 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Super-Resolution using Explicit Perceptual Loss
Paper and Code
Sep 01, 2020
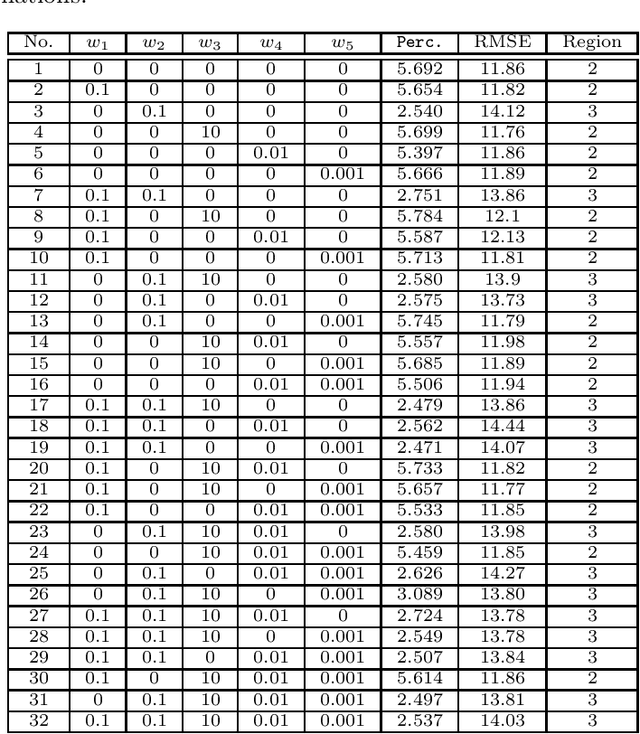
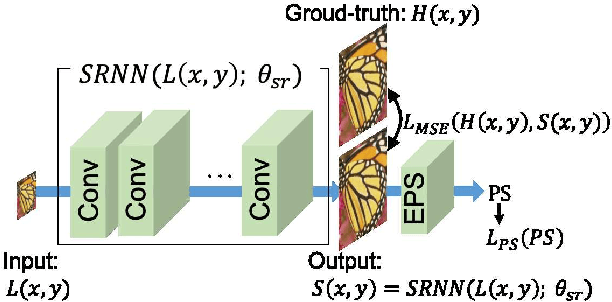

This paper proposes an explicit way to optimize the super-resolution network for generating visually pleasing images. The previous approaches use several loss functions which is hard to interpret and has the implicit relationships to improve the perceptual score. We show how to exploit the machine learning based model which is directly trained to provide the perceptual score on generated images. It is believed that these models can be used to optimizes the super-resolution network which is easier to interpret. We further analyze the characteristic of the existing loss and our proposed explicit perceptual loss for better interpretation. The experimental results show the explicit approach has a higher perceptual score than other approaches. Finally, we demonstrate the relation of explicit perceptual loss and visually pleasing images using subjective evaluation.