii) recommending image tags (objects in image) to select new ad image. Based on A/B tests conducted by multiple advertisers, we form pairwise examples of inferior and superior ad creatives, and use such pairs to train models for the above tasks. For generating new ad text, we demonstrate the efficacy of an encoder-decoder architecture with copy mechanism, which allows some words from the (inferior) input text to be copied to the output while incorporating new words associated with higher click-through-rate. For the keyphrase and image tag recommendation task, we demonstrate the efficacy of a deep relevance matching model, as well as the relative robustness of ranking approaches compared to ad text generation in cold-start scenarios with unseen advertisers. We also share broadly applicable insights from our experiments using data from the Yahoo Gemini ad platform.
Graph Convolutional Networks for Model-Based Learning in Nonlinear Inverse Problems
Mar 28, 2021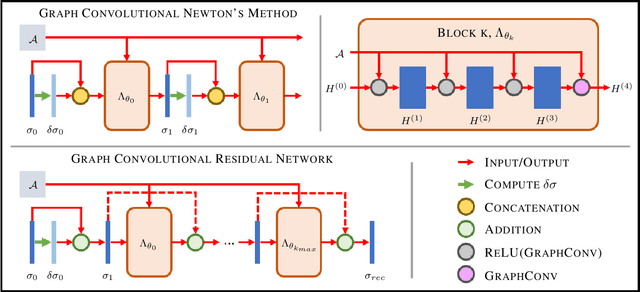

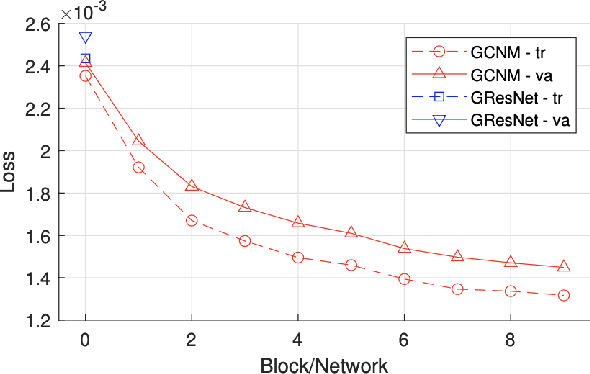
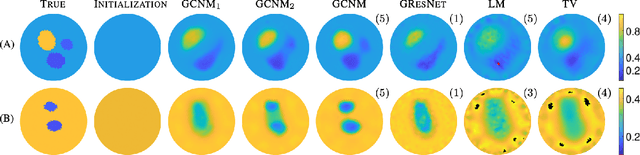
The majority of model-based learned image reconstruction methods in medical imaging have been limited to uniform domains, such as pixelated images. If the underlying model is solved on nonuniform meshes, arising from a finite element method typical for nonlinear inverse problems, interpolation and embeddings are needed. To overcome this, we present a flexible framework to extend model-based learning directly to nonuniform meshes, by interpreting the mesh as a graph and formulating our network architectures using graph convolutional neural networks. This gives rise to the proposed iterative Graph Convolutional Newton's Method (GCNM), which directly includes the forward model into the solution of the inverse problem, while all updates are directly computed by the network on the problem specific mesh. We present results for Electrical Impedance Tomography, a severely ill-posed nonlinear inverse problem that is frequently solved via optimization-based methods, where the forward problem is solved by finite element methods. Results for absolute EIT imaging are compared to standard iterative methods as well as a graph residual network. We show that the GCNM has strong generalizability to different domain shapes, out of distribution data as well as experimental data, from purely simulated training data.
HSI-CNN: A Novel Convolution Neural Network for Hyperspectral Image
Feb 28, 2018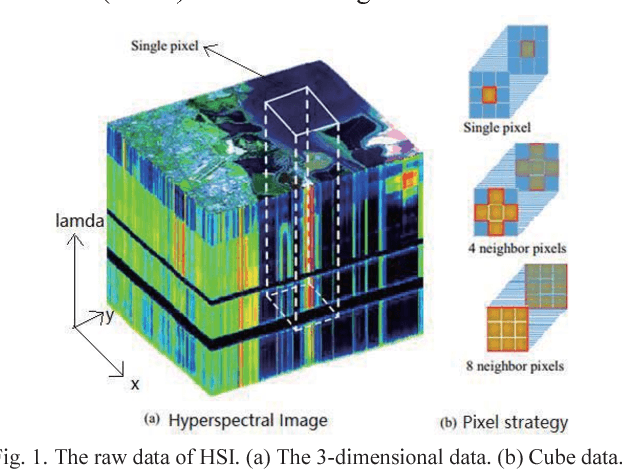
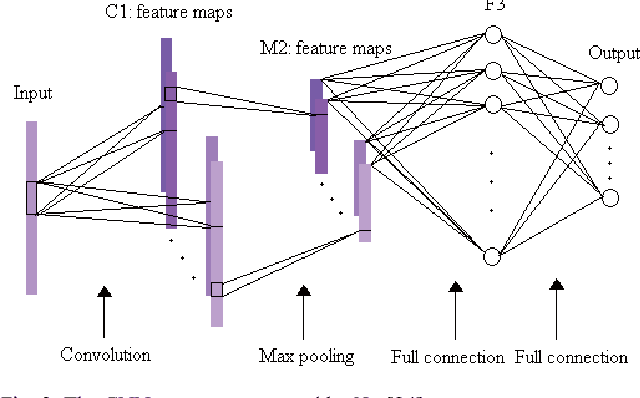
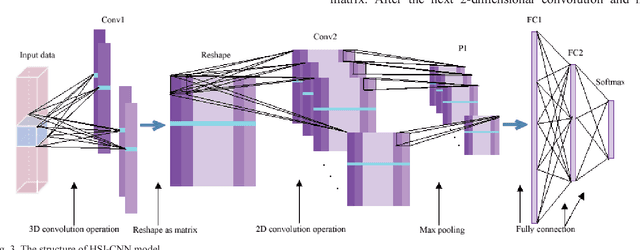

With the development of deep learning, the performance of hyperspectral image (HSI) classification has been greatly improved in recent years. The shortage of training samples has become a bottleneck for further improvement of performance. In this paper, we propose a novel convolutional neural network framework for the characteristics of hyperspectral image data, called HSI-CNN. Firstly, the spectral-spatial feature is extracted from a target pixel and its neighbors. Then, a number of one-dimensional feature maps, obtained by convolution operation on spectral-spatial features, are stacked into a two-dimensional matrix. Finally, the two-dimensional matrix considered as an image is fed into standard CNN. This is why we call it HSI-CNN. In addition, we also implements two depth network classification models, called HSI-CNN+XGBoost and HSI-CapsNet, in order to compare the performance of our framework. Experiments show that the performance of hyperspectral image classification is improved efficiently with HSI-CNN framework. We evaluate the model's performance using four popular HSI datasets, which are the Kennedy Space Center (KSC), Indian Pines (IP), Pavia University scene (PU) and Salinas scene (SA). As far as we concerned, HSI-CNN has got the state-of-art accuracy among all methods we have known on these datasets of 99.28%, 99.09%, 99.42%, 98.95% separately.
Understanding Image Virality
May 26, 2015
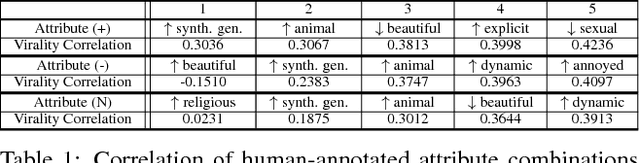
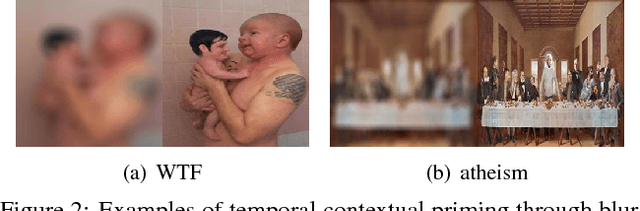
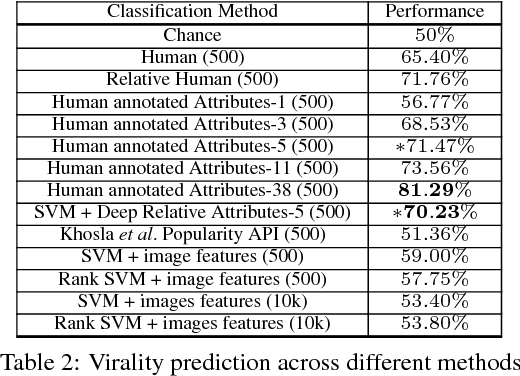
Virality of online content on social networking websites is an important but esoteric phenomenon often studied in fields like marketing, psychology and data mining. In this paper we study viral images from a computer vision perspective. We introduce three new image datasets from Reddit, and define a virality score using Reddit metadata. We train classifiers with state-of-the-art image features to predict virality of individual images, relative virality in pairs of images, and the dominant topic of a viral image. We also compare machine performance to human performance on these tasks. We find that computers perform poorly with low level features, and high level information is critical for predicting virality. We encode semantic information through relative attributes. We identify the 5 key visual attributes that correlate with virality. We create an attribute-based characterization of images that can predict relative virality with 68.10% accuracy (SVM+Deep Relative Attributes) -- better than humans at 60.12%. Finally, we study how human prediction of image virality varies with different `contexts' in which the images are viewed, such as the influence of neighbouring images, images recently viewed, as well as the image title or caption. This work is a first step in understanding the complex but important phenomenon of image virality. Our datasets and annotations will be made publicly available.
AMPA-Net: Optimization-Inspired Attention Neural Network for Deep Compressed Sensing
Oct 21, 2020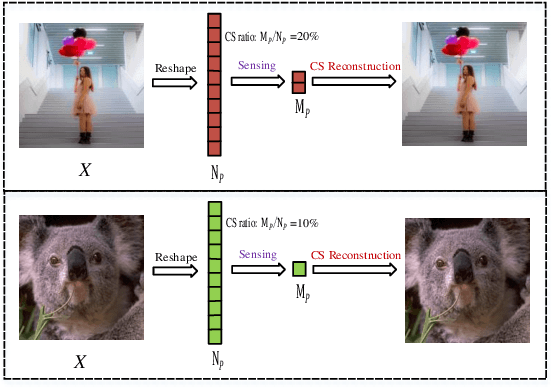
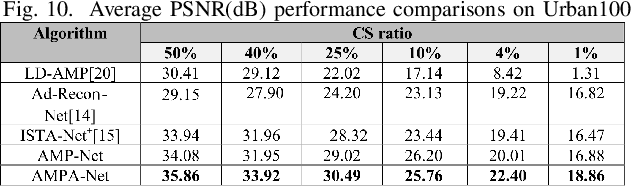
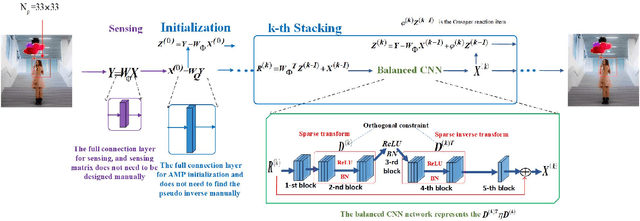
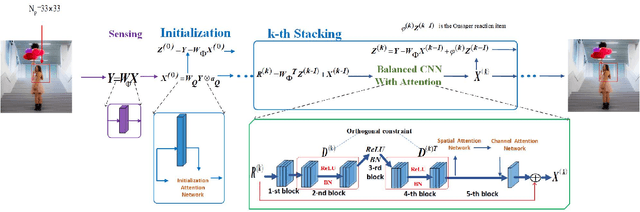
Compressed sensing (CS) is a challenging problem in image processing due to reconstructing an almost complete image from a limited measurement. To achieve fast and accurate CS reconstruction, we synthesize the advantages of two well-known methods (neural network and optimization algorithm) to propose a novel optimization inspired neural network which dubbed AMP-Net. AMP-Net realizes the fusion of the Approximate Message Passing (AMP) algorithm and neural network. All of its parameters are learned automatically. Furthermore, we propose an AMPA-Net which uses three attention networks to improve the representation ability of AMP-Net. Finally, We demonstrate the effectiveness of AMP-Net and AMPA-Net on four CS reconstruction benchmark data sets.
* 7 pages,7 figures
Deep Learning Body Region Classification of MRI and CT examinations
Apr 28, 2021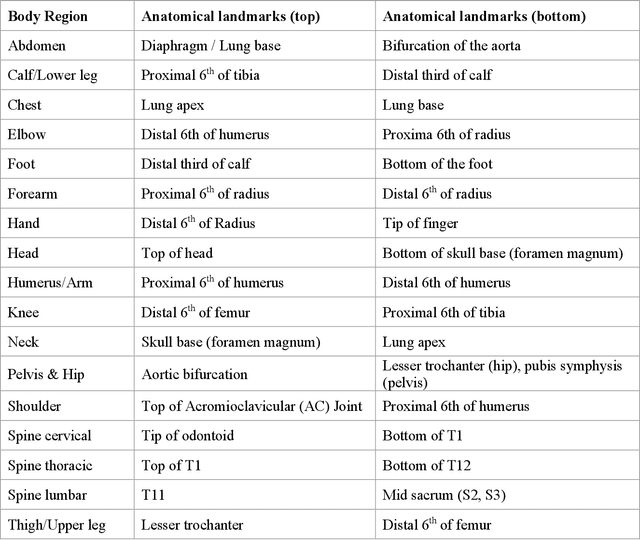
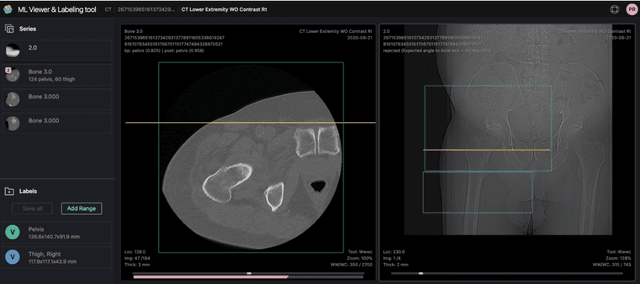
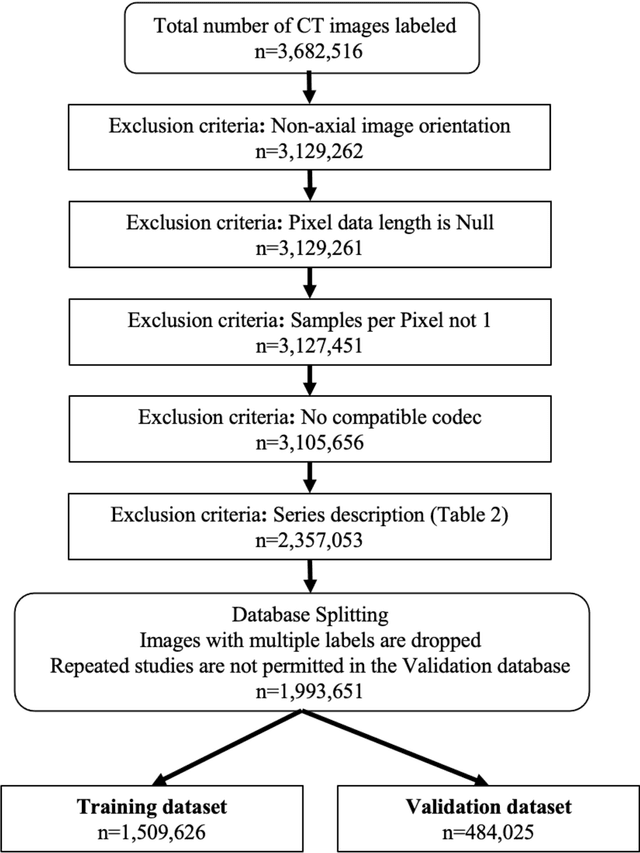

Standardized body region labelling of individual images provides data that can improve human and computer use of medical images. A CNN-based classifier was developed to identify body regions in CT and MRI. 17 CT (18 MRI) body regions covering the entire human body were defined for the classification task. Three retrospective databases were built for the AI model training, validation, and testing, with a balanced distribution of studies per body region. The test databases originated from a different healthcare network. Accuracy, recall and precision of the classifier was evaluated for patient age, patient gender, institution, scanner manufacturer, contrast, slice thickness, MRI sequence, and CT kernel. The data included a retrospective cohort of 2,934 anonymized CT cases (training: 1,804 studies, validation: 602 studies, test: 528 studies) and 3,185 anonymized MRI cases (training: 1,911 studies, validation: 636 studies, test: 638 studies). 27 institutions from primary care hospitals, community hospitals and imaging centers contributed to the test datasets. The data included cases of all genders in equal proportions and subjects aged from a few months old to +90 years old. An image-level prediction accuracy of 91.9% (90.2 - 92.1) for CT, and 94.2% (92.0 - 95.6) for MRI was achieved. The classification results were robust across all body regions and confounding factors. Due to limited data, performance results for subjects under 10 years-old could not be reliably evaluated. We show that deep learning models can classify CT and MRI images by body region including lower and upper extremities with high accuracy.
HandTailor: Towards High-Precision Monocular 3D Hand Recovery
Feb 18, 2021
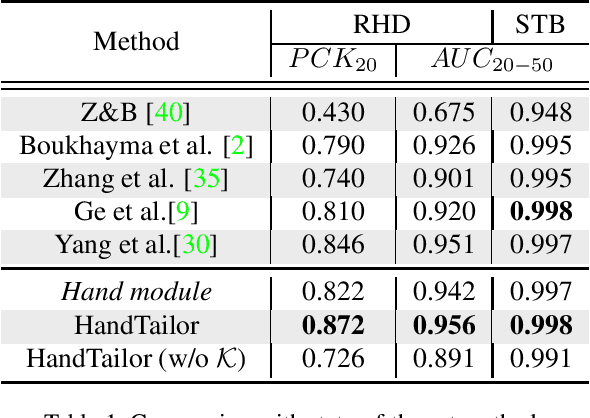
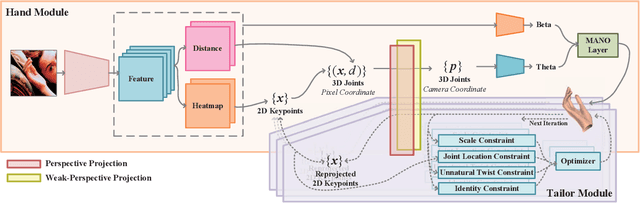
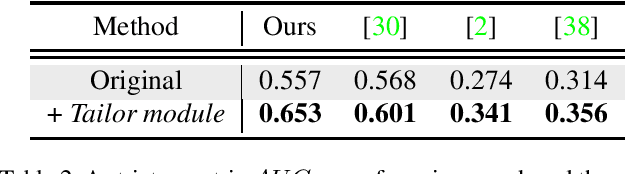
3D hand pose estimation and shape recovery are challenging tasks in computer vision. We introduce a novel framework HandTailor, which combines a learning-based hand module and an optimization-based tailor module to achieve high-precision hand mesh recovery from a monocular RGB image. The proposed hand module unifies perspective projection and weak perspective projection in a single network towards accuracy-oriented and in-the-wild scenarios. The proposed tailor module then utilizes the coarsely reconstructed mesh model provided by the hand module as initialization, and iteratively optimizes an energy function to obtain better results. The tailor module is time-efficient, costs only 8ms per frame on a modern CPU. We demonstrate that HandTailor can get state-of-the-art performance on several public benchmarks, with impressive qualitative results on in-the-wild experiments.
The Low-Rank Simplicity Bias in Deep Networks
Mar 18, 2021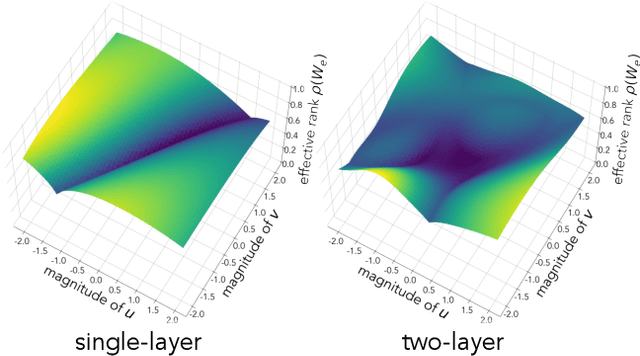
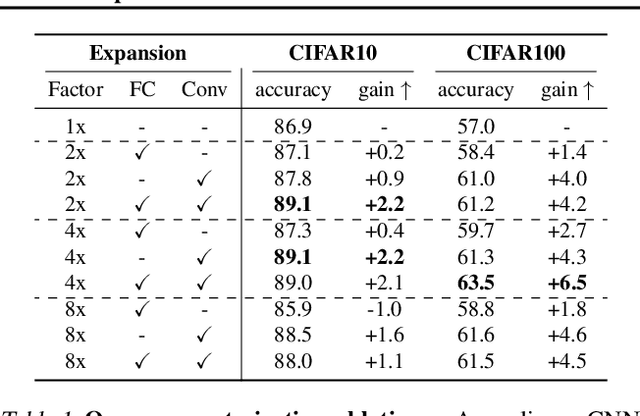
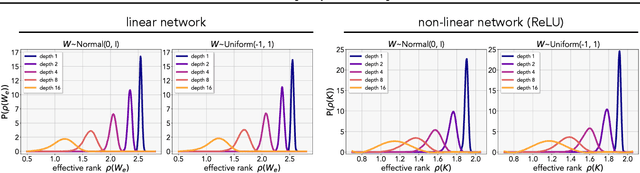
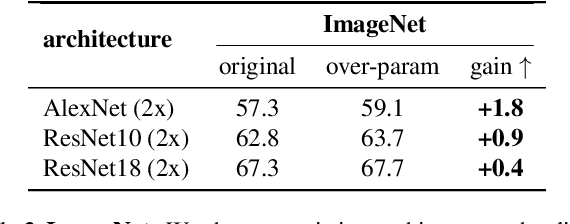
Modern deep neural networks are highly over-parameterized compared to the data on which they are trained, yet they often generalize remarkably well. A flurry of recent work has asked: why do deep networks not overfit to their training data? We investigate the hypothesis that deeper nets are implicitly biased to find lower rank solutions and that these are the solutions that generalize well. We prove for the asymptotic case that the percent volume of low effective-rank solutions increases monotonically as linear neural networks are made deeper. We then show empirically that our claim holds true on finite width models. We further empirically find that a similar result holds for non-linear networks: deeper non-linear networks learn a feature space whose kernel has a lower rank. We further demonstrate how linear over-parameterization of deep non-linear models can be used to induce low-rank bias, improving generalization performance without changing the effective model capacity. We evaluate on various model architectures and demonstrate that linearly over-parameterized models outperform existing baselines on image classification tasks, including ImageNet.
Multi-Scale Context Aggregation Network with Attention-Guided for Crowd Counting
Apr 06, 2021
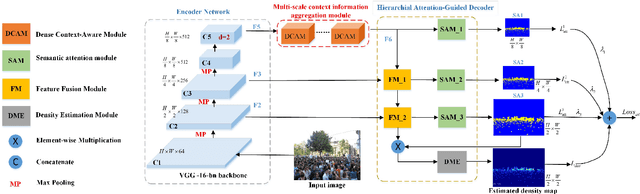
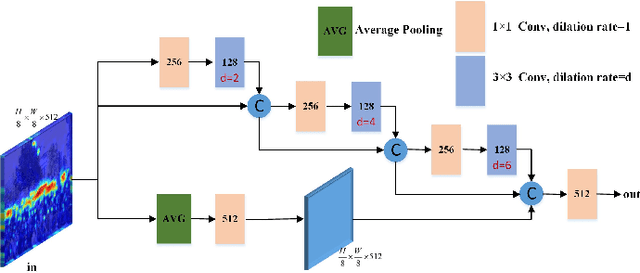
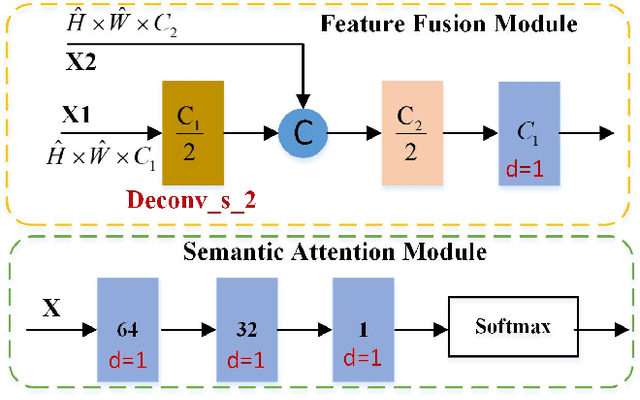
Crowd counting aims to predict the number of people and generate the density map in the image. There are many challenges, including varying head scales, the diversity of crowd distribution across images and cluttered backgrounds. In this paper, we propose a multi-scale context aggregation network (MSCANet) based on single-column encoder-decoder architecture for crowd counting, which consists of an encoder based on a dense context-aware module (DCAM) and a hierarchical attention-guided decoder. To handle the issue of scale variation, we construct the DCAM to aggregate multi-scale contextual information by densely connecting the dilated convolution with varying receptive fields. The proposed DCAM can capture rich contextual information of crowd areas due to its long-range receptive fields and dense scale sampling. Moreover, to suppress the background noise and generate a high-quality density map, we adopt a hierarchical attention-guided mechanism in the decoder. This helps to integrate more useful spatial information from shallow feature maps of the encoder by introducing multiple supervision based on semantic attention module (SAM). Extensive experiments demonstrate that the proposed approach achieves better performance than other similar state-of-the-art methods on three challenging benchmark datasets for crowd counting. The code is available at https://github.com/KingMV/MSCANet