 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery
May 28, 2021
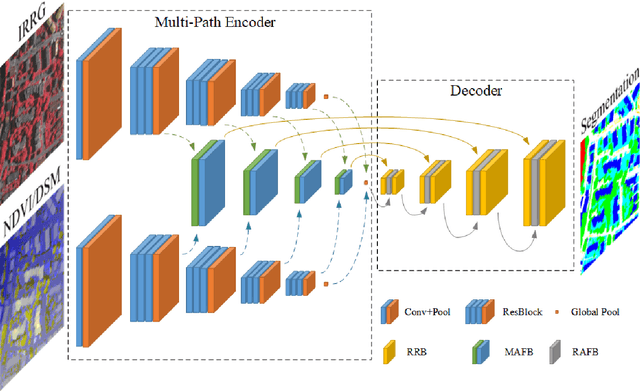
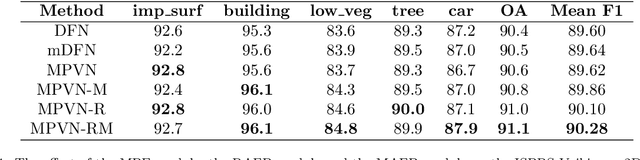
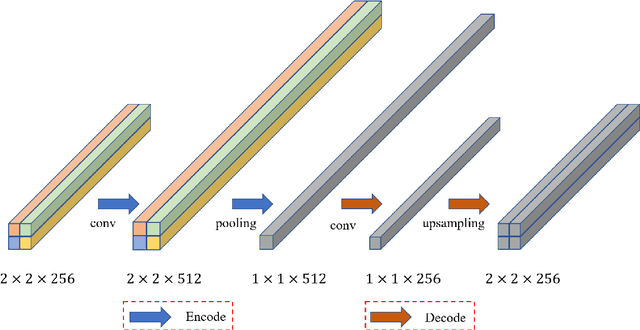
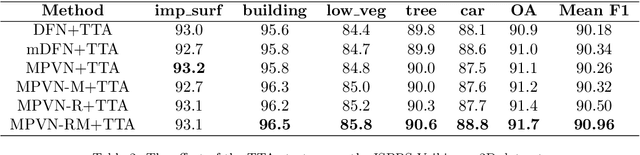
Semantic segmentation is an essential part of deep learning. In recent years, with the development of remote sensing big data, semantic segmentation has been increasingly used in remote sensing. Deep convolutional neural networks (DCNNs) face the challenge of feature fusion: very-high-resolution remote sensing image multisource data fusion can increase the network's learnable information, which is conducive to correctly classifying target objects by DCNNs; simultaneously, the fusion of high-level abstract features and low-level spatial features can improve the classification accuracy at the border between target objects. In this paper, we propose a multipath encoder structure to extract features of multipath inputs, a multipath attention-fused block module to fuse multipath features, and a refinement attention-fused block module to fuse high-level abstract features and low-level spatial features. Furthermore, we propose a novel convolutional neural network architecture, named attention-fused network (AFNet). Based on our AFNet, we achieve state-of-the-art performance with an overall accuracy of 91.7% and a mean F1 score of 90.96% on the ISPRS Vaihingen 2D dataset and an overall accuracy of 92.1% and a mean F1 score of 93.44% on the ISPRS Potsdam 2D dataset.
* 35 pages. Published by ISPRS Journal of Photogrammetry and Remote Sensing
Bias-Free FedGAN
Mar 17, 2021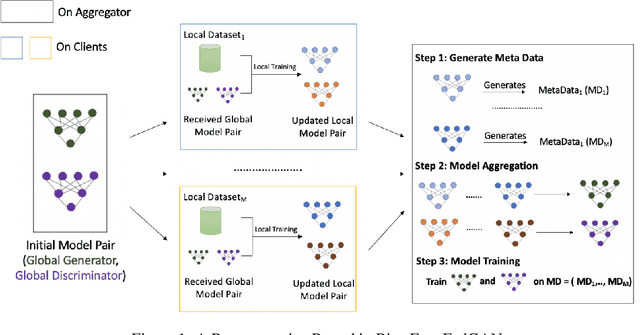

Federated Generative Adversarial Network (FedGAN) is a communication-efficient approach to train a GAN across distributed clients without clients having to share their sensitive training data. In this paper, we experimentally show that FedGAN generates biased data points under non-independent-and-identically-distributed (non-iid) settings. Also, we propose Bias-Free FedGAN, an approach to generate bias-free synthetic datasets using FedGAN. Bias-Free FedGAN has the same communication cost as that of FedGAN. Experimental results on image datasets (MNIST and FashionMNIST) validate our claims.
Image-based model parameter optimisation using Model-Assisted Generative Adversarial Networks
Nov 30, 2018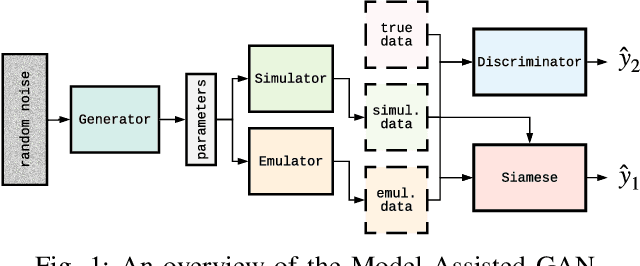
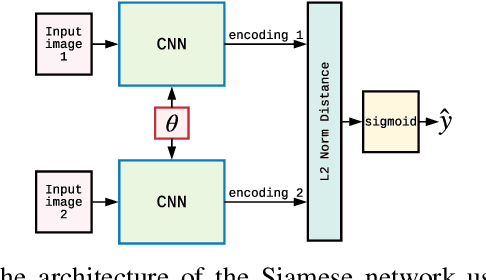
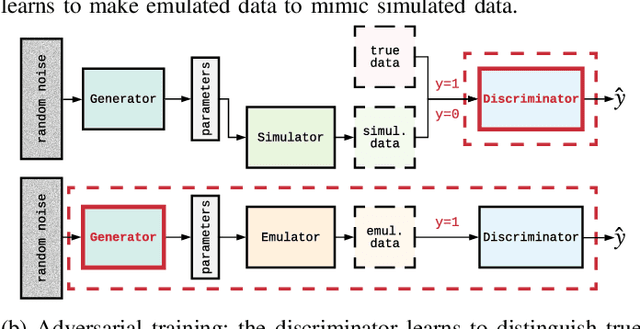
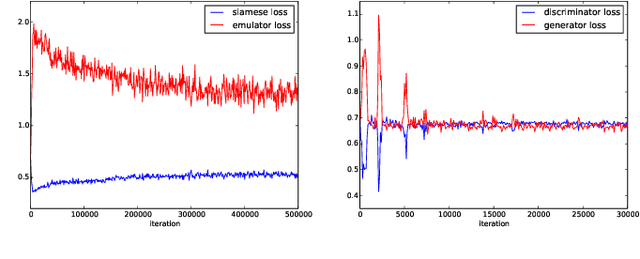
We propose and demonstrate the use of a Model-Assisted Generative Adversarial Network to produce simulated images that accurately match true images through the variation of underlying model parameters that describe the image generation process. The generator learns the parameter values that give images that best match the true images. Two case studies show the excellent agreement between the generated best match parameters and the true parameters. The best match parameter values that produce the most accurate simulated images can be extracted and used to re-tune the default simulation to minimise any bias when applying image recognition techniques to simulated and true images. In the case of a real-world experiment, the true data is replaced by experimental data with unknown true parameter values. The Model-Assisted Generative Adversarial Network uses a convolutional neural network to emulate the simulation for all parameter values that, when trained, can be used as a conditional generator for fast image production.
Image Super-Resolution using Explicit Perceptual Loss
Sep 01, 2020
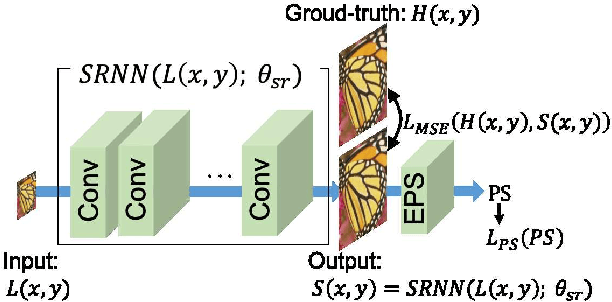

This paper proposes an explicit way to optimize the super-resolution network for generating visually pleasing images. The previous approaches use several loss functions which is hard to interpret and has the implicit relationships to improve the perceptual score. We show how to exploit the machine learning based model which is directly trained to provide the perceptual score on generated images. It is believed that these models can be used to optimizes the super-resolution network which is easier to interpret. We further analyze the characteristic of the existing loss and our proposed explicit perceptual loss for better interpretation. The experimental results show the explicit approach has a higher perceptual score than other approaches. Finally, we demonstrate the relation of explicit perceptual loss and visually pleasing images using subjective evaluation.
Black-box Adversarial Attacks on Monocular Depth Estimation Using Evolutionary Multi-objective Optimization
Dec 29, 2020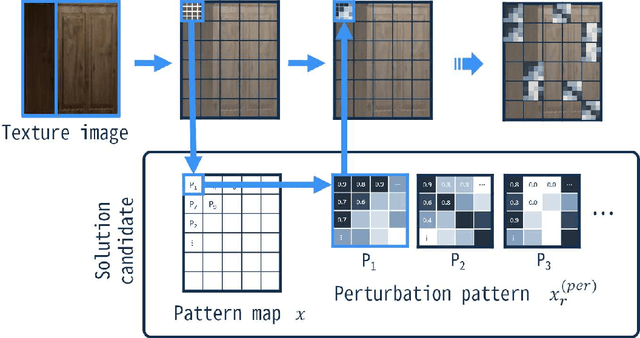

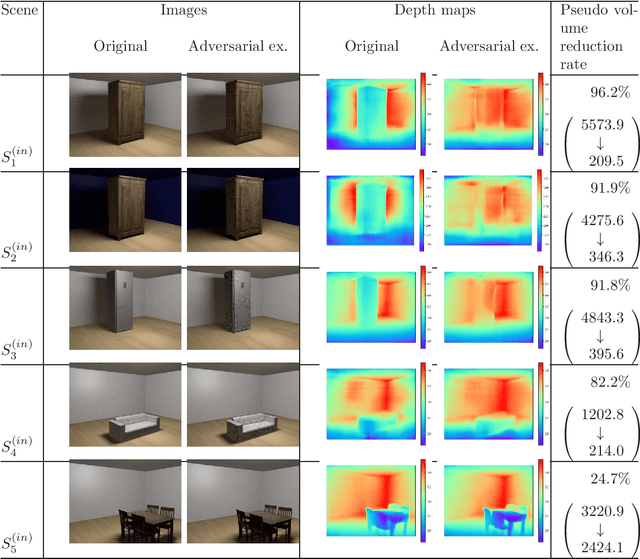
This paper proposes an adversarial attack method to deep neural networks (DNNs) for monocular depth estimation, i.e., estimating the depth from a single image. Single image depth estimation has improved drastically in recent years due to the development of DNNs. However, vulnerabilities of DNNs for image classification have been revealed by adversarial attacks, and DNNs for monocular depth estimation could contain similar vulnerabilities. Therefore, research on vulnerabilities of DNNs for monocular depth estimation has spread rapidly, but many of them assume white-box conditions where inside information of DNNs is available, or are transferability-based black-box attacks that require a substitute DNN model and a training dataset. Utilizing Evolutionary Multi-objective Optimization, the proposed method in this paper analyzes DNNs under the black-box condition where only output depth maps are available. In addition, the proposed method does not require a substitute DNN that has a similar architecture to the target DNN nor any knowledge about training data used to train the target model. Experimental results showed that the proposed method succeeded in attacking two DNN-based methods that were trained with indoor and outdoor scenes respectively.
FReTAL: Generalizing Deepfake Detection using Knowledge Distillation and Representation Learning
May 28, 2021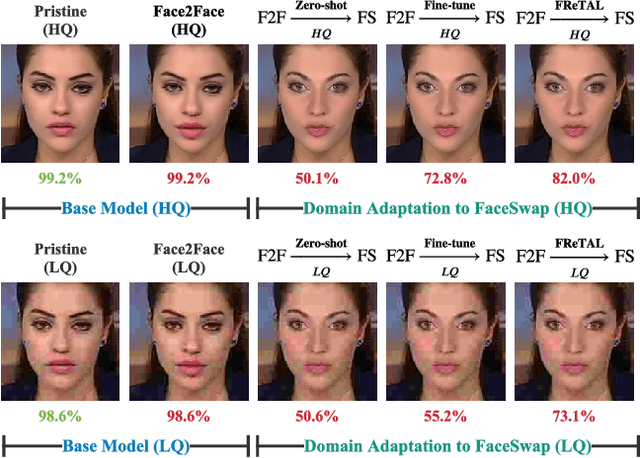
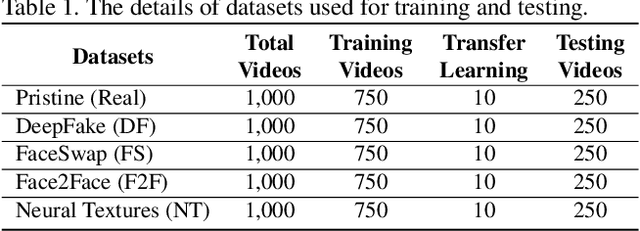
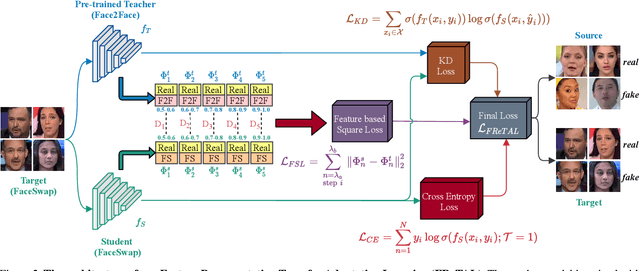
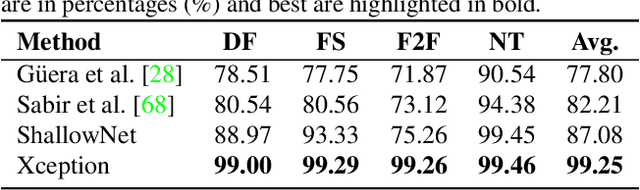
As GAN-based video and image manipulation technologies become more sophisticated and easily accessible, there is an urgent need for effective deepfake detection technologies. Moreover, various deepfake generation techniques have emerged over the past few years. While many deepfake detection methods have been proposed, their performance suffers from new types of deepfake methods on which they are not sufficiently trained. To detect new types of deepfakes, the model should learn from additional data without losing its prior knowledge about deepfakes (catastrophic forgetting), especially when new deepfakes are significantly different. In this work, we employ the Representation Learning (ReL) and Knowledge Distillation (KD) paradigms to introduce a transfer learning-based Feature Representation Transfer Adaptation Learning (FReTAL) method. We use FReTAL to perform domain adaptation tasks on new deepfake datasets while minimizing catastrophic forgetting. Our student model can quickly adapt to new types of deepfake by distilling knowledge from a pre-trained teacher model and applying transfer learning without using source domain data during domain adaptation. Through experiments on FaceForensics++ datasets, we demonstrate that FReTAL outperforms all baselines on the domain adaptation task with up to 86.97% accuracy on low-quality deepfakes.
S2FGAN: Semantically Aware Interactive Sketch-to-Face Translation
Nov 30, 2020
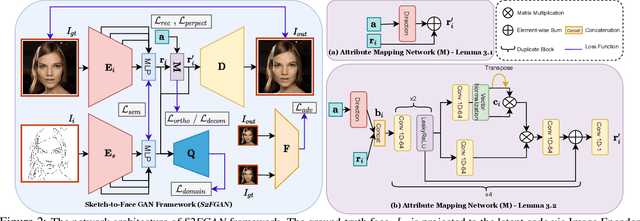
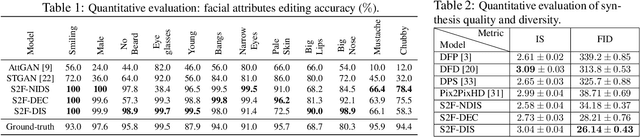

Interactive facial image manipulation attempts to edit single and multiple face attributes using a photo-realistic face and/or semantic mask as input. In the absence of the photo-realistic image (only sketch/mask available), previous methods only retrieve the original face but ignore the potential of aiding model controllability and diversity in the translation process. This paper proposes a sketch-to-image generation framework called S2FGAN, aiming to improve users' ability to interpret and flexibility of face attribute editing from a simple sketch. The proposed framework modifies the constrained latent space semantics trained on Generative Adversarial Networks (GANs). We employ two latent spaces to control the face appearance and adjust the desired attributes of the generated face. Instead of constraining the translation process by using a reference image, the users can command the model to retouch the generated images by involving the semantic information in the generation process. In this way, our method can manipulate single or multiple face attributes by only specifying attributes to be changed. Extensive experimental results on CelebAMask-HQ dataset empirically shows our superior performance and effectiveness on this task. Our method successfully outperforms state-of-the-art methods on attribute manipulation by exploiting greater control of attribute intensity.
ISETAuto: Detecting vehicles with depth and radiance information
Jan 07, 2021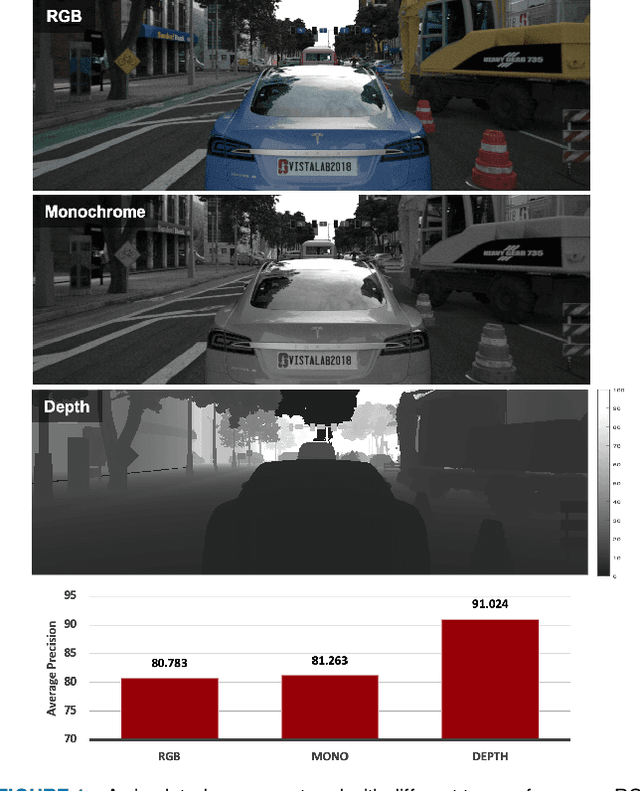

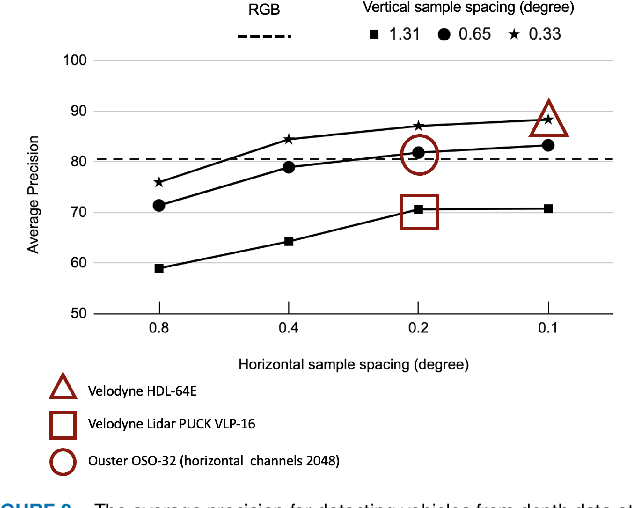
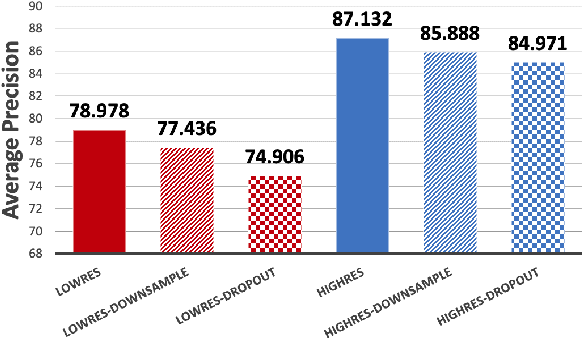
Autonomous driving applications use two types of sensor systems to identify vehicles - depth sensing LiDAR and radiance sensing cameras. We compare the performance (average precision) of a ResNet for vehicle detection in complex, daytime, driving scenes when the input is a depth map (D = d(x,y)), a radiance image (L = r(x,y)), or both [D,L]. (1) When the spatial sampling resolution of the depth map and radiance image are equal to typical camera resolutions, a ResNet detects vehicles at higher average precision from depth than radiance. (2) As the spatial sampling of the depth map declines to the range of current LiDAR devices, the ResNet average precision is higher for radiance than depth. (3) For a hybrid system that combines a depth map and radiance image, the average precision is higher than using depth or radiance alone. We established these observations in simulation and then confirmed them using realworld data. The advantage of combining depth and radiance can be explained by noting that the two type of information have complementary weaknesses. The radiance data are limited by dynamic range and motion blur. The LiDAR data have relatively low spatial resolution. The ResNet combines the two data sources effectively to improve overall vehicle detection.
Image-Based Size Analysis of Agglomerated and Partially Sintered Particles via Convolutional Neural Networks
Jul 12, 2019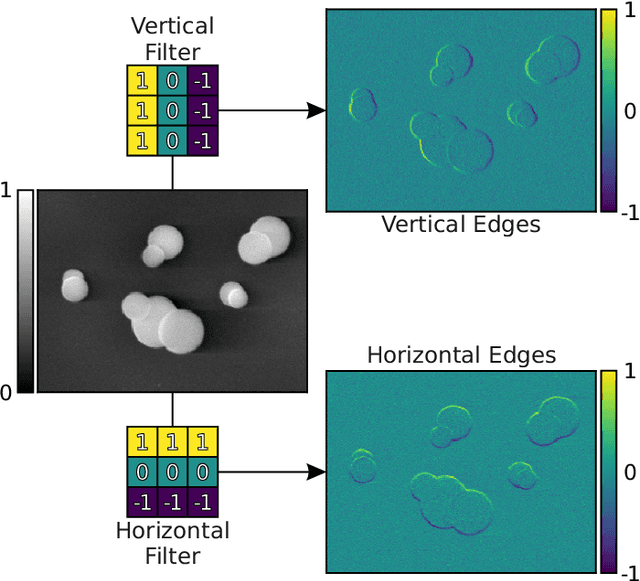
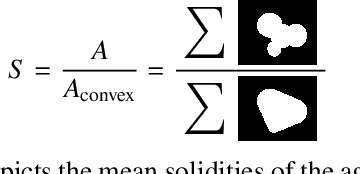
There is a high demand for fully automated methods for the analysis of particle size distributions of agglomerated, sintered or occluded primary particles. Therefore, a novel, deep learning-based, method for the pixel-perfect detection and sizing of agglomerated, aggregated or occluded primary particles was proposed and tested. As a specialty, the training of the utilized convolutional neural networks was carried out using only synthetic images, to avoid the laborious task of manual annotation and to increase the quality of the ground truth. Despite the training on synthetic images, the proposed method performs excellent on real world samples of sintered silica nanoparticles with various sintering degrees and varying image conditions. In a direct comparison, the proposed method clearly outperforms two state-of-the-art methods for automated image-based particle size analysis (Hough transformation and the ImageJ ParticleSizer plug-in), with respect to precision and speed, thereby advancing into regions of human-like performance and reliability.
Accelerating Gossip SGD with Periodic Global Averaging
May 19, 2021
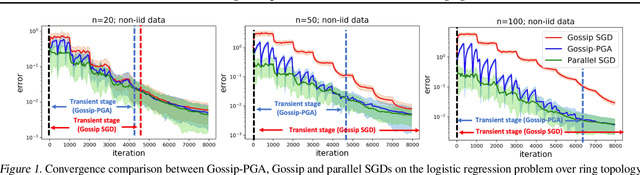

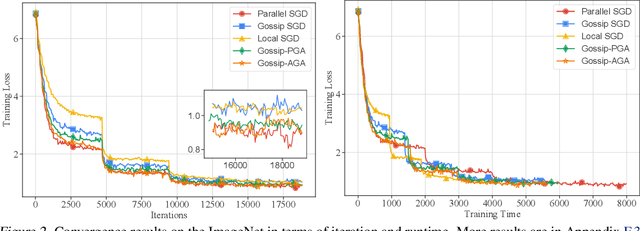
Communication overhead hinders the scalability of large-scale distributed training. Gossip SGD, where each node averages only with its neighbors, is more communication-efficient than the prevalent parallel SGD. However, its convergence rate is reversely proportional to quantity $1-\beta$ which measures the network connectivity. On large and sparse networks where $1-\beta \to 0$, Gossip SGD requires more iterations to converge, which offsets against its communication benefit. This paper introduces Gossip-PGA, which adds Periodic Global Averaging into Gossip SGD. Its transient stage, i.e., the iterations required to reach asymptotic linear speedup stage, improves from $\Omega(\beta^4 n^3/(1-\beta)^4)$ to $\Omega(\beta^4 n^3 H^4)$ for non-convex problems. The influence of network topology in Gossip-PGA can be controlled by the averaging period $H$. Its transient-stage complexity is also superior to Local SGD which has order $\Omega(n^3 H^4)$. Empirical results of large-scale training on image classification (ResNet50) and language modeling (BERT) validate our theoretical findings.