 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Self-Adaptive Metric Learning On the Fly
Apr 03, 2021

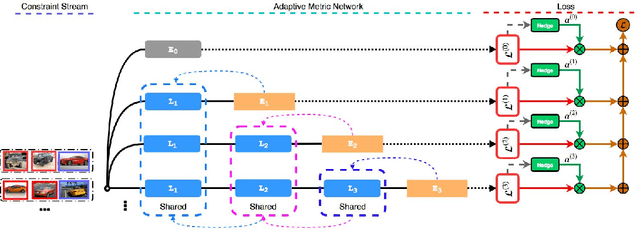
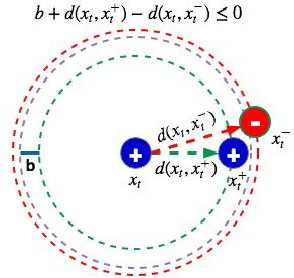
Good quality similarity metrics can significantly facilitate the performance of many large-scale, real-world applications. Existing studies have proposed various solutions to learn a Mahalanobis or bilinear metric in an online fashion by either restricting distances between similar (dissimilar) pairs to be smaller (larger) than a given lower (upper) bound or requiring similar instances to be separated from dissimilar instances with a given margin. However, these linear metrics learned by leveraging fixed bounds or margins may not perform well in real-world applications, especially when data distributions are complex. We aim to address the open challenge of "Online Adaptive Metric Learning" (OAML) for learning adaptive metric functions on the fly. Unlike traditional online metric learning methods, OAML is significantly more challenging since the learned metric could be non-linear and the model has to be self-adaptive as more instances are observed. In this paper, we present a new online metric learning framework that attempts to tackle the challenge by learning an ANN-based metric with adaptive model complexity from a stream of constraints. In particular, we propose a novel Adaptive-Bound Triplet Loss (ABTL) to effectively utilize the input constraints and present a novel Adaptive Hedge Update (AHU) method for online updating the model parameters. We empirically validate the effectiveness and efficacy of our framework on various applications such as real-world image classification, facial verification, and image retrieval.
Focused LRP: Explainable AI for Face Morphing Attack Detection
Mar 26, 2021

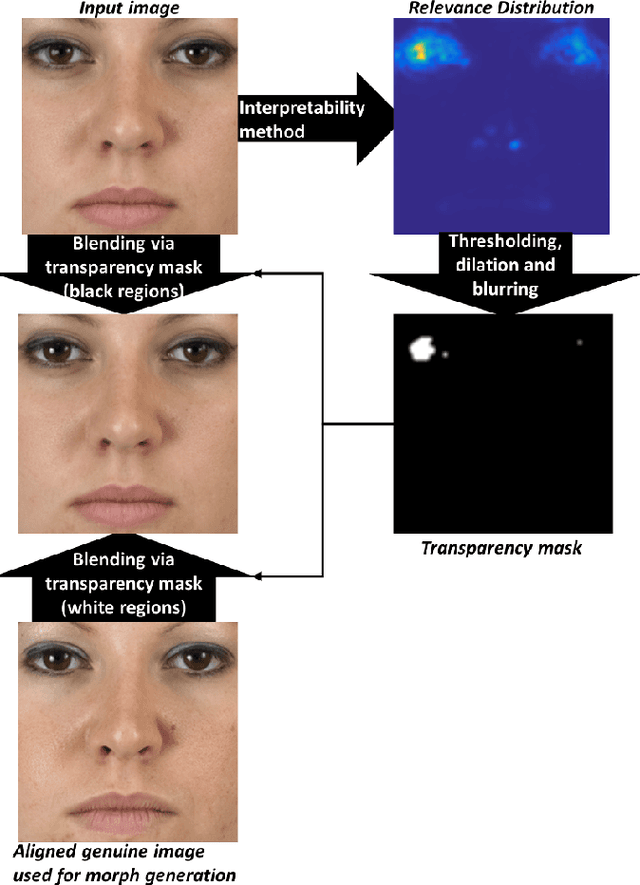
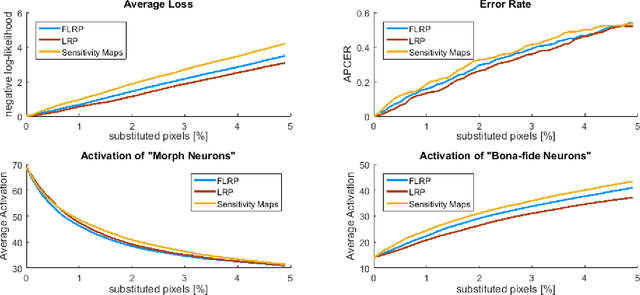
The task of detecting morphed face images has become highly relevant in recent years to ensure the security of automatic verification systems based on facial images, e.g. automated border control gates. Detection methods based on Deep Neural Networks (DNN) have been shown to be very suitable to this end. However, they do not provide transparency in the decision making and it is not clear how they distinguish between genuine and morphed face images. This is particularly relevant for systems intended to assist a human operator, who should be able to understand the reasoning. In this paper, we tackle this problem and present Focused Layer-wise Relevance Propagation (FLRP). This framework explains to a human inspector on a precise pixel level, which image regions are used by a Deep Neural Network to distinguish between a genuine and a morphed face image. Additionally, we propose another framework to objectively analyze the quality of our method and compare FLRP to other DNN interpretability methods. This evaluation framework is based on removing detected artifacts and analyzing the influence of these changes on the decision of the DNN. Especially, if the DNN is uncertain in its decision or even incorrect, FLRP performs much better in highlighting visible artifacts compared to other methods.
Plot and Rework: Modeling Storylines for Visual Storytelling
May 14, 2021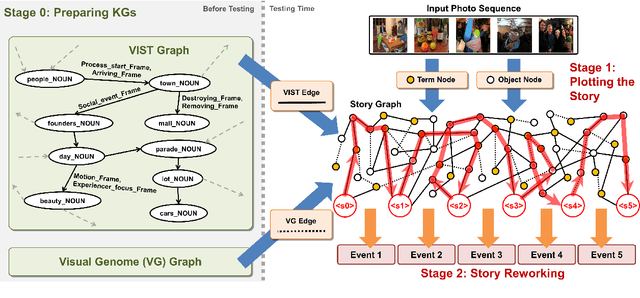

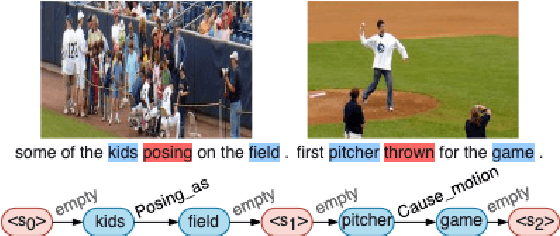

Writing a coherent and engaging story is not easy. Creative writers use their knowledge and worldview to put disjointed elements together to form a coherent storyline, and work and rework iteratively toward perfection. Automated visual storytelling (VIST) models, however, make poor use of external knowledge and iterative generation when attempting to create stories. This paper introduces PR-VIST, a framework that represents the input image sequence as a story graph in which it finds the best path to form a storyline. PR-VIST then takes this path and learns to generate the final story via an iterative training process. This framework produces stories that are superior in terms of diversity, coherence, and humanness, per both automatic and human evaluations. An ablation study shows that both plotting and reworking contribute to the model's superiority.
Zero-Shot Calibration of Fisheye Cameras
Nov 30, 2020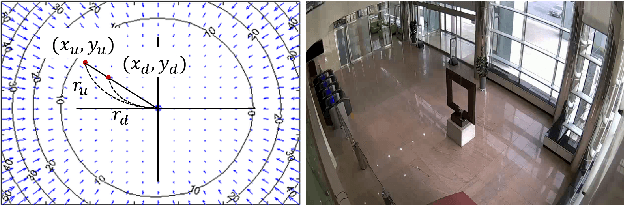
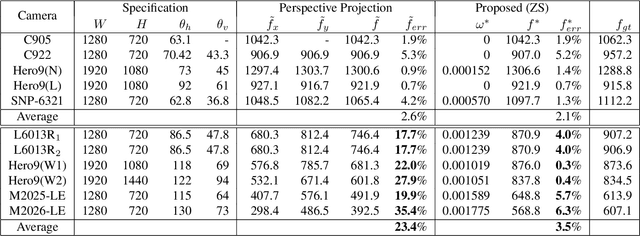
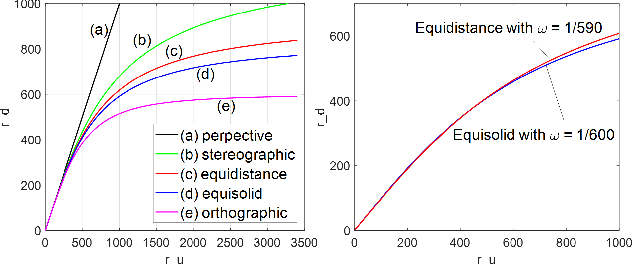
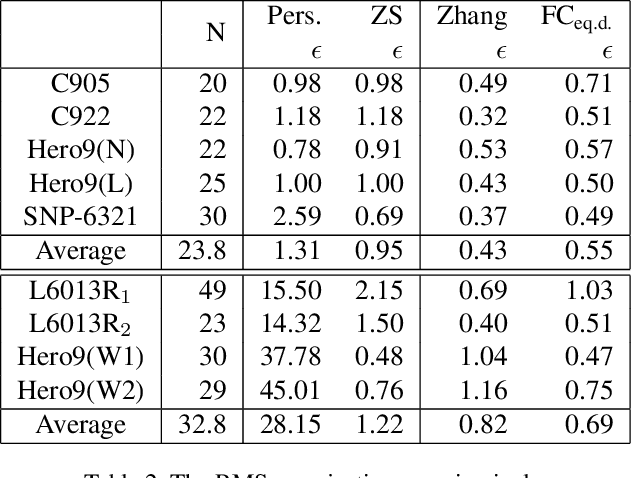
In this paper, we present a novel zero-shot camera calibration method that estimates camera parameters with no calibration image. It is common sense that we need at least one or more pattern images for camera calibration. However, the proposed method estimates camera parameters from the horizontal and vertical field of view information of the camera without any image acquisition. The proposed method is particularly useful for wide-angle or fisheye cameras that have large image distortion. Image distortion is modeled in the way fisheye lenses are designed and estimated based on the square pixel assumption of the image sensors. The calibration accuracy of the proposed method is evaluated on eight different commercial cameras qualitatively and quantitatively, and compared with conventional calibration methods. The experimental results show that the calibration accuracy of the zero-shot method is comparable to conventional full calibration results. The method can be used as a practical alternative in real applications where individual calibration is difficult or impractical, and in most field applications where calibration accuracy is less critical. Moreover, the estimated camera parameters by the method can also be used to provide proper initialization of any existing calibration methods, making them to converge more stably and avoid local minima.
Chart-Text: A Fully Automated Chart Image Descriptor
Dec 27, 2018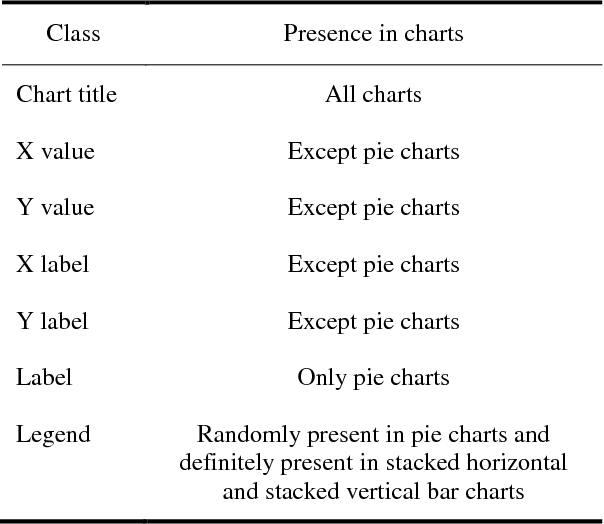
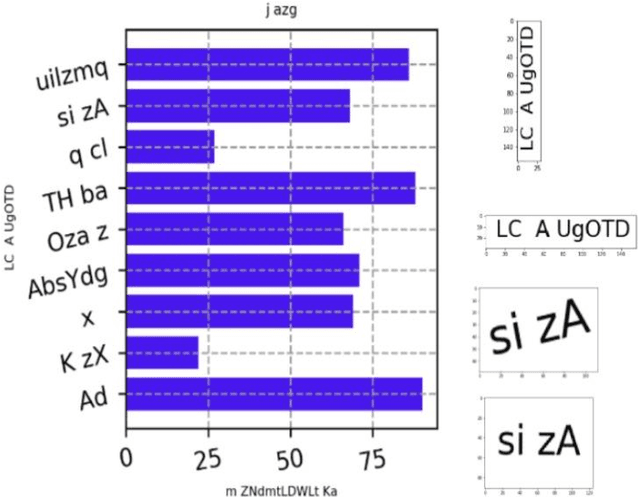
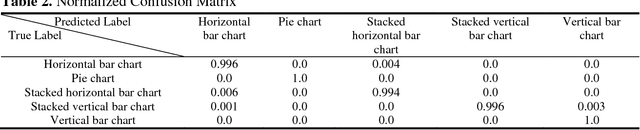
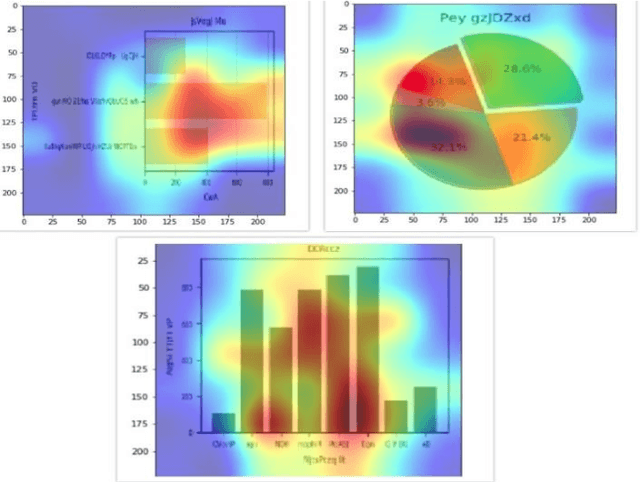
Images greatly help in understanding, interpreting and visualizing data. Adding textual description to images is the first and foremost principle of web accessibility. Visually impaired users using screen readers will use these textual descriptions to get better understanding of images present in digital contents. In this paper, we propose Chart-Text a novel fully automated system that creates textual description of chart images. Given a PNG image of a chart, our Chart-Text system creates a complete textual description of it. First, the system classifies the type of chart and then it detects and classifies the labels and texts in the charts. Finally, it uses specific image processing algorithms to extract relevant information from the chart images. Our proposed system achieves an accuracy of 99.72% in classifying the charts and an accuracy of 78.9% in extracting the data and creating the corresponding textual description.
High-throughput Onboard Hyperspectral Image Compression with Ground-based CNN Reconstruction
Jul 05, 2019
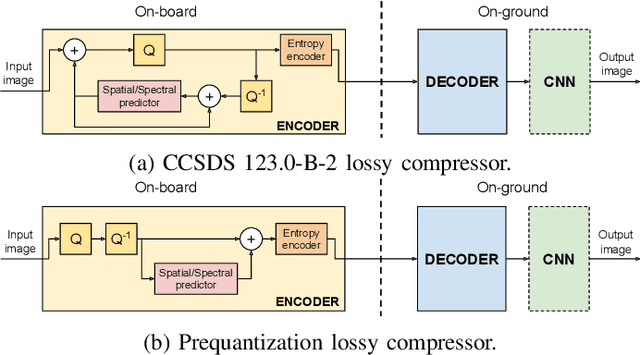
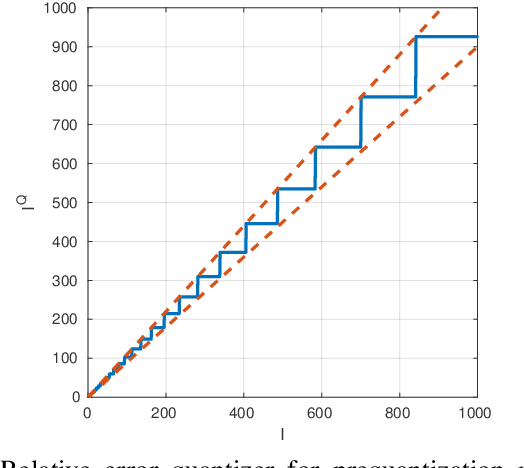
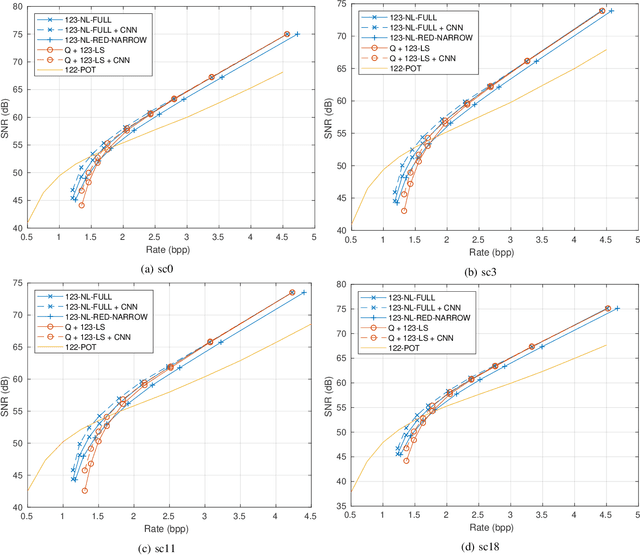
Compression of hyperspectral images onboard of spacecrafts is a tradeoff between the limited computational resources and the ever-growing spatial and spectral resolution of the optical instruments. As such, it requires low-complexity algorithms with good rate-distortion performance and high throughput. In recent years, the Consultative Committee for Space Data Systems (CCSDS) has focused on lossless and near-lossless compression approaches based on predictive coding, resulting in the recently published CCSDS 123.0-B-2 recommended standard. While the in-loop reconstruction of quantized prediction residuals provides excellent rate-distortion performance for the near-lossless operating mode, it significantly constrains the achievable throughput due to data dependencies. In this paper, we study the performance of a faster method based on prequantization of the image followed by a lossless predictive compressor. While this is well known to be suboptimal, one can exploit powerful signal models to reconstruct the image at the ground segment, recovering part of the suboptimality. In particular, we show that convolutional neural networks can be used for this task and that they can recover the whole SNR drop incurred at a bitrate of 2 bits per pixel.
EEG-GNN: Graph Neural Networks for Classification of Electroencephalogram (EEG) Signals
Jun 16, 2021



Convolutional neural networks (CNN) have been frequently used to extract subject-invariant features from electroencephalogram (EEG) for classification tasks. This approach holds the underlying assumption that electrodes are equidistant analogous to pixels of an image and hence fails to explore/exploit the complex functional neural connectivity between different electrode sites. We overcome this limitation by tailoring the concepts of convolution and pooling applied to 2D grid-like inputs for the functional network of electrode sites. Furthermore, we develop various graph neural network (GNN) models that project electrodes onto the nodes of a graph, where the node features are represented as EEG channel samples collected over a trial, and nodes can be connected by weighted/unweighted edges according to a flexible policy formulated by a neuroscientist. The empirical evaluations show that our proposed GNN-based framework outperforms standard CNN classifiers across ErrP, and RSVP datasets, as well as allowing neuroscientific interpretability and explainability to deep learning methods tailored to EEG related classification problems. Another practical advantage of our GNN-based framework is that it can be used in EEG channel selection, which is critical for reducing computational cost, and designing portable EEG headsets.
On Enhancing Ground Surface Detection from Sparse Lidar Point Cloud
May 25, 2021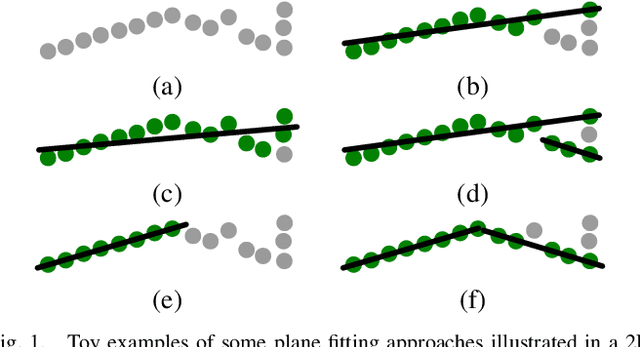
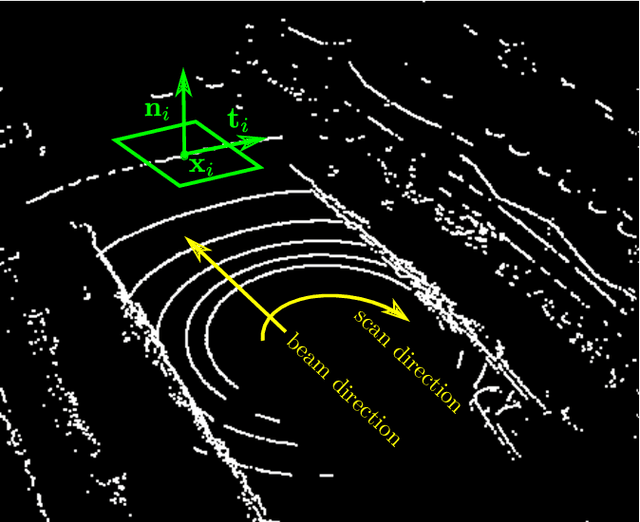
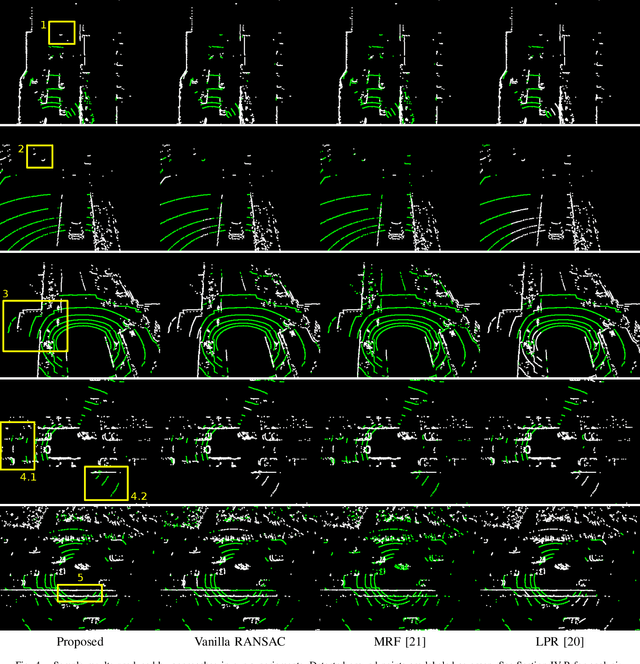
Ground surface detection in point cloud is widely used as a key module in autonomous driving systems. Different from previous approaches which are mostly developed for lidars with high beam resolution, e.g. Velodyne HDL-64, this paper proposes ground detection techniques applicable to much sparser point cloud captured by lidars with low beam resolution, e.g. Velodyne VLP-16. The approach is based on the RANSAC scheme of plane fitting. Inlier verification for plane hypotheses is enhanced by exploiting the point-wise tangent, which is a local feature available to compute regardless of the density of lidar beams. Ground surface which is not perfectly planar is fitted by multiple (specifically 4 in our implementation) disjoint plane regions. By assuming these plane regions to be rectanglar and exploiting the integral image technique, our approach approximately finds the optimal region partition and plane hypotheses under the RANSAC scheme with real-time computational complexity.
A Simple and Strong Baseline: Progressively Region-based Scene Text Removal Networks
Jun 24, 2021
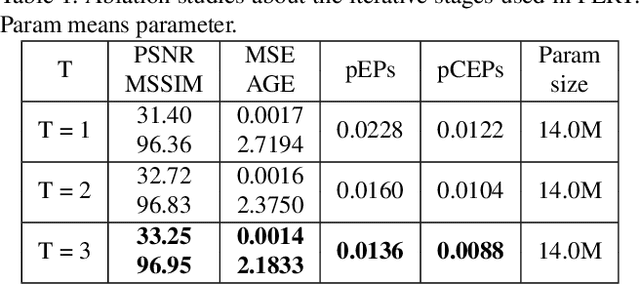
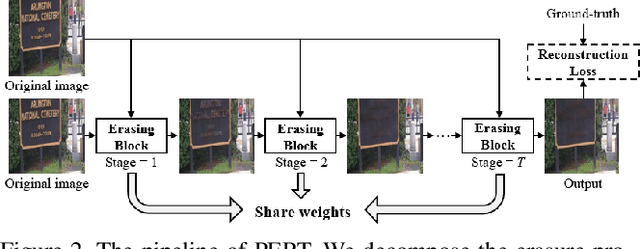
Existing scene text removal methods mainly train an elaborate network with paired images to realize the function of text localization and background reconstruction simultaneously, but there exists two problems: 1) lacking the exhaustive erasure of text region and 2) causing the excessive erasure to text-free areas. To handle these issues, this paper provides a novel ProgrEssively Region-based scene Text eraser (PERT), which introduces region-based modification strategy to progressively erase the pixels in only text region. Firstly, PERT decomposes the STR task to several erasing stages. As each stage aims to take a further step toward the text-removed image rather than directly regress to the final result, the decomposed operation reduces the learning difficulty in each stage, and an exhaustive erasure result can be obtained by iterating over lightweight erasing blocks with shared parameters. Then, PERT introduces a region-based modification strategy to ensure the integrity of text-free areas by decoupling text localization from erasure process to guide the removal. Benefiting from the simplicity architecture, PERT is a simple and strong baseline, and is easy to be followed and developed. Extensive experiments demonstrate that PERT obtains the state-of-the-art results on both synthetic and real-world datasets. Code is available athttps://github.com/wangyuxin87/PERT.
GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation
Mar 08, 2021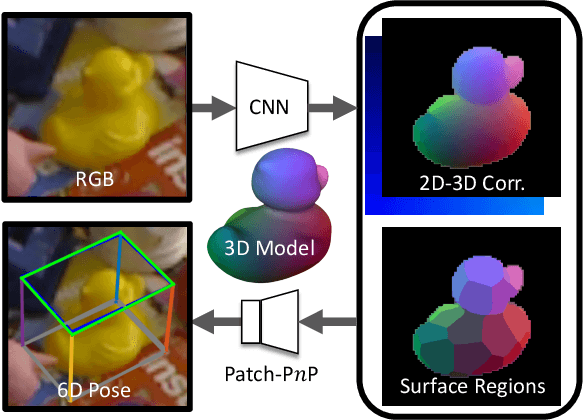
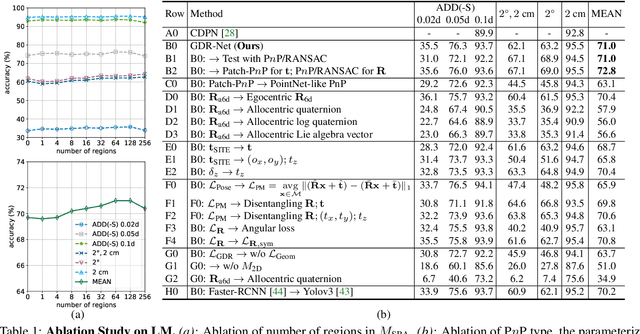
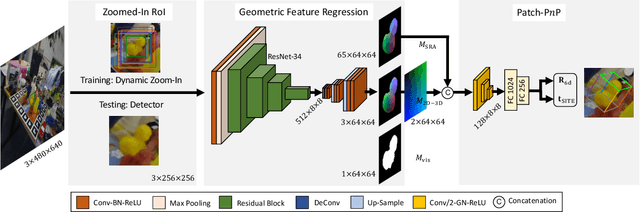
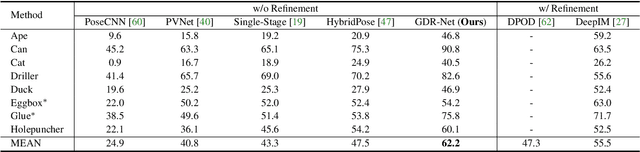
6D pose estimation from a single RGB image is a fundamental task in computer vision. The current top-performing deep learning-based methods rely on an indirect strategy, i.e., first establishing 2D-3D correspondences between the coordinates in the image plane and object coordinate system, and then applying a variant of the P$n$P/RANSAC algorithm. However, this two-stage pipeline is not end-to-end trainable, thus is hard to be employed for many tasks requiring differentiable poses. On the other hand, methods based on direct regression are currently inferior to geometry-based methods. In this work, we perform an in-depth investigation on both direct and indirect methods, and propose a simple yet effective Geometry-guided Direct Regression Network (GDR-Net) to learn the 6D pose in an end-to-end manner from dense correspondence-based intermediate geometric representations. Extensive experiments show that our approach remarkably outperforms state-of-the-art methods on LM, LM-O and YCB-V datasets. Code is available at https://git.io/GDR-Net.