 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hierarchical Phenotyping and Graph Modeling of Spatial Architecture in Lymphoid Neoplasms
Jun 30, 2021

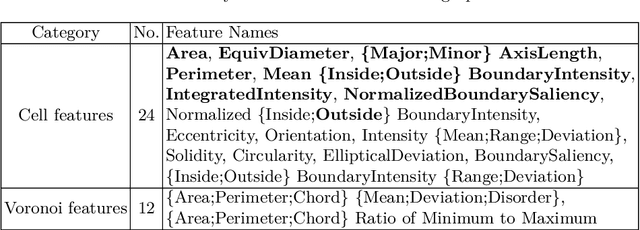
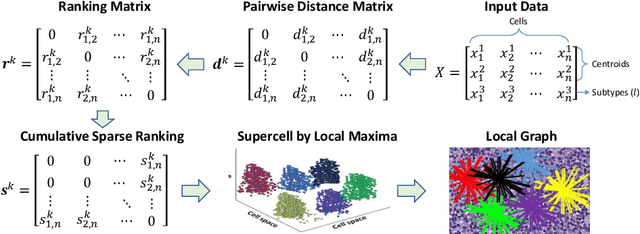
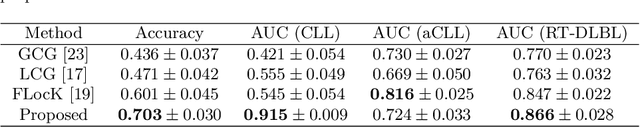
The cells and their spatial patterns in the tumor microenvironment (TME) play a key role in tumor evolution, and yet remains an understudied topic in computational pathology. This study, to the best of our knowledge, is among the first to hybrid local and global graph methods to profile orchestration and interaction of cellular components. To address the challenge in hematolymphoid cancers where the cell classes in TME are unclear, we first implemented cell level unsupervised learning and identified two new cell subtypes. Local cell graphs or supercells were built for each image by considering the individual cell's geospatial location and classes. Then, we applied supercell level clustering and identified two new cell communities. In the end, we built global graphs to abstract spatial interaction patterns and extract features for disease diagnosis. We evaluate the proposed algorithm on H\&E slides of 60 hematolymphoid neoplasm patients and further compared it with three cell level graph-based algorithms, including the global cell graph, cluster cell graph, and FLocK. The proposed algorithm achieves a mean diagnosis accuracy of 0.703 with the repeated 5-fold cross-validation scheme. In conclusion, our algorithm shows superior performance over the existing methods and can be potentially applied to other cancer types.
Selective Replay Enhances Learning in Online Continual Analogical Reasoning
Mar 06, 2021
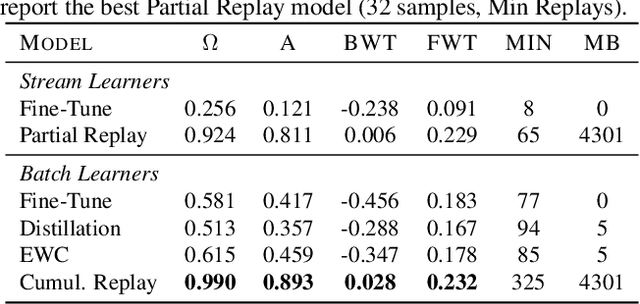

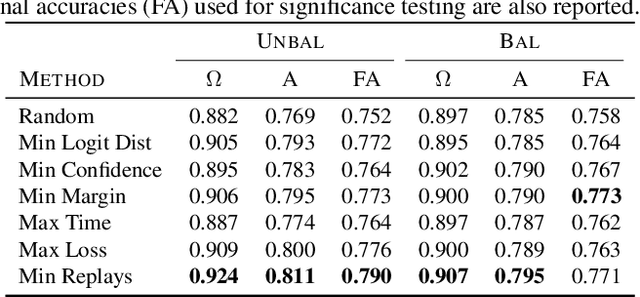
In continual learning, a system learns from non-stationary data streams or batches without catastrophic forgetting. While this problem has been heavily studied in supervised image classification and reinforcement learning, continual learning in neural networks designed for abstract reasoning has not yet been studied. Here, we study continual learning of analogical reasoning. Analogical reasoning tests such as Raven's Progressive Matrices (RPMs) are commonly used to measure non-verbal abstract reasoning in humans, and recently offline neural networks for the RPM problem have been proposed. In this paper, we establish experimental baselines, protocols, and forward and backward transfer metrics to evaluate continual learners on RPMs. We employ experience replay to mitigate catastrophic forgetting. Prior work using replay for image classification tasks has found that selectively choosing the samples to replay offers little, if any, benefit over random selection. In contrast, we find that selective replay can significantly outperform random selection for the RPM task.
Automatically eliminating seam lines with Poisson editing in complex relative radiometric normalization mosaicking scenarios
Jun 14, 2021Relative radiometric normalization (RRN) mosaicking among multiple remote sensing images is crucial for the downstream tasks, including map-making, image recognition, semantic segmentation, and change detection. However, there are often seam lines on the mosaic boundary and radiometric contrast left, especially in complex scenarios, making the appearance of mosaic images unsightly and reducing the accuracy of the latter classification/recognition algorithms. This paper renders a novel automatical approach to eliminate seam lines in complex RRN mosaicking scenarios. It utilizes the histogram matching on the overlap area to alleviate radiometric contrast, Poisson editing to remove the seam lines, and merging procedure to determine the normalization transfer order. Our method can handle the mosaicking seam lines with arbitrary shapes and images with extreme topological relationships (with a small intersection area). These conditions make the main feathering or blending methods, e.g., linear weighted blending and Laplacian pyramid blending, unavailable. In the experiment, our approach visually surpasses the automatic methods without Poisson editing and the manual blurring and feathering method using GIMP software.
CRASH: Raw Audio Score-based Generative Modeling for Controllable High-resolution Drum Sound Synthesis
Jun 14, 2021
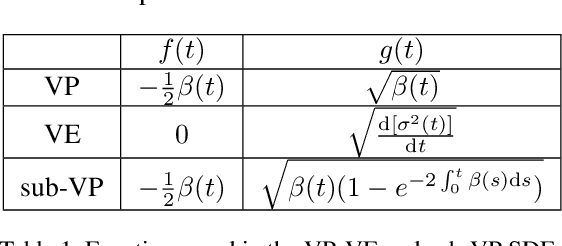
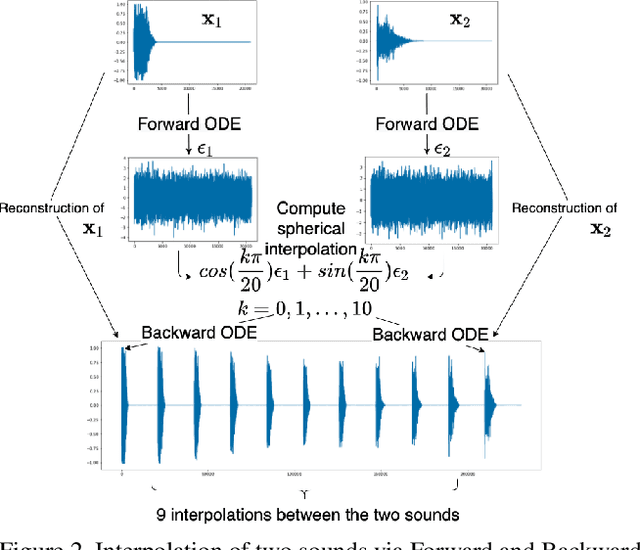

In this paper, we propose a novel score-base generative model for unconditional raw audio synthesis. Our proposal builds upon the latest developments on diffusion process modeling with stochastic differential equations, which already demonstrated promising results on image generation. We motivate novel heuristics for the choice of the diffusion processes better suited for audio generation, and consider the use of a conditional U-Net to approximate the score function. While previous approaches on diffusion models on audio were mainly designed as speech vocoders in medium resolution, our method termed CRASH (Controllable Raw Audio Synthesis with High-resolution) allows us to generate short percussive sounds in 44.1kHz in a controllable way. Through extensive experiments, we showcase on a drum sound generation task the numerous sampling schemes offered by our method (unconditional generation, deterministic generation, inpainting, interpolation, variations, class-conditional sampling) and propose the class-mixing sampling, a novel way to generate "hybrid" sounds. Our proposed method closes the gap with GAN-based methods on raw audio, while offering more flexible generation capabilities with lighter and easier-to-train models.
Time Series Imaging for Link Layer Anomaly Classification in Wireless Networks
Apr 02, 2021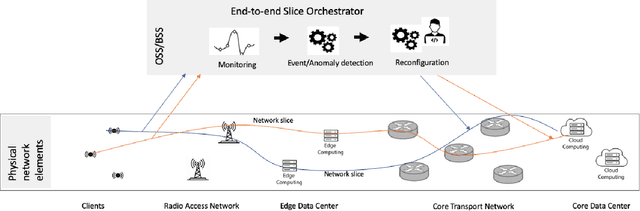


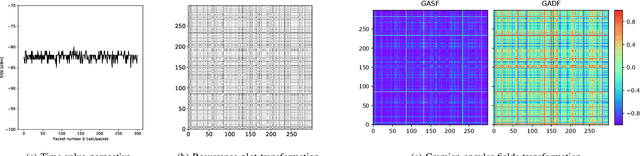
The number of end devices that use the last mile wireless connectivity is dramatically increasing with the rise of smart infrastructures and require reliable functioning to support smooth and efficient business processes. To efficiently manage such massive wireless networks, more advanced and accurate network monitoring and malfunction detection solutions are required. In this paper, we perform a first time analysis of image-based representation techniques for wireless anomaly detection using recurrence plots and Gramian angular fields and propose a new deep learning architecture enabling accurate anomaly detection. We examine the relative performance of the proposed model and show that the image transformation of time series improves the performance of anomaly detection by up to 29% for binary classification and by up to 27% for multiclass classification. At the same time, the best performing model based on recurrence plot transformation leads to up to 55% increase compared to the state of the art where classical machine learning techniques are used. We also provide insights for the decisions of the classifier using an instance based approach enabled by insights into guided back-propagation. Our results demonstrate the potential of transformation of time series signals to images to improve classification performance compared to classification on raw time series data.
ODDObjects: A Framework for Multiclass Unsupervised Anomaly Detection on Masked Objects
Apr 26, 2021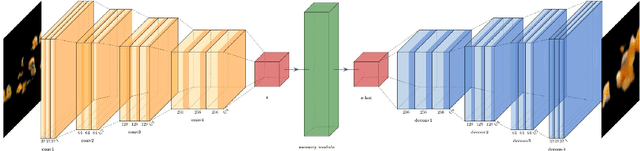



This paper presents a novel framework for unsupervised anomaly detection on masked objects called ODDObjects, which stands for Out-of-Distribution Detection on Objects. ODDObjects is designed to detect anomalies of various categories using unsupervised autoencoders trained on COCO-style datasets. The method utilizes autoencoder-based image reconstruction, where high reconstruction error indicates the possibility of an anomaly. The framework extends previous work on anomaly detection with autoencoders, comparing state-of-the-art models trained on object recognition datasets. Various model architectures were compared, and experimental results show that memory-augmented deep convolutional autoencoders perform the best at detecting out-of-distribution objects.
Automatic Head Overcoat Thickness Measure with NASNet-Large-Decoder Net
Jun 22, 2021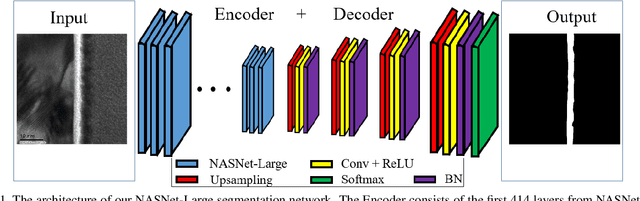
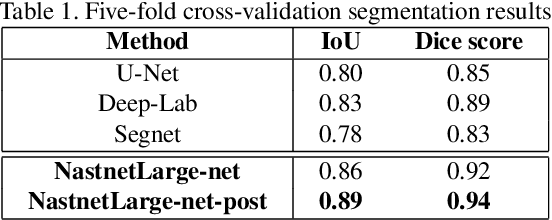
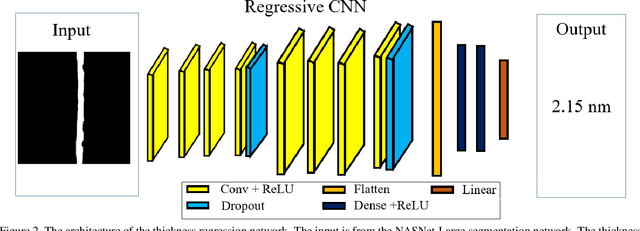
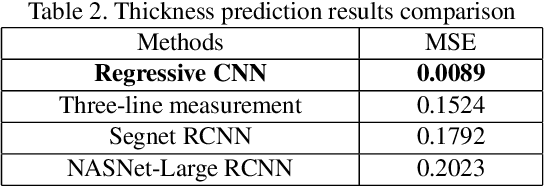
Transmission electron microscopy (TEM) is one of the primary tools to show microstructural characterization of materials as well as film thickness. However, manual determination of film thickness from TEM images is time-consuming as well as subjective, especially when the films in question are very thin and the need for measurement precision is very high. Such is the case for head overcoat (HOC) thickness measurements in the magnetic hard disk drive industry. It is therefore necessary to develop software to automatically measure HOC thickness. In this paper, for the first time, we propose a HOC layer segmentation method using NASNet-Large as an encoder and then followed by a decoder architecture, which is one of the most commonly used architectures in deep learning for image segmentation. To further improve segmentation results, we are the first to propose a post-processing layer to remove irrelevant portions in the segmentation result. To measure the thickness of the segmented HOC layer, we propose a regressive convolutional neural network (RCNN) model as well as orthogonal thickness calculation methods. Experimental results demonstrate a higher dice score for our model which has lower mean squared error and outperforms current state-of-the-art manual measurement.
A Variational Perspective on Diffusion-Based Generative Models and Score Matching
Jun 05, 2021


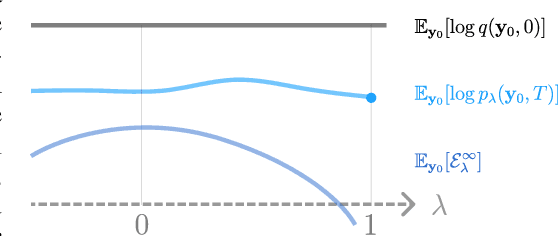
Discrete-time diffusion-based generative models and score matching methods have shown promising results in modeling high-dimensional image data. Recently, Song et al. (2021) show that diffusion processes that transform data into noise can be reversed via learning the score function, i.e. the gradient of the log-density of the perturbed data. They propose to plug the learned score function into an inverse formula to define a generative diffusion process. Despite the empirical success, a theoretical underpinning of this procedure is still lacking. In this work, we approach the (continuous-time) generative diffusion directly and derive a variational framework for likelihood estimation, which includes continuous-time normalizing flows as a special case, and can be seen as an infinitely deep variational autoencoder. Under this framework, we show that minimizing the score-matching loss is equivalent to maximizing a lower bound of the likelihood of the plug-in reverse SDE proposed by Song et al. (2021), bridging the theoretical gap.
Learning Nonparametric Human Mesh Reconstruction from a Single Image without Ground Truth Meshes
Feb 28, 2020
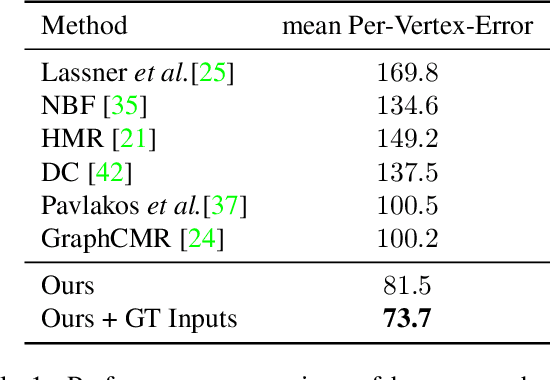
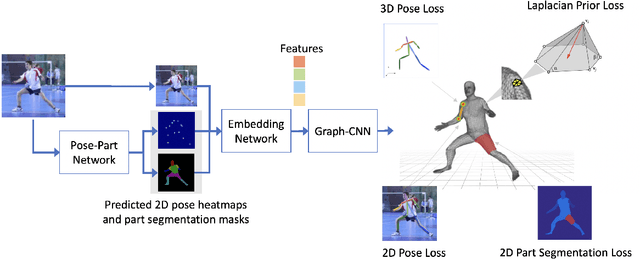

Nonparametric approaches have shown promising results on reconstructing 3D human mesh from a single monocular image. Unlike previous approaches that use a parametric human model like skinned multi-person linear model (SMPL), and attempt to regress the model parameters, nonparametric approaches relax the heavy reliance on the parametric space. However, existing nonparametric methods require ground truth meshes as their regression target for each vertex, and obtaining ground truth mesh labels is very expensive. In this paper, we propose a novel approach to learn human mesh reconstruction without any ground truth meshes. This is made possible by introducing two new terms into the loss function of a graph convolutional neural network (Graph CNN). The first term is the Laplacian prior that acts as a regularizer on the reconstructed mesh. The second term is the part segmentation loss that forces the projected region of the reconstructed mesh to match the part segmentation. Experimental results on multiple public datasets show that without using 3D ground truth meshes, the proposed approach outperforms the previous state-of-the-art approaches that require ground truth meshes for training.
Day-to-day and seasonal regularity of network passenger delay for metro networks
Jul 07, 2021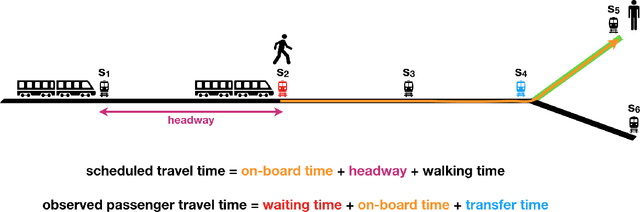
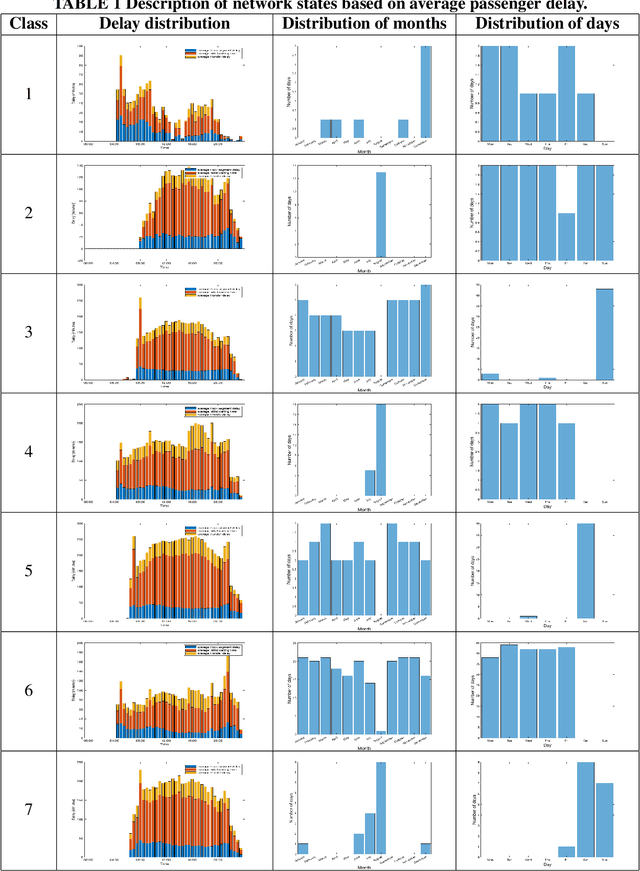
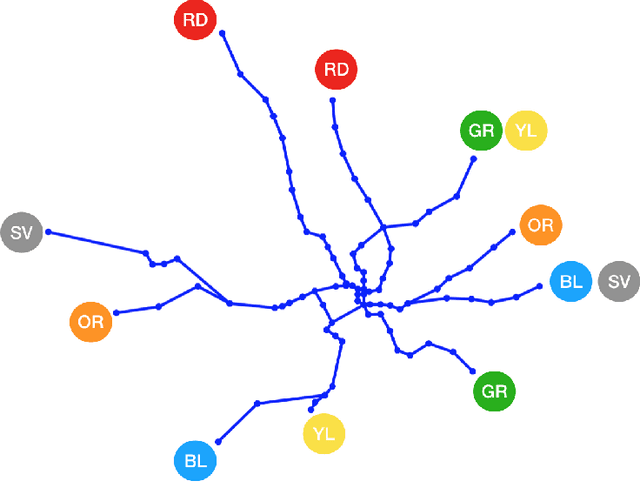
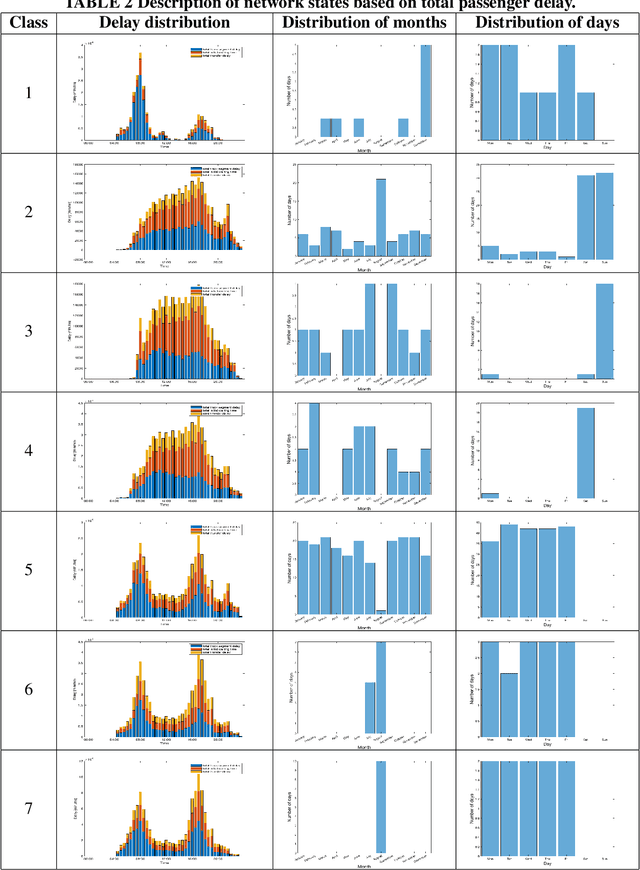
In an effort to improve user satisfaction and transit image, transit service providers worldwide offer delay compensations. Smart card data enables the estimation of passenger delays throughout the network and aid in monitoring service performance. Notwithstanding, in order to prioritize measures for improving service reliability and hence reducing passenger delays, it is paramount to identify the system components - stations and track segments - where most passenger delay occurs. To this end, we propose a novel method for estimating network passenger delay from individual trajectories. We decompose the delay along a passenger trajectory into its corresponding track segment delay, initial waiting time and transfer delay. We distinguish between two different types of passenger delay in relation to the public transit network: average passenger delay and total passenger delay. We employ temporal clustering on these two quantities to reveal daily and seasonal regularity in delay patterns of the transit network. The estimation and clustering methods are demonstrated on one year of data from Washington metro network. The data consists of schedule information and smart card data which includes passenger-train assignment of the metro network for the months of August 2017 to August 2018. Our findings show that the average passenger delay is relatively stable throughout the day. The temporal clustering reveals pronounced and recurrent and thus predictable daily and weekly patterns with distinct characteristics for certain months.