 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFill the Gap: Quantifying and Reducing the Modality Gap in Image-Text Representation Learning
May 06, 2025Vision-language models (VLMs) allow to embed texts and images in a shared representation space. However, it has been shown that these models are subject to a modality gap phenomenon meaning there exists a clear separation between the embeddings from one modality and another in the embedding space. While this misalignment is detrimental for downstream tasks such as multimodal retrieval, multimodal clustering or zero-shot classification, etc. no generic and practical methods have so far been proposed to assess it precisely and even reduce it. We therefore propose novel measures and effective techniques (spectral- and optimal transport-based methods) to achieve this goal. Extensive experiments conducted on several image-text datasets and models demonstrate their effectiveness and beneficial effects on downstream tasks. Our code is available at the URL provided in the paper's abstract.
Lidar-Monocular Surface Reconstruction Using Line Segments
Apr 06, 2021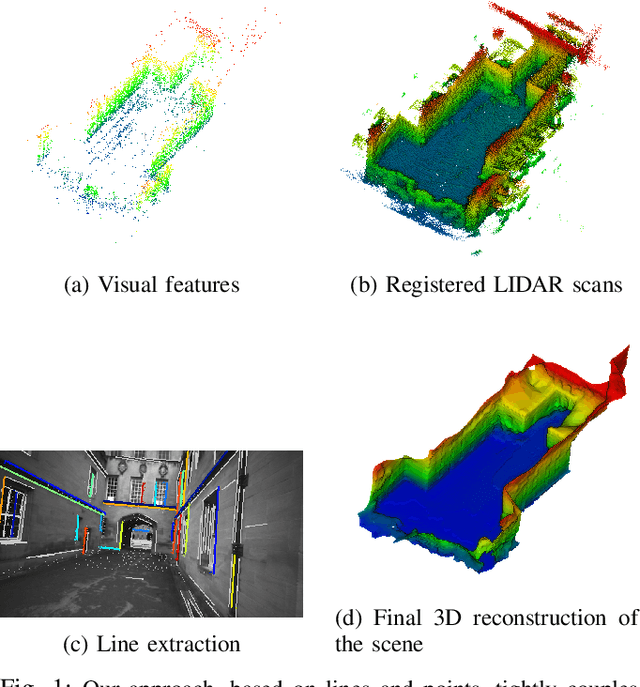
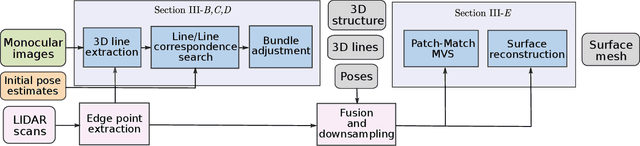
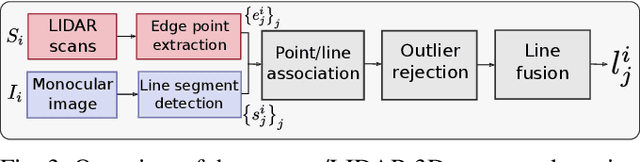
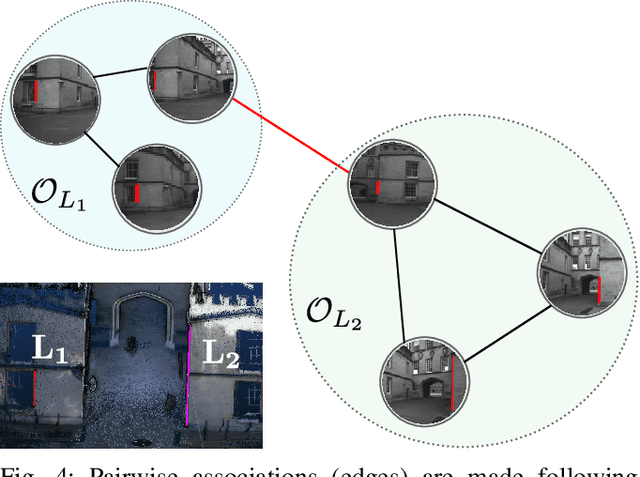
Structure from Motion (SfM) often fails to estimate accurate poses in environments that lack suitable visual features. In such cases, the quality of the final 3D mesh, which is contingent on the accuracy of those estimates, is reduced. One way to overcome this problem is to combine data from a monocular camera with that of a LIDAR. This allows fine details and texture to be captured while still accurately representing featureless subjects. However, fusing these two sensor modalities is challenging due to their fundamentally different characteristics. Rather than directly fusing image features and LIDAR points, we propose to leverage common geometric features that are detected in both the LIDAR scans and image data, allowing data from the two sensors to be processed in a higher-level space. In particular, we propose to find correspondences between 3D lines extracted from LIDAR scans and 2D lines detected in images before performing a bundle adjustment to refine poses. We also exploit the detected and optimized line segments to improve the quality of the final mesh. We test our approach on the recently published dataset, Newer College Dataset. We compare the accuracy and the completeness of the 3D mesh to a ground truth obtained with a survey-grade 3D scanner. We show that our method delivers results that are comparable to a state-of-the-art LIDAR survey while not requiring highly accurate ground truth pose estimates.