 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Active Covering
Jun 04, 2021

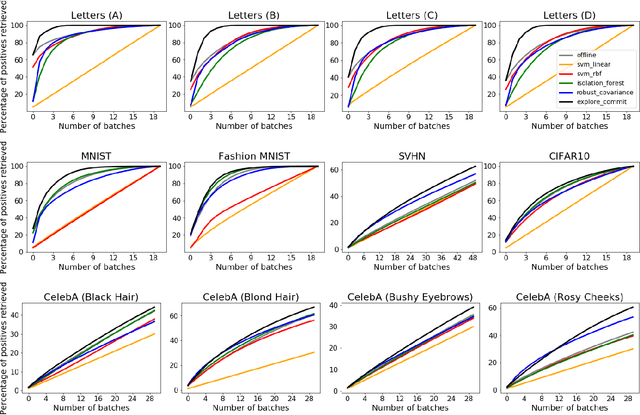
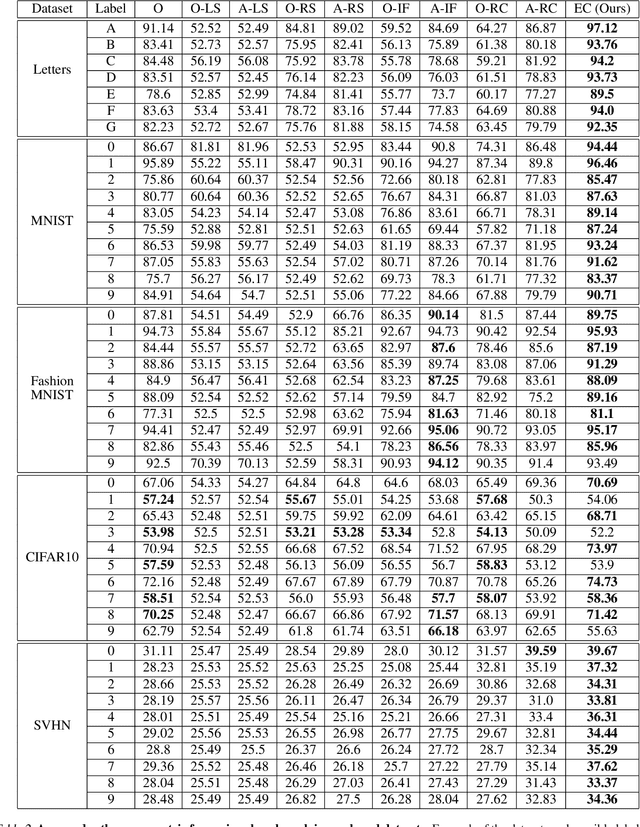
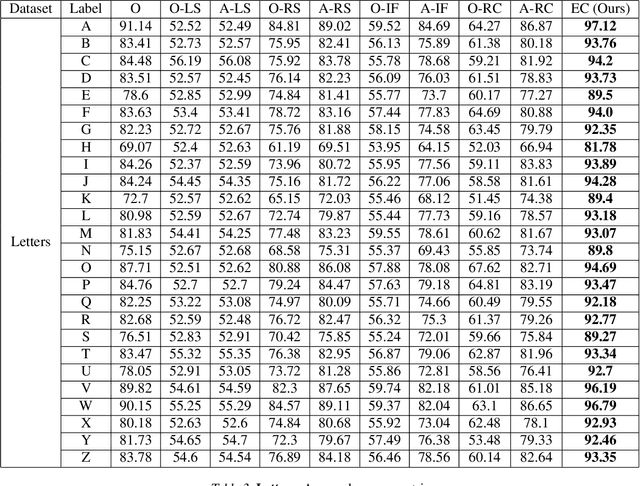
We analyze the problem of active covering, where the learner is given an unlabeled dataset and can sequentially label query examples. The objective is to label query all of the positive examples in the fewest number of total label queries. We show under standard non-parametric assumptions that a classical support estimator can be repurposed as an offline algorithm attaining an excess query cost of $\widetilde{\Theta}(n^{D/(D+1)})$ compared to the optimal learner, where $n$ is the number of datapoints and $D$ is the dimension. We then provide a simple active learning method that attains an improved excess query cost of $\widetilde{O}(n^{(D-1)/D})$. Furthermore, the proposed algorithms only require access to the positive labeled examples, which in certain settings provides additional computational and privacy benefits. Finally, we show that the active learning method consistently outperforms offline methods as well as a variety of baselines on a wide range of benchmark image-based datasets.
Decomposition-Based Transfer Distance Metric Learning for Image Classification
Apr 08, 2019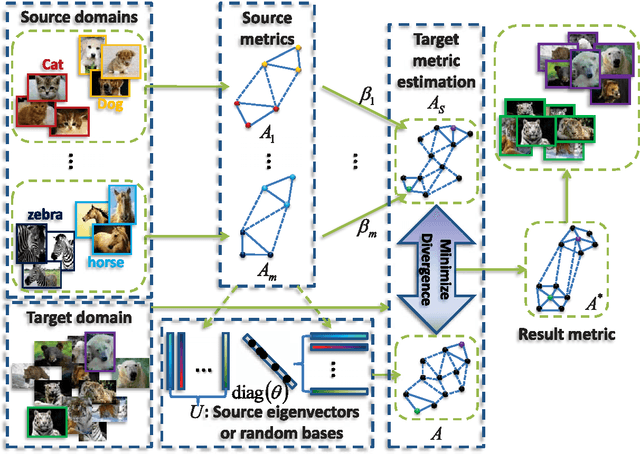
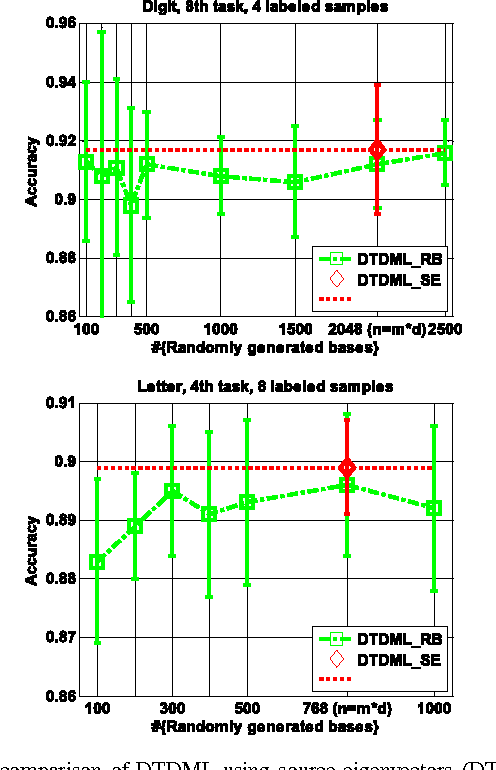
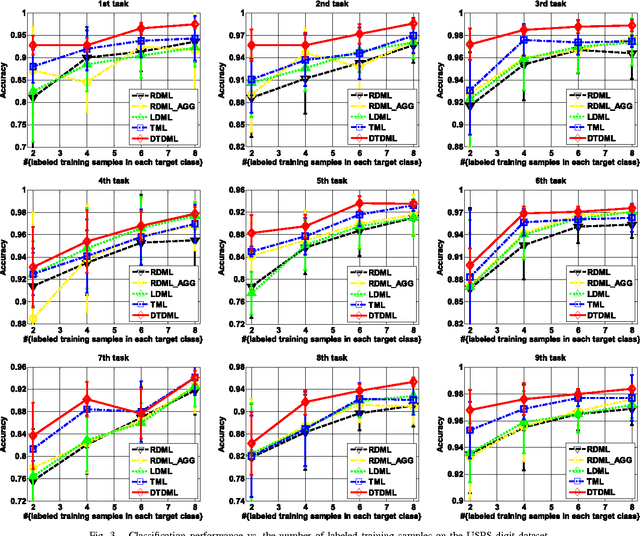
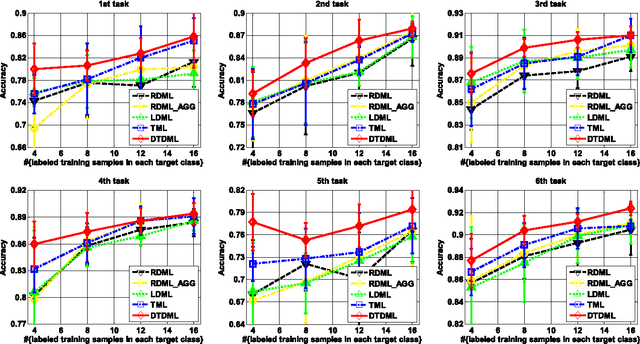
Distance metric learning (DML) is a critical factor for image analysis and pattern recognition. To learn a robust distance metric for a target task, we need abundant side information (i.e., the similarity/dissimilarity pairwise constraints over the labeled data), which is usually unavailable in practice due to the high labeling cost. This paper considers the transfer learning setting by exploiting the large quantity of side information from certain related, but different source tasks to help with target metric learning (with only a little side information). The state-of-the-art metric learning algorithms usually fail in this setting because the data distributions of the source task and target task are often quite different. We address this problem by assuming that the target distance metric lies in the space spanned by the eigenvectors of the source metrics (or other randomly generated bases). The target metric is represented as a combination of the base metrics, which are computed using the decomposed components of the source metrics (or simply a set of random bases); we call the proposed method, decomposition-based transfer DML (DTDML). In particular, DTDML learns a sparse combination of the base metrics to construct the target metric by forcing the target metric to be close to an integration of the source metrics. The main advantage of the proposed method compared with existing transfer metric learning approaches is that we directly learn the base metric coefficients instead of the target metric. To this end, far fewer variables need to be learned. We therefore obtain more reliable solutions given the limited side information and the optimization tends to be faster. Experiments on the popular handwritten image (digit, letter) classification and challenge natural image annotation tasks demonstrate the effectiveness of the proposed method.
SHD360: A Benchmark Dataset for Salient Human Detection in 360° Videos
Jun 04, 2021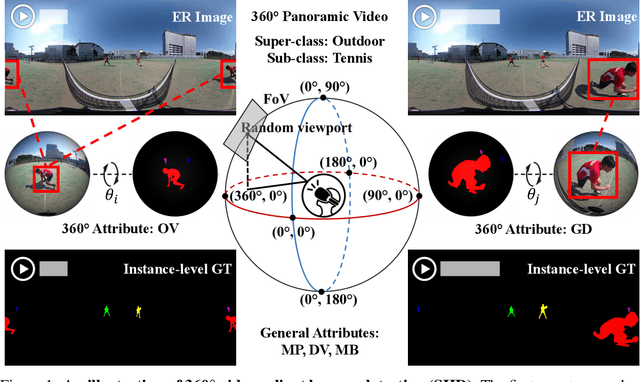
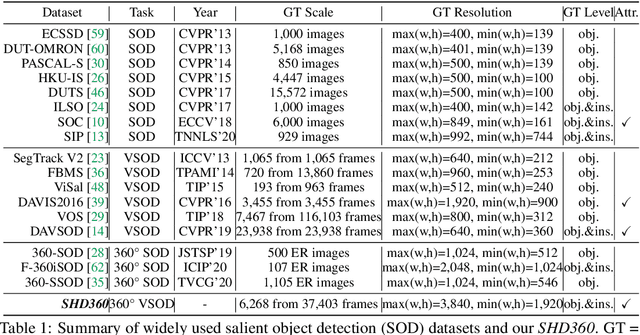
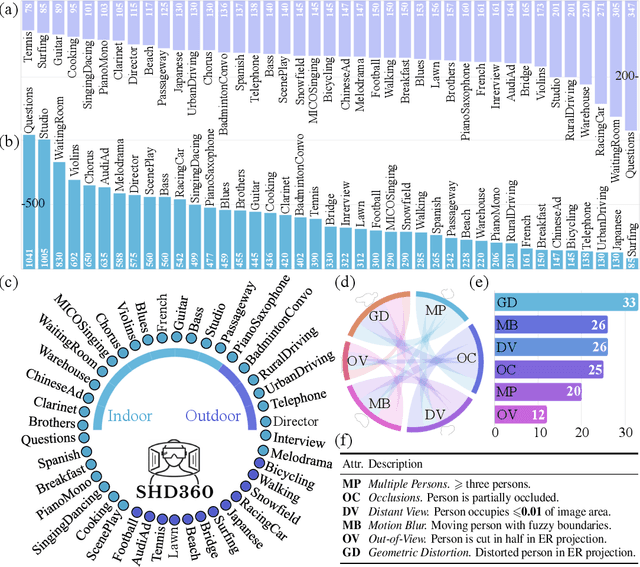
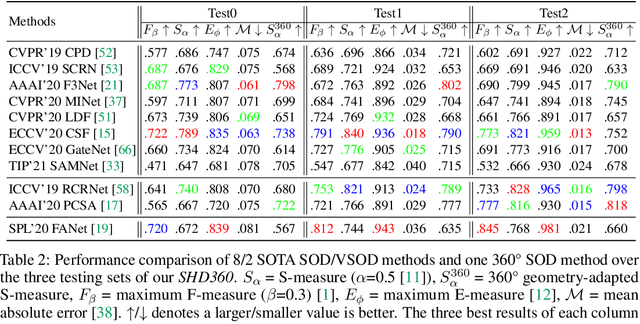
Salient human detection (SHD) in dynamic 360{\deg} immersive videos is of great importance for various applications such as robotics, inter-human and human-object interaction in augmented reality. However, 360{\deg} video SHD has been seldom discussed in the computer vision community due to a lack of datasets with large-scale omnidirectional videos and rich annotations. To this end, we propose SHD360, the first 360{\deg} video SHD dataset containing various real-life daily scenes borrowed from http://hidden.for.anonymity, with hierarchical annotations for 6,268 key frames uniformly sampled from 37,403 omnidirectional video frames at 4K resolution. Since so far there is no method proposed for 360{\deg} image/video SHD, we systematically benchmark 11 representative state-of-the-art salient object detection approaches on our SHD360. We hope our proposed dataset and benchmark could serve as a good starting point for advancing human-centric researches towards 360{\deg} panoramic data. Our dataset and benchmark will be publicly available at https://github.com/PanoAsh/SHD360.
User-driven mobile robot storyboarding: Learning image interest and saliency from pairwise image comparisons
Jun 19, 2017
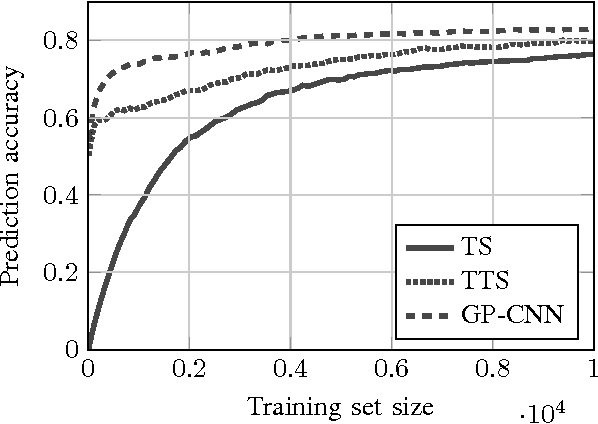
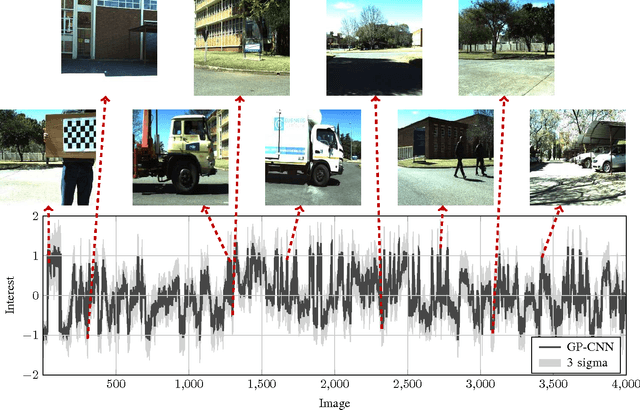

This paper describes a novel storyboarding scheme that uses a model trained on pairwise image comparisons to identify images likely to be of interest to a mobile robot user. Traditional storyboarding schemes typically attempt to summarise robot observations using predefined novelty or image quality objectives, but we propose a user training stage that allows the incorporation of user interest when storyboarding. Our approach dramatically reduces the number of image comparisons required to infer image interest by applying a Gaussian process smoothing algorithm on image features extracted using a pre-trained convolutional neural network. As a particularly valuable by-product, the proposed approach allows the generation of user-specific saliency or attention maps.
Semi-supervised FusedGAN for Conditional Image Generation
Jan 17, 2018
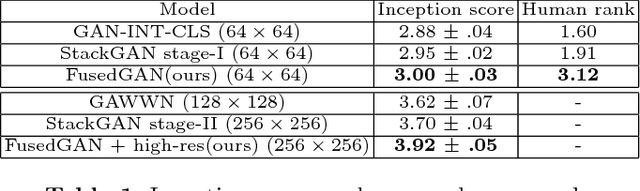
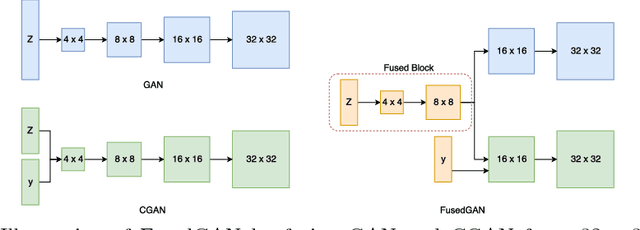

We present FusedGAN, a deep network for conditional image synthesis with controllable sampling of diverse images. Fidelity, diversity and controllable sampling are the main quality measures of a good image generation model. Most existing models are insufficient in all three aspects. The FusedGAN can perform controllable sampling of diverse images with very high fidelity. We argue that controllability can be achieved by disentangling the generation process into various stages. In contrast to stacked GANs, where multiple stages of GANs are trained separately with full supervision of labeled intermediate images, the FusedGAN has a single stage pipeline with a built-in stacking of GANs. Unlike existing methods, which requires full supervision with paired conditions and images, the FusedGAN can effectively leverage more abundant images without corresponding conditions in training, to produce more diverse samples with high fidelity. We achieve this by fusing two generators: one for unconditional image generation, and the other for conditional image generation, where the two partly share a common latent space thereby disentangling the generation. We demonstrate the efficacy of the FusedGAN in fine grained image generation tasks such as text-to-image, and attribute-to-face generation.
CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents
May 28, 2020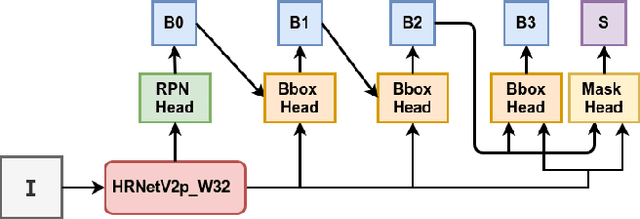
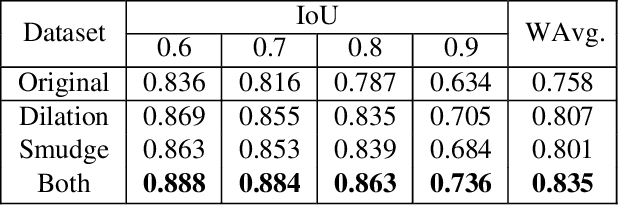
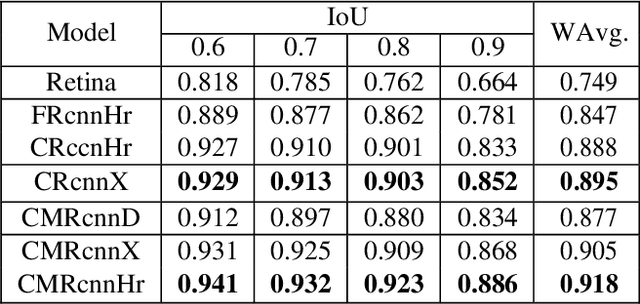
An automatic table recognition method for interpretation of tabular data in document images majorly involves solving two problems of table detection and table structure recognition. The prior work involved solving both problems independently using two separate approaches. More recent works signify the use of deep learning-based solutions while also attempting to design an end to end solution. In this paper, we present an improved deep learning-based end to end approach for solving both problems of table detection and structure recognition using a single Convolution Neural Network (CNN) model. We propose CascadeTabNet: a Cascade mask Region-based CNN High-Resolution Network (Cascade mask R-CNN HRNet) based model that detects the regions of tables and recognizes the structural body cells from the detected tables at the same time. We evaluate our results on ICDAR 2013, ICDAR 2019 and TableBank public datasets. We achieved 3rd rank in ICDAR 2019 post-competition results for table detection while attaining the best accuracy results for the ICDAR 2013 and TableBank dataset. We also attain the highest accuracy results on the ICDAR 2019 table structure recognition dataset. Additionally, we demonstrate effective transfer learning and image augmentation techniques that enable CNNs to achieve very accurate table detection results. Code and dataset has been made available at: https://github.com/DevashishPrasad/CascadeTabNet
Ice Core Science Meets Computer Vision: Challenges and Perspectives
Apr 09, 2021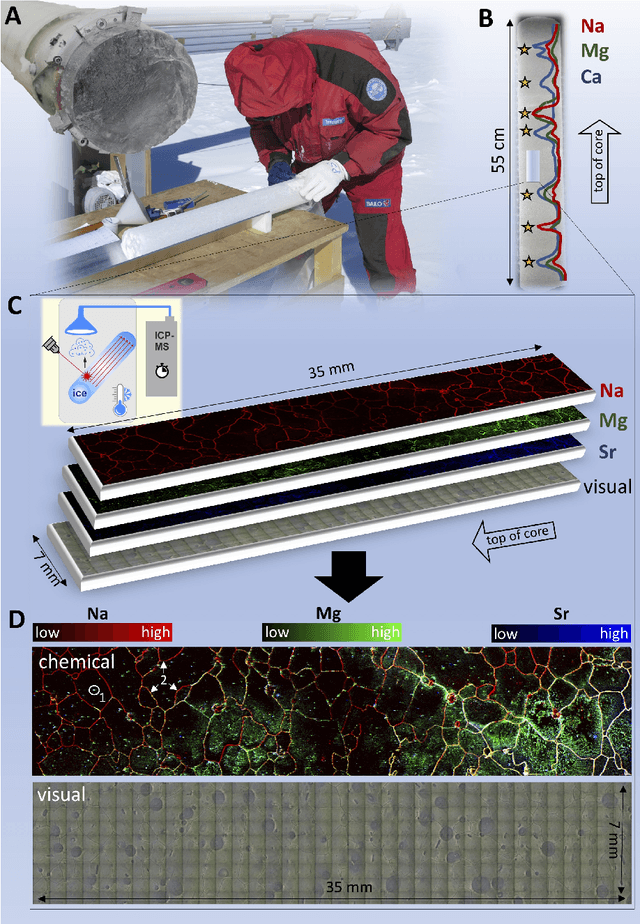
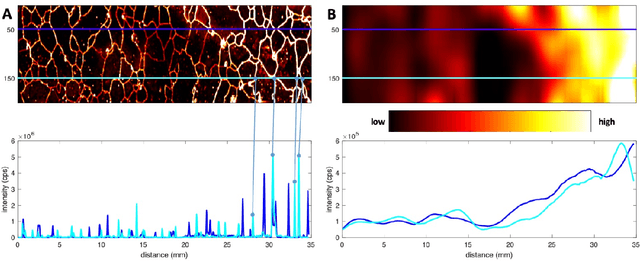
Polar ice cores play a central role in studies of the earth's climate system through natural archives. A pressing issue is the analysis of the oldest, highly thinned ice core sections, where the identification of paleoclimate signals is particularly challenging. For this, state-of-the-art imaging by laser-ablation inductively-coupled plasma mass spectrometry (LA-ICP-MS) has the potential to be revolutionary due to its combination of micron-scale 2D chemical information with visual features. However, the quantitative study of record preservation in chemical images raises new questions that call for the expertise of the computer vision community. To illustrate this new inter-disciplinary frontier, we describe a selected set of key questions. One critical task is to assess the paleoclimate significance of single line profiles along the main core axis, which we show is a scale-dependent problem for which advanced image analysis methods are critical. Another important issue is the evaluation of post-depositional layer changes, for which the chemical images provide rich information. Accordingly, the time is ripe to begin an intensified exchange among the two scientific communities of computer vision and ice core science. The collaborative building of a new framework for investigating high-resolution chemical images with automated image analysis techniques will also benefit the already wide-spread application of LA-ICP-MS chemical imaging in the geosciences.
FPS-Net: A Convolutional Fusion Network for Large-Scale LiDAR Point Cloud Segmentation
Mar 01, 2021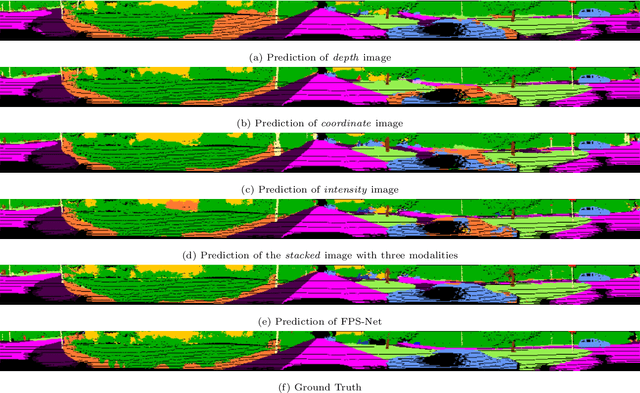
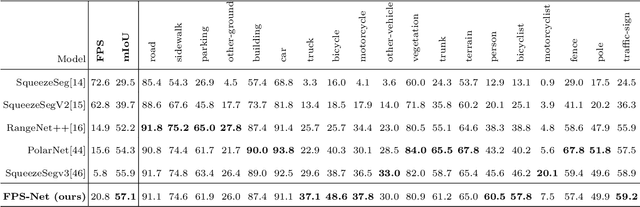
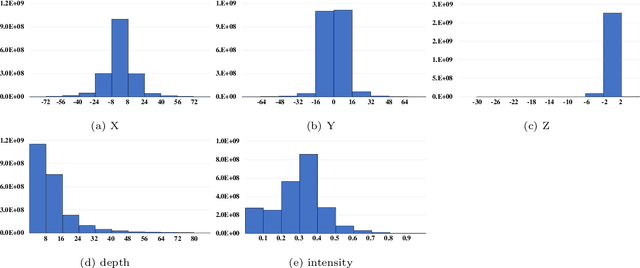
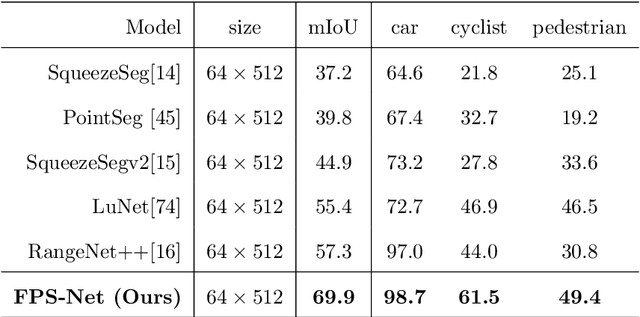
Scene understanding based on LiDAR point cloud is an essential task for autonomous cars to drive safely, which often employs spherical projection to map 3D point cloud into multi-channel 2D images for semantic segmentation. Most existing methods simply stack different point attributes/modalities (e.g. coordinates, intensity, depth, etc.) as image channels to increase information capacity, but ignore distinct characteristics of point attributes in different image channels. We design FPS-Net, a convolutional fusion network that exploits the uniqueness and discrepancy among the projected image channels for optimal point cloud segmentation. FPS-Net adopts an encoder-decoder structure. Instead of simply stacking multiple channel images as a single input, we group them into different modalities to first learn modality-specific features separately and then map the learned features into a common high-dimensional feature space for pixel-level fusion and learning. Specifically, we design a residual dense block with multiple receptive fields as a building block in the encoder which preserves detailed information in each modality and learns hierarchical modality-specific and fused features effectively. In the FPS-Net decoder, we use a recurrent convolution block likewise to hierarchically decode fused features into output space for pixel-level classification. Extensive experiments conducted on two widely adopted point cloud datasets show that FPS-Net achieves superior semantic segmentation as compared with state-of-the-art projection-based methods. In addition, the proposed modality fusion idea is compatible with typical projection-based methods and can be incorporated into them with consistent performance improvements.
The Chan-Vese Model with Elastica and Landmark Constraints for Image Segmentation
May 27, 2019
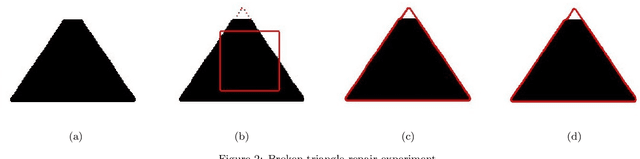
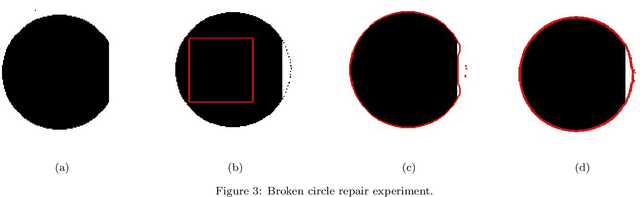
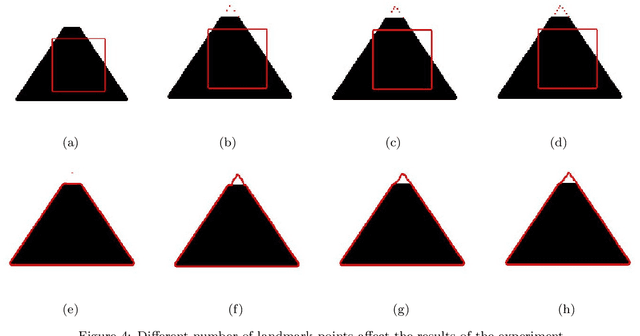
In order to separate completely the objects with larger occluded boundaries in an image, we devise a new variational level set model for image segmentation combing the recently proposed Chan-Vese-Euler model with elastica and landmark constraints. For computational efficiency, we deign its Augmented Lagrangian Method(ALM) or Alternating Direction Method of Multiplier(ADMM) method by introducing some auxiliary variables, Lagrange multipliers and penalty parameters. In each loop of alternating iterative optimization, the sub-problems of minimization can be solved via simple Gauss-Seidel iterative method, or generalized soft thresholding formulas with projection methods respectively. Numerical experiments show that the proposed model not only can recover larger broken boundaries, but also can improve segmentation efficiency, decrease the dependence of segmentation on tuning parameters and initialization.
Conditional Meta-Network for Blind Super-Resolution with Multiple Degradations
Apr 09, 2021


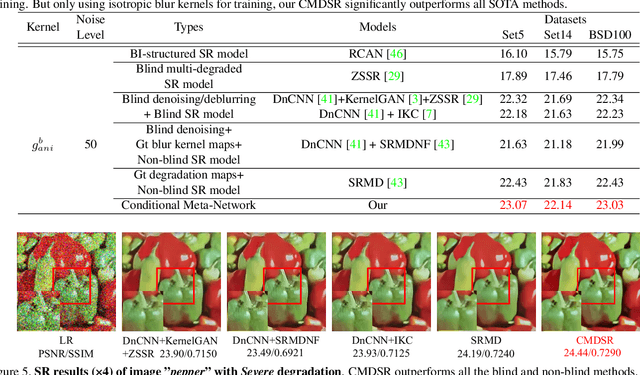
Although single-image super-resolution (SISR) methods have achieved great success on single degradation, they still suffer performance drop with multiple degrading effects in real scenarios. Recently, some blind and non-blind models for multiple degradations have been explored. However, those methods usually degrade significantly for distribution shifts between the training and test data. Towards this end, we propose a conditional meta-network framework (named CMDSR) for the first time, which helps SR framework learn how to adapt to changes in input distribution. We extract degradation prior at task-level with the proposed ConditionNet, which will be used to adapt the parameters of the basic SR network (BaseNet). Specifically, the ConditionNet of our framework first learns the degradation prior from a support set, which is composed of a series of degraded image patches from the same task. Then the adaptive BaseNet rapidly shifts its parameters according to the conditional features. Moreover, in order to better extract degradation prior, we propose a task contrastive loss to decrease the inner-task distance and increase the cross-task distance between task-level features. Without predefining degradation maps, our blind framework can conduct one single parameter update to yield considerable SR results. Extensive experiments demonstrate the effectiveness of CMDSR over various blind, even non-blind methods. The flexible BaseNet structure also reveals that CMDSR can be a general framework for large series of SISR models.