 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation
Apr 03, 2024
Text-to-image generation has achieved astonishing results, yet precise spatial controllability and prompt fidelity remain highly challenging. This limitation is typically addressed through cumbersome prompt engineering, scene layout conditioning, or image editing techniques which often require hand drawn masks. Nonetheless, pre-existing works struggle to take advantage of the natural instance-level compositionality of scenes due to the typically flat nature of rasterized RGB output images. Towards adressing this challenge, we introduce MuLAn: a novel dataset comprising over 44K MUlti-Layer ANnotations of RGB images as multilayer, instance-wise RGBA decompositions, and over 100K instance images. To build MuLAn, we developed a training free pipeline which decomposes a monocular RGB image into a stack of RGBA layers comprising of background and isolated instances. We achieve this through the use of pretrained general-purpose models, and by developing three modules: image decomposition for instance discovery and extraction, instance completion to reconstruct occluded areas, and image re-assembly. We use our pipeline to create MuLAn-COCO and MuLAn-LAION datasets, which contain a variety of image decompositions in terms of style, composition and complexity. With MuLAn, we provide the first photorealistic resource providing instance decomposition and occlusion information for high quality images, opening up new avenues for text-to-image generative AI research. With this, we aim to encourage the development of novel generation and editing technology, in particular layer-wise solutions. MuLAn data resources are available at https://MuLAn-dataset.github.io/.
Point-In-Context: Understanding Point Cloud via In-Context Learning
Apr 18, 2024With the emergence of large-scale models trained on diverse datasets, in-context learning has emerged as a promising paradigm for multitasking, notably in natural language processing and image processing. However, its application in 3D point cloud tasks remains largely unexplored. In this work, we introduce Point-In-Context (PIC), a novel framework for 3D point cloud understanding via in-context learning. We address the technical challenge of effectively extending masked point modeling to 3D point clouds by introducing a Joint Sampling module and proposing a vanilla version of PIC called Point-In-Context-Generalist (PIC-G). PIC-G is designed as a generalist model for various 3D point cloud tasks, with inputs and outputs modeled as coordinates. In this paradigm, the challenging segmentation task is achieved by assigning label points with XYZ coordinates for each category; the final prediction is then chosen based on the label point closest to the predictions. To break the limitation by the fixed label-coordinate assignment, which has poor generalization upon novel classes, we propose two novel training strategies, In-Context Labeling and In-Context Enhancing, forming an extended version of PIC named Point-In-Context-Segmenter (PIC-S), targeting improving dynamic context labeling and model training. By utilizing dynamic in-context labels and extra in-context pairs, PIC-S achieves enhanced performance and generalization capability in and across part segmentation datasets. PIC is a general framework so that other tasks or datasets can be seamlessly introduced into our PIC through a unified data format. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks and segmenting multi-datasets. Our PIC-S is capable of generalizing unseen datasets and performing novel part segmentation by customizing prompts.
On the Scalability of GNNs for Molecular Graphs
Apr 17, 2024Scaling deep learning models has been at the heart of recent revolutions in language modelling and image generation. Practitioners have observed a strong relationship between model size, dataset size, and performance. However, structure-based architectures such as Graph Neural Networks (GNNs) are yet to show the benefits of scale mainly due to the lower efficiency of sparse operations, large data requirements, and lack of clarity about the effectiveness of various architectures. We address this drawback of GNNs by studying their scaling behavior. Specifically, we analyze message-passing networks, graph Transformers, and hybrid architectures on the largest public collection of 2D molecular graphs. For the first time, we observe that GNNs benefit tremendously from the increasing scale of depth, width, number of molecules, number of labels, and the diversity in the pretraining datasets, resulting in a 30.25% improvement when scaling to 1 billion parameters and 28.98% improvement when increasing size of dataset to eightfold. We further demonstrate strong finetuning scaling behavior on 38 tasks, outclassing previous large models. We hope that our work paves the way for an era where foundational GNNs drive pharmaceutical drug discovery.
State-space Decomposition Model for Video Prediction Considering Long-term Motion Trend
Apr 17, 2024Stochastic video prediction enables the consideration of uncertainty in future motion, thereby providing a better reflection of the dynamic nature of the environment. Stochastic video prediction methods based on image auto-regressive recurrent models need to feed their predictions back into the latent space. Conversely, the state-space models, which decouple frame synthesis and temporal prediction, proves to be more efficient. However, inferring long-term temporal information about motion and generalizing to dynamic scenarios under non-stationary assumptions remains an unresolved challenge. In this paper, we propose a state-space decomposition stochastic video prediction model that decomposes the overall video frame generation into deterministic appearance prediction and stochastic motion prediction. Through adaptive decomposition, the model's generalization capability to dynamic scenarios is enhanced. In the context of motion prediction, obtaining a prior on the long-term trend of future motion is crucial. Thus, in the stochastic motion prediction branch, we infer the long-term motion trend from conditional frames to guide the generation of future frames that exhibit high consistency with the conditional frames. Experimental results demonstrate that our model outperforms baselines on multiple datasets.
Efficient Learnable Collaborative Attention for Single Image Super-Resolution
Apr 07, 2024Non-Local Attention (NLA) is a powerful technique for capturing long-range feature correlations in deep single image super-resolution (SR). However, NLA suffers from high computational complexity and memory consumption, as it requires aggregating all non-local feature information for each query response and recalculating the similarity weight distribution for different abstraction levels of features. To address these challenges, we propose a novel Learnable Collaborative Attention (LCoA) that introduces inductive bias into non-local modeling. Our LCoA consists of two components: Learnable Sparse Pattern (LSP) and Collaborative Attention (CoA). LSP uses the k-means clustering algorithm to dynamically adjust the sparse attention pattern of deep features, which reduces the number of non-local modeling rounds compared with existing sparse solutions. CoA leverages the sparse attention pattern and weights learned by LSP, and co-optimizes the similarity matrix across different abstraction levels, which avoids redundant similarity matrix calculations. The experimental results show that our LCoA can reduce the non-local modeling time by about 83% in the inference stage. In addition, we integrate our LCoA into a deep Learnable Collaborative Attention Network (LCoAN), which achieves competitive performance in terms of inference time, memory consumption, and reconstruction quality compared with other state-of-the-art SR methods.
LCM-Lookahead for Encoder-based Text-to-Image Personalization
Apr 04, 2024Recent advancements in diffusion models have introduced fast sampling methods that can effectively produce high-quality images in just one or a few denoising steps. Interestingly, when these are distilled from existing diffusion models, they often maintain alignment with the original model, retaining similar outputs for similar prompts and seeds. These properties present opportunities to leverage fast sampling methods as a shortcut-mechanism, using them to create a preview of denoised outputs through which we can backpropagate image-space losses. In this work, we explore the potential of using such shortcut-mechanisms to guide the personalization of text-to-image models to specific facial identities. We focus on encoder-based personalization approaches, and demonstrate that by tuning them with a lookahead identity loss, we can achieve higher identity fidelity, without sacrificing layout diversity or prompt alignment. We further explore the use of attention sharing mechanisms and consistent data generation for the task of personalization, and find that encoder training can benefit from both.
Benchmarking Counterfactual Image Generation
Mar 29, 2024
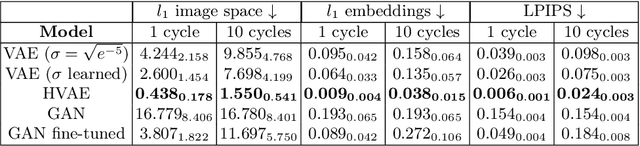
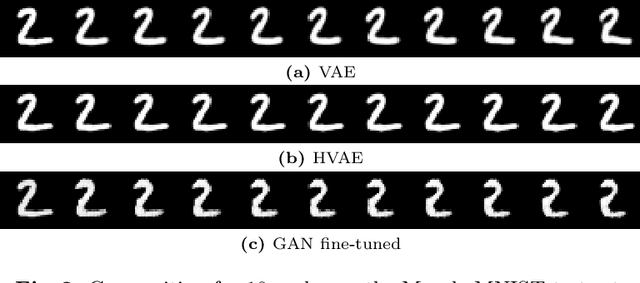
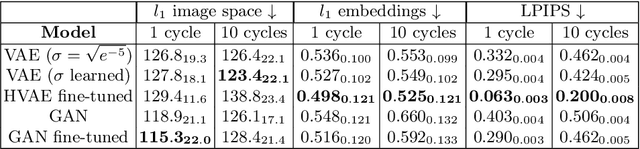
Counterfactual image generation is pivotal for understanding the causal relations of variables, with applications in interpretability and generation of unbiased synthetic data. However, evaluating image generation is a long-standing challenge in itself. The need to evaluate counterfactual generation compounds on this challenge, precisely because counterfactuals, by definition, are hypothetical scenarios without observable ground truths. In this paper, we present a novel comprehensive framework aimed at benchmarking counterfactual image generation methods. We incorporate metrics that focus on evaluating diverse aspects of counterfactuals, such as composition, effectiveness, minimality of interventions, and image realism. We assess the performance of three distinct conditional image generation model types, based on the Structural Causal Model paradigm. Our work is accompanied by a user-friendly Python package which allows to further evaluate and benchmark existing and future counterfactual image generation methods. Our framework is extendable to additional SCM and other causal methods, generative models, and datasets.
Classification of Prostate Cancer in 3D Magnetic Resonance Imaging Data based on Convolutional Neural Networks
Apr 16, 2024Prostate cancer is a commonly diagnosed cancerous disease among men world-wide. Even with modern technology such as multi-parametric magnetic resonance tomography and guided biopsies, the process for diagnosing prostate cancer remains time consuming and requires highly trained professionals. In this paper, different convolutional neural networks (CNN) are evaluated on their abilities to reliably classify whether an MRI sequence contains malignant lesions. Implementations of a ResNet, a ConvNet and a ConvNeXt for 3D image data are trained and evaluated. The models are trained using different data augmentation techniques, learning rates, and optimizers. The data is taken from a private dataset, provided by Cantonal Hospital Aarau. The best result was achieved by a ResNet3D, yielding an average precision score of 0.4583 and AUC ROC score of 0.6214.
AIGIQA-20K: A Large Database for AI-Generated Image Quality Assessment
Apr 04, 2024With the rapid advancements in AI-Generated Content (AIGC), AI-Generated Images (AIGIs) have been widely applied in entertainment, education, and social media. However, due to the significant variance in quality among different AIGIs, there is an urgent need for models that consistently match human subjective ratings. To address this issue, we organized a challenge towards AIGC quality assessment on NTIRE 2024 that extensively considers 15 popular generative models, utilizing dynamic hyper-parameters (including classifier-free guidance, iteration epochs, and output image resolution), and gather subjective scores that consider perceptual quality and text-to-image alignment altogether comprehensively involving 21 subjects. This approach culminates in the creation of the largest fine-grained AIGI subjective quality database to date with 20,000 AIGIs and 420,000 subjective ratings, known as AIGIQA-20K. Furthermore, we conduct benchmark experiments on this database to assess the correspondence between 16 mainstream AIGI quality models and human perception. We anticipate that this large-scale quality database will inspire robust quality indicators for AIGIs and propel the evolution of AIGC for vision. The database is released on https://www.modelscope.cn/datasets/lcysyzxdxc/AIGCQA-30K-Image.
Mitigating the Curse of Dimensionality for Certified Robustness via Dual Randomized Smoothing
Apr 15, 2024Randomized Smoothing (RS) has been proven a promising method for endowing an arbitrary image classifier with certified robustness. However, the substantial uncertainty inherent in the high-dimensional isotropic Gaussian noise imposes the curse of dimensionality on RS. Specifically, the upper bound of ${\ell_2}$ certified robustness radius provided by RS exhibits a diminishing trend with the expansion of the input dimension $d$, proportionally decreasing at a rate of $1/\sqrt{d}$. This paper explores the feasibility of providing ${\ell_2}$ certified robustness for high-dimensional input through the utilization of dual smoothing in the lower-dimensional space. The proposed Dual Randomized Smoothing (DRS) down-samples the input image into two sub-images and smooths the two sub-images in lower dimensions. Theoretically, we prove that DRS guarantees a tight ${\ell_2}$ certified robustness radius for the original input and reveal that DRS attains a superior upper bound on the ${\ell_2}$ robustness radius, which decreases proportionally at a rate of $(1/\sqrt m + 1/\sqrt n )$ with $m+n=d$. Extensive experiments demonstrate the generalizability and effectiveness of DRS, which exhibits a notable capability to integrate with established methodologies, yielding substantial improvements in both accuracy and ${\ell_2}$ certified robustness baselines of RS on the CIFAR-10 and ImageNet datasets. Code is available at https://github.com/xiasong0501/DRS.