 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Atrous Residual Interconnected Encoder to Attention Decoder Framework for Vertebrae Segmentation via 3D Volumetric CT Images
Apr 08, 2021
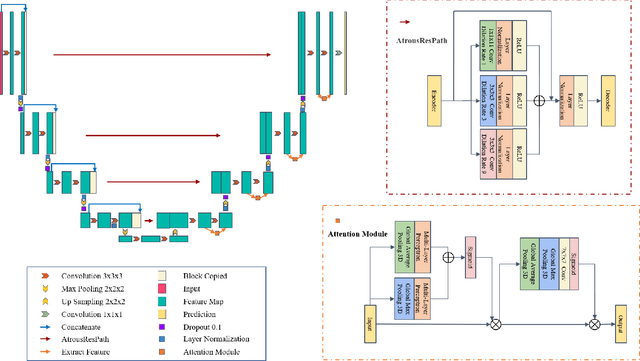

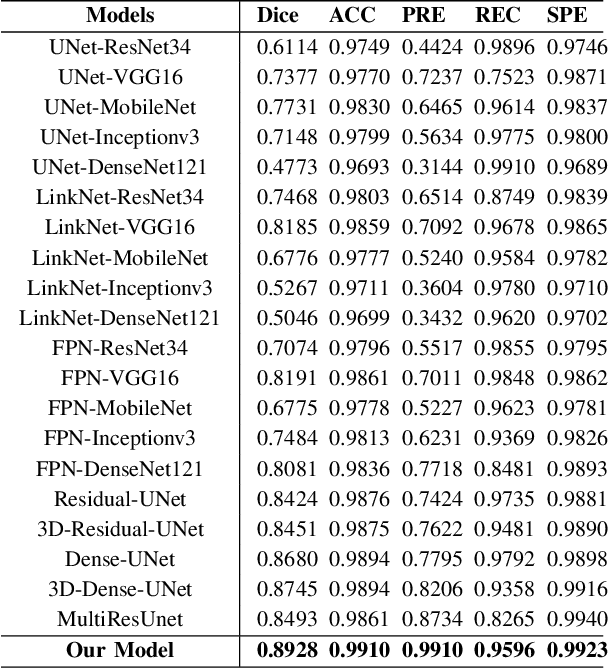
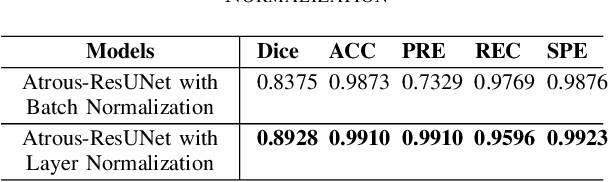
Automatic medical image segmentation based on Computed Tomography (CT) has been widely applied for computer-aided surgery as a prerequisite. With the development of deep learning technologies, deep convolutional neural networks (DCNNs) have shown robust performance in automated semantic segmentation of medical images. However, semantic segmentation algorithms based on DCNNs still meet the challenges of feature loss between encoder and decoder, multi-scale object, restricted field of view of filters, and lack of medical image data. This paper proposes a novel algorithm for automated vertebrae segmentation via 3D volumetric spine CT images. The proposed model is based on the structure of encoder to decoder, using layer normalization to optimize mini-batch training performance. To address the concern of the information loss between encoder and decoder, we designed an Atrous Residual Path to pass more features from encoder to decoder instead of an easy shortcut connection. The proposed model also applied the attention module in the decoder part to extract features from variant scales. The proposed model is evaluated on a publicly available dataset by a variety of metrics. The experimental results show that our model achieves competitive performance compared with other state-of-the-art medical semantic segmentation methods.
Integrating Novelty Detection Capabilities with MSL Mastcam Operations to Enhance Data Analysis
Mar 23, 2021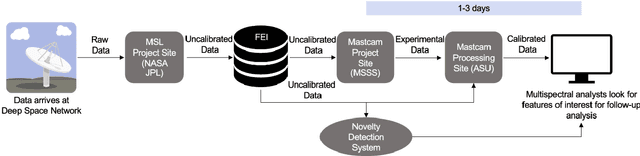



While innovations in scientific instrumentation have pushed the boundaries of Mars rover mission capabilities, the increase in data complexity has pressured Mars Science Laboratory (MSL) and future Mars rover operations staff to quickly analyze complex data sets to meet progressively shorter tactical and strategic planning timelines. MSLWEB is an internal data tracking tool used by operations staff to perform first pass analysis on MSL image sequences, a series of products taken by the Mast camera, Mastcam. Mastcam's multiband multispectral image sequences require more complex analysis compared to standard 3-band RGB images. Typically, these are analyzed using traditional methods to identify unique features within the sequence. Given the short time frame of tactical planning in which downlinked images might need to be analyzed (within 5-10 hours before the next uplink), there exists a need to triage analysis time to focus on the most important sequences and parts of a sequence. We address this need by creating products for MSLWEB that use novelty detection to help operations staff identify unusual data that might be diagnostic of new or atypical compositions or mineralogies detected within an imaging scene. This was achieved in two ways: 1) by creating products for each sequence to identify novel regions in the image, and 2) by assigning multispectral sequences a sortable novelty score. These new products provide colorized heat maps of inferred novelty that operations staff can use to rapidly review downlinked data and focus their efforts on analyzing potentially new kinds of diagnostic multispectral signatures. This approach has the potential to guide scientists to new discoveries by quickly drawing their attention to often subtle variations not detectable with simple color composites.
DONet: Learning Category-Level 6D Object Pose and Size Estimation from Depth Observation
Jun 27, 2021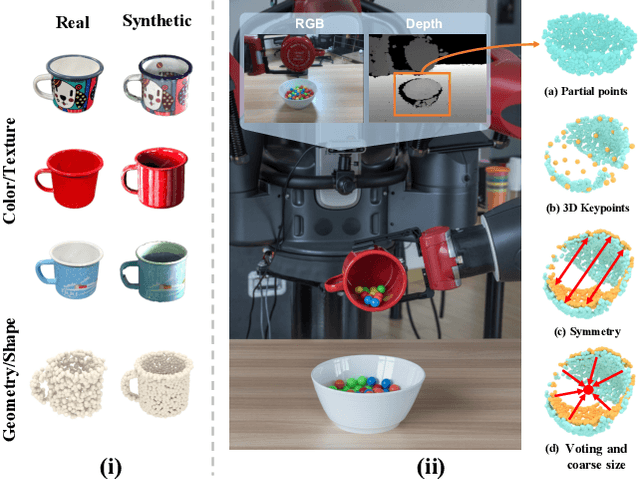
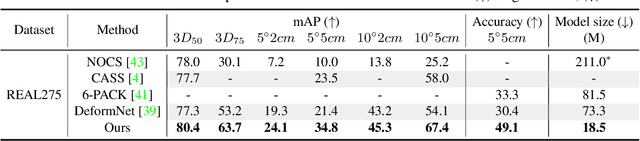
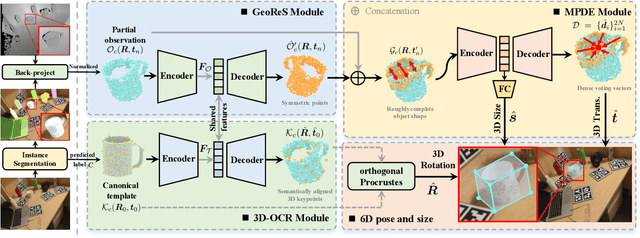
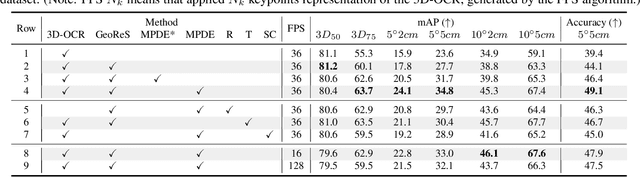
We propose a method of Category-level 6D Object Pose and Size Estimation (COPSE) from a single depth image, without external pose-annotated real-world training data. While previous works exploit visual cues in RGB(D) images, our method makes inferences based on the rich geometric information of the object in the depth channel alone. Essentially, our framework explores such geometric information by learning the unified 3D Orientation-Consistent Representations (3D-OCR) module, and further enforced by the property of Geometry-constrained Reflection Symmetry (GeoReS) module. The magnitude information of object size and the center point is finally estimated by Mirror-Paired Dimensional Estimation (MPDE) module. Extensive experiments on the category-level NOCS benchmark demonstrate that our framework competes with state-of-the-art approaches that require labeled real-world images. We also deploy our approach to a physical Baxter robot to perform manipulation tasks on unseen but category-known instances, and the results further validate the efficacy of our proposed model. Our videos are available in the supplementary material.
HPRNet: Hierarchical Point Regression for Whole-Body Human Pose Estimation
Jun 08, 2021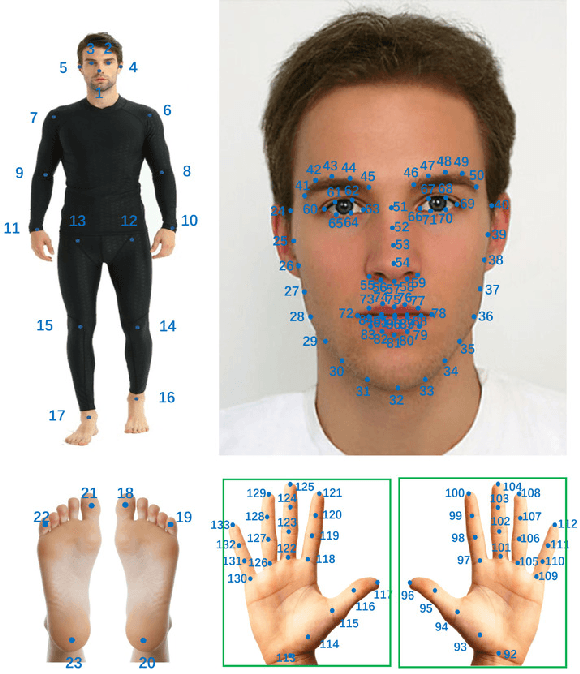

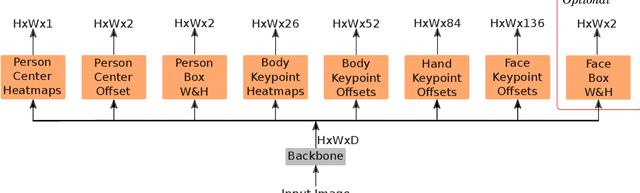

In this paper, we present a new bottom-up one-stage method for whole-body pose estimation, which we name "hierarchical point regression," or HPRNet for short, referring to the network that implements this method. To handle the scale variance among different body parts, we build a hierarchical point representation of body parts and jointly regress them. Unlike the existing two-stage methods, our method predicts whole-body pose in a constant time independent of the number of people in an image. On the COCO WholeBody dataset, HPRNet significantly outperforms all previous bottom-up methods on the keypoint detection of all whole-body parts (i.e. body, foot, face and hand); it also achieves state-of-the-art results in the face (75.4 AP) and hand (50.4 AP) keypoint detection. Code and models are available at https://github.com/nerminsamet/HPRNet.git.
Ultrasound Matrix Imaging. I. The focused reflection matrix and the F-factor
Mar 02, 2021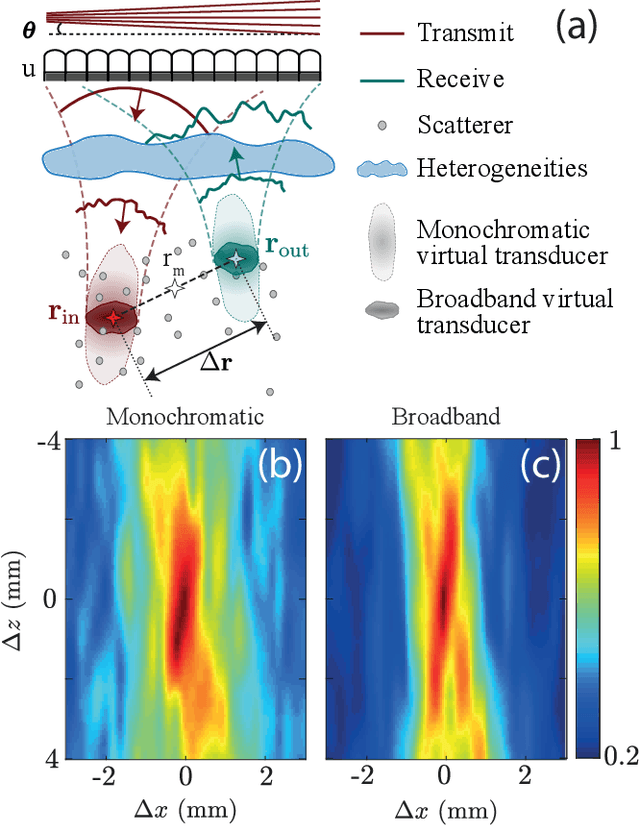
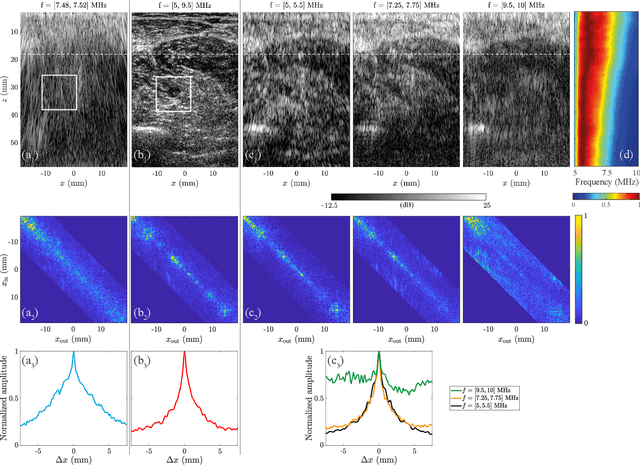
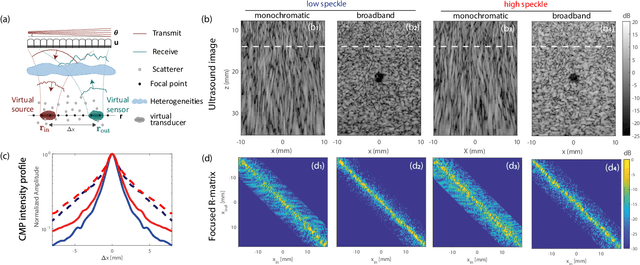
This is the first article in a series of two dealing with a matrix approach \alex{for} aberration quantification and correction in ultrasound imaging. Advanced synthetic beamforming relies on a double focusing operation at transmission and reception on each point of the medium. Ultrasound matrix imaging (UMI) consists in decoupling the location of these transmitted and received focal spots. The response between those virtual transducers form the so-called focused reflection matrix that actually contains much more information than a raw ultrasound image. In this paper, a time-frequency analysis of this matrix is performed, which highlights the single and multiple scattering contributions as well as the impact of aberrations in the monochromatic and broadband regimes. Interestingly, this analysis enables the measurement of the incoherent input-output point spread function at any pixel of this image. A focusing criterion can then be built, and its evolution used to quantify the amount of aberration throughout the ultrasound image. In contrast to the standard coherence factor used in the literature, this new indicator is robust to multiple scattering and electronic noise, thereby providing a highly contrasted map of the focusing quality. As a proof-of-concept, UMI is applied here to the in-vivo study of a human calf, but it can be extended to any kind of ultrasound diagnosis or non-destructive evaluation.
LightLayers: Parameter Efficient Dense and Convolutional Layers for Image Classification
Jan 06, 2021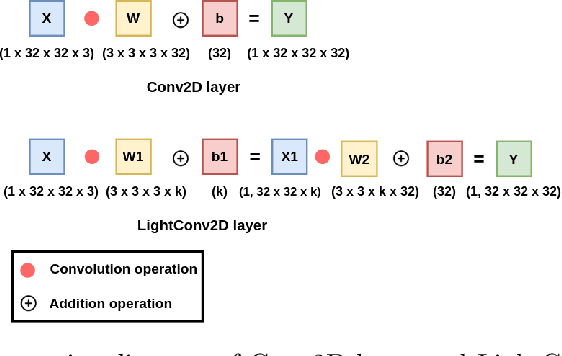
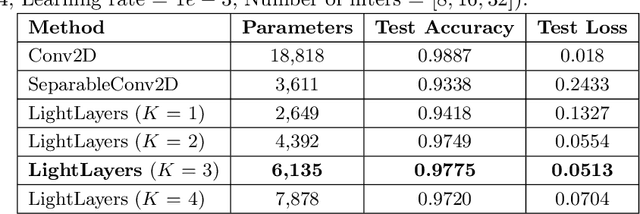
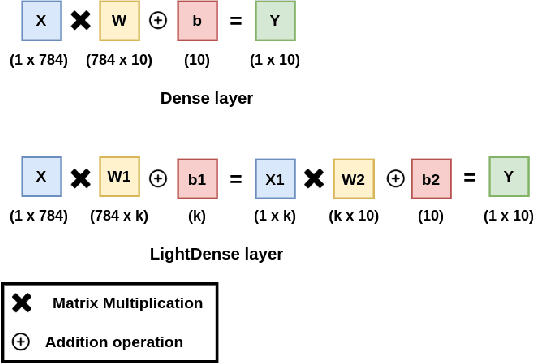
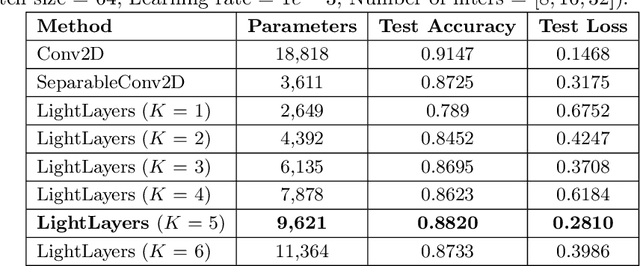
Deep Neural Networks (DNNs) have become the de-facto standard in computer vision, as well as in many other pattern recognition tasks. A key drawback of DNNs is that the training phase can be very computationally expensive. Organizations or individuals that cannot afford purchasing state-of-the-art hardware or tapping into cloud-hosted infrastructures may face a long waiting time before the training completes or might not be able to train a model at all. Investigating novel ways to reduce the training time could be a potential solution to alleviate this drawback, and thus enabling more rapid development of new algorithms and models. In this paper, we propose LightLayers, a method for reducing the number of trainable parameters in deep neural networks (DNN). The proposed LightLayers consists of LightDense andLightConv2D layer that are as efficient as regular Conv2D and Dense layers, but uses less parameters. We resort to Matrix Factorization to reduce the complexity of the DNN models resulting into lightweight DNNmodels that require less computational power, without much loss in the accuracy. We have tested LightLayers on MNIST, Fashion MNIST, CI-FAR 10, and CIFAR 100 datasets. Promising results are obtained for MNIST, Fashion MNIST, CIFAR-10 datasets whereas CIFAR 100 shows acceptable performance by using fewer parameters.
Edge-competing Pathological Liver Vessel Segmentation with Limited Labels
Aug 01, 2021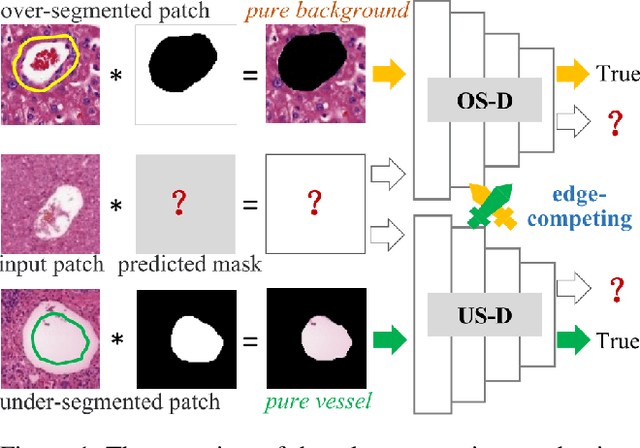
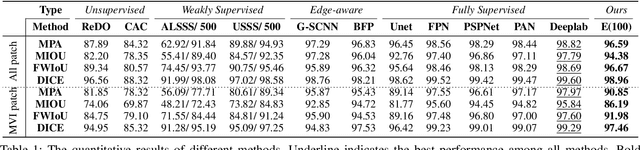
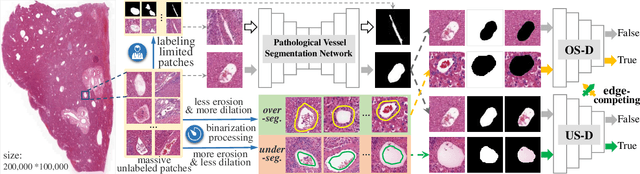
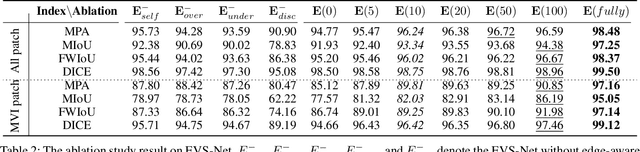
The microvascular invasion (MVI) is a major prognostic factor in hepatocellular carcinoma, which is one of the malignant tumors with the highest mortality rate. The diagnosis of MVI needs discovering the vessels that contain hepatocellular carcinoma cells and counting their number in each vessel, which depends heavily on experiences of the doctor, is largely subjective and time-consuming. However, there is no algorithm as yet tailored for the MVI detection from pathological images. This paper collects the first pathological liver image dataset containing 522 whole slide images with labels of vessels, MVI, and hepatocellular carcinoma grades. The first and essential step for the automatic diagnosis of MVI is the accurate segmentation of vessels. The unique characteristics of pathological liver images, such as super-large size, multi-scale vessel, and blurred vessel edges, make the accurate vessel segmentation challenging. Based on the collected dataset, we propose an Edge-competing Vessel Segmentation Network (EVS-Net), which contains a segmentation network and two edge segmentation discriminators. The segmentation network, combined with an edge-aware self-supervision mechanism, is devised to conduct vessel segmentation with limited labeled patches. Meanwhile, two discriminators are introduced to distinguish whether the segmented vessel and background contain residual features in an adversarial manner. In the training stage, two discriminators are devised tocompete for the predicted position of edges. Exhaustive experiments demonstrate that, with only limited labeled patches, EVS-Net achieves a close performance of fully supervised methods, which provides a convenient tool for the pathological liver vessel segmentation. Code is publicly available at https://github.com/zju-vipa/EVS-Net.
Two-Stage Monte Carlo Denoising with Adaptive Sampling and Kernel Pool
Mar 30, 2021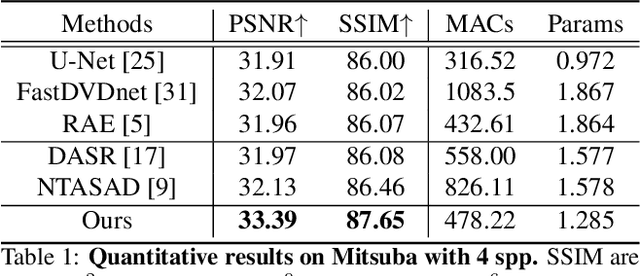
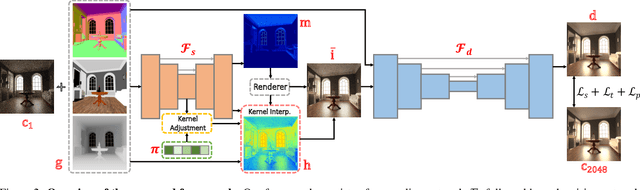
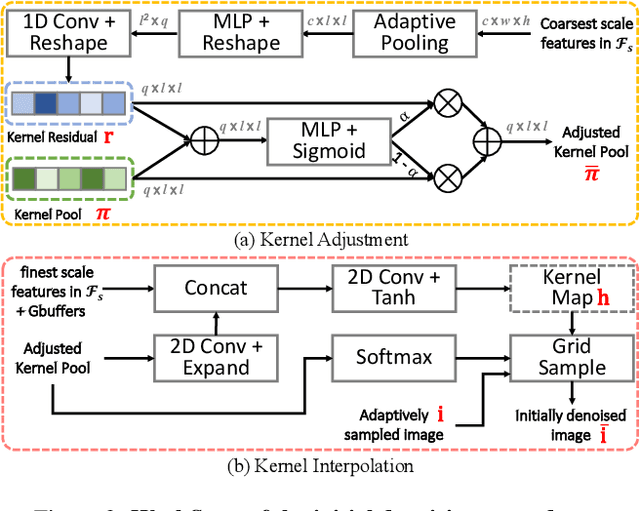

Monte Carlo path tracer renders noisy image sequences at low sampling counts. Although great progress has been made on denoising such sequences, existing methods still suffer from spatial and temporary artifacts. In this paper, we tackle the problems in Monte Carlo rendering by proposing a two-stage denoiser based on the adaptive sampling strategy. In the first stage, concurrent to adjusting samples per pixel (spp) on-the-fly, we reuse the computations to generate extra denoising kernels applying on the adaptively rendered image. Rather than a direct prediction of pixel-wise kernels, we save the overhead complexity by interpolating such kernels from a public kernel pool, which can be dynamically updated to fit input signals. In the second stage, we design the position-aware pooling and semantic alignment operators to improve spatial-temporal stability. Our method was first benchmarked on 10 synthesized scenes rendered from the Mitsuba renderer and then validated on 3 additional scenes rendered from our self-built RTX-based renderer. Our method outperforms state-of-the-art counterparts in terms of both numerical error and visual quality.
DMSANet: Dual Multi Scale Attention Network
Jun 13, 2021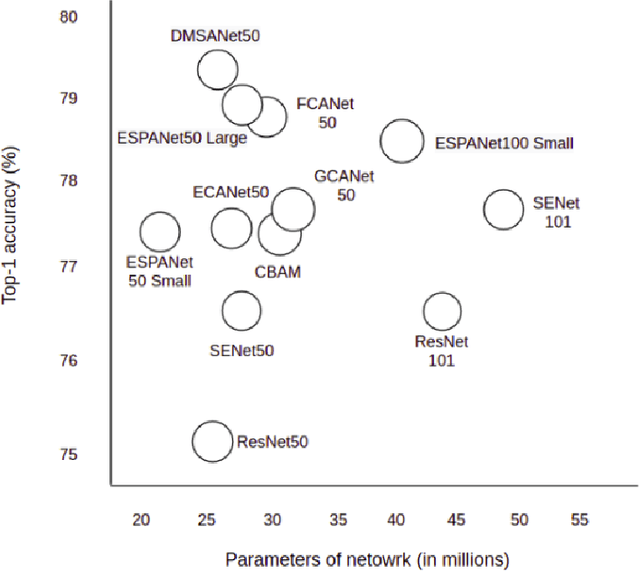
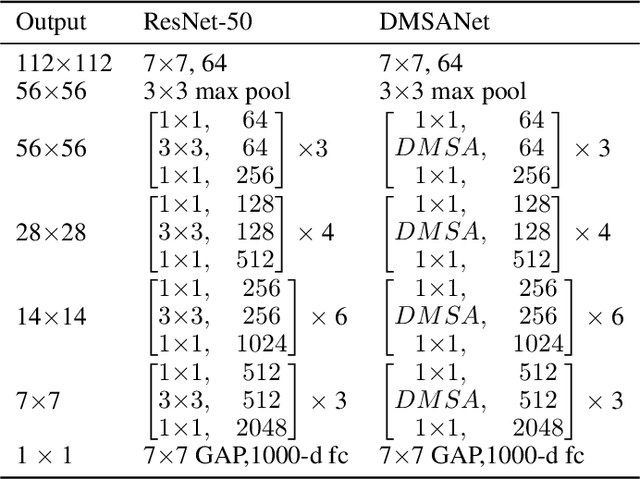
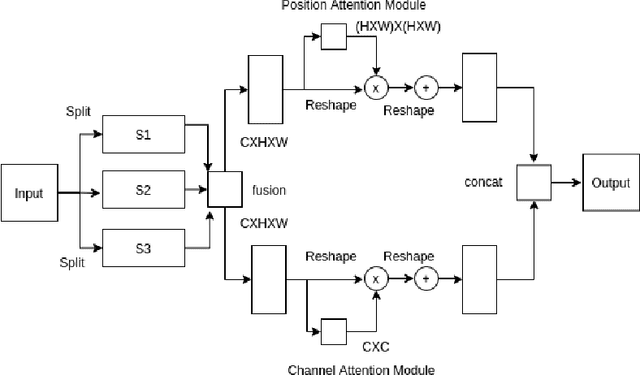
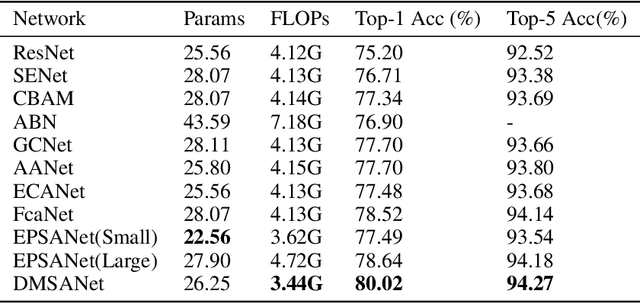
Attention mechanism of late has been quite popular in the computer vision community. A lot of work has been done to improve the performance of the network, although almost always it results in increased computational complexity. In this paper, we propose a new attention module that not only achieves the best performance but also has lesser parameters compared to most existing models. Our attention module can easily be integrated with other convolutional neural networks because of its lightweight nature. The proposed network named Dual Multi Scale Attention Network (DMSANet) is comprised of two parts: the first part is used to extract features at various scales and aggregate them, the second part uses spatial and channel attention modules in parallel to adaptively integrate local features with their global dependencies. We benchmark our network performance for Image Classification on ImageNet dataset, Object Detection and Instance Segmentation both on MS COCO dataset.
The Randomness of Input Data Spaces is an A Priori Predictor for Generalization
Jun 08, 2021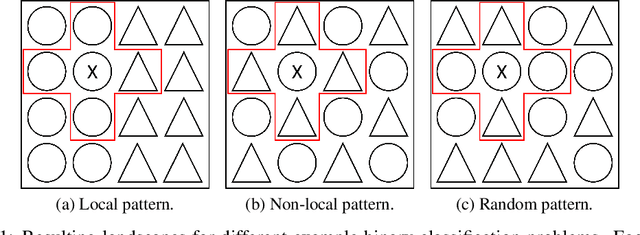
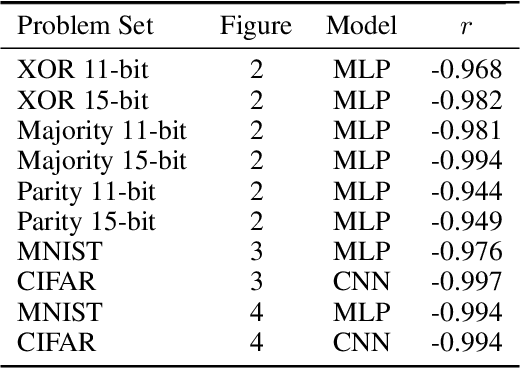
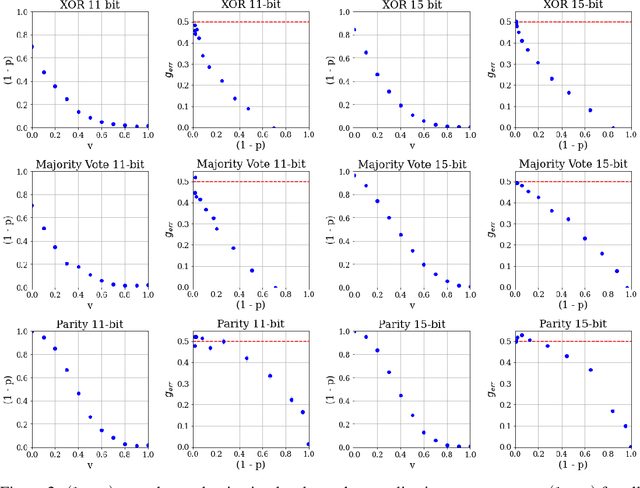
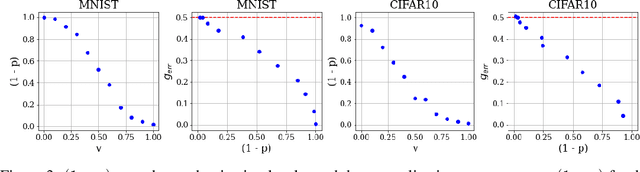
Over-parameterized models can perfectly learn various types of data distributions, however, generalization error is usually lower for real data in comparison to artificial data. This suggests that the properties of data distributions have an impact on generalization capability. This work focuses on the search space defined by the input data and assumes that the correlation between labels of neighboring input values influences generalization. If correlation is low, the randomness of the input data space is high leading to high generalization error. We suggest to measure the randomness of an input data space using Maurer's universal. Results for synthetic classification tasks and common image classification benchmarks (MNIST, CIFAR10, and Microsoft's cats vs. dogs data set) find a high correlation between the randomness of input data spaces and the generalization error of deep neural networks for binary classification problems.