 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Orthogonally Regularized Deep Networks For Image Super-resolution
Feb 06, 2018
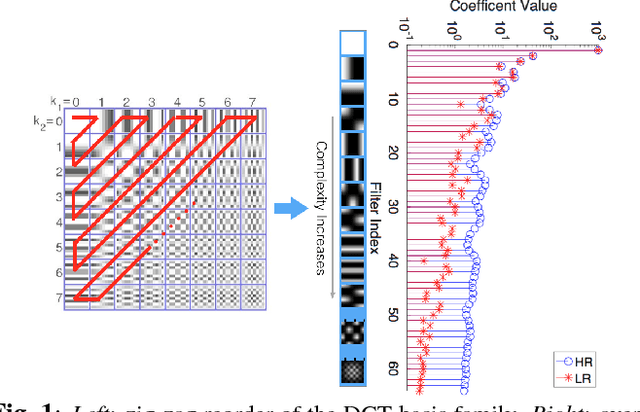

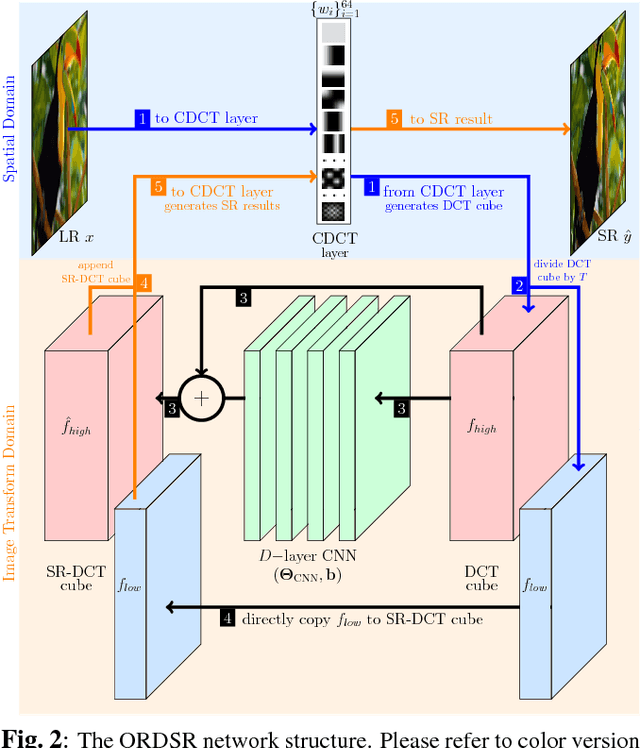

Deep learning methods, in particular trained Convolutional Neural Networks (CNNs) have recently been shown to produce compelling state-of-the-art results for single image Super-Resolution (SR). Invariably, a CNN is learned to map the low resolution (LR) image to its corresponding high resolution (HR) version in the spatial domain. Aiming for faster inference and more efficient solutions than solving the SR problem in the spatial domain, we propose a novel network structure for learning the SR mapping function in an image transform domain, specifically the Discrete Cosine Transform (DCT). As a first contribution, we show that DCT can be integrated into the network structure as a Convolutional DCT (CDCT) layer. We further extend the network to allow the CDCT layer to become trainable (i.e. optimizable). Because this layer represents an image transform, we enforce pairwise orthogonality constraints on the individual basis functions/filters. This Orthogonally Regularized Deep SR network (ORDSR) simplifies the SR task by taking advantage of image transform domain while adapting the design of transform basis to the training image set.
Total3DUnderstanding: Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes from a Single Image
Feb 27, 2020
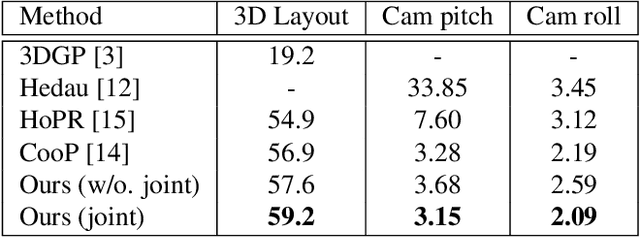
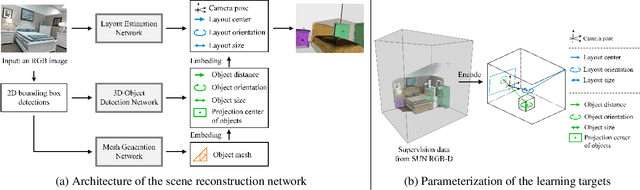

Semantic reconstruction of indoor scenes refers to both scene understanding and object reconstruction. Existing works either address one part of this problem or focus on independent objects. In this paper, we bridge the gap between understanding and reconstruction, and propose an end-to-end solution to jointly reconstruct room layout, object bounding boxes and meshes from a single image. Instead of separately resolving scene understanding and object reconstruction, our method builds upon a holistic scene context and proposes a coarse-to-fine hierarchy with three components: 1. room layout with camera pose; 2. 3D object bounding boxes; 3. object meshes. We argue that understanding the context of each component can assist the task of parsing the others, which enables joint understanding and reconstruction. The experiments on the SUN RGB-D and Pix3D datasets demonstrate that our method consistently outperforms existing methods in indoor layout estimation, 3D object detection and mesh reconstruction.
Quantum Enhanced Filter: QFilter
Apr 07, 2021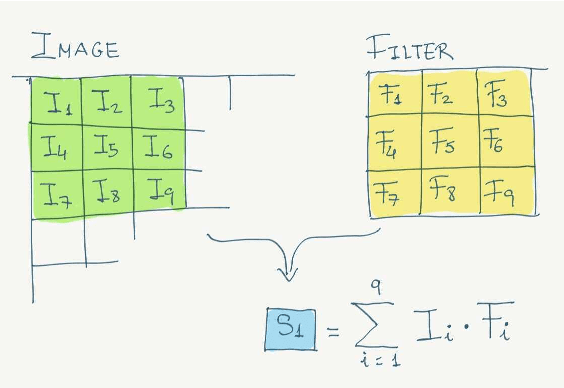
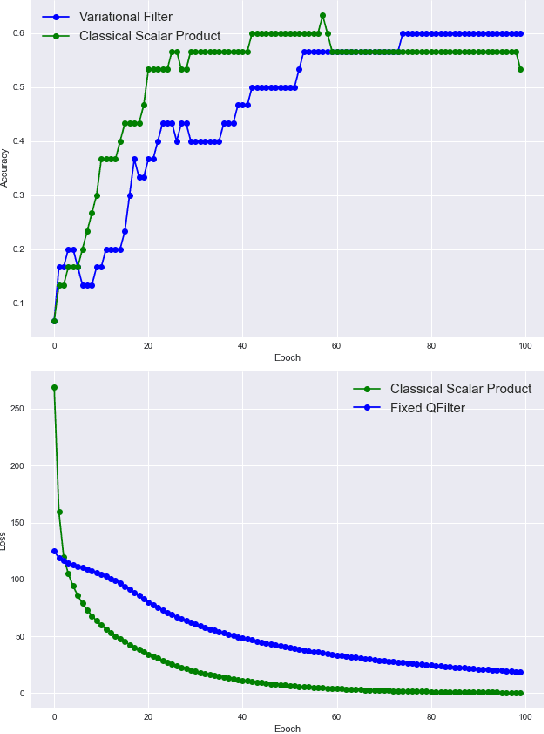
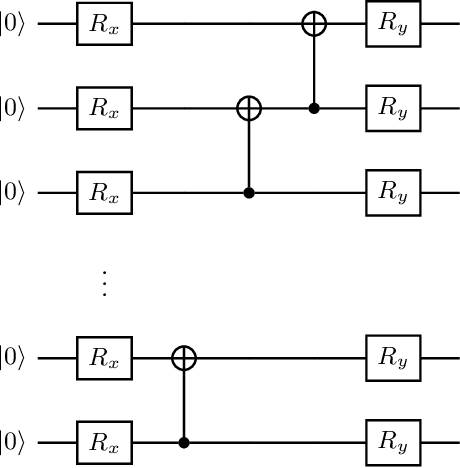
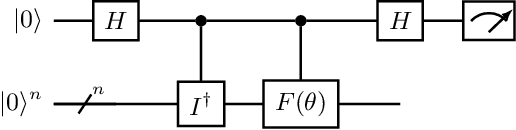
Convolutional Neural Networks (CNN) are used mainly to treat problems with many images characteristic of Deep Learning. In this work, we propose a hybrid image classification model to take advantage of quantum and classical computing. The method will use the potential that convolutional networks have shown in artificial intelligence by replacing classical filters with variational quantum filters. Similarly, this work will compare with other classification methods and the system's execution on different servers. The algorithm's quantum feasibility is modelled and tested on Amazon Braket Notebook instances and experimented on the Pennylane's philosophy and framework.
Image Projective Invariants
Jul 19, 2017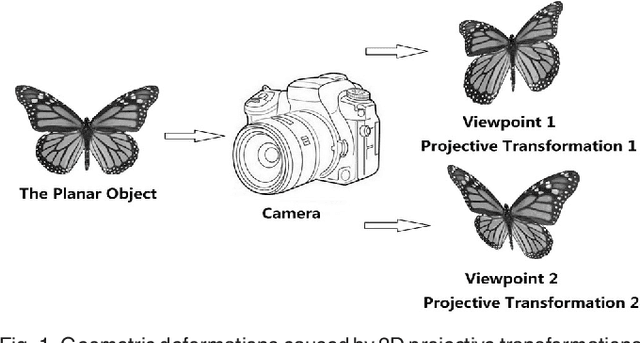

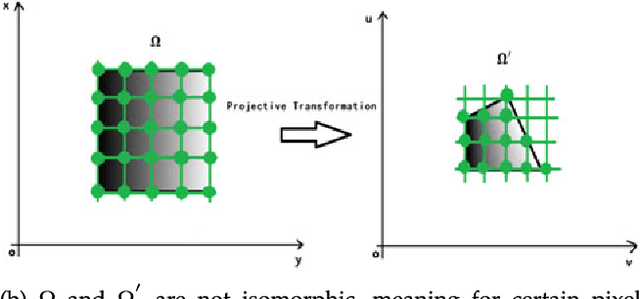

In this paper, we propose relative projective differential invariants (RPDIs) which are invariant to general projective transformations. By using RPDIs and the structural frame of integral invariant, projective weighted moment invariants (PIs) can be constructed very easily. It is first proved that a kind of projective invariants exists in terms of weighted integration of images, with relative differential invariants as the weight functions. Then, some simple instances of PIs are given. In order to ensure the stability and discriminability of PIs, we discuss how to calculate partial derivatives of discrete images more accurately. Since the number of pixels in discrete images before and after the geometric transformation may be different, we design the method to normalize the number of pixels. These ways enhance the performance of PIs. Finally, we carry out some experiments based on synthetic and real image datasets. We choose commonly used moment invariants for comparison. The results indicate that PIs have better performance than other moment invariants in image retrieval and classification. With PIs, one can compare the similarity between images under the projective transformation without knowing the parameters of the transformation, which provides a good tool to shape analysis in image processing, computer vision and pattern recognition.
Remote sensing image regression for heterogeneous change detection
Jul 31, 2018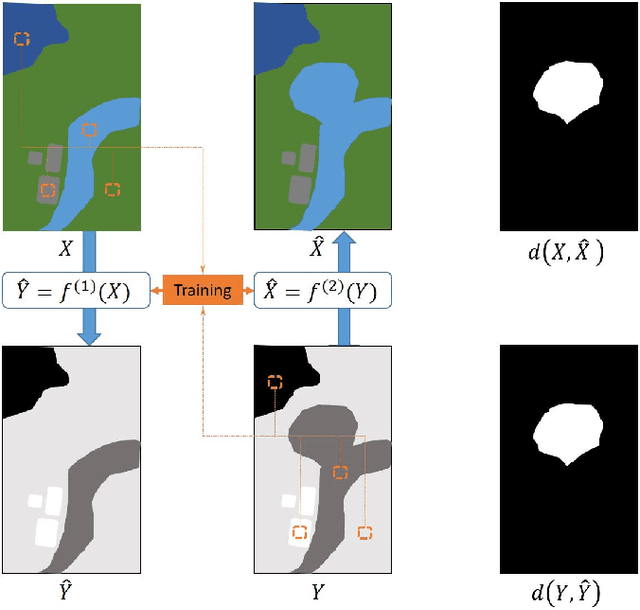
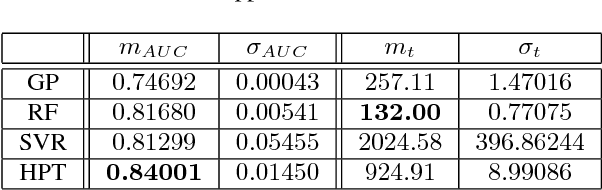


Change detection in heterogeneous multitemporal satellite images is an emerging topic in remote sensing. In this paper we propose a framework, based on image regression, to perform change detection in heterogeneous multitemporal satellite images, which has become a main topic in remote sensing. Our method learns a transformation to map the first image to the domain of the other image, and vice versa. Four regression methods are selected to carry out the transformation: Gaussian processes, support vector machines, random forests, and a recently proposed kernel regression method called homogeneous pixel transformation. To evaluate not only potentials and limitations of our framework, but also the pros and cons of each regression method, we perform experiments on two data sets. The results indicates that random forests achieve good performance, are fast and robust to hyperparameters, whereas the homogeneous pixel transformation method can achieve better accuracy at the cost of a higher complexity.
Real-Time High-Performance Semantic Image Segmentation of Urban Street Scenes
Mar 11, 2020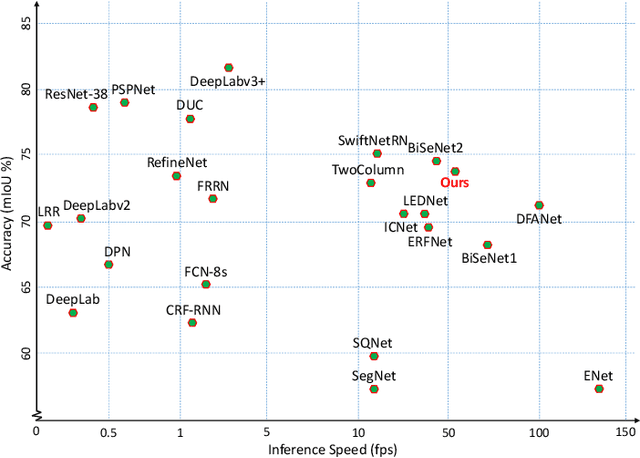


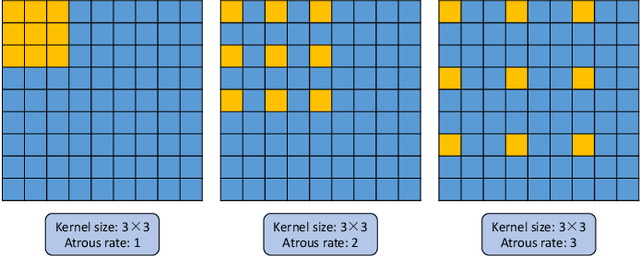
Deep Convolutional Neural Networks (DCNNs) have recently shown outstanding performance in semantic image segmentation. However, state-of-the-art DCNN-based semantic segmentation methods usually suffer from high computational complexity due to the use of complex network architectures. This greatly limits their applications in the real-world scenarios that require real-time processing. In this paper, we propose a real-time high-performance DCNN-based method for robust semantic segmentation of urban street scenes, which achieves a good trade-off between accuracy and speed. Specifically, a Lightweight Baseline Network with Atrous convolution and Attention (LBN-AA) is firstly used as our baseline network to efficiently obtain dense feature maps. Then, the Distinctive Atrous Spatial Pyramid Pooling (DASPP), which exploits the different sizes of pooling operations to encode the rich and distinctive semantic information, is developed to detect objects at multiple scales. Meanwhile, a Spatial detail-Preserving Network (SPN) with shallow convolutional layers is designed to generate high-resolution feature maps preserving the detailed spatial information. Finally, a simple but practical Feature Fusion Network (FFN) is used to effectively combine both shallow and deep features from the semantic branch (DASPP) and the spatial branch (SPN), respectively. Extensive experimental results show that the proposed method respectively achieves the accuracy of 73.6% and 68.0% mean Intersection over Union (mIoU) with the inference speed of 51.0 fps and 39.3 fps on the challenging Cityscapes and CamVid test datasets (by only using a single NVIDIA TITAN X card). This demonstrates that the proposed method offers excellent performance at the real-time speed for semantic segmentation of urban street scenes.
Generalized Categorisation of Digital Pathology Whole Image Slides using Unsupervised Learning
Dec 27, 2020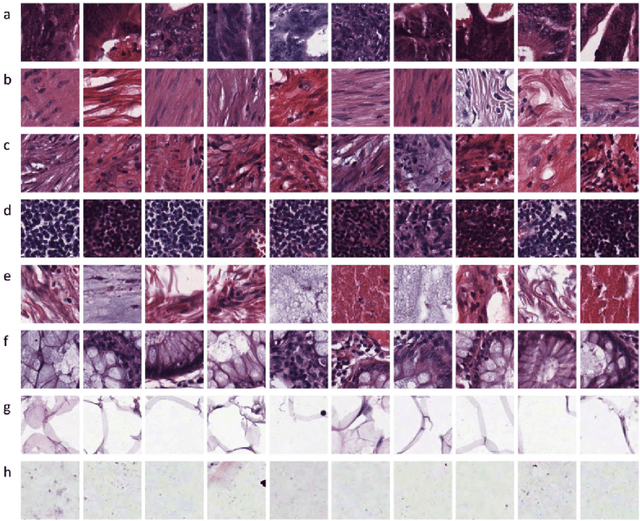
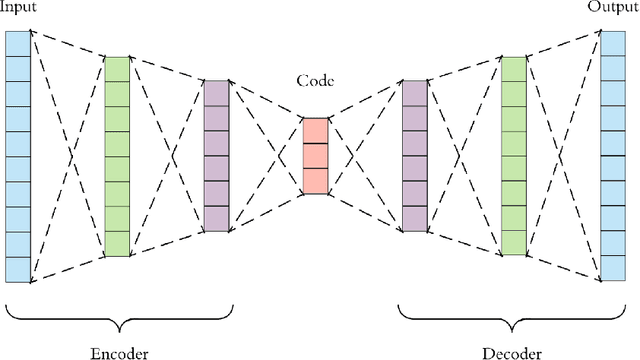
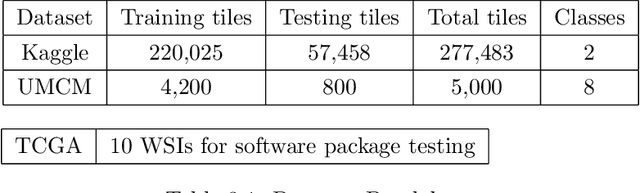
This project aims to break down large pathology images into small tiles and then cluster those tiles into distinct groups without the knowledge of true labels, our analysis shows how difficult certain aspects of clustering tumorous and non-tumorous cells can be and also shows that comparing the results of different unsupervised approaches is not a trivial task. The project also provides a software package to be used by the digital pathology community, that uses some of the approaches developed to perform unsupervised unsupervised tile classification, which could then be easily manually labelled. The project uses a mixture of techniques ranging from classical clustering algorithms such as K-Means and Gaussian Mixture Models to more complicated feature extraction techniques such as deep Autoencoders and Multi-loss learning. Throughout the project, we attempt to set a benchmark for evaluation using a few measures such as completeness scores and cluster plots. Throughout our results we show that Convolutional Autoencoders manages to slightly outperform the rest of the approaches due to its powerful internal representation learning abilities. Moreover, we show that Gaussian Mixture models produce better results than K-Means on average due to its flexibility in capturing different clusters. We also show the huge difference in the difficulties of classifying different types of pathology textures.
Lidar-Monocular Surface Reconstruction Using Line Segments
Apr 06, 2021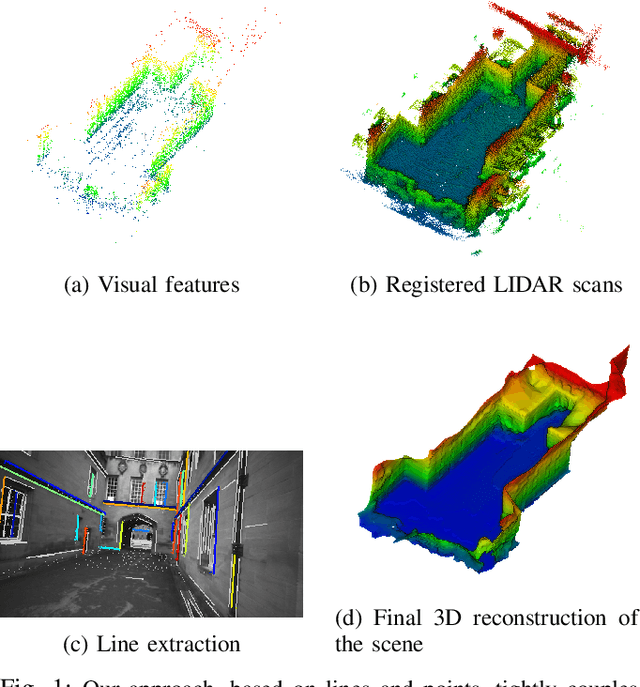
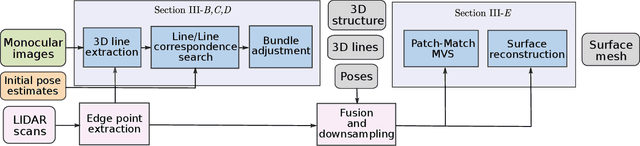
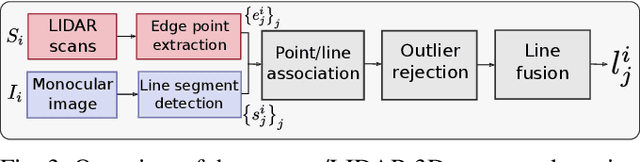
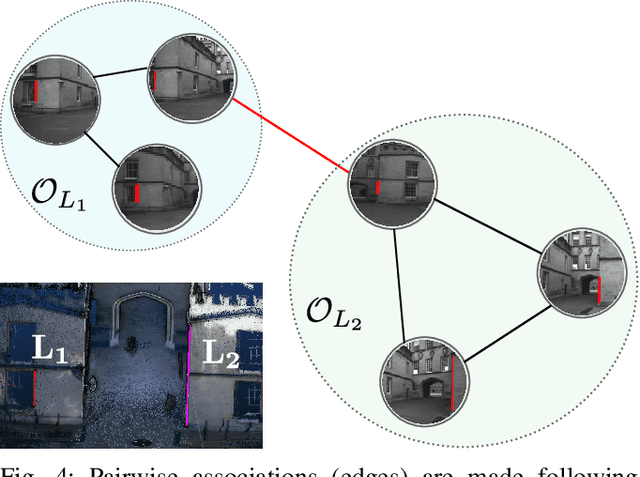
Structure from Motion (SfM) often fails to estimate accurate poses in environments that lack suitable visual features. In such cases, the quality of the final 3D mesh, which is contingent on the accuracy of those estimates, is reduced. One way to overcome this problem is to combine data from a monocular camera with that of a LIDAR. This allows fine details and texture to be captured while still accurately representing featureless subjects. However, fusing these two sensor modalities is challenging due to their fundamentally different characteristics. Rather than directly fusing image features and LIDAR points, we propose to leverage common geometric features that are detected in both the LIDAR scans and image data, allowing data from the two sensors to be processed in a higher-level space. In particular, we propose to find correspondences between 3D lines extracted from LIDAR scans and 2D lines detected in images before performing a bundle adjustment to refine poses. We also exploit the detected and optimized line segments to improve the quality of the final mesh. We test our approach on the recently published dataset, Newer College Dataset. We compare the accuracy and the completeness of the 3D mesh to a ground truth obtained with a survey-grade 3D scanner. We show that our method delivers results that are comparable to a state-of-the-art LIDAR survey while not requiring highly accurate ground truth pose estimates.
Untrained networks for compressive lensless photography
Mar 13, 2021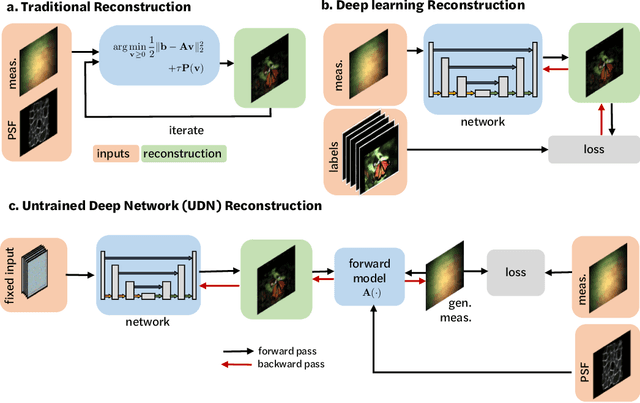
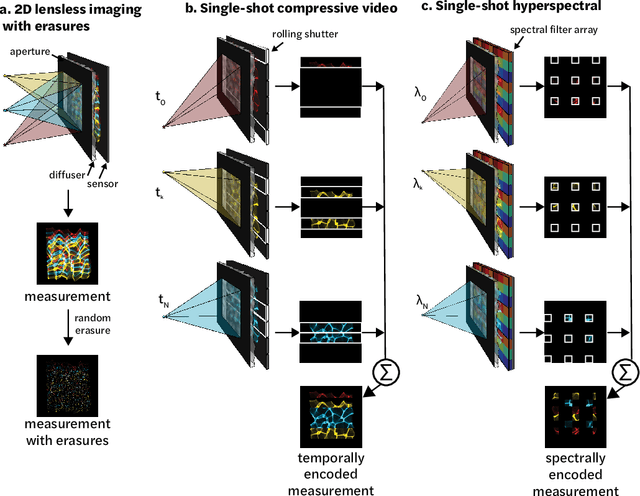
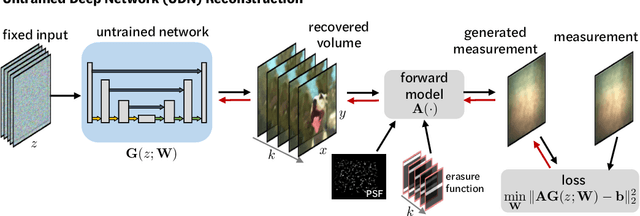
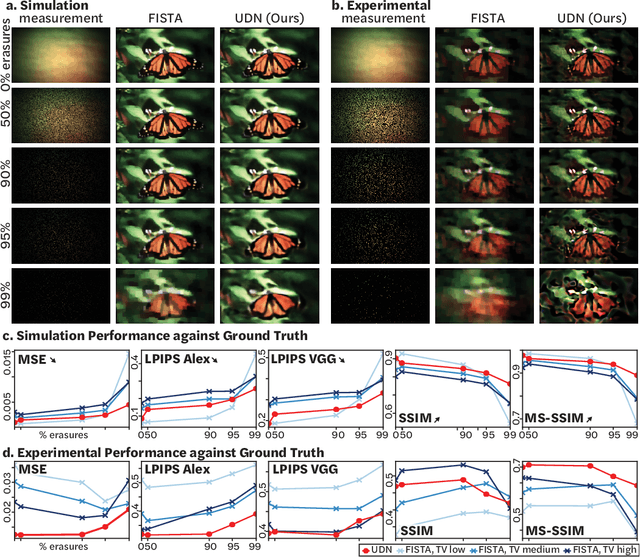
Compressive lensless imagers enable novel applications in an extremely compact device, requiring only a phase or amplitude mask placed close to the sensor. They have been demonstrated for 2D and 3D microscopy, single-shot video, and single-shot hyperspectral imaging; in each of these cases, a compressive-sensing-based inverse problem is solved in order to recover a 3D data-cube from a 2D measurement. Typically, this is accomplished using convex optimization and hand-picked priors. Alternatively, deep learning-based reconstruction methods offer the promise of better priors, but require many thousands of ground truth training pairs, which can be difficult or impossible to acquire. In this work, we propose the use of untrained networks for compressive image recovery. Our approach does not require any labeled training data, but instead uses the measurement itself to update the network weights. We demonstrate our untrained approach on lensless compressive 2D imaging as well as single-shot high-speed video recovery using the camera's rolling shutter, and single-shot hyperspectral imaging. We provide simulation and experimental verification, showing that our method results in improved image quality over existing methods.
Machine learning based in situ quality estimation by molten pool condition-quality relations modeling using experimental data
Mar 21, 2021
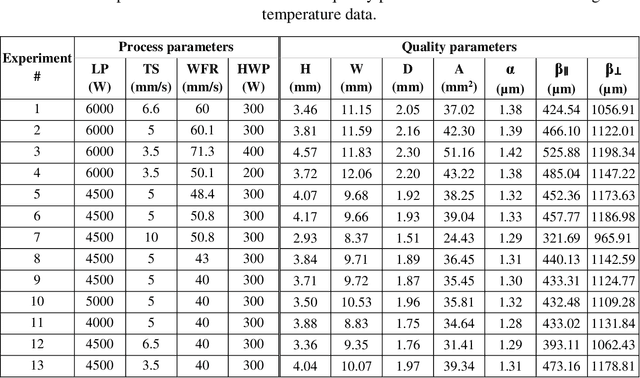


The advancement of machine learning promises the ability to accelerate the adoption of new processes and property designs for metal additive manufacturing. The molten pool geometry and molten pool temperature are the significant indicators for the final part's geometric shape and microstructural properties for the Wire-feed laser direct energy deposition process. Thus, the molten pool condition-property relations are of preliminary importance for in situ quality assurance. To enable in situ quality monitoring of bead geometry and characterization properties, we need to continuously monitor the sensor's data for molten pool dimensions and temperature for the Wire-feed laser additive manufacturing (WLAM) system. We first develop a machine learning convolutional neural network (CNN) model for establishing the correlations from the measurable molten pool image and temperature data directly to the geometric shape and microstructural properties. The multi-modality network receives both the camera image and temperature measurement as inputs, yielding the corresponding characterization properties of the final build part (e.g., fusion zone depth, alpha lath thickness). The performance of the CNN model is compared with the regression model as a baseline. The developed models enable molten pool condition-quality relations mapping for building quantitative and collaborative in situ quality estimation and assurance framework.