 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Guided Electron Microscopy with Active Acquisition
Jan 07, 2021
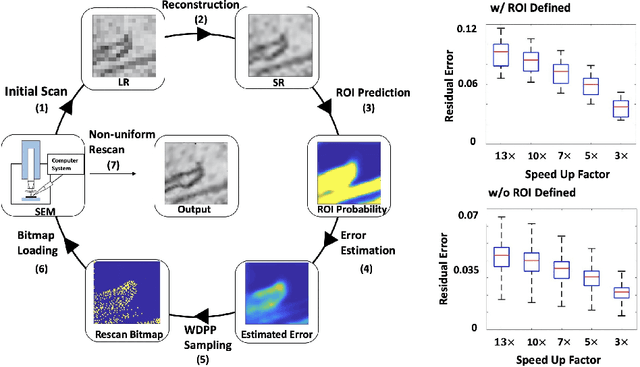
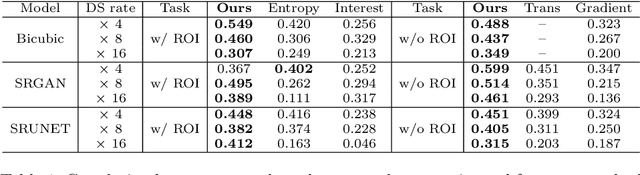
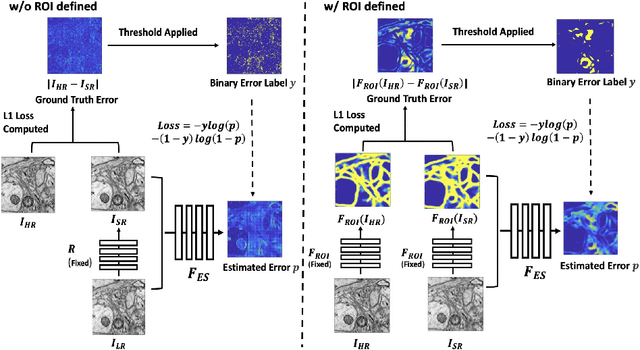
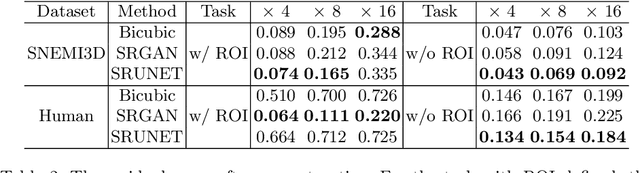
Single-beam scanning electron microscopes (SEM) are widely used to acquire massive data sets for biomedical study, material analysis, and fabrication inspection. Datasets are typically acquired with uniform acquisition: applying the electron beam with the same power and duration to all image pixels, even if there is great variety in the pixels' importance for eventual use. Many SEMs are now able to move the beam to any pixel in the field of view without delay, enabling them, in principle, to invest their time budget more effectively with non-uniform imaging. In this paper, we show how to use deep learning to accelerate and optimize single-beam SEM acquisition of images. Our algorithm rapidly collects an information-lossy image (e.g. low resolution) and then applies a novel learning method to identify a small subset of pixels to be collected at higher resolution based on a trade-off between the saliency and spatial diversity. We demonstrate the efficacy of this novel technique for active acquisition by speeding up the task of collecting connectomic datasets for neurobiology by up to an order of magnitude.
Spatio-Contextual Deep Network Based Multimodal Pedestrian Detection For Autonomous Driving
May 26, 2021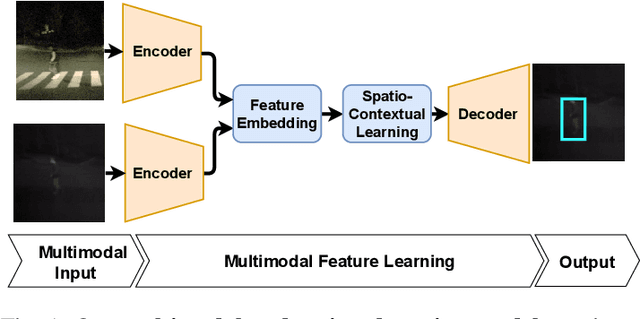
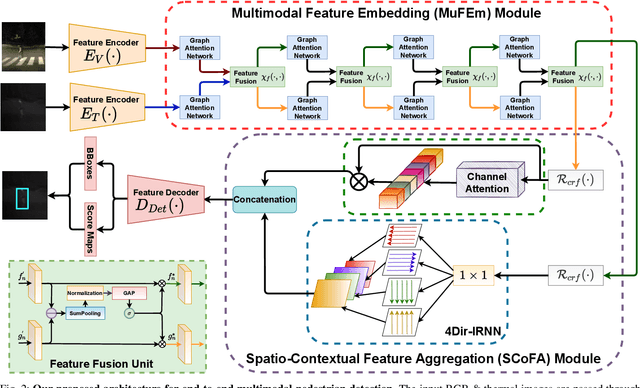


Pedestrian Detection is the most critical module of an Autonomous Driving system. Although a camera is commonly used for this purpose, its quality degrades severely in low-light night time driving scenarios. On the other hand, the quality of a thermal camera image remains unaffected in similar conditions. This paper proposes an end-to-end multimodal fusion model for pedestrian detection using RGB and thermal images. Its novel spatio-contextual deep network architecture is capable of exploiting the multimodal input efficiently. It consists of two distinct deformable ResNeXt-50 encoders for feature extraction from the two modalities. Fusion of these two encoded features takes place inside a multimodal feature embedding module (MuFEm) consisting of several groups of a pair of Graph Attention Network and a feature fusion unit. The output of the last feature fusion unit of MuFEm is subsequently passed to two CRFs for their spatial refinement. Further enhancement of the features is achieved by applying channel-wise attention and extraction of contextual information with the help of four RNNs traversing in four different directions. Finally, these feature maps are used by a single-stage decoder to generate the bounding box of each pedestrian and the score map. We have performed extensive experiments of the proposed framework on three publicly available multimodal pedestrian detection benchmark datasets, namely KAIST, CVC-14, and UTokyo. The results on each of them improved the respective state-of-the-art performance. A short video giving an overview of this work along with its qualitative results can be seen at https://youtu.be/FDJdSifuuCs.
RoBIC: A benchmark suite for assessing classifiers robustness
Feb 10, 2021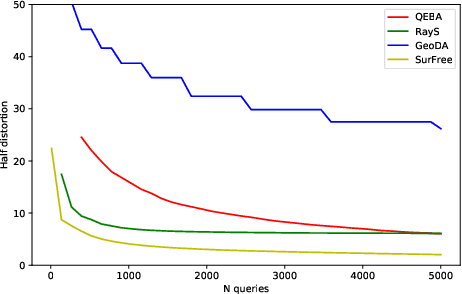
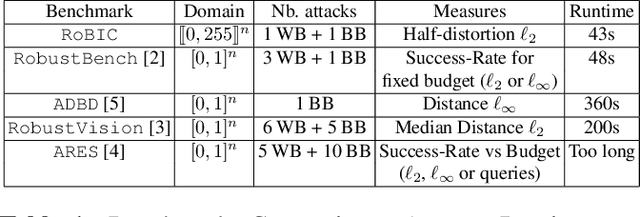
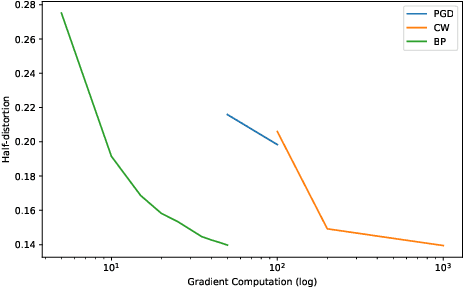
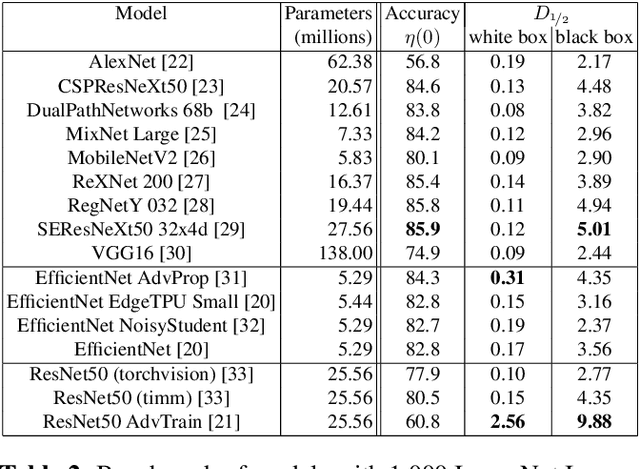
Many defenses have emerged with the development of adversarial attacks. Models must be objectively evaluated accordingly. This paper systematically tackles this concern by proposing a new parameter-free benchmark we coin RoBIC. RoBIC fairly evaluates the robustness of image classifiers using a new half-distortion measure. It gauges the robustness of the network against white and black box attacks, independently of its accuracy. RoBIC is faster than the other available benchmarks. We present the significant differences in the robustness of 16 recent models as assessed by RoBIC.
Balancing Constraints and Submodularity in Data Subset Selection
Apr 26, 2021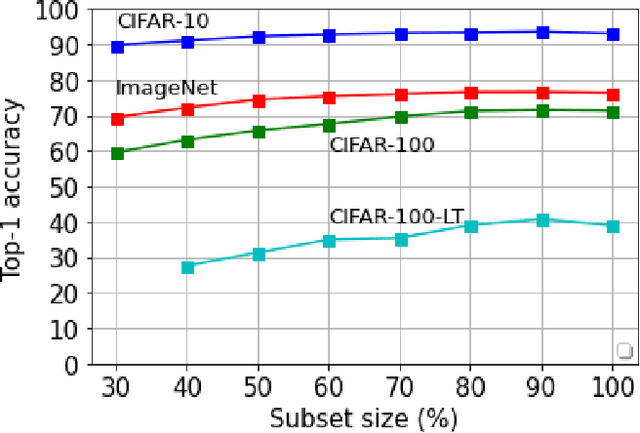
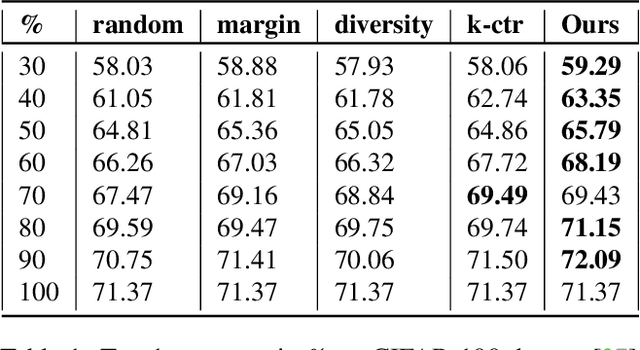
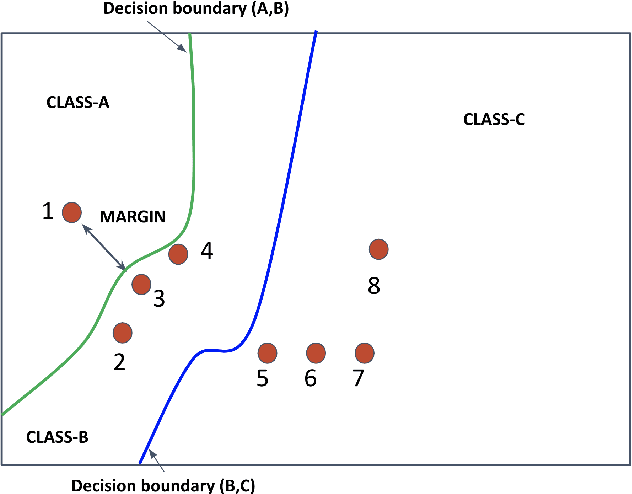
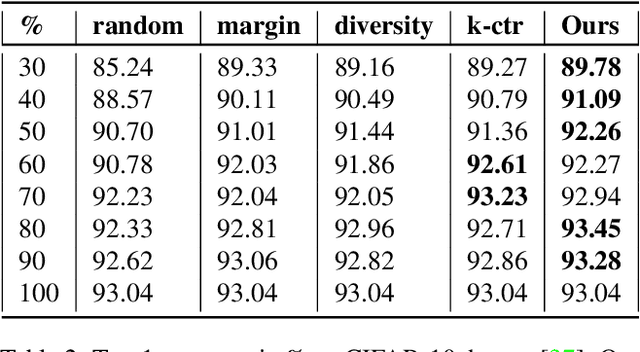
Deep learning has yielded extraordinary results in vision and natural language processing, but this achievement comes at a cost. Most deep learning models require enormous resources during training, both in terms of computation and in human labeling effort. In this paper, we show that one can achieve similar accuracy to traditional deep-learning models, while using less training data. Much of the previous work in this area relies on using uncertainty or some form of diversity to select subsets of a larger training set. Submodularity, a discrete analogue of convexity, has been exploited to model diversity in various settings including data subset selection. In contrast to prior methods, we propose a novel diversity driven objective function, and balancing constraints on class labels and decision boundaries using matroids. This allows us to use efficient greedy algorithms with approximation guarantees for subset selection. We outperform baselines on standard image classification datasets such as CIFAR-10, CIFAR-100, and ImageNet. In addition, we also show that the proposed balancing constraints can play a key role in boosting the performance in long-tailed datasets such as CIFAR-100-LT.
A CNN-RNN Framework with a Novel Patch-Based Multi-Attention Mechanism for Multi-Label Image Classification in Remote Sensing
Mar 22, 2019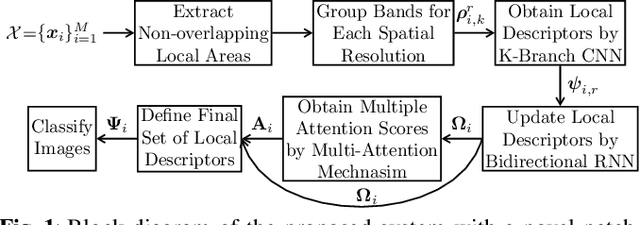
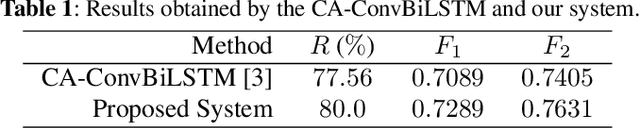
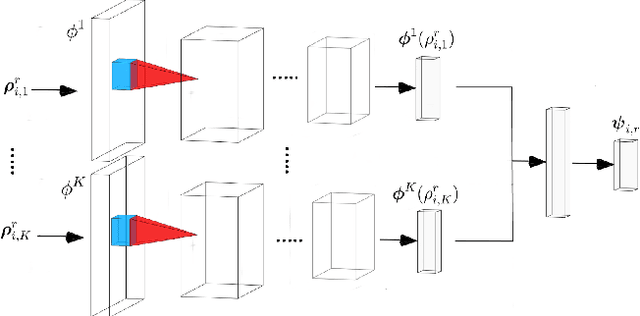
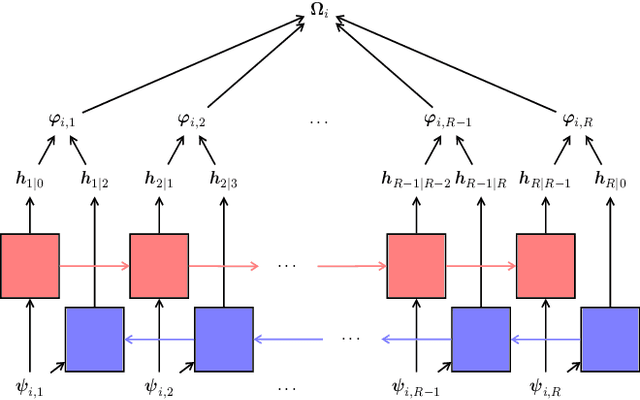
This paper presents a novel framework that jointly exploits Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) in the context of multi-label remote sensing (RS) image classification. The proposed framework consists of four main modules. The first module aims to extract preliminary local descriptors by considering that RS image bands can be associated with different spatial resolutions. To this end, we introduce a K-Branch CNN in which each branch aims at extracting descriptors of image bands that have the same spatial resolution. The second module aims to model spatial relationship among local descriptors. To this end, we propose a Bidirectional RNN architecture in which Long Short-Term Memory nodes enrich local descriptors by considering spatial relationships of local areas (image patches). The third module aims to define multiple attention scores for local descriptors. To this end, we introduce a novel patch-based multi-attention mechanism that takes into account the joint occurrence of multiple land-cover classes and provides the attention-based local descriptors. The last module aims to employ these descriptors for multi-label RS image classification. Experimental results obtained on the BigEarthNet that is a large-scale Sentinel-2 benchmark archive show the effectiveness of the proposed framework compared to a state of the art method.
Webly Supervised Joint Embedding for Cross-Modal Image-Text Retrieval
Aug 23, 2018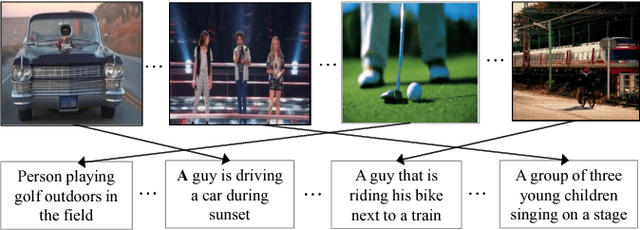
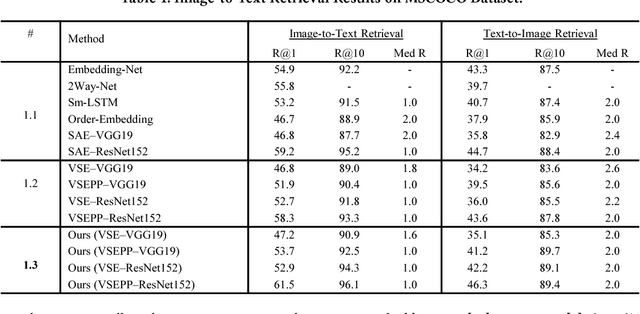
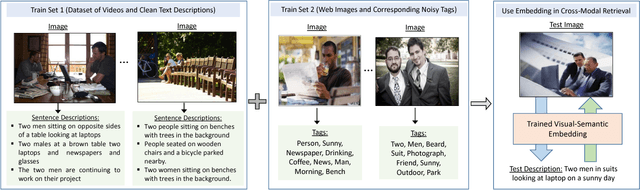
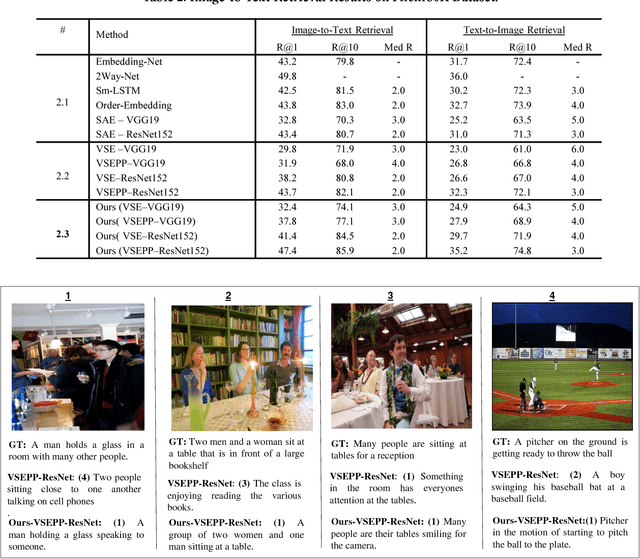
Cross-modal retrieval between visual data and natural language description remains a long-standing challenge in multimedia. While recent image-text retrieval methods offer great promise by learning deep representations aligned across modalities, most of these methods are plagued by the issue of training with small-scale datasets covering a limited number of images with ground-truth sentences. Moreover, it is extremely expensive to create a larger dataset by annotating millions of images with sentences and may lead to a biased model. Inspired by the recent success of webly supervised learning in deep neural networks, we capitalize on readily-available web images with noisy annotations to learn robust image-text joint representation. Specifically, our main idea is to leverage web images and corresponding tags, along with fully annotated datasets, in training for learning the visual-semantic joint embedding. We propose a two-stage approach for the task that can augment a typical supervised pair-wise ranking loss based formulation with weakly-annotated web images to learn a more robust visual-semantic embedding. Experiments on two standard benchmark datasets demonstrate that our method achieves a significant performance gain in image-text retrieval compared to state-of-the-art approaches.
GUIGAN: Learning to Generate GUI Designs Using Generative Adversarial Networks
Jan 27, 2021
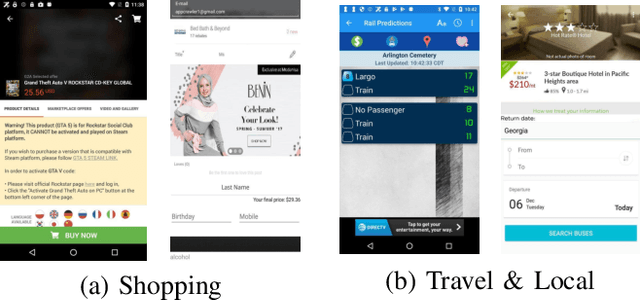
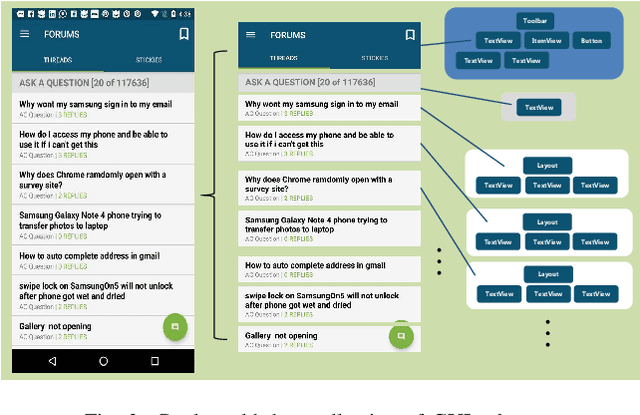
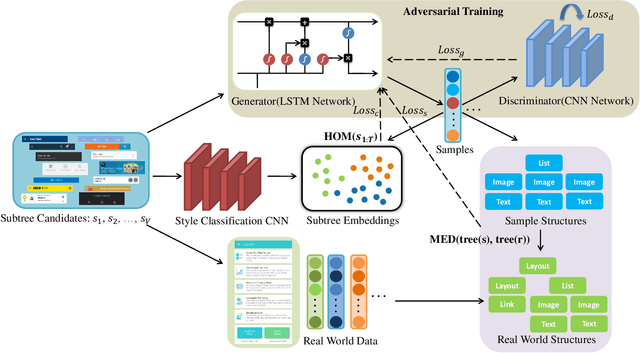
Graphical User Interface (GUI) is ubiquitous in almost all modern desktop software, mobile applications, and online websites. A good GUI design is crucial to the success of the software in the market, but designing a good GUI which requires much innovation and creativity is difficult even to well-trained designers. Besides, the requirement of the rapid development of GUI design also aggravates designers' working load. So, the availability of various automated generated GUIs can help enhance the design personalization and specialization as they can cater to the taste of different designers. To assist designers, we develop a model GUIGAN to automatically generate GUI designs. Different from conventional image generation models based on image pixels, our GUIGAN is to reuse GUI components collected from existing mobile app GUIs for composing a new design that is similar to natural-language generation. Our GUIGAN is based on SeqGAN by modeling the GUI component style compatibility and GUI structure. The evaluation demonstrates that our model significantly outperforms the best of the baseline methods by 30.77% in Frechet Inception distance (FID) and 12.35% in 1-Nearest Neighbor Accuracy (1-NNA). Through a pilot user study, we provide initial evidence of the usefulness of our approach for generating acceptable brand new GUI designs.
Slower is Better: Revisiting the Forgetting Mechanism in LSTM for Slower Information Decay
May 12, 2021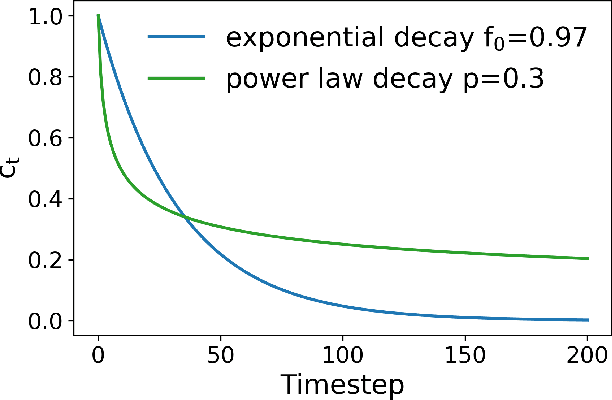
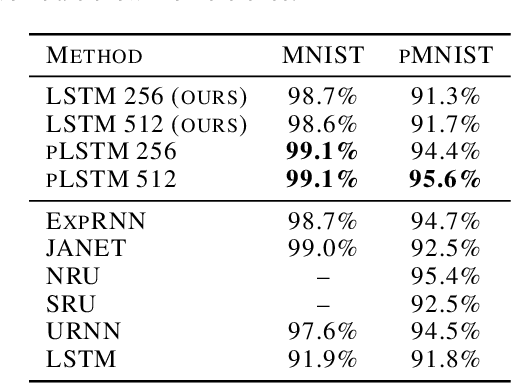
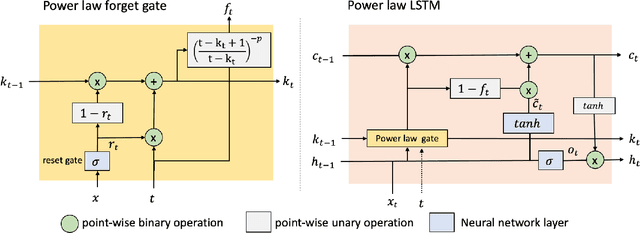
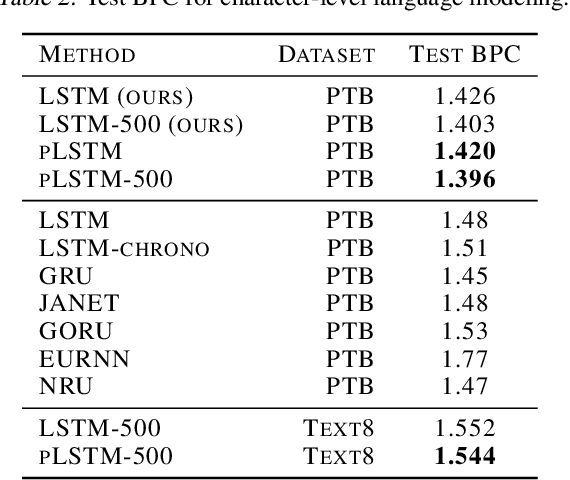
Sequential information contains short- to long-range dependencies; however, learning long-timescale information has been a challenge for recurrent neural networks. Despite improvements in long short-term memory networks (LSTMs), the forgetting mechanism results in the exponential decay of information, limiting their capacity to capture long-timescale information. Here, we propose a power law forget gate, which instead learns to forget information along a slower power law decay function. Specifically, the new gate learns to control the power law decay factor, p, allowing the network to adjust the information decay rate according to task demands. Our experiments show that an LSTM with power law forget gates (pLSTM) can effectively capture long-range dependencies beyond hundreds of elements on image classification, language modeling, and categorization tasks, improving performance over the vanilla LSTM. We also inspected the revised forget gate by varying the initialization of p, setting p to a fixed value, and ablating cells in the pLSTM network. The results show that the information decay can be controlled by the learnable decay factor p, which allows pLSTM to achieve its superior performance. Altogether, we found that LSTM with the proposed forget gate can learn long-term dependencies, outperforming other recurrent networks in multiple domains; such gating mechanism can be integrated into other architectures for improving the learning of long timescale information in recurrent neural networks.
Scale-Invariant Structure Saliency Selection for Fast Image Fusion
Oct 30, 2018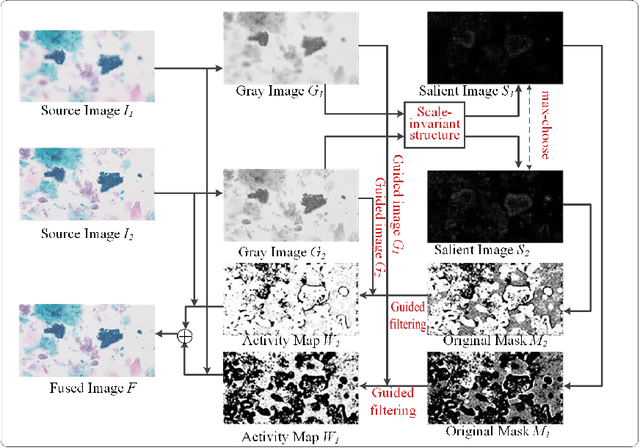
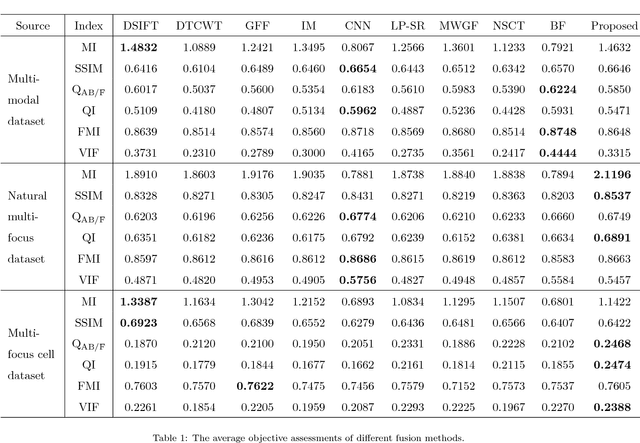
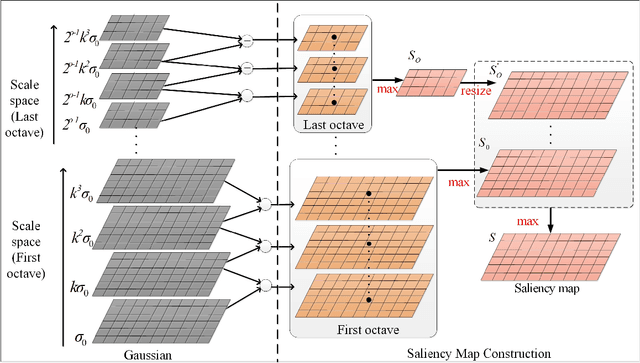

In this paper, we present a fast yet effective method for pixel-level scale-invariant image fusion in spatial domain based on the scale-space theory. Specifically, we propose a scale-invariant structure saliency selection scheme based on the difference-of-Gaussian (DoG) pyramid of images to build the weights or activity map. Due to the scale-invariant structure saliency selection, our method can keep both details of small size objects and the integrity information of large size objects in images. In addition, our method is very efficient since there are no complex operation involved and easy to be implemented and therefore can be used for fast high resolution images fusion. Experimental results demonstrate the proposed method yields competitive or even better results comparing to state-of-the-art image fusion methods both in terms of visual quality and objective evaluation metrics. Furthermore, the proposed method is very fast and can be used to fuse the high resolution images in real-time. Code is available at https://github.com/yiqingmy/Fusion.
Snowy Night-to-Day Translator and Semantic Segmentation Label Similarity for Snow Hazard Indicator
Feb 28, 2021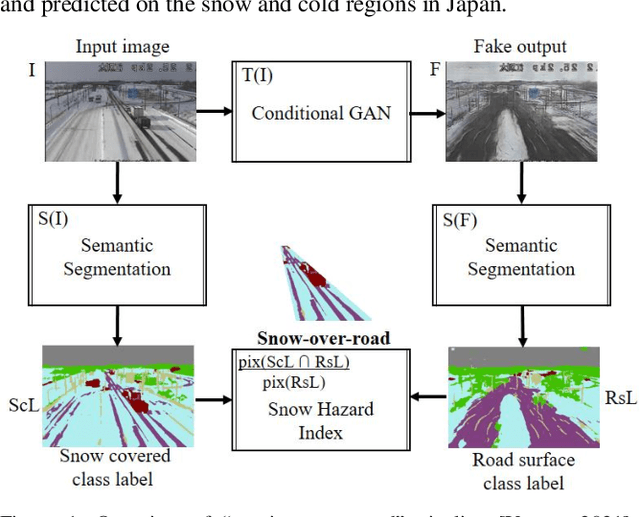
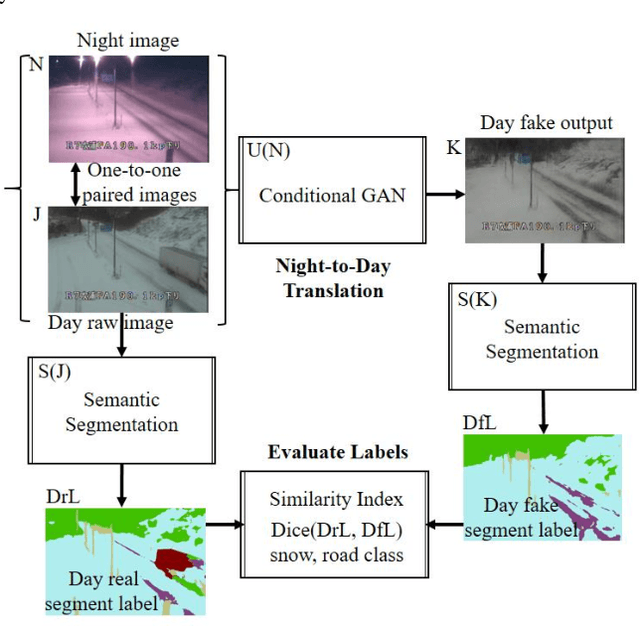


In 2021, Japan recorded more than three times as much snowfall as usual, so road user maybe come across dangerous situation. The poor visibility caused by snow triggers traffic accidents. For example, 2021 January 19, due to the dry snow and the strong wind speed of 27 m / s, blizzards occurred and the outlook has been ineffective. Because of the whiteout phenomenon, multiple accidents with 17 casualties occurred, and 134 vehicles were stacked up for 10 hours over 1 km. At the night time zone, the temperature drops and the road surface tends to freeze. CCTV images on the road surface have the advantage that we enable to monitor the status of major points at the same time. Road managers are required to make decisions on road closures and snow removal work owing to the road surface conditions even at night. In parallel, they would provide road users to alert for hazardous road surfaces. This paper propose a method to automate a snow hazard indicator that the road surface region is generated from the night snow image using the Conditional GAN, pix2pix. In addition, the road surface and the snow covered ROI are predicted using the semantic segmentation DeepLabv3+ with a backbone MobileNet, and the snow hazard indicator to automatically compute how much the night road surface is covered with snow. We demonstrate several results applied to the cold and snow region in the winter of Japan January 19 to 21 2021, and mention the usefulness of high similarity between snowy night-to-day fake output and real snowy day image for night snow visibility.