 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-generalizable Face Anti-Spoofing with Patch-based Multi-tasking and Artifact Pattern Conversion
Apr 10, 2026Face Anti-Spoofing (FAS) algorithms, designed to secure face recognition systems against spoofing, struggle with limited dataset diversity, impairing their ability to handle unseen visual domains and spoofing methods. We introduce the Pattern Conversion Generative Adversarial Network (PCGAN) to enhance domain generalization in FAS. PCGAN effectively disentangles latent vectors for spoof artifacts and facial features, allowing to generate images with diverse artifacts. We further incorporate patch-based and multi-task learning to tackle partial attacks and overfitting issues to facial features. Our extensive experiments validate PCGAN's effectiveness in domain generalization and detecting partial attacks, giving a substantial improvement in facial recognition security.
* The published version is available at DOI: https://doi.org/10.1016/j.patcog.2026.113640
MIXAD: Memory-Induced Explainable Time Series Anomaly Detection
Oct 30, 2024



For modern industrial applications, accurately detecting and diagnosing anomalies in multivariate time series data is essential. Despite such need, most state-of-the-art methods often prioritize detection performance over model interpretability. Addressing this gap, we introduce MIXAD (Memory-Induced Explainable Time Series Anomaly Detection), a model designed for interpretable anomaly detection. MIXAD leverages a memory network alongside spatiotemporal processing units to understand the intricate dynamics and topological structures inherent in sensor relationships. We also introduce a novel anomaly scoring method that detects significant shifts in memory activation patterns during anomalies. Our approach not only ensures decent detection performance but also outperforms state-of-the-art baselines by 34.30% and 34.51% in interpretability metrics.
SSMT: Few-Shot Traffic Forecasting with Single Source Meta-Transfer
Oct 21, 2024



Traffic forecasting in Intelligent Transportation Systems (ITS) is vital for intelligent traffic prediction. Yet, ITS often relies on data from traffic sensors or vehicle devices, where certain cities might not have all those smart devices or enabling infrastructures. Also, recent studies have employed meta-learning to generalize spatial-temporal traffic networks, utilizing data from multiple cities for effective traffic forecasting for data-scarce target cities. However, collecting data from multiple cities can be costly and time-consuming. To tackle this challenge, we introduce Single Source Meta-Transfer Learning (SSMT) which relies only on a single source city for traffic prediction. Our method harnesses this transferred knowledge to enable few-shot traffic forecasting, particularly when the target city possesses limited data. Specifically, we use memory-augmented attention to store the heterogeneous spatial knowledge from the source city and selectively recall them for the data-scarce target city. We extend the idea of sinusoidal positional encoding to establish meta-learning tasks by leveraging diverse temporal traffic patterns from the source city. Moreover, to capture a more generalized representation of the positions we introduced a meta-positional encoding that learns the most optimal representation of the temporal pattern across all the tasks. We experiment on five real-world benchmark datasets to demonstrate that our method outperforms several existing methods in time series traffic prediction.
GDFlow: Anomaly Detection with NCDE-based Normalizing Flow for Advanced Driver Assistance System
Sep 09, 2024



For electric vehicles, the Adaptive Cruise Control (ACC) in Advanced Driver Assistance Systems (ADAS) is designed to assist braking based on driving conditions, road inclines, predefined deceleration strengths, and user braking patterns. However, the driving data collected during the development of ADAS are generally limited and lack diversity. This deficiency leads to late or aggressive braking for different users. Crucially, it is necessary to effectively identify anomalies, such as unexpected or inconsistent braking patterns in ADAS, especially given the challenge of working with unlabelled, limited, and noisy datasets from real-world electric vehicles. In order to tackle the aforementioned challenges in ADAS, we propose Graph Neural Controlled Differential Equation Normalizing Flow (GDFlow), a model that leverages Normalizing Flow (NF) with Neural Controlled Differential Equations (NCDE) to learn the distribution of normal driving patterns continuously. Compared to the traditional clustering or anomaly detection algorithms, our approach effectively captures the spatio-temporal information from different sensor data and more accurately models continuous changes in driving patterns. Additionally, we introduce a quantile-based maximum likelihood objective to improve the likelihood estimate of the normal data near the boundary of the distribution, enhancing the model's ability to distinguish between normal and anomalous patterns. We validate GDFlow using real-world electric vehicle driving data that we collected from Hyundai IONIQ5 and GV80EV, achieving state-of-the-art performance compared to six baselines across four dataset configurations of different vehicle types and drivers. Furthermore, our model outperforms the latest anomaly detection methods across four time series benchmark datasets. Our approach demonstrates superior efficiency in inference time compared to existing methods.
Evaluation of an Audio-Video Multimodal Deepfake Dataset using Unimodal and Multimodal Detectors
Sep 07, 2021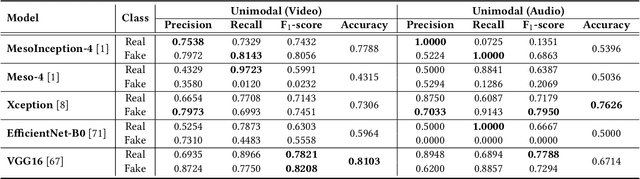
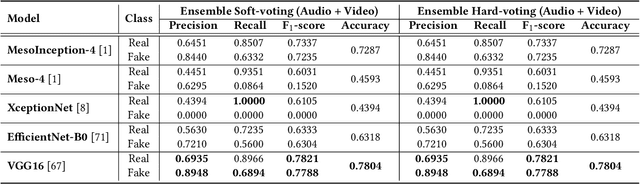
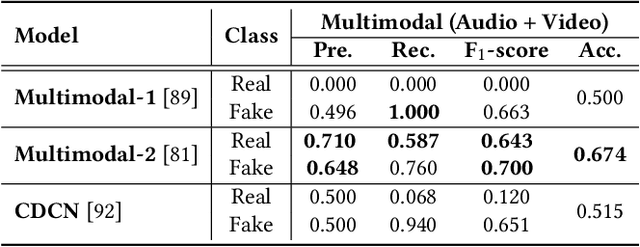
Significant advancements made in the generation of deepfakes have caused security and privacy issues. Attackers can easily impersonate a person's identity in an image by replacing his face with the target person's face. Moreover, a new domain of cloning human voices using deep-learning technologies is also emerging. Now, an attacker can generate realistic cloned voices of humans using only a few seconds of audio of the target person. With the emerging threat of potential harm deepfakes can cause, researchers have proposed deepfake detection methods. However, they only focus on detecting a single modality, i.e., either video or audio. On the other hand, to develop a good deepfake detector that can cope with the recent advancements in deepfake generation, we need to have a detector that can detect deepfakes of multiple modalities, i.e., videos and audios. To build such a detector, we need a dataset that contains video and respective audio deepfakes. We were able to find a most recent deepfake dataset, Audio-Video Multimodal Deepfake Detection Dataset (FakeAVCeleb), that contains not only deepfake videos but synthesized fake audios as well. We used this multimodal deepfake dataset and performed detailed baseline experiments using state-of-the-art unimodal, ensemble-based, and multimodal detection methods to evaluate it. We conclude through detailed experimentation that unimodals, addressing only a single modality, video or audio, do not perform well compared to ensemble-based methods. Whereas purely multimodal-based baselines provide the worst performance.
FakeAVCeleb: A Novel Audio-Video Multimodal Deepfake Dataset
Sep 06, 2021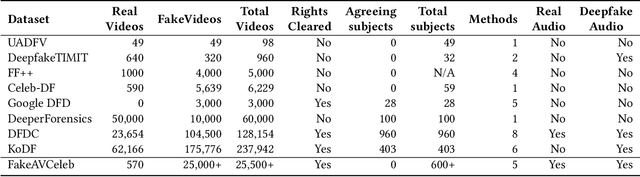
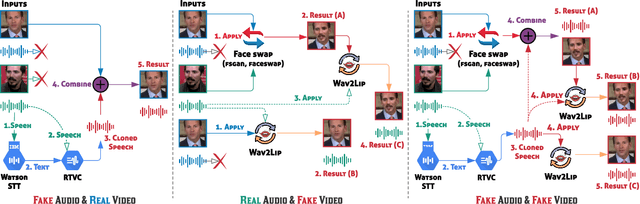
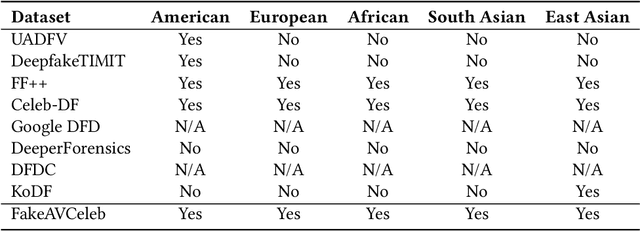

While significant advancements have been made in the generation of deepfakes using deep learning technologies, its misuse is a well-known issue now. Deepfakes can cause severe security and privacy issues as they can be used to impersonate a person's identity in a video by replacing his/her face with another person's face. Recently, a new problem of generating synthesized human voice of a person is emerging, where AI-based deep learning models can synthesize any person's voice requiring just a few seconds of audio. With the emerging threat of impersonation attacks using deepfake audios and videos, a new generation of deepfake detectors is needed to focus on both video and audio collectively. A large amount of good quality datasets is typically required to capture the real-world scenarios to develop a competent deepfake detector. Existing deepfake datasets either contain deepfake videos or audios, which are racially biased as well. Hence, there is a crucial need for creating a good video as well as an audio deepfake dataset, which can be used to detect audio and video deepfake simultaneously. To fill this gap, we propose a novel Audio-Video Deepfake dataset (FakeAVCeleb) that contains not only deepfake videos but also respective synthesized lip-synced fake audios. We generate this dataset using the current most popular deepfake generation methods. We selected real YouTube videos of celebrities with four racial backgrounds (Caucasian, Black, East Asian, and South Asian) to develop a more realistic multimodal dataset that addresses racial bias and further help develop multimodal deepfake detectors. We performed several experiments using state-of-the-art detection methods to evaluate our deepfake dataset and demonstrate the challenges and usefulness of our multimodal Audio-Video deepfake dataset.
CoReD: Generalizing Fake Media Detection with Continual Representation using Distillation
Jul 10, 2021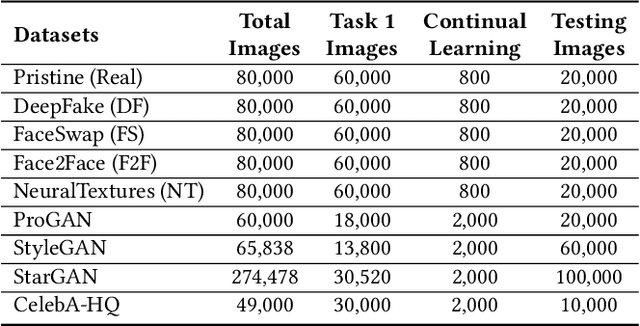
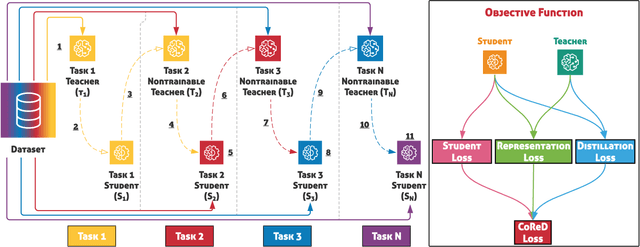
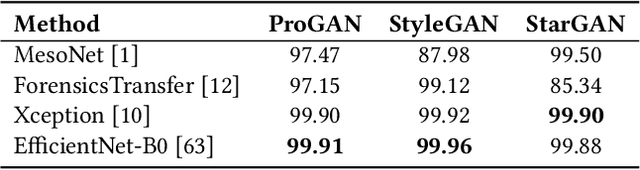
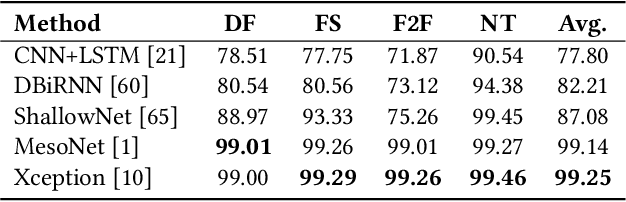
Over the last few decades, artificial intelligence research has made tremendous strides, but it still heavily relies on fixed datasets in stationary environments. Continual learning is a growing field of research that examines how AI systems can learn sequentially from a continuous stream of linked data in the same way that biological systems do. Simultaneously, fake media such as deepfakes and synthetic face images have emerged as significant to current multimedia technologies. Recently, numerous method has been proposed which can detect deepfakes with high accuracy. However, they suffer significantly due to their reliance on fixed datasets in limited evaluation settings. Therefore, in this work, we apply continuous learning to neural networks' learning dynamics, emphasizing its potential to increase data efficiency significantly. We propose Continual Representation using Distillation (CoReD) method that employs the concept of Continual Learning (CoL), Representation Learning (ReL), and Knowledge Distillation (KD). We design CoReD to perform sequential domain adaptation tasks on new deepfake and GAN-generated synthetic face datasets, while effectively minimizing the catastrophic forgetting in a teacher-student model setting. Our extensive experimental results demonstrate that our method is efficient at domain adaptation to detect low-quality deepfakes videos and GAN-generated images from several datasets, outperforming the-state-of-art baseline methods.
FReTAL: Generalizing Deepfake Detection using Knowledge Distillation and Representation Learning
May 28, 2021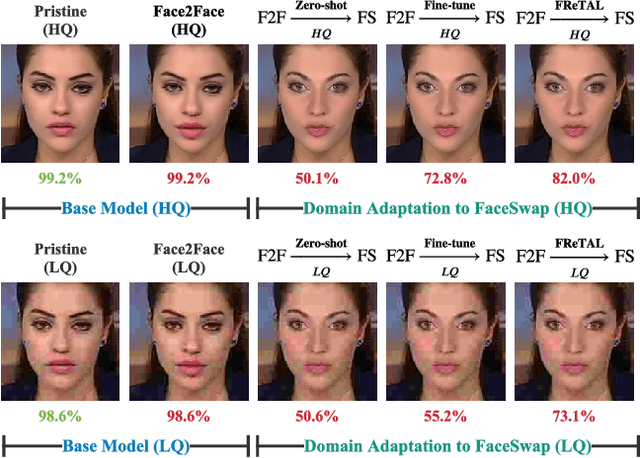
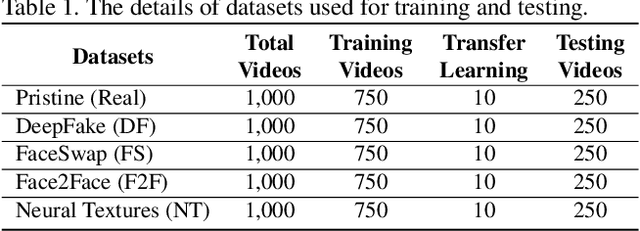
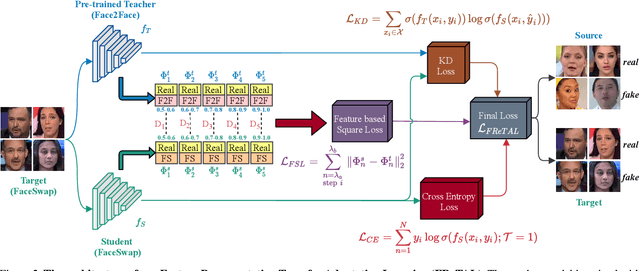
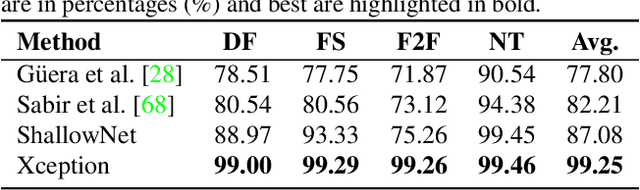
As GAN-based video and image manipulation technologies become more sophisticated and easily accessible, there is an urgent need for effective deepfake detection technologies. Moreover, various deepfake generation techniques have emerged over the past few years. While many deepfake detection methods have been proposed, their performance suffers from new types of deepfake methods on which they are not sufficiently trained. To detect new types of deepfakes, the model should learn from additional data without losing its prior knowledge about deepfakes (catastrophic forgetting), especially when new deepfakes are significantly different. In this work, we employ the Representation Learning (ReL) and Knowledge Distillation (KD) paradigms to introduce a transfer learning-based Feature Representation Transfer Adaptation Learning (FReTAL) method. We use FReTAL to perform domain adaptation tasks on new deepfake datasets while minimizing catastrophic forgetting. Our student model can quickly adapt to new types of deepfake by distilling knowledge from a pre-trained teacher model and applying transfer learning without using source domain data during domain adaptation. Through experiments on FaceForensics++ datasets, we demonstrate that FReTAL outperforms all baselines on the domain adaptation task with up to 86.97% accuracy on low-quality deepfakes.