 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Differentially Private Federated Learning via Inexact ADMM
Jun 11, 2021

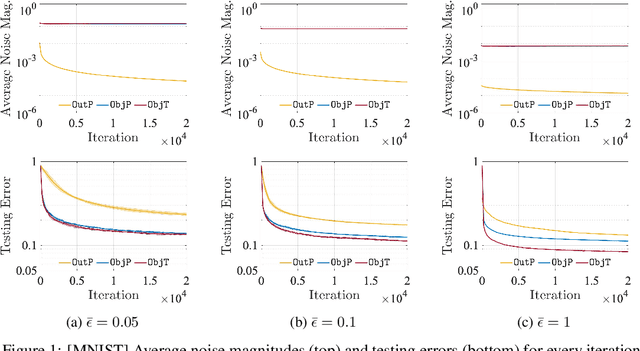
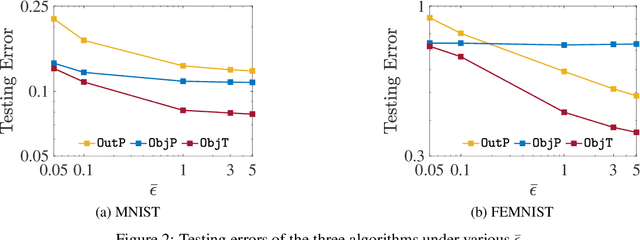
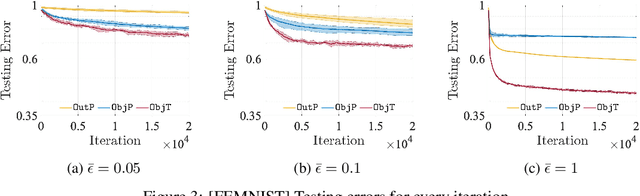
Differential privacy (DP) techniques can be applied to the federated learning model to protect data privacy against inference attacks to communication among the learning agents. The DP techniques, however, hinder achieving a greater learning performance while ensuring strong data privacy. In this paper we develop a DP inexact alternating direction method of multipliers algorithm that solves a sequence of trust-region subproblems with the objective perturbation by random noises generated from a Laplace distribution. We show that our algorithm provides $\bar{\epsilon}$-DP for every iteration and $\mathcal{O}(1/T)$ rate of convergence in expectation, where $T$ is the number of iterations. Using MNIST and FEMNIST datasets for the image classification, we demonstrate that our algorithm reduces the testing error by at most $22\%$ compared with the existing DP algorithm, while achieving the same level of data privacy. The numerical experiment also shows that our algorithm converges faster than the existing algorithm.
Survey of the Detection and Classification of Pulmonary Lesions via CT and X-Ray
Dec 31, 2020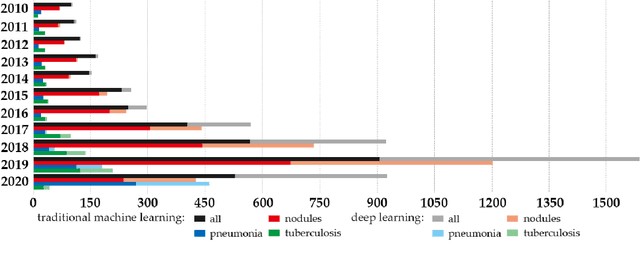
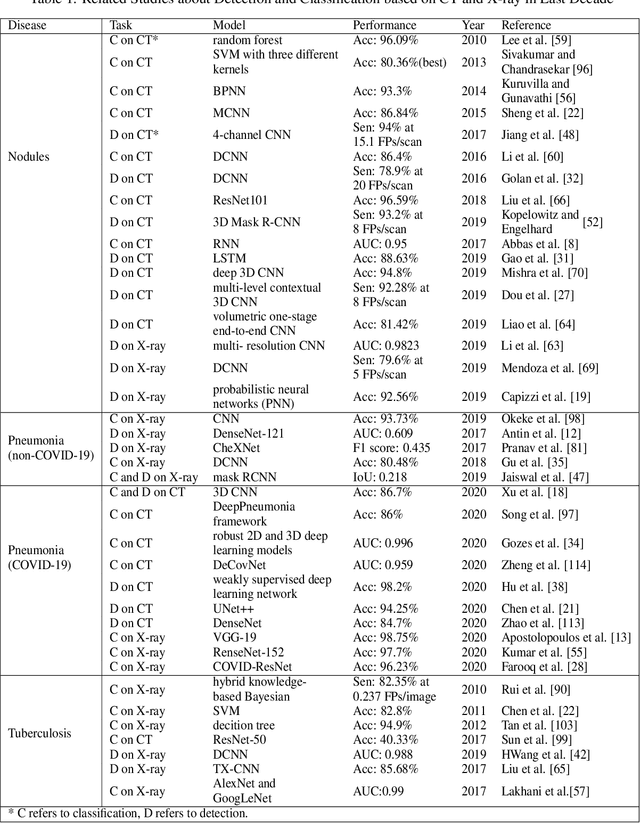
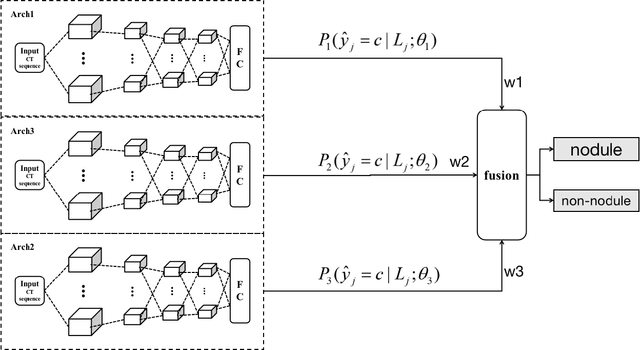
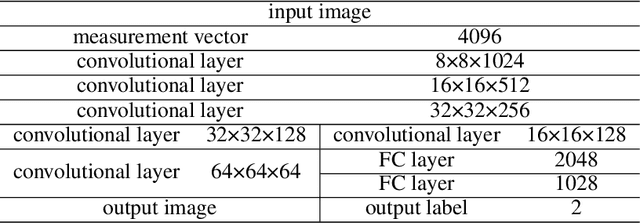
In recent years, the prevalence of several pulmonary diseases, especially the coronavirus disease 2019 (COVID-19) pandemic, has attracted worldwide attention. These diseases can be effectively diagnosed and treated with the help of lung imaging. With the development of deep learning technology and the emergence of many public medical image datasets, the diagnosis of lung diseases via medical imaging has been further improved. This article reviews pulmonary CT and X-ray image detection and classification in the last decade. It also provides an overview of the detection of lung nodules, pneumonia, and other common lung lesions based on the imaging characteristics of various lesions. Furthermore, this review introduces 26 commonly used public medical image datasets, summarizes the latest technology, and discusses current challenges and future research directions.
DG-Font: Deformable Generative Networks for Unsupervised Font Generation
Apr 08, 2021
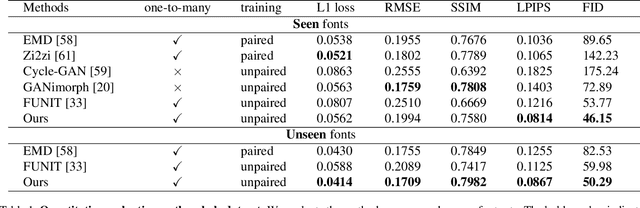
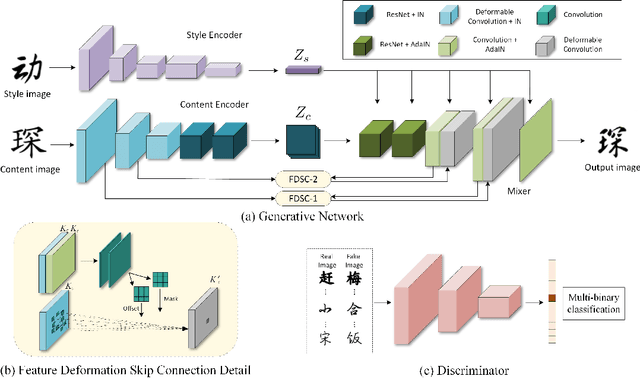

Font generation is a challenging problem especially for some writing systems that consist of a large number of characters and has attracted a lot of attention in recent years. However, existing methods for font generation are often in supervised learning. They require a large number of paired data, which is labor-intensive and expensive to collect. Besides, common image-to-image translation models often define style as the set of textures and colors, which cannot be directly applied to font generation. To address these problems, we propose novel deformable generative networks for unsupervised font generation (DGFont). We introduce a feature deformation skip connection (FDSC) which predicts pairs of displacement maps and employs the predicted maps to apply deformable convolution to the low-level feature maps from the content encoder. The outputs of FDSC are fed into a mixer to generate the final results. Taking advantage of FDSC, the mixer outputs a high-quality character with a complete structure. To further improve the quality of generated images, we use three deformable convolution layers in the content encoder to learn style-invariant feature representations. Experiments demonstrate that our model generates characters in higher quality than state-of-art methods. The source code is available at https://github.com/ecnuycxie/DG-Font.
Image Super-Resolution via Deterministic-Stochastic Synthesis and Local Statistical Rectification
Sep 18, 2018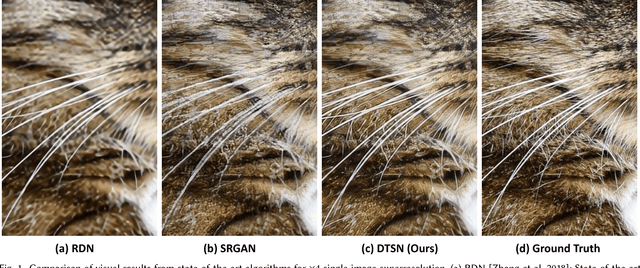
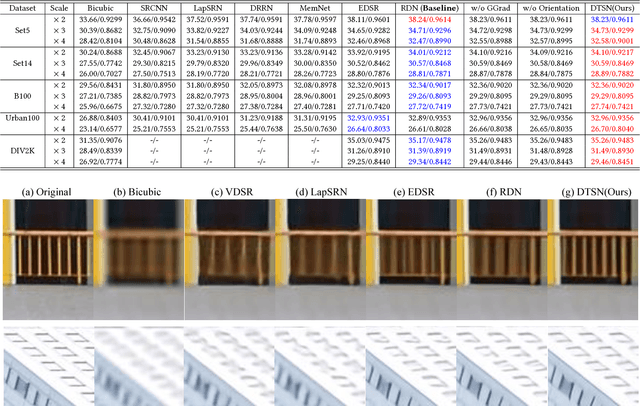

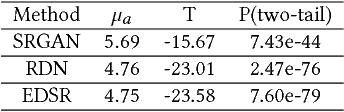
Single image superresolution has been a popular research topic in the last two decades and has recently received a new wave of interest due to deep neural networks. In this paper, we approach this problem from a different perspective. With respect to a downsampled low resolution image, we model a high resolution image as a combination of two components, a deterministic component and a stochastic component. The deterministic component can be recovered from the low-frequency signals in the downsampled image. The stochastic component, on the other hand, contains the signals that have little correlation with the low resolution image. We adopt two complementary methods for generating these two components. While generative adversarial networks are used for the stochastic component, deterministic component reconstruction is formulated as a regression problem solved using deep neural networks. Since the deterministic component exhibits clearer local orientations, we design novel loss functions tailored for such properties for training the deep regression network. These two methods are first applied to the entire input image to produce two distinct high-resolution images. Afterwards, these two images are fused together using another deep neural network that also performs local statistical rectification, which tries to make the local statistics of the fused image match the same local statistics of the groundtruth image. Quantitative results and a user study indicate that the proposed method outperforms existing state-of-the-art algorithms with a clear margin.
Domain Transformer: Predicting Samples of Unseen, Future Domains
Jun 10, 2021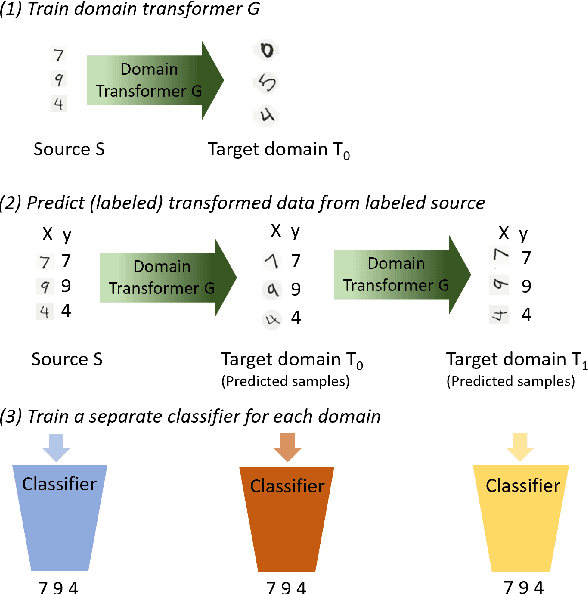
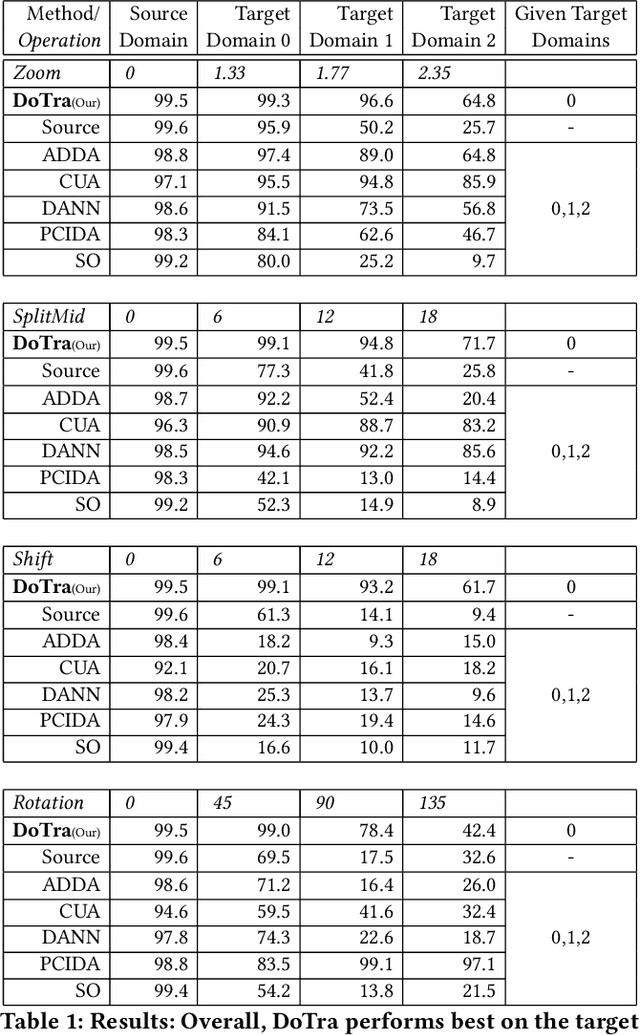
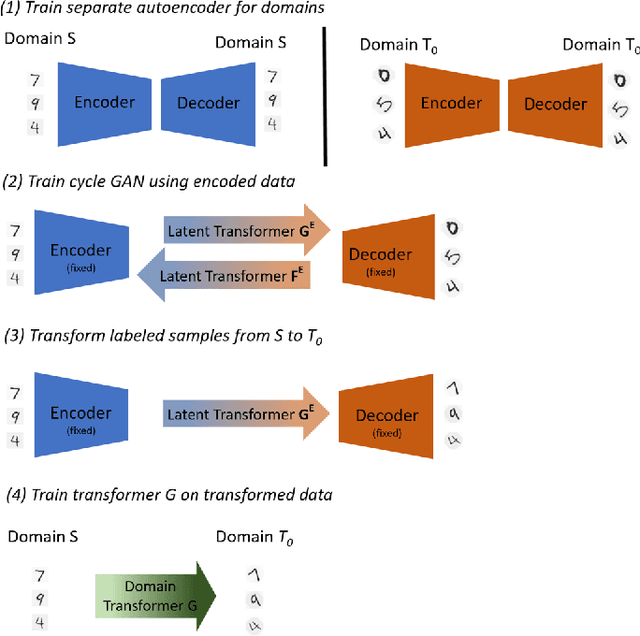

The data distribution commonly evolves over time leading to problems such as concept drift that often decrease classifier performance. We seek to predict unseen data (and their labels) allowing us to tackle challenges due to a non-constant data distribution in a \emph{proactive} manner rather than detecting and reacting to already existing changes that might already have led to errors. To this end, we learn a domain transformer in an unsupervised manner that allows generating data of unseen domains. Our approach first matches independently learned latent representations of two given domains obtained from an auto-encoder using a Cycle-GAN. In turn, a transformation of the original samples can be learned that can be applied iteratively to extrapolate to unseen domains. Our evaluation on CNNs on image data confirms the usefulness of the approach. It also achieves very good results on the well-known problem of unsupervised domain adaption, where labels but not samples have to be predicted.
Supervised learning for crop/weed classification based on color and texture features
Jun 19, 2021

Computer vision techniques have attracted a great interest in precision agriculture, recently. The common goal of all computer vision-based precision agriculture tasks is to detect the objects of interest (e.g., crop, weed) and discriminating them from the background. The Weeds are unwanted plants growing among crops competing for nutrients, water, and sunlight, causing losses to crop yields. Weed detection and mapping is critical for site-specific weed management to reduce the cost of labor and impact of herbicides. This paper investigates the use of color and texture features for discrimination of Soybean crops and weeds. Feature extraction methods including two color spaces (RGB, HSV), gray level Co-occurrence matrix (GLCM), and Local Binary Pattern (LBP) are used to train the Support Vector Machine (SVM) classifier. The experiment was carried out on image dataset of soybean crop, obtained from an unmanned aerial vehicle (UAV), which is publicly available. The results from the experiment showed that the highest accuracy (above 96%) was obtained from the combination of color and LBP features.
TeLCoS: OnDevice Text Localization with Clustering of Script
Apr 16, 2021
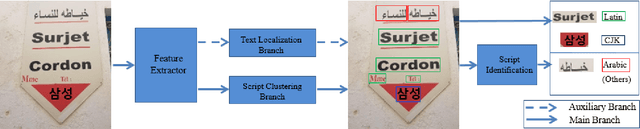

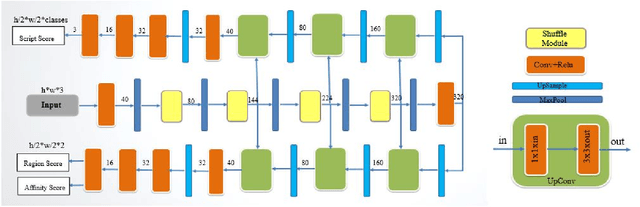
Recent research in the field of text localization in a resource constrained environment has made extensive use of deep neural networks. Scene text localization and recognition on low-memory mobile devices have a wide range of applications including content extraction, image categorization and keyword based image search. For text recognition of multi-lingual localized text, the OCR systems require prior knowledge of the script of each text instance. This leads to word script identification being an essential step for text recognition. Most existing methods treat text localization, script identification and text recognition as three separate tasks. This makes script identification an overhead in the recognition pipeline. To reduce this overhead, we propose TeLCoS: OnDevice Text Localization with Clustering of Script, a multi-task dual branch lightweight CNN network that performs real-time on device Text Localization and High-level Script Clustering simultaneously. The network drastically reduces the number of calls to a separate script identification module, by grouping and identifying some majorly used scripts through a single feed-forward pass over the localization network. We also introduce a novel structural similarity based channel pruning mechanism to build an efficient network with only 1.15M parameters. Experiments on benchmark datasets suggest that our method achieves state-of-the-art performance, with execution latency of 60 ms for the entire pipeline on the Exynos 990 chipset device.
Robust Principal Component Analysis for Background Estimation of Particle Image Velocimetry Data
Aug 16, 2019

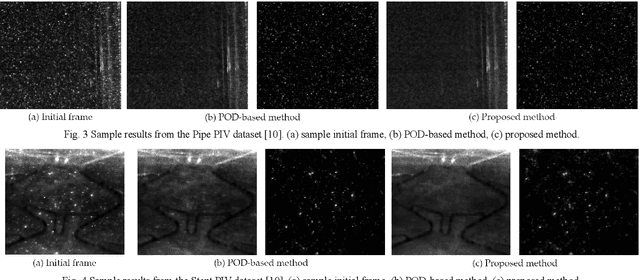
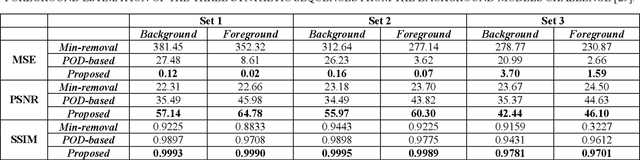
Particle Image Velocimetry (PIV) data processing procedures are adversely affected by light reflections and backgrounds as well as defects in the models and sticky particles that occlude the inner walls of the boundaries. In this paper, a novel approach is proposed for decomposition of the PIV data into background/foreground components, greatly reducing the effects of such artifacts. This is achieved by utilizing Robust Principal Component Analysis (RPCA) applied to the data matrix, generated by aggregating the vectorized PIV frames. It is assumed that the data matrix can be decomposed into two statistically different components, a low-rank component depicting the still background and a sparse component representing the moving particles within the imaged geometry. Formulating the assumptions as an optimization problem, Augmented Lagrange Multiplier (ALM) method is used for decomposing the data matrix into the low-rank and sparse components. Experiments and comparisons with the state-of-the-art using several PIV image sequences reveal the superiority of the proposed approach for background removal of PIV data.
iToF2dToF: A Robust and Flexible Representation for Data-Driven Time-of-Flight Imaging
Mar 12, 2021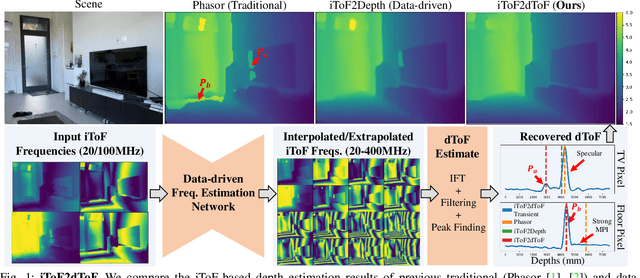
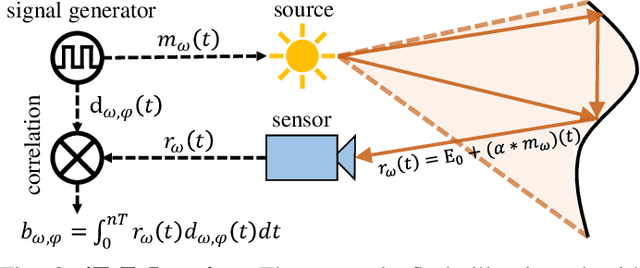
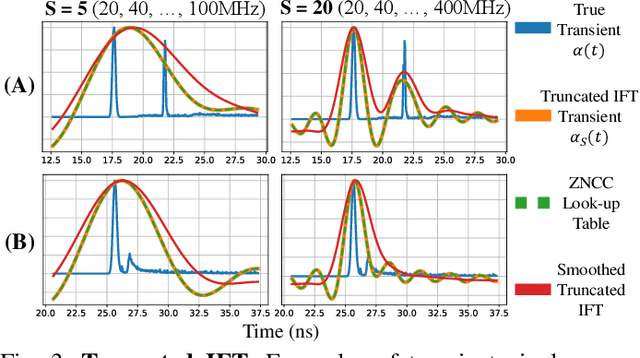
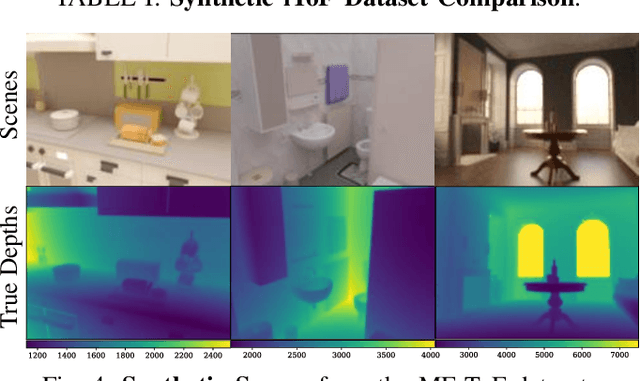
Indirect Time-of-Flight (iToF) cameras are a promising depth sensing technology. However, they are prone to errors caused by multi-path interference (MPI) and low signal-to-noise ratio (SNR). Traditional methods, after denoising, mitigate MPI by estimating a transient image that encodes depths. Recently, data-driven methods that jointly denoise and mitigate MPI have become state-of-the-art without using the intermediate transient representation. In this paper, we propose to revisit the transient representation. Using data-driven priors, we interpolate/extrapolate iToF frequencies and use them to estimate the transient image. Given direct ToF (dToF) sensors capture transient images, we name our method iToF2dToF. The transient representation is flexible. It can be integrated with different rule-based depth sensing algorithms that are robust to low SNR and can deal with ambiguous scenarios that arise in practice (e.g., specular MPI, optical cross-talk). We demonstrate the benefits of iToF2dToF over previous methods in real depth sensing scenarios.
Product Image Recognition with Guidance Learning and Noisy Supervision
Jul 26, 2019


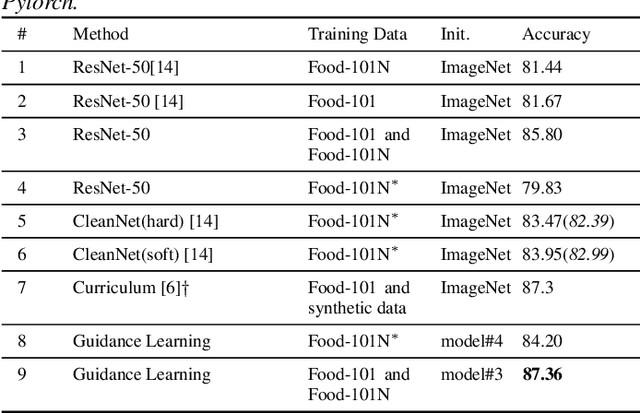
This paper considers recognizing products from daily photos, which is an important problem in real-world applications but also challenging due to background clutters, category diversities, noisy labels, etc. We address this problem by two contributions. First, we introduce a novel large-scale product image dataset, termed as Product-90. Instead of collecting product images by labor-and time-intensive image capturing, we take advantage of the web and download images from the reviews of several e-commerce websites where the images are casually captured by consumers. Labels are assigned automatically by the categories of e-commerce websites. Totally the Product-90 consists of more than 140K images with 90 categories. Due to the fact that consumers may upload unrelated images, it is inevitable that our Product-90 introduces noisy labels. As the second contribution, we develop a simple yet efficient \textit{guidance learning} (GL) method for training convolutional neural networks (CNNs) with noisy supervision. The GL method first trains an initial teacher network with the full noisy dataset, and then trains a target/student network with both large-scale noisy set and small manually-verified clean set in a multi-task manner. Specifically, in the stage of student network training, the large-scale noisy data is supervised by its guidance knowledge which is the combination of its given noisy label and the soften label from the teacher network. We conduct extensive experiments on our Products-90 and public datasets, namely Food101, Food-101N, and Clothing1M. Our guidance learning method achieves performance superior to state-of-the-art methods on these datasets.